 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiqun Liu
Introducing EEG Analyses to Help Personal Music Preference Prediction
Apr 24, 2024
Nowadays, personalized recommender systems play an increasingly important role in music scenarios in our daily life with the preference prediction ability. However, existing methods mainly rely on users' implicit feedback (e.g., click, dwell time) which ignores the detailed user experience. This paper introduces Electroencephalography (EEG) signals to personal music preferences as a basis for the personalized recommender system. To realize collection in daily life, we use a dry-electrodes portable device to collect data. We perform a user study where participants listen to music and record preferences and moods. Meanwhile, EEG signals are collected with a portable device. Analysis of the collected data indicates a significant relationship between music preference, mood, and EEG signals. Furthermore, we conduct experiments to predict personalized music preference with the features of EEG signals. Experiments show significant improvement in rating prediction and preference classification with the help of EEG. Our work demonstrates the possibility of introducing EEG signals in personal music preference with portable devices. Moreover, our approach is not restricted to the music scenario, and the EEG signals as explicit feedback can be used in personalized recommendation tasks.
EEG-SVRec: An EEG Dataset with User Multidimensional Affective Engagement Labels in Short Video Recommendation
Apr 01, 2024In recent years, short video platforms have gained widespread popularity, making the quality of video recommendations crucial for retaining users. Existing recommendation systems primarily rely on behavioral data, which faces limitations when inferring user preferences due to issues such as data sparsity and noise from accidental interactions or personal habits. To address these challenges and provide a more comprehensive understanding of user affective experience and cognitive activity, we propose EEG-SVRec, the first EEG dataset with User Multidimensional Affective Engagement Labels in Short Video Recommendation. The study involves 30 participants and collects 3,657 interactions, offering a rich dataset that can be used for a deeper exploration of user preference and cognitive activity. By incorporating selfassessment techniques and real-time, low-cost EEG signals, we offer a more detailed understanding user affective experiences (valence, arousal, immersion, interest, visual and auditory) and the cognitive mechanisms behind their behavior. We establish benchmarks for rating prediction by the recommendation algorithm, showing significant improvement with the inclusion of EEG signals. Furthermore, we demonstrate the potential of this dataset in gaining insights into the affective experience and cognitive activity behind user behaviors in recommender systems. This work presents a novel perspective for enhancing short video recommendation by leveraging the rich information contained in EEG signals and multidimensional affective engagement scores, paving the way for future research in short video recommendation systems.
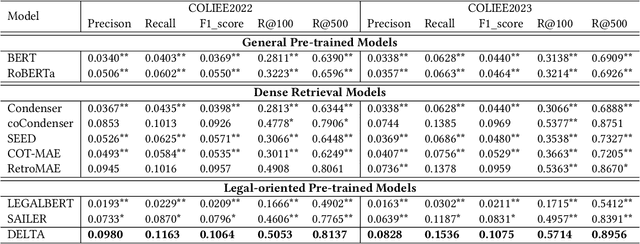
Towards an In-Depth Comprehension of Case Relevance for Better Legal Retrieval
Apr 01, 2024Legal retrieval techniques play an important role in preserving the fairness and equality of the judicial system. As an annually well-known international competition, COLIEE aims to advance the development of state-of-the-art retrieval models for legal texts. This paper elaborates on the methodology employed by the TQM team in COLIEE2024.Specifically, we explored various lexical matching and semantic retrieval models, with a focus on enhancing the understanding of case relevance. Additionally, we endeavor to integrate various features using the learning-to-rank technique. Furthermore, fine heuristic pre-processing and post-processing methods have been proposed to mitigate irrelevant information. Consequently, our methodology achieved remarkable performance in COLIEE2024, securing first place in Task 1 and third place in Task 3. We anticipate that our proposed approach can contribute valuable insights to the advancement of legal retrieval technology.
Scaling Laws For Dense Retrieval
Mar 27, 2024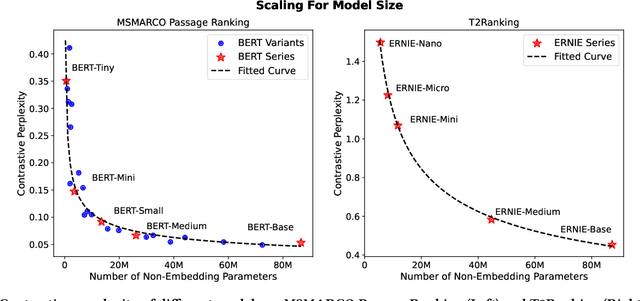

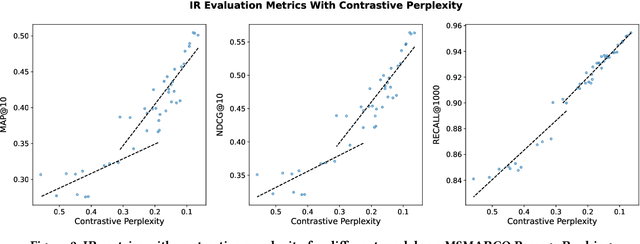

Scaling up neural models has yielded significant advancements in a wide array of tasks, particularly in language generation. Previous studies have found that the performance of neural models frequently adheres to predictable scaling laws, correlated with factors such as training set size and model size. This insight is invaluable, especially as large-scale experiments grow increasingly resource-intensive. Yet, such scaling law has not been fully explored in dense retrieval due to the discrete nature of retrieval metrics and complex relationships between training data and model sizes in retrieval tasks. In this study, we investigate whether the performance of dense retrieval models follows the scaling law as other neural models. We propose to use contrastive log-likelihood as the evaluation metric and conduct extensive experiments with dense retrieval models implemented with different numbers of parameters and trained with different amounts of annotated data. Results indicate that, under our settings, the performance of dense retrieval models follows a precise power-law scaling related to the model size and the number of annotations. Additionally, we examine scaling with prevalent data augmentation methods to assess the impact of annotation quality, and apply the scaling law to find the best resource allocation strategy under a budget constraint. We believe that these insights will significantly contribute to understanding the scaling effect of dense retrieval models and offer meaningful guidance for future research endeavors.
Sequential Recommendation with Latent Relations based on Large Language Model
Mar 27, 2024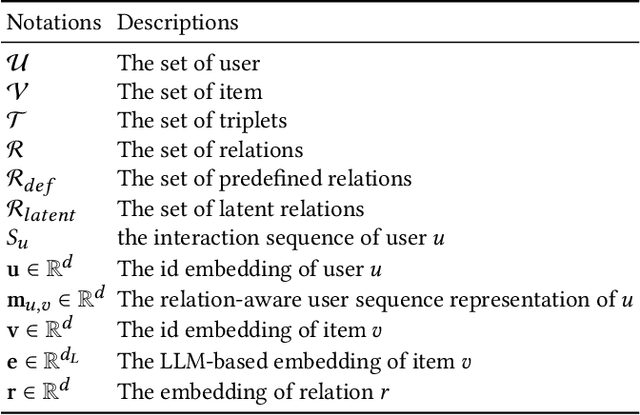
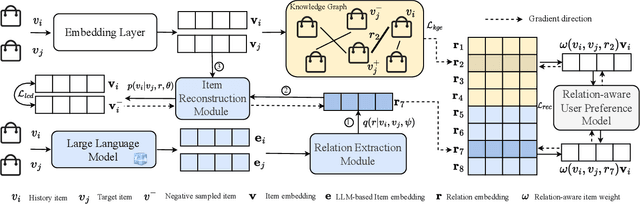
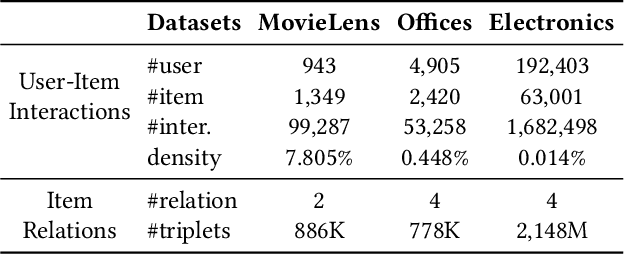
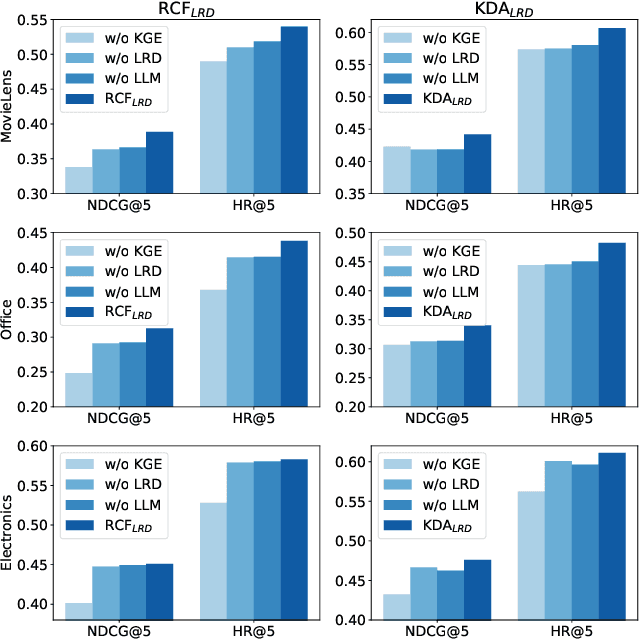
Sequential recommender systems predict items that may interest users by modeling their preferences based on historical interactions. Traditional sequential recommendation methods rely on capturing implicit collaborative filtering signals among items. Recent relation-aware sequential recommendation models have achieved promising performance by explicitly incorporating item relations into the modeling of user historical sequences, where most relations are extracted from knowledge graphs. However, existing methods rely on manually predefined relations and suffer the sparsity issue, limiting the generalization ability in diverse scenarios with varied item relations. In this paper, we propose a novel relation-aware sequential recommendation framework with Latent Relation Discovery (LRD). Different from previous relation-aware models that rely on predefined rules, we propose to leverage the Large Language Model (LLM) to provide new types of relations and connections between items. The motivation is that LLM contains abundant world knowledge, which can be adopted to mine latent relations of items for recommendation. Specifically, inspired by that humans can describe relations between items using natural language, LRD harnesses the LLM that has demonstrated human-like knowledge to obtain language knowledge representations of items. These representations are fed into a latent relation discovery module based on the discrete state variational autoencoder (DVAE). Then the self-supervised relation discovery tasks and recommendation tasks are jointly optimized. Experimental results on multiple public datasets demonstrate our proposed latent relations discovery method can be incorporated with existing relation-aware sequential recommendation models and significantly improve the performance. Further analysis experiments indicate the effectiveness and reliability of the discovered latent relations.
Common Sense Enhanced Knowledge-based Recommendation with Large Language Model
Mar 27, 2024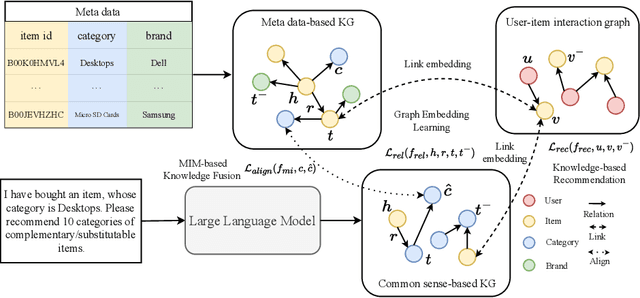


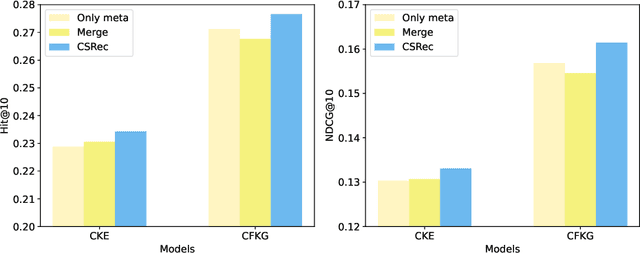
Knowledge-based recommendation models effectively alleviate the data sparsity issue leveraging the side information in the knowledge graph, and have achieved considerable performance. Nevertheless, the knowledge graphs used in previous work, namely metadata-based knowledge graphs, are usually constructed based on the attributes of items and co-occurring relations (e.g., also buy), in which the former provides limited information and the latter relies on sufficient interaction data and still suffers from cold start issue. Common sense, as a form of knowledge with generality and universality, can be used as a supplement to the metadata-based knowledge graph and provides a new perspective for modeling users' preferences. Recently, benefiting from the emergent world knowledge of the large language model, efficient acquisition of common sense has become possible. In this paper, we propose a novel knowledge-based recommendation framework incorporating common sense, CSRec, which can be flexibly coupled to existing knowledge-based methods. Considering the challenge of the knowledge gap between the common sense-based knowledge graph and metadata-based knowledge graph, we propose a knowledge fusion approach based on mutual information maximization theory. Experimental results on public datasets demonstrate that our approach significantly improves the performance of existing knowledge-based recommendation models.
BLADE: Enhancing Black-box Large Language Models with Small Domain-Specific Models
Mar 27, 2024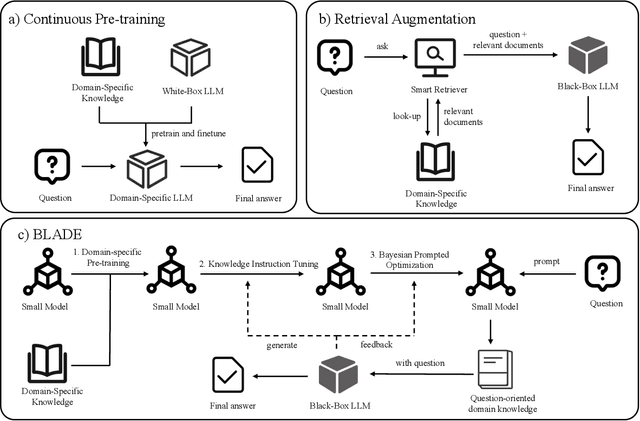
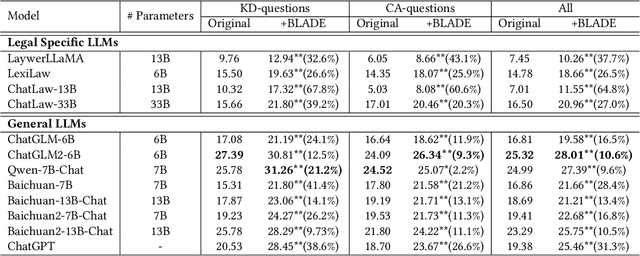
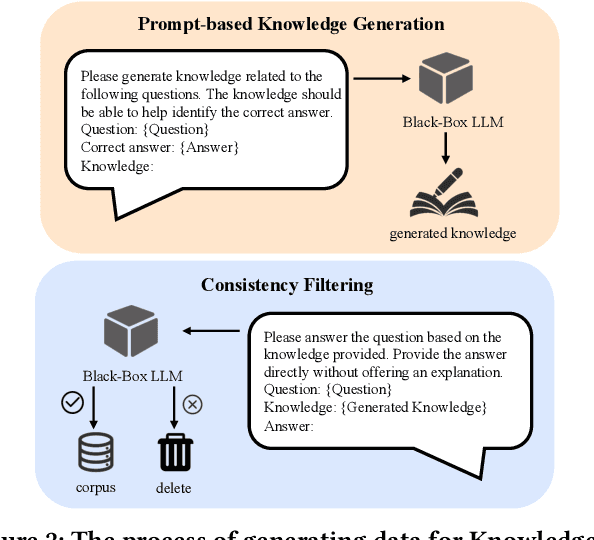
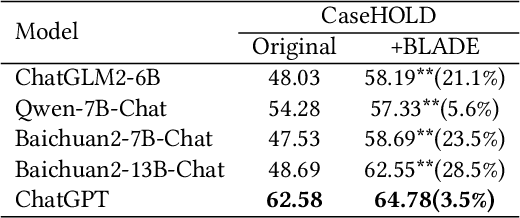
Large Language Models (LLMs) like ChatGPT and GPT-4 are versatile and capable of addressing a diverse range of tasks. However, general LLMs, which are developed on open-domain data, may lack the domain-specific knowledge essential for tasks in vertical domains, such as legal, medical, etc. To address this issue, previous approaches either conduct continuous pre-training with domain-specific data or employ retrieval augmentation to support general LLMs. Unfortunately, these strategies are either cost-intensive or unreliable in practical applications. To this end, we present a novel framework named BLADE, which enhances Black-box LArge language models with small Domain-spEcific models. BLADE consists of a black-box LLM and a small domain-specific LM. The small LM preserves domain-specific knowledge and offers specialized insights, while the general LLM contributes robust language comprehension and reasoning capabilities. Specifically, our method involves three steps: 1) pre-training the small LM with domain-specific data, 2) fine-tuning this model using knowledge instruction data, and 3) joint Bayesian optimization of the general LLM and the small LM. Extensive experiments conducted on public legal and medical benchmarks reveal that BLADE significantly outperforms existing approaches. This shows the potential of BLADE as an effective and cost-efficient solution in adapting general LLMs for vertical domains.
DELTA: Pre-train a Discriminative Encoder for Legal Case Retrieval via Structural Word Alignment
Mar 27, 2024
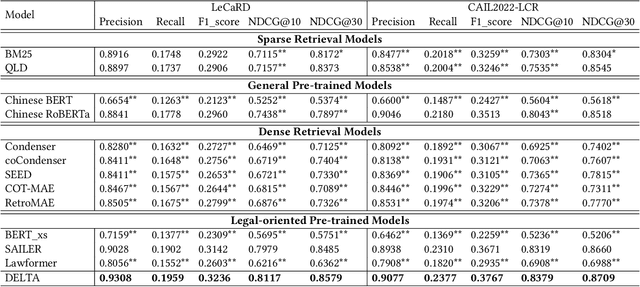
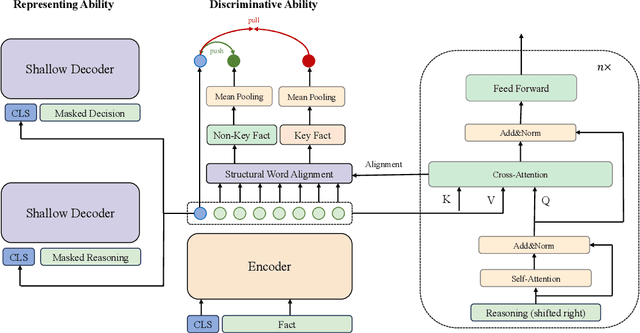
Recent research demonstrates the effectiveness of using pre-trained language models for legal case retrieval. Most of the existing works focus on improving the representation ability for the contextualized embedding of the [CLS] token and calculate relevance using textual semantic similarity. However, in the legal domain, textual semantic similarity does not always imply that the cases are relevant enough. Instead, relevance in legal cases primarily depends on the similarity of key facts that impact the final judgment. Without proper treatments, the discriminative ability of learned representations could be limited since legal cases are lengthy and contain numerous non-key facts. To this end, we introduce DELTA, a discriminative model designed for legal case retrieval. The basic idea involves pinpointing key facts in legal cases and pulling the contextualized embedding of the [CLS] token closer to the key facts while pushing away from the non-key facts, which can warm up the case embedding space in an unsupervised manner. To be specific, this study brings the word alignment mechanism to the contextual masked auto-encoder. First, we leverage shallow decoders to create information bottlenecks, aiming to enhance the representation ability. Second, we employ the deep decoder to enable translation between different structures, with the goal of pinpointing key facts to enhance discriminative ability. Comprehensive experiments conducted on publicly available legal benchmarks show that our approach can outperform existing state-of-the-art methods in legal case retrieval. It provides a new perspective on the in-depth understanding and processing of legal case documents.
Capability-aware Prompt Reformulation Learning for Text-to-Image Generation
Mar 27, 2024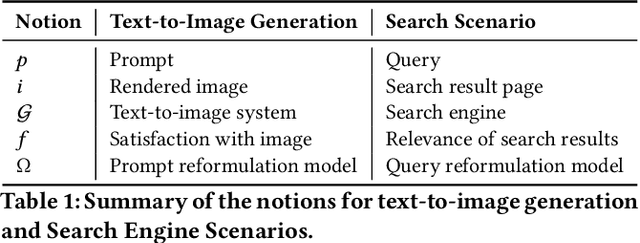
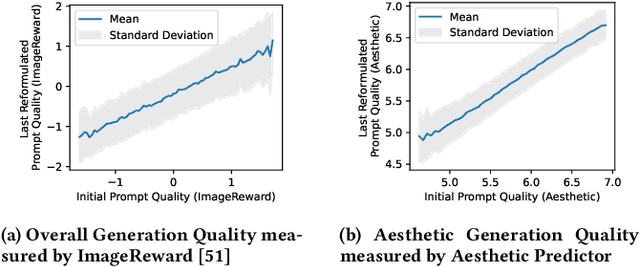
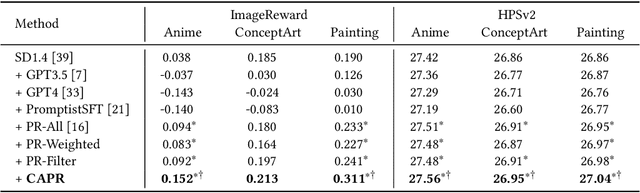
Text-to-image generation systems have emerged as revolutionary tools in the realm of artistic creation, offering unprecedented ease in transforming textual prompts into visual art. However, the efficacy of these systems is intricately linked to the quality of user-provided prompts, which often poses a challenge to users unfamiliar with prompt crafting. This paper addresses this challenge by leveraging user reformulation data from interaction logs to develop an automatic prompt reformulation model. Our in-depth analysis of these logs reveals that user prompt reformulation is heavily dependent on the individual user's capability, resulting in significant variance in the quality of reformulation pairs. To effectively use this data for training, we introduce the Capability-aware Prompt Reformulation (CAPR) framework. CAPR innovatively integrates user capability into the reformulation process through two key components: the Conditional Reformulation Model (CRM) and Configurable Capability Features (CCF). CRM reformulates prompts according to a specified user capability, as represented by CCF. The CCF, in turn, offers the flexibility to tune and guide the CRM's behavior. This enables CAPR to effectively learn diverse reformulation strategies across various user capacities and to simulate high-capability user reformulation during inference. Extensive experiments on standard text-to-image generation benchmarks showcase CAPR's superior performance over existing baselines and its remarkable robustness on unseen systems. Furthermore, comprehensive analyses validate the effectiveness of different components. CAPR can facilitate user-friendly interaction with text-to-image systems and make advanced artistic creation more achievable for a broader range of users.
Improving Legal Case Retrieval with Brain Signals
Mar 20, 2024
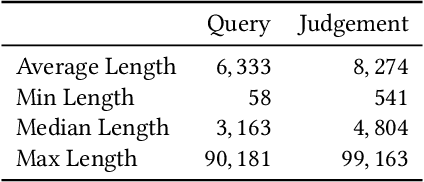
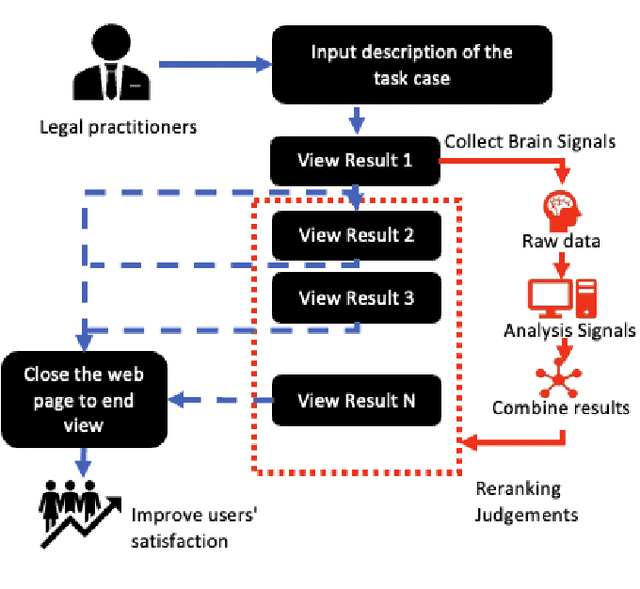
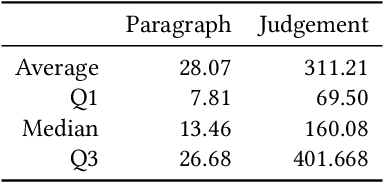
The tasks of legal case retrieval have received growing attention from the IR community in the last decade. Relevance feedback techniques with implicit user feedback (e.g., clicks) have been demonstrated to be effective in traditional search tasks (e.g., Web search). In legal case retrieval, however, collecting relevance feedback faces a couple of challenges that are difficult to resolve under existing feedback paradigms. First, legal case retrieval is a complex task as users often need to understand the relationship between legal cases in detail to correctly judge their relevance. Traditional feedback signal such as clicks is too coarse to use as they do not reflect any fine-grained relevance information. Second, legal case documents are usually long, users often need even tens of minutes to read and understand them. Simple behavior signal such as clicks and eye-tracking fixations can hardly be useful when users almost click and examine every part of the document. In this paper, we explore the possibility of solving the feedback problem in legal case retrieval with brain signal. Recent advances in brain signal processing have shown that human emotional can be collected in fine grains through Brain-Machine Interfaces (BMI) without interrupting the users in their tasks. Therefore, we propose a framework for legal case retrieval that uses EEG signal to optimize retrieval results. We collected and create a legal case retrieval dataset with users EEG signal and propose several methods to extract effective EEG features for relevance feedback. Our proposed features achieve a 71% accuracy for feedback prediction with an SVM-RFE model, and our proposed ranking method that takes into account the diverse needs of users can significantly improve user satisfaction for legal case retrieval. Experiment results show that re-ranked result list make user more satisfied.