 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianhua Li
Spikewhisper: Temporal Spike Backdoor Attacks on Federated Neuromorphic Learning over Low-power Devices
Mar 27, 2024
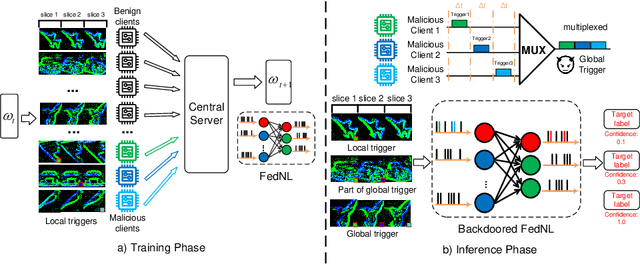

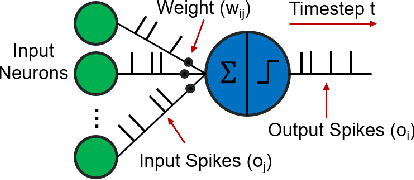
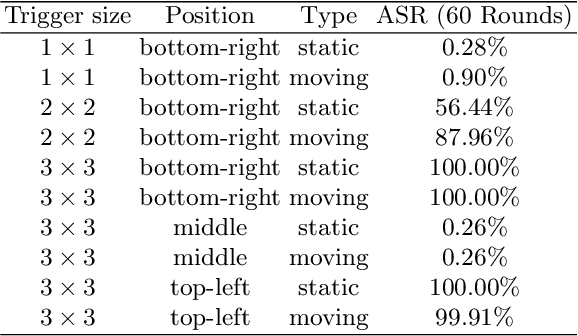
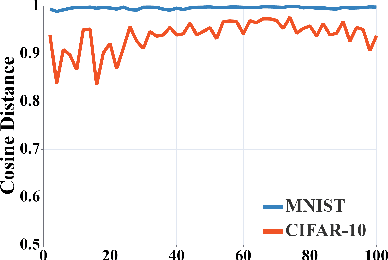
Federated neuromorphic learning (FedNL) leverages event-driven spiking neural networks and federated learning frameworks to effectively execute intelligent analysis tasks over amounts of distributed low-power devices but also perform vulnerability to poisoning attacks. The threat of backdoor attacks on traditional deep neural networks typically comes from time-invariant data. However, in FedNL, unknown threats may be hidden in time-varying spike signals. In this paper, we start to explore a novel vulnerability of FedNL-based systems with the concept of time division multiplexing, termed Spikewhisper, which allows attackers to evade detection as much as possible, as multiple malicious clients can imperceptibly poison with different triggers at different timeslices. In particular, the stealthiness of Spikewhisper is derived from the time-domain divisibility of global triggers, in which each malicious client pastes only one local trigger to a certain timeslice in the neuromorphic sample, and also the polarity and motion of each local trigger can be configured by attackers. Extensive experiments based on two different neuromorphic datasets demonstrate that the attack success rate of Spikewispher is higher than the temporally centralized attacks. Besides, it is validated that the effect of Spikewispher is sensitive to the trigger duration.
Toward the Tradeoffs between Privacy, Fairness and Utility in Federated Learning
Nov 30, 2023Federated Learning (FL) is a novel privacy-protection distributed machine learning paradigm that guarantees user privacy and prevents the risk of data leakage due to the advantage of the client's local training. Researchers have struggled to design fair FL systems that ensure fairness of results. However, the interplay between fairness and privacy has been less studied. Increasing the fairness of FL systems can have an impact on user privacy, while an increase in user privacy can affect fairness. In this work, on the client side, we use fairness metrics, such as Demographic Parity (DemP), Equalized Odds (EOs), and Disparate Impact (DI), to construct the local fair model. To protect the privacy of the client model, we propose a privacy-protection fairness FL method. The results show that the accuracy of the fair model with privacy increases because privacy breaks the constraints of the fairness metrics. In our experiments, we conclude the relationship between privacy, fairness and utility, and there is a tradeoff between these.
From Cluster Assumption to Graph Convolution: Graph-based Semi-Supervised Learning Revisited
Sep 24, 2023Graph-based semi-supervised learning (GSSL) has long been a hot research topic. Traditional methods are generally shallow learners, based on the cluster assumption. Recently, graph convolutional networks (GCNs) have become the predominant techniques for their promising performance. In this paper, we theoretically discuss the relationship between these two types of methods in a unified optimization framework. One of the most intriguing findings is that, unlike traditional ones, typical GCNs may not jointly consider the graph structure and label information at each layer. Motivated by this, we further propose three simple but powerful graph convolution methods. The first is a supervised method OGC which guides the graph convolution process with labels. The others are two unsupervised methods: GGC and its multi-scale version GGCM, both aiming to preserve the graph structure information during the convolution process. Finally, we conduct extensive experiments to show the effectiveness of our methods.
Case-Aware Adversarial Training
Apr 20, 2022
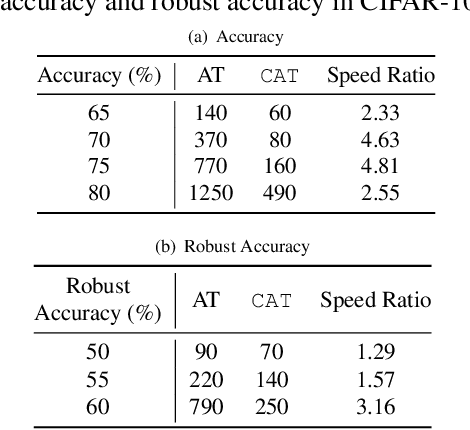

The neural network (NN) becomes one of the most heated type of models in various signal processing applications. However, NNs are extremely vulnerable to adversarial examples (AEs). To defend AEs, adversarial training (AT) is believed to be the most effective method while due to the intensive computation, AT is limited to be applied in most applications. In this paper, to resolve the problem, we design a generic and efficient AT improvement scheme, namely case-aware adversarial training (CAT). Specifically, the intuition stems from the fact that a very limited part of informative samples can contribute to most of model performance. Alternatively, if only the most informative AEs are used in AT, we can lower the computation complexity of AT significantly as maintaining the defense effect. To achieve this, CAT achieves two breakthroughs. First, a method to estimate the information degree of adversarial examples is proposed for AE filtering. Second, to further enrich the information that the NN can obtain from AEs, CAT involves a weight estimation and class-level balancing based sampling strategy to increase the diversity of AT at each iteration. Extensive experiments show that CAT is faster than vanilla AT by up to 3x while achieving competitive defense effect.
Video Annotation for Visual Tracking via Selection and Refinement
Aug 09, 2021
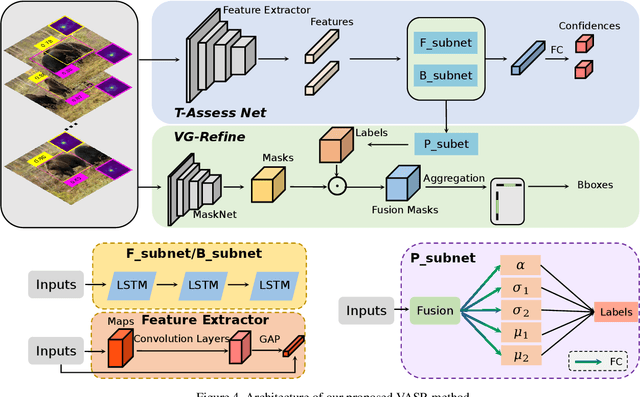
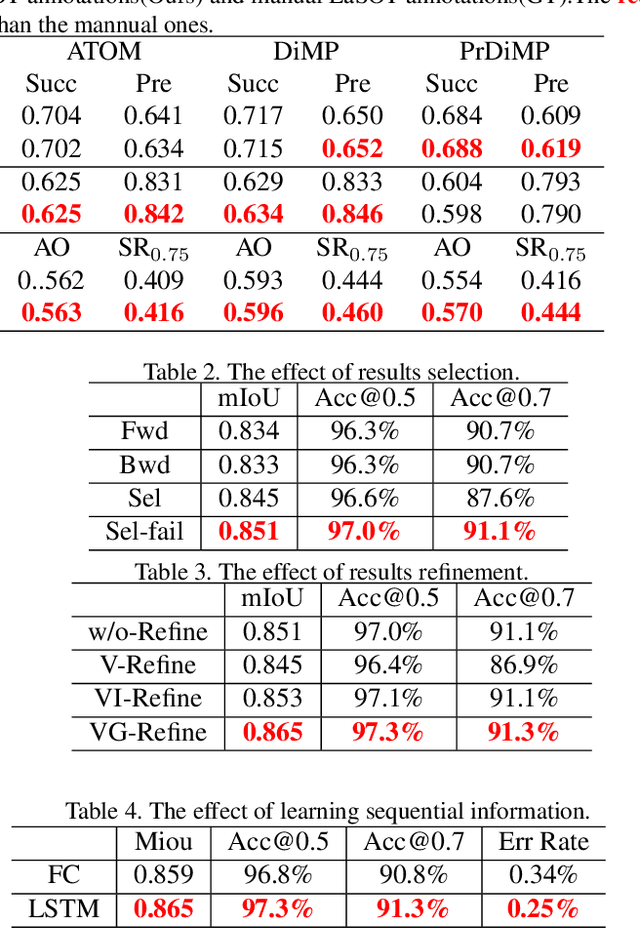
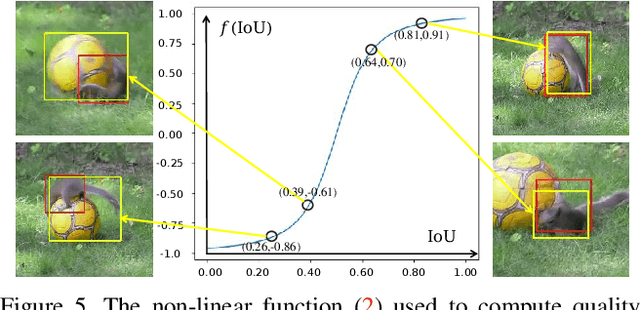
Deep learning based visual trackers entail offline pre-training on large volumes of video datasets with accurate bounding box annotations that are labor-expensive to achieve. We present a new framework to facilitate bounding box annotations for video sequences, which investigates a selection-and-refinement strategy to automatically improve the preliminary annotations generated by tracking algorithms. A temporal assessment network (T-Assess Net) is proposed which is able to capture the temporal coherence of target locations and select reliable tracking results by measuring their quality. Meanwhile, a visual-geometry refinement network (VG-Refine Net) is also designed to further enhance the selected tracking results by considering both target appearance and temporal geometry constraints, allowing inaccurate tracking results to be corrected. The combination of the above two networks provides a principled approach to ensure the quality of automatic video annotation. Experiments on large scale tracking benchmarks demonstrate that our method can deliver highly accurate bounding box annotations and significantly reduce human labor by 94.0%, yielding an effective means to further boost tracking performance with augmented training data.
Leveraging AI and Intelligent Reflecting Surface for Energy-Efficient Communication in 6G IoT
Dec 29, 2020

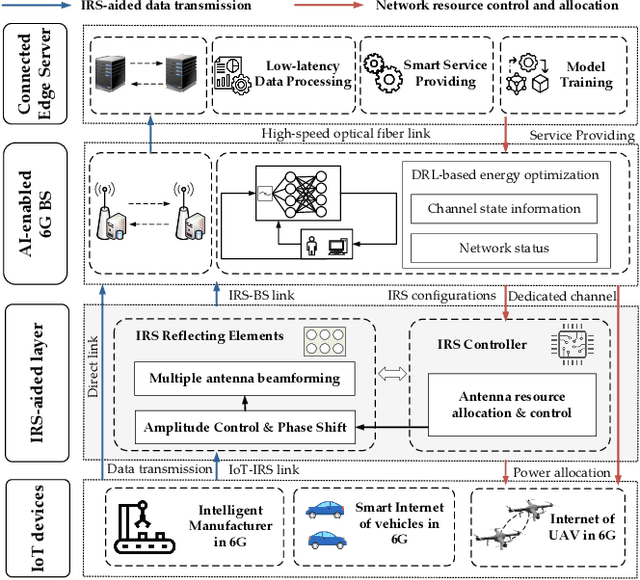

The ever-increasing data traffic, various delay-sensitive services, and the massive deployment of energy-limited Internet of Things (IoT) devices have brought huge challenges to the current communication networks, motivating academia and industry to move to the sixth-generation (6G) network. With the powerful capability of data transmission and processing, 6G is considered as an enabler for IoT communication with low latency and energy cost. In this paper, we propose an artificial intelligence (AI) and intelligent reflecting surface (IRS) empowered energy-efficiency communication system for 6G IoT. First, we design a smart and efficient communication architecture including the IRS-aided data transmission and the AI-driven network resource management mechanisms. Second, an energy efficiency-maximizing model under given transmission latency for 6G IoT system is formulated, which jointly optimizes the settings of all communication participants, i.e. IoT transmission power, IRS-reflection phase shift, and BS detection matrix. Third, a deep reinforcement learning (DRL) empowered network resource control and allocation scheme is proposed to solve the formulated optimization model. Based on the network and channel status, the DRL-enabled scheme facilities the energy-efficiency and low-latency communication. Finally, experimental results verified the effectiveness of our proposed communication system for 6G IoT.
High-Performance Long-Term Tracking with Meta-Updater
Apr 01, 2020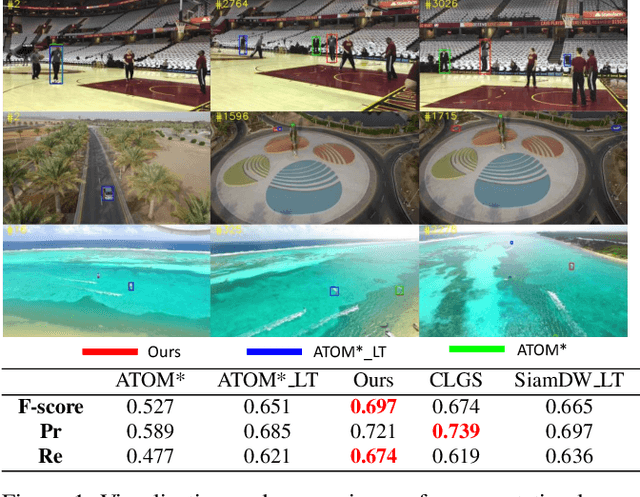

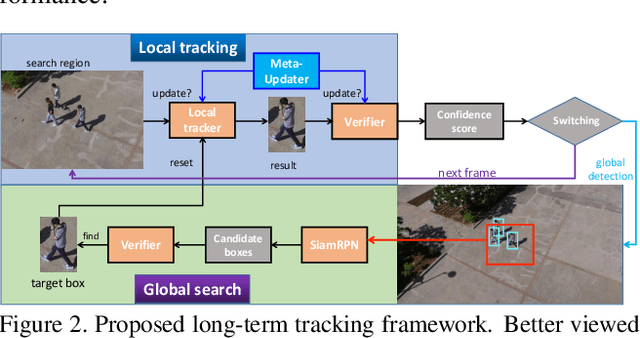
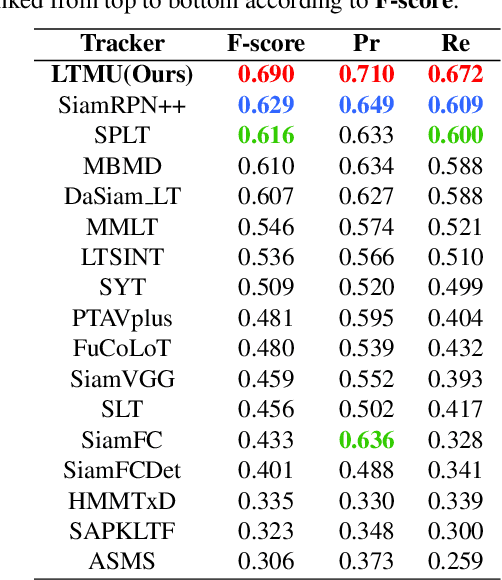
Long-term visual tracking has drawn increasing attention because it is much closer to practical applications than short-term tracking. Most top-ranked long-term trackers adopt the offline-trained Siamese architectures, thus, they cannot benefit from great progress of short-term trackers with online update. However, it is quite risky to straightforwardly introduce online-update-based trackers to solve the long-term problem, due to long-term uncertain and noisy observations. In this work, we propose a novel offline-trained Meta-Updater to address an important but unsolved problem: Is the tracker ready for updating in the current frame? The proposed meta-updater can effectively integrate geometric, discriminative, and appearance cues in a sequential manner, and then mine the sequential information with a designed cascaded LSTM module. Our meta-updater learns a binary output to guide the tracker's update and can be easily embedded into different trackers. This work also introduces a long-term tracking framework consisting of an online local tracker, an online verifier, a SiamRPN-based re-detector, and our meta-updater. Numerous experimental results on the VOT2018LT, VOT2019LT, OxUvALT, TLP, and LaSOT benchmarks show that our tracker performs remarkably better than other competing algorithms. Our project is available on the website: https://github.com/Daikenan/LTMU.
GelSlim: A High-Resolution, Compact, Robust, and Calibrated Tactile-sensing Finger
May 15, 2018


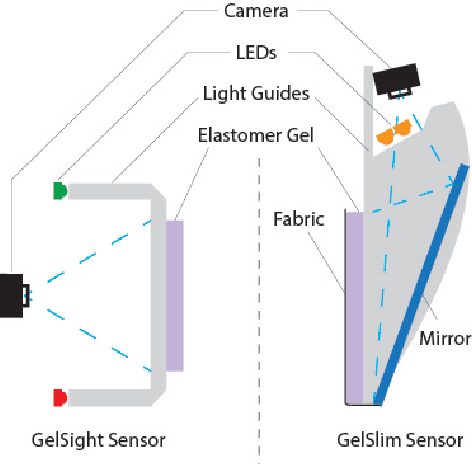
This work describes the development of a high-resolution tactile-sensing finger for robot grasping. This finger, inspired by previous GelSight sensing techniques, features an integration that is slimmer, more robust, and with more homogeneous output than previous vision-based tactile sensors. To achieve a compact integration, we redesign the optical path from illumination source to camera by combining light guides and an arrangement of mirror reflections. We parameterize the optical path with geometric design variables and describe the tradeoffs between the finger thickness, the depth of field of the camera, and the size of the tactile sensing area. The sensor sustains the wear from continuous use -- and abuse -- in grasping tasks by combining tougher materials for the compliant soft gel, a textured fabric skin, a structurally rigid body, and a calibration process that maintains homogeneous illumination and contrast of the tactile images during use. Finally, we evaluate the sensor's durability along four metrics that track the signal quality during more than 3000 grasping experiments.
Slip Detection with Combined Tactile and Visual Information
Feb 27, 2018
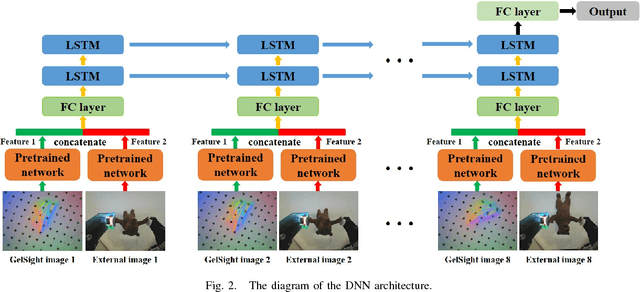


Slip detection plays a vital role in robotic manipulation and it has long been a challenging problem in the robotic community. In this paper, we propose a new method based on deep neural network (DNN) to detect slip. The training data is acquired by a GelSight tactile sensor and a camera mounted on a gripper when we use a robot arm to grasp and lift 94 daily objects with different grasping forces and grasping positions. The DNN is trained to classify whether a slip occurred or not. To evaluate the performance of the DNN, we test 10 unseen objects in 152 grasps. A detection accuracy as high as 88.03% is achieved. It is anticipated that the accuracy can be further improved with a larger dataset. This method is beneficial for robots to make stable grasps, which can be widely applied to automatic force control, grasping strategy selection and fine manipulation.
Deep Learning-Based Food Calorie Estimation Method in Dietary Assessment
Feb 18, 2018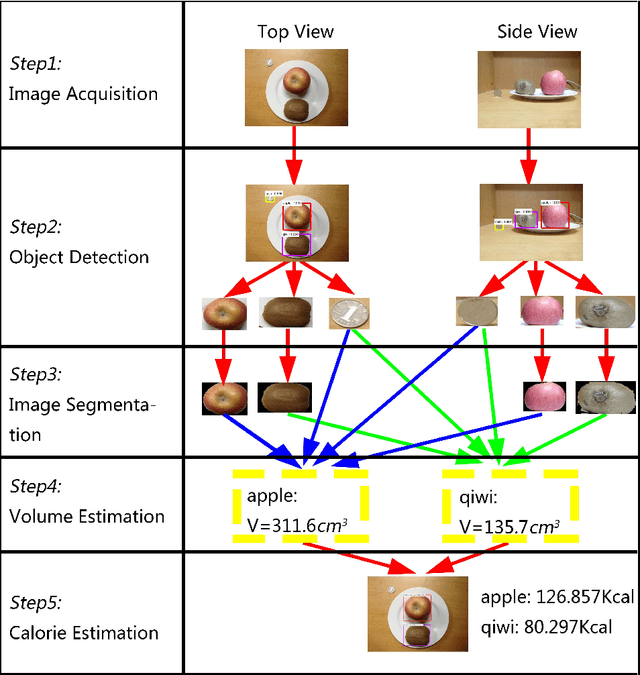
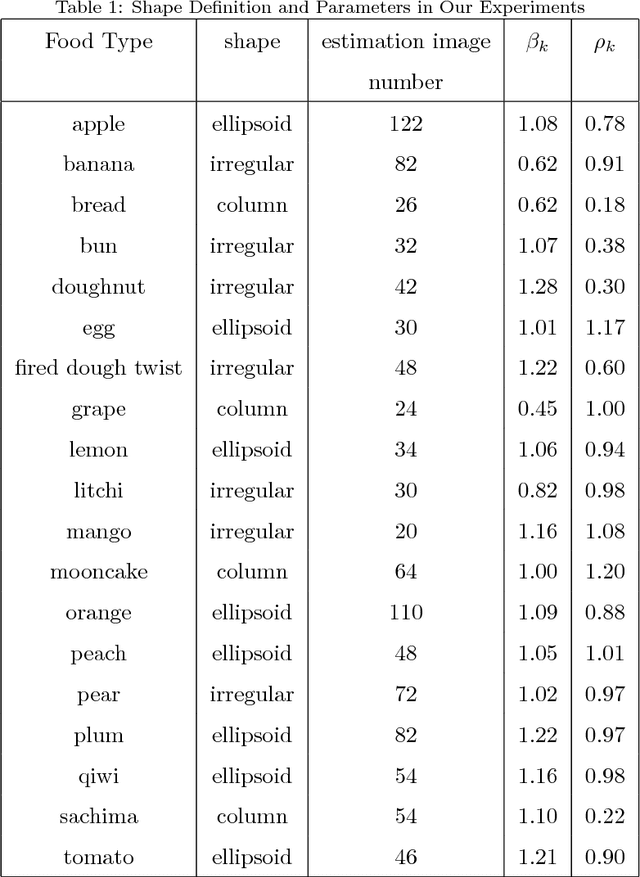
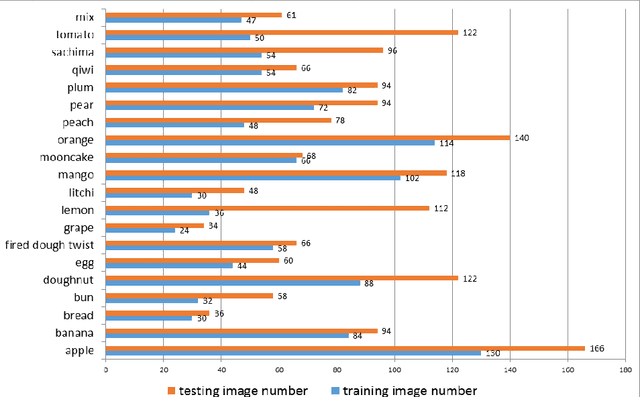

Obesity treatment requires obese patients to record all food intakes per day. Computer vision has been introduced to estimate calories from food images. In order to increase accuracy of detection and reduce the error of volume estimation in food calorie estimation, we present our calorie estimation method in this paper. To estimate calorie of food, a top view and side view is needed. Faster R-CNN is used to detect the food and calibration object. GrabCut algorithm is used to get each food's contour. Then the volume is estimated with the food and corresponding object. Finally we estimate each food's calorie. And the experiment results show our estimation method is effective.