 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeizhi Ma
To Recommend or Not: Recommendability Identification in Conversations with Pre-trained Language Models
Apr 08, 2024
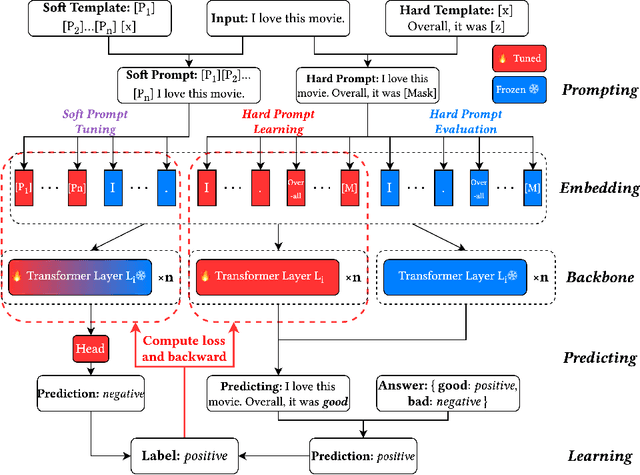


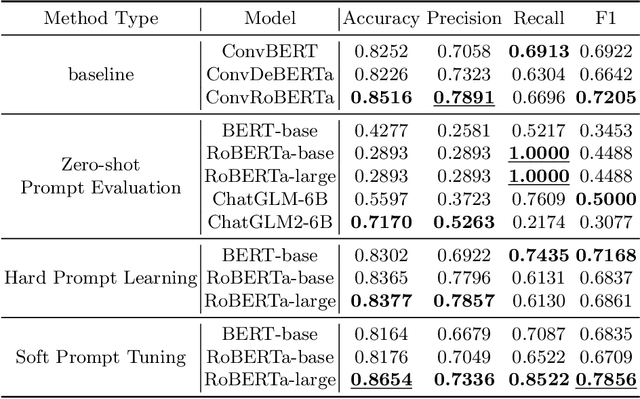
Most current recommender systems primarily focus on what to recommend, assuming users always require personalized recommendations. However, with the widely spread of ChatGPT and other chatbots, a more crucial problem in the context of conversational systems is how to minimize user disruption when we provide recommendation services for users. While previous research has extensively explored different user intents in dialogue systems, fewer efforts are made to investigate whether recommendations should be provided. In this paper, we formally define the recommendability identification problem, which aims to determine whether recommendations are necessary in a specific scenario. First, we propose and define the recommendability identification task, which investigates the need for recommendations in the current conversational context. A new dataset is constructed. Subsequently, we discuss and evaluate the feasibility of leveraging pre-trained language models (PLMs) for recommendability identification. Finally, through comparative experiments, we demonstrate that directly employing PLMs with zero-shot results falls short of meeting the task requirements. Besides, fine-tuning or utilizing soft prompt techniques yields comparable results to traditional classification methods. Our work is the first to study recommendability before recommendation and provides preliminary ways to make it a fundamental component of the future recommendation system.
Aiming at the Target: Filter Collaborative Information for Cross-Domain Recommendation
Mar 29, 2024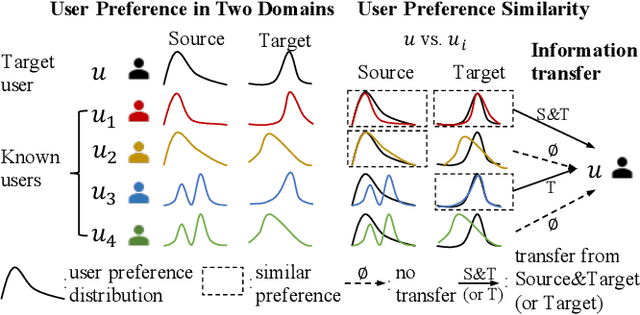
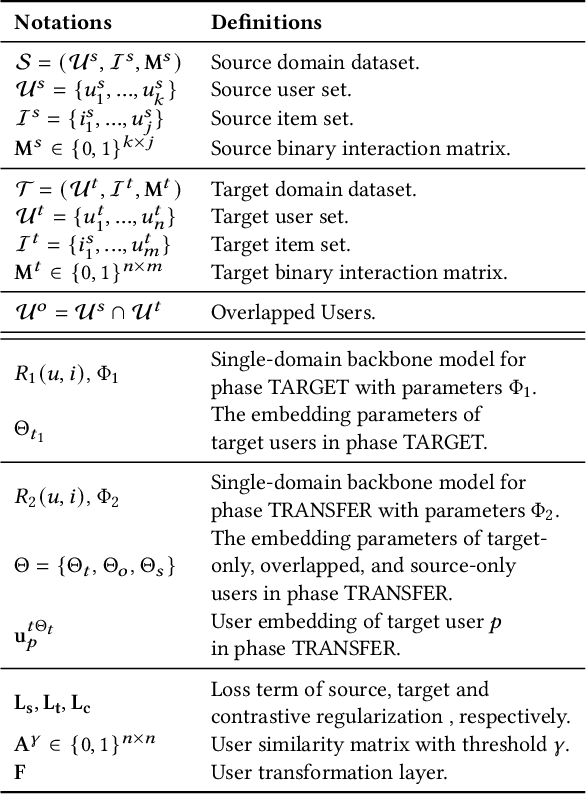
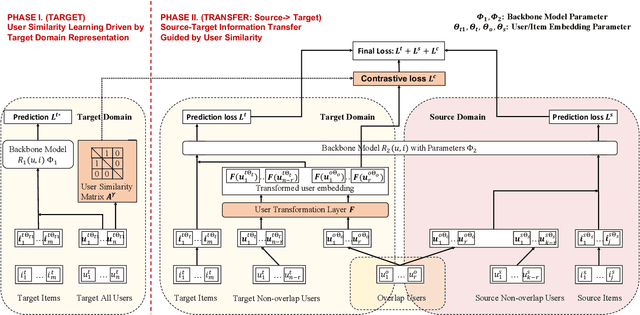
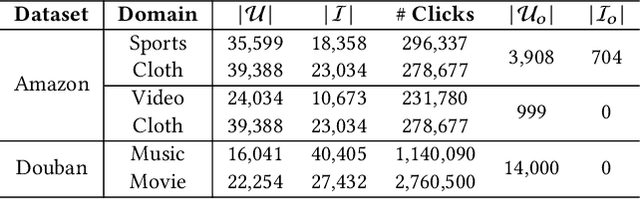
Cross-domain recommender (CDR) systems aim to enhance the performance of the target domain by utilizing data from other related domains. However, irrelevant information from the source domain may instead degrade target domain performance, which is known as the negative transfer problem. There have been some attempts to address this problem, mostly by designing adaptive representations for overlapped users. Whereas, representation adaptions solely rely on the expressive capacity of the CDR model, lacking explicit constraint to filter the irrelevant source-domain collaborative information for the target domain. In this paper, we propose a novel Collaborative information regularized User Transformation (CUT) framework to tackle the negative transfer problem by directly filtering users' collaborative information. In CUT, user similarity in the target domain is adopted as a constraint for user transformation learning to filter the user collaborative information from the source domain. CUT first learns user similarity relationships from the target domain. Then, source-target information transfer is guided by the user similarity, where we design a user transformation layer to learn target-domain user representations and a contrastive loss to supervise the user collaborative information transferred. The results show significant performance improvement of CUT compared with SOTA single and cross-domain methods. Further analysis of the target-domain results illustrates that CUT can effectively alleviate the negative transfer problem.
Sequential Recommendation with Latent Relations based on Large Language Model
Mar 27, 2024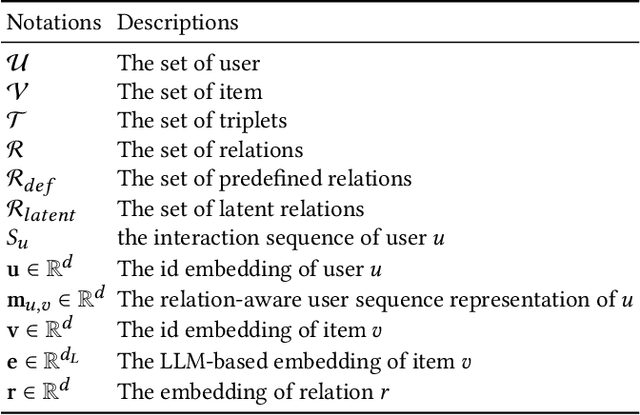
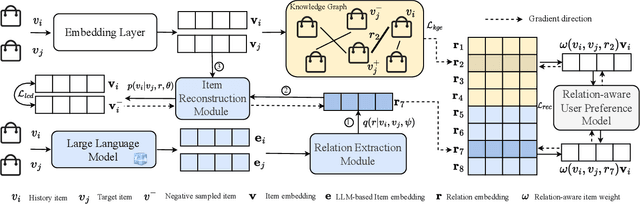
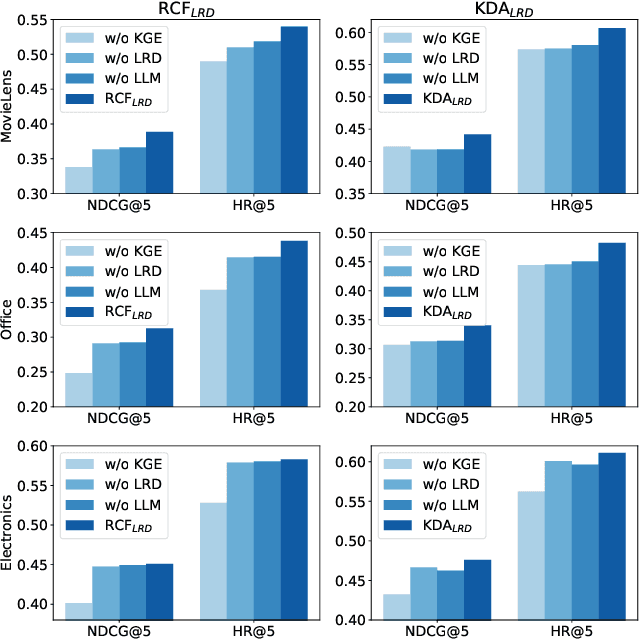
Sequential recommender systems predict items that may interest users by modeling their preferences based on historical interactions. Traditional sequential recommendation methods rely on capturing implicit collaborative filtering signals among items. Recent relation-aware sequential recommendation models have achieved promising performance by explicitly incorporating item relations into the modeling of user historical sequences, where most relations are extracted from knowledge graphs. However, existing methods rely on manually predefined relations and suffer the sparsity issue, limiting the generalization ability in diverse scenarios with varied item relations. In this paper, we propose a novel relation-aware sequential recommendation framework with Latent Relation Discovery (LRD). Different from previous relation-aware models that rely on predefined rules, we propose to leverage the Large Language Model (LLM) to provide new types of relations and connections between items. The motivation is that LLM contains abundant world knowledge, which can be adopted to mine latent relations of items for recommendation. Specifically, inspired by that humans can describe relations between items using natural language, LRD harnesses the LLM that has demonstrated human-like knowledge to obtain language knowledge representations of items. These representations are fed into a latent relation discovery module based on the discrete state variational autoencoder (DVAE). Then the self-supervised relation discovery tasks and recommendation tasks are jointly optimized. Experimental results on multiple public datasets demonstrate our proposed latent relations discovery method can be incorporated with existing relation-aware sequential recommendation models and significantly improve the performance. Further analysis experiments indicate the effectiveness and reliability of the discovered latent relations.
Common Sense Enhanced Knowledge-based Recommendation with Large Language Model
Mar 27, 2024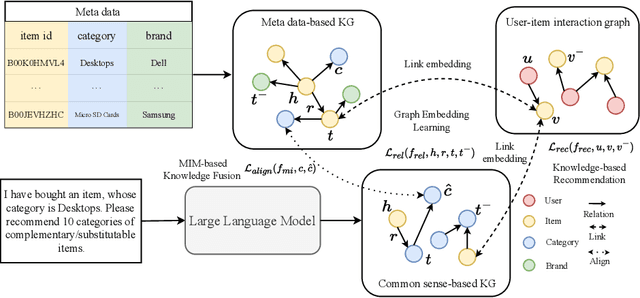


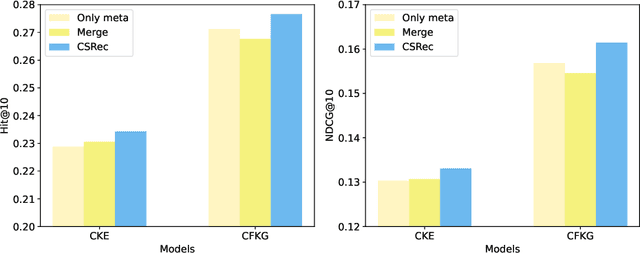
Knowledge-based recommendation models effectively alleviate the data sparsity issue leveraging the side information in the knowledge graph, and have achieved considerable performance. Nevertheless, the knowledge graphs used in previous work, namely metadata-based knowledge graphs, are usually constructed based on the attributes of items and co-occurring relations (e.g., also buy), in which the former provides limited information and the latter relies on sufficient interaction data and still suffers from cold start issue. Common sense, as a form of knowledge with generality and universality, can be used as a supplement to the metadata-based knowledge graph and provides a new perspective for modeling users' preferences. Recently, benefiting from the emergent world knowledge of the large language model, efficient acquisition of common sense has become possible. In this paper, we propose a novel knowledge-based recommendation framework incorporating common sense, CSRec, which can be flexibly coupled to existing knowledge-based methods. Considering the challenge of the knowledge gap between the common sense-based knowledge graph and metadata-based knowledge graph, we propose a knowledge fusion approach based on mutual information maximization theory. Experimental results on public datasets demonstrate that our approach significantly improves the performance of existing knowledge-based recommendation models.
A Situation-aware Enhancer for Personalized Recommendation
Mar 27, 2024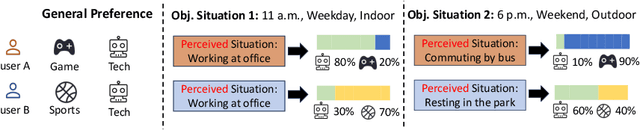
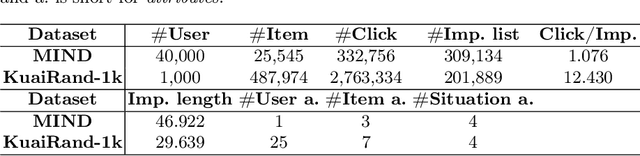
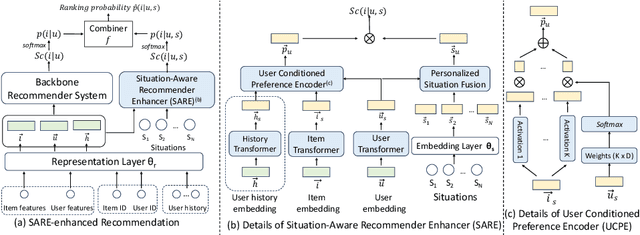
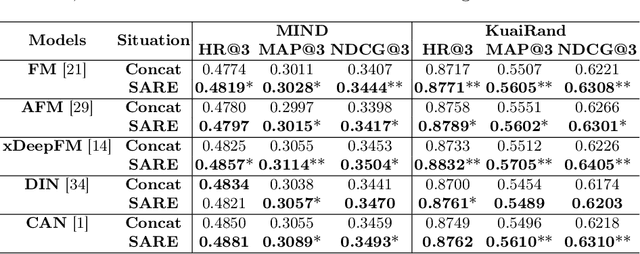
When users interact with Recommender Systems (RecSys), current situations, such as time, location, and environment, significantly influence their preferences. Situations serve as the background for interactions, where relationships between users and items evolve with situation changes. However, existing RecSys treat situations, users, and items on the same level. They can only model the relations between situations and users/items respectively, rather than the dynamic impact of situations on user-item associations (i.e., user preferences). In this paper, we provide a new perspective that takes situations as the preconditions for users' interactions. This perspective allows us to separate situations from user/item representations, and capture situations' influences over the user-item relationship, offering a more comprehensive understanding of situations. Based on it, we propose a novel Situation-Aware Recommender Enhancer (SARE), a pluggable module to integrate situations into various existing RecSys. Since users' perception of situations and situations' impact on preferences are both personalized, SARE includes a Personalized Situation Fusion (PSF) and a User-Conditioned Preference Encoder (UCPE) to model the perception and impact of situations, respectively. We conduct experiments of applying SARE on seven backbones in various settings on two real-world datasets. Experimental results indicate that SARE improves the recommendation performances significantly compared with backbones and SOTA situation-aware baselines.
Citation-Enhanced Generation for LLM-based Chatbots
Mar 04, 2024Large language models (LLMs) exhibit powerful general intelligence across diverse scenarios, including their integration into chatbots. However, a vital challenge of LLM-based chatbots is that they may produce hallucinated content in responses, which significantly limits their applicability. Various efforts have been made to alleviate hallucination, such as retrieval augmented generation and reinforcement learning with human feedback, but most of them require additional training and data annotation. In this paper, we propose a novel post-hoc Citation-Enhanced Generation (CEG) approach combined with retrieval argumentation. Unlike previous studies that focus on preventing hallucinations during generation, our method addresses this issue in a post-hoc way. It incorporates a retrieval module to search for supporting documents relevant to the generated content, and employs a natural language inference-based citation generation module. Once the statements in the generated content lack of reference, our model can regenerate responses until all statements are supported by citations. Note that our method is a training-free plug-and-play plugin that is capable of various LLMs. Experiments on various hallucination-related datasets show our framework outperforms state-of-the-art methods in both hallucination detection and response regeneration on three benchmarks. Our codes and dataset will be publicly available.
EasyRL4Rec: A User-Friendly Code Library for Reinforcement Learning Based Recommender Systems
Feb 23, 2024Reinforcement Learning (RL)-Based Recommender Systems (RSs) are increasingly recognized for their ability to improve long-term user engagement. Yet, the field grapples with challenges such as the absence of accessible frameworks, inconsistent evaluation standards, and the complexity of replicating prior work. Addressing these obstacles, we present EasyRL4Rec, a user-friendly and efficient library tailored for RL-based RSs. EasyRL4Rec features lightweight, diverse RL environments built on five widely-used public datasets, and is equipped with comprehensive core modules that offer rich options to ease the development of models. It establishes consistent evaluation criteria with a focus on long-term impacts and introduces customized solutions for state modeling and action representation tailored to recommender systems. Additionally, we share valuable insights gained from extensive experiments with current methods. EasyRL4Rec aims to facilitate the model development and experimental process in the domain of RL-based RSs. The library is openly accessible at https://github.com/chongminggao/EasyRL4Rec.
Multi-Agent Collaboration Framework for Recommender Systems
Feb 23, 2024LLM-based agents have gained considerable attention for their decision-making skills and ability to handle complex tasks. Recognizing the current gap in leveraging agent capabilities for multi-agent collaboration in recommendation systems, we introduce MACRec, a novel framework designed to enhance recommendation systems through multi-agent collaboration. Unlike existing work on using agents for user/item simulation, we aim to deploy multi-agents to tackle recommendation tasks directly. In our framework, recommendation tasks are addressed through the collaborative efforts of various specialized agents, including Manager, User/Item Analyst, Reflector, Searcher, and Task Interpreter, with different working flows. Furthermore, we provide application examples of how developers can easily use MACRec on various recommendation tasks, including rating prediction, sequential recommendation, conversational recommendation, and explanation generation of recommendation results. The framework and demonstration video are publicly available at https://github.com/wzf2000/MACRec.
Recommender for Its Purpose: Repeat and Exploration in Food Delivery Recommendations
Feb 22, 2024Recommender systems have been widely used for various scenarios, such as e-commerce, news, and music, providing online contents to help and enrich users' daily life. Different scenarios hold distinct and unique characteristics, calling for domain-specific investigations and corresponding designed recommender systems. Therefore, in this paper, we focus on food delivery recommendations to unveil unique features in this domain, where users order food online and enjoy their meals shortly after delivery. We first conduct an in-depth analysis on food delivery datasets. The analysis shows that repeat orders are prevalent for both users and stores, and situations' differently influence repeat and exploration consumption in the food delivery recommender systems. Moreover, we revisit the ability of existing situation-aware methods for repeat and exploration recommendations respectively, and find them unable to effectively solve both tasks simultaneously. Based on the analysis and experiments, we have designed two separate recommendation models -- ReRec for repeat orders and ExpRec for exploration orders; both are simple in their design and computation. We conduct experiments on three real-world food delivery datasets, and our proposed models outperform various types of baselines on repeat, exploration, and combined recommendation tasks. This paper emphasizes the importance of dedicated analyses and methods for domain-specific characteristics for the recommender system studies.
Intersectional Two-sided Fairness in Recommendation
Feb 15, 2024Fairness of recommender systems (RS) has attracted increasing attention recently. Based on the involved stakeholders, the fairness of RS can be divided into user fairness, item fairness, and two-sided fairness which considers both user and item fairness simultaneously. However, we argue that the intersectional two-sided unfairness may still exist even if the RS is two-sided fair, which is observed and shown by empirical studies on real-world data in this paper, and has not been well-studied previously. To mitigate this problem, we propose a novel approach called Intersectional Two-sided Fairness Recommendation (ITFR). Our method utilizes a sharpness-aware loss to perceive disadvantaged groups, and then uses collaborative loss balance to develop consistent distinguishing abilities for different intersectional groups. Additionally, predicted score normalization is leveraged to align positive predicted scores to fairly treat positives in different intersectional groups. Extensive experiments and analyses on three public datasets show that our proposed approach effectively alleviates the intersectional two-sided unfairness and consistently outperforms previous state-of-the-art methods.