 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin Zhang
In-Context Learning State Vector with Inner and Momentum Optimization
Apr 17, 2024
Large Language Models (LLMs) have exhibited an impressive ability to perform In-Context Learning (ICL) from only a few examples. Recent works have indicated that the functions learned by ICL can be represented through compressed vectors derived from the transformer. However, the working mechanisms and optimization of these vectors are yet to be thoroughly explored. In this paper, we address this gap by presenting a comprehensive analysis of these compressed vectors, drawing parallels to the parameters trained with gradient descent, and introduce the concept of state vector. Inspired by the works on model soup and momentum-based gradient descent, we propose inner and momentum optimization methods that are applied to refine the state vector progressively as test-time adaptation. Moreover, we simulate state vector aggregation in the multiple example setting, where demonstrations comprising numerous examples are usually too lengthy for regular ICL, and further propose a divide-and-conquer aggregation method to address this challenge. We conduct extensive experiments using Llama-2 and GPT-J in both zero-shot setting and few-shot setting. The experimental results show that our optimization method effectively enhances the state vector and achieves the state-of-the-art performance on diverse tasks. Code is available at https://github.com/HITsz-TMG/ICL-State-Vector
Collaborative-Enhanced Prediction of Spending on Newly Downloaded Mobile Games under Consumption Uncertainty
Apr 12, 2024With the surge in mobile gaming, accurately predicting user spending on newly downloaded games has become paramount for maximizing revenue. However, the inherently unpredictable nature of user behavior poses significant challenges in this endeavor. To address this, we propose a robust model training and evaluation framework aimed at standardizing spending data to mitigate label variance and extremes, ensuring stability in the modeling process. Within this framework, we introduce a collaborative-enhanced model designed to predict user game spending without relying on user IDs, thus ensuring user privacy and enabling seamless online training. Our model adopts a unique approach by separately representing user preferences and game features before merging them as input to the spending prediction module. Through rigorous experimentation, our approach demonstrates notable improvements over production models, achieving a remarkable \textbf{17.11}\% enhancement on offline data and an impressive \textbf{50.65}\% boost in an online A/B test. In summary, our contributions underscore the importance of stable model training frameworks and the efficacy of collaborative-enhanced models in predicting user spending behavior in mobile gaming.
Chinese Sequence Labeling with Semi-Supervised Boundary-Aware Language Model Pre-training
Apr 08, 2024Chinese sequence labeling tasks are heavily reliant on accurate word boundary demarcation. Although current pre-trained language models (PLMs) have achieved substantial gains on these tasks, they rarely explicitly incorporate boundary information into the modeling process. An exception to this is BABERT, which incorporates unsupervised statistical boundary information into Chinese BERT's pre-training objectives. Building upon this approach, we input supervised high-quality boundary information to enhance BABERT's learning, developing a semi-supervised boundary-aware PLM. To assess PLMs' ability to encode boundaries, we introduce a novel ``Boundary Information Metric'' that is both simple and effective. This metric allows comparison of different PLMs without task-specific fine-tuning. Experimental results on Chinese sequence labeling datasets demonstrate that the improved BABERT variant outperforms the vanilla version, not only on these tasks but also more broadly across a range of Chinese natural language understanding tasks. Additionally, our proposed metric offers a convenient and accurate means of evaluating PLMs' boundary awareness.
To Recommend or Not: Recommendability Identification in Conversations with Pre-trained Language Models
Apr 08, 2024Most current recommender systems primarily focus on what to recommend, assuming users always require personalized recommendations. However, with the widely spread of ChatGPT and other chatbots, a more crucial problem in the context of conversational systems is how to minimize user disruption when we provide recommendation services for users. While previous research has extensively explored different user intents in dialogue systems, fewer efforts are made to investigate whether recommendations should be provided. In this paper, we formally define the recommendability identification problem, which aims to determine whether recommendations are necessary in a specific scenario. First, we propose and define the recommendability identification task, which investigates the need for recommendations in the current conversational context. A new dataset is constructed. Subsequently, we discuss and evaluate the feasibility of leveraging pre-trained language models (PLMs) for recommendability identification. Finally, through comparative experiments, we demonstrate that directly employing PLMs with zero-shot results falls short of meeting the task requirements. Besides, fine-tuning or utilizing soft prompt techniques yields comparable results to traditional classification methods. Our work is the first to study recommendability before recommendation and provides preliminary ways to make it a fundamental component of the future recommendation system.
Cross-Domain Audio Deepfake Detection: Dataset and Analysis
Apr 07, 2024Audio deepfake detection (ADD) is essential for preventing the misuse of synthetic voices that may infringe on personal rights and privacy. Recent zero-shot text-to-speech (TTS) models pose higher risks as they can clone voices with a single utterance. However, the existing ADD datasets are outdated, leading to suboptimal generalization of detection models. In this paper, we construct a new cross-domain ADD dataset comprising over 300 hours of speech data that is generated by five advanced zero-shot TTS models. To simulate real-world scenarios, we employ diverse attack methods and audio prompts from different datasets. Experiments show that, through novel attack-augmented training, the Wav2Vec2-large and Whisper-medium models achieve equal error rates of 4.1\% and 6.5\% respectively. Additionally, we demonstrate our models' outstanding few-shot ADD ability by fine-tuning with just one minute of target-domain data. Nonetheless, neural codec compressors greatly affect the detection accuracy, necessitating further research.
Instruction-Driven Game Engines on Large Language Models
Apr 03, 2024The Instruction-Driven Game Engine (IDGE) project aims to democratize game development by enabling a large language model (LLM) to follow free-form game rules and autonomously generate game-play processes. The IDGE allows users to create games by issuing simple natural language instructions, which significantly lowers the barrier for game development. We approach the learning process for IDGEs as a Next State Prediction task, wherein the model autoregressively predicts in-game states given player actions. It is a challenging task because the computation of in-game states must be precise; otherwise, slight errors could disrupt the game-play. To address this, we train the IDGE in a curriculum manner that progressively increases the model's exposure to complex scenarios. Our initial progress lies in developing an IDGE for Poker, a universally cherished card game. The engine we've designed not only supports a wide range of poker variants but also allows for high customization of rules through natural language inputs. Furthermore, it also favors rapid prototyping of new games from minimal samples, proposing an innovative paradigm in game development that relies on minimal prompt and data engineering. This work lays the groundwork for future advancements in instruction-driven game creation, potentially transforming how games are designed and played.
Unifying Qualitative and Quantitative Safety Verification of DNN-Controlled Systems
Apr 02, 2024The rapid advance of deep reinforcement learning techniques enables the oversight of safety-critical systems through the utilization of Deep Neural Networks (DNNs). This underscores the pressing need to promptly establish certified safety guarantees for such DNN-controlled systems. Most of the existing verification approaches rely on qualitative approaches, predominantly employing reachability analysis. However, qualitative verification proves inadequate for DNN-controlled systems as their behaviors exhibit stochastic tendencies when operating in open and adversarial environments. In this paper, we propose a novel framework for unifying both qualitative and quantitative safety verification problems of DNN-controlled systems. This is achieved by formulating the verification tasks as the synthesis of valid neural barrier certificates (NBCs). Initially, the framework seeks to establish almost-sure safety guarantees through qualitative verification. In cases where qualitative verification fails, our quantitative verification method is invoked, yielding precise lower and upper bounds on probabilistic safety across both infinite and finite time horizons. To facilitate the synthesis of NBCs, we introduce their $k$-inductive variants. We also devise a simulation-guided approach for training NBCs, aiming to achieve tightness in computing precise certified lower and upper bounds. We prototype our approach into a tool called $\textsf{UniQQ}$ and showcase its efficacy on four classic DNN-controlled systems.
EEG-SVRec: An EEG Dataset with User Multidimensional Affective Engagement Labels in Short Video Recommendation
Apr 01, 2024In recent years, short video platforms have gained widespread popularity, making the quality of video recommendations crucial for retaining users. Existing recommendation systems primarily rely on behavioral data, which faces limitations when inferring user preferences due to issues such as data sparsity and noise from accidental interactions or personal habits. To address these challenges and provide a more comprehensive understanding of user affective experience and cognitive activity, we propose EEG-SVRec, the first EEG dataset with User Multidimensional Affective Engagement Labels in Short Video Recommendation. The study involves 30 participants and collects 3,657 interactions, offering a rich dataset that can be used for a deeper exploration of user preference and cognitive activity. By incorporating selfassessment techniques and real-time, low-cost EEG signals, we offer a more detailed understanding user affective experiences (valence, arousal, immersion, interest, visual and auditory) and the cognitive mechanisms behind their behavior. We establish benchmarks for rating prediction by the recommendation algorithm, showing significant improvement with the inclusion of EEG signals. Furthermore, we demonstrate the potential of this dataset in gaining insights into the affective experience and cognitive activity behind user behaviors in recommender systems. This work presents a novel perspective for enhancing short video recommendation by leveraging the rich information contained in EEG signals and multidimensional affective engagement scores, paving the way for future research in short video recommendation systems.
Aiming at the Target: Filter Collaborative Information for Cross-Domain Recommendation
Mar 29, 2024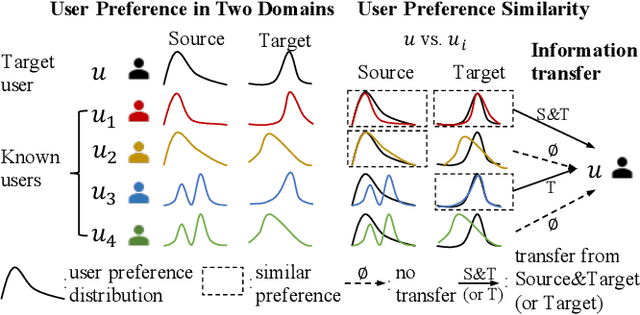
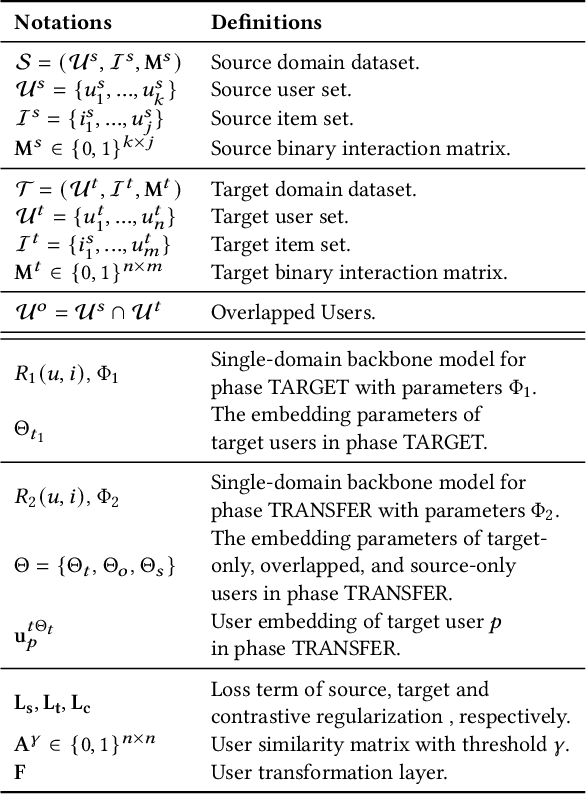
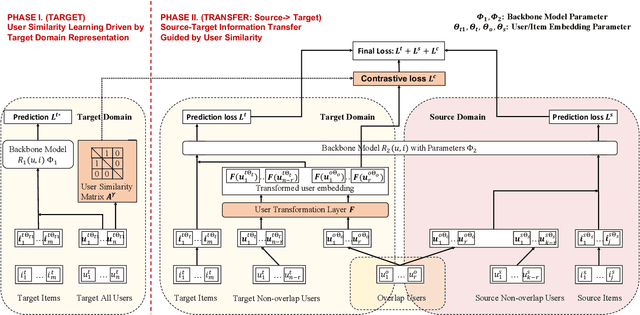
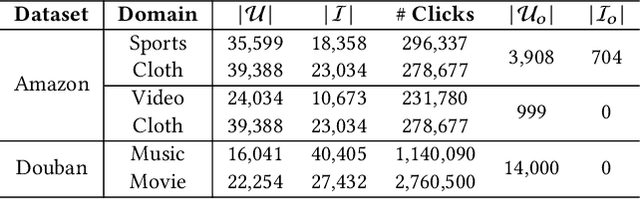
Cross-domain recommender (CDR) systems aim to enhance the performance of the target domain by utilizing data from other related domains. However, irrelevant information from the source domain may instead degrade target domain performance, which is known as the negative transfer problem. There have been some attempts to address this problem, mostly by designing adaptive representations for overlapped users. Whereas, representation adaptions solely rely on the expressive capacity of the CDR model, lacking explicit constraint to filter the irrelevant source-domain collaborative information for the target domain. In this paper, we propose a novel Collaborative information regularized User Transformation (CUT) framework to tackle the negative transfer problem by directly filtering users' collaborative information. In CUT, user similarity in the target domain is adopted as a constraint for user transformation learning to filter the user collaborative information from the source domain. CUT first learns user similarity relationships from the target domain. Then, source-target information transfer is guided by the user similarity, where we design a user transformation layer to learn target-domain user representations and a contrastive loss to supervise the user collaborative information transferred. The results show significant performance improvement of CUT compared with SOTA single and cross-domain methods. Further analysis of the target-domain results illustrates that CUT can effectively alleviate the negative transfer problem.