 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJia Chen
Resistive Memory-based Neural Differential Equation Solver for Score-based Diffusion Model
Apr 08, 2024
Human brains image complicated scenes when reading a novel. Replicating this imagination is one of the ultimate goals of AI-Generated Content (AIGC). However, current AIGC methods, such as score-based diffusion, are still deficient in terms of rapidity and efficiency. This deficiency is rooted in the difference between the brain and digital computers. Digital computers have physically separated storage and processing units, resulting in frequent data transfers during iterative calculations, incurring large time and energy overheads. This issue is further intensified by the conversion of inherently continuous and analog generation dynamics, which can be formulated by neural differential equations, into discrete and digital operations. Inspired by the brain, we propose a time-continuous and analog in-memory neural differential equation solver for score-based diffusion, employing emerging resistive memory. The integration of storage and computation within resistive memory synapses surmount the von Neumann bottleneck, benefiting the generative speed and energy efficiency. The closed-loop feedback integrator is time-continuous, analog, and compact, physically implementing an infinite-depth neural network. Moreover, the software-hardware co-design is intrinsically robust to analog noise. We experimentally validate our solution with 180 nm resistive memory in-memory computing macros. Demonstrating equivalent generative quality to the software baseline, our system achieved remarkable enhancements in generative speed for both unconditional and conditional generation tasks, by factors of 64.8 and 156.5, respectively. Moreover, it accomplished reductions in energy consumption by factors of 5.2 and 4.1. Our approach heralds a new horizon for hardware solutions in edge computing for generative AI applications.
Capability-aware Prompt Reformulation Learning for Text-to-Image Generation
Mar 27, 2024
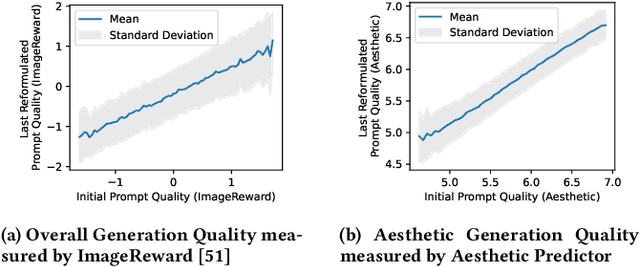
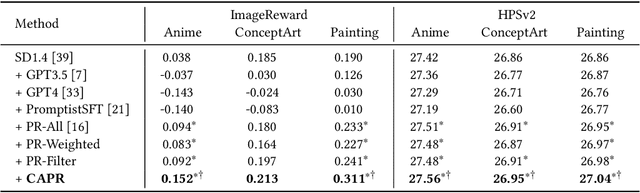
Text-to-image generation systems have emerged as revolutionary tools in the realm of artistic creation, offering unprecedented ease in transforming textual prompts into visual art. However, the efficacy of these systems is intricately linked to the quality of user-provided prompts, which often poses a challenge to users unfamiliar with prompt crafting. This paper addresses this challenge by leveraging user reformulation data from interaction logs to develop an automatic prompt reformulation model. Our in-depth analysis of these logs reveals that user prompt reformulation is heavily dependent on the individual user's capability, resulting in significant variance in the quality of reformulation pairs. To effectively use this data for training, we introduce the Capability-aware Prompt Reformulation (CAPR) framework. CAPR innovatively integrates user capability into the reformulation process through two key components: the Conditional Reformulation Model (CRM) and Configurable Capability Features (CCF). CRM reformulates prompts according to a specified user capability, as represented by CCF. The CCF, in turn, offers the flexibility to tune and guide the CRM's behavior. This enables CAPR to effectively learn diverse reformulation strategies across various user capacities and to simulate high-capability user reformulation during inference. Extensive experiments on standard text-to-image generation benchmarks showcase CAPR's superior performance over existing baselines and its remarkable robustness on unseen systems. Furthermore, comprehensive analyses validate the effectiveness of different components. CAPR can facilitate user-friendly interaction with text-to-image systems and make advanced artistic creation more achievable for a broader range of users.
DELTA: Pre-train a Discriminative Encoder for Legal Case Retrieval via Structural Word Alignment
Mar 27, 2024
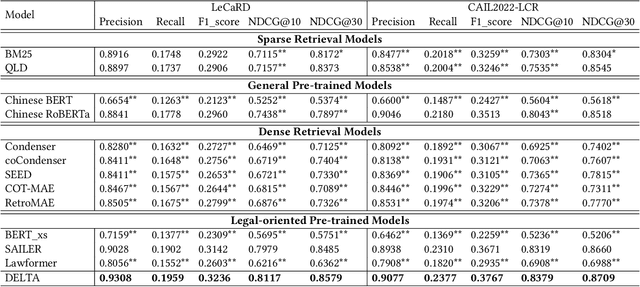
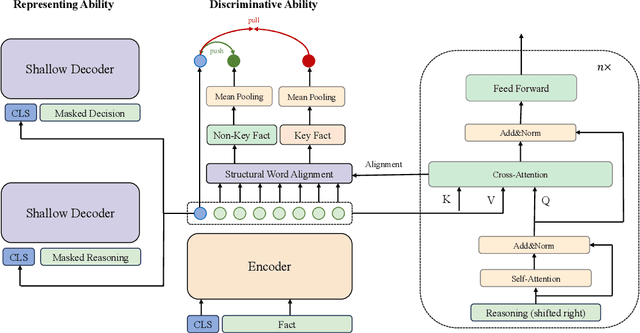
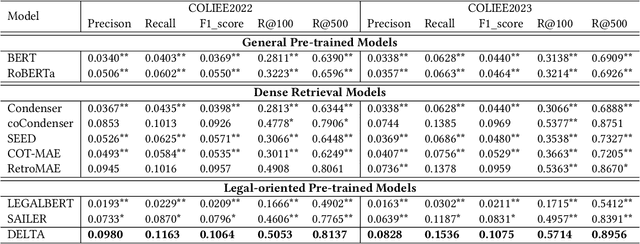
Recent research demonstrates the effectiveness of using pre-trained language models for legal case retrieval. Most of the existing works focus on improving the representation ability for the contextualized embedding of the [CLS] token and calculate relevance using textual semantic similarity. However, in the legal domain, textual semantic similarity does not always imply that the cases are relevant enough. Instead, relevance in legal cases primarily depends on the similarity of key facts that impact the final judgment. Without proper treatments, the discriminative ability of learned representations could be limited since legal cases are lengthy and contain numerous non-key facts. To this end, we introduce DELTA, a discriminative model designed for legal case retrieval. The basic idea involves pinpointing key facts in legal cases and pulling the contextualized embedding of the [CLS] token closer to the key facts while pushing away from the non-key facts, which can warm up the case embedding space in an unsupervised manner. To be specific, this study brings the word alignment mechanism to the contextual masked auto-encoder. First, we leverage shallow decoders to create information bottlenecks, aiming to enhance the representation ability. Second, we employ the deep decoder to enable translation between different structures, with the goal of pinpointing key facts to enhance discriminative ability. Comprehensive experiments conducted on publicly available legal benchmarks show that our approach can outperform existing state-of-the-art methods in legal case retrieval. It provides a new perspective on the in-depth understanding and processing of legal case documents.
BLADE: Enhancing Black-box Large Language Models with Small Domain-Specific Models
Mar 27, 2024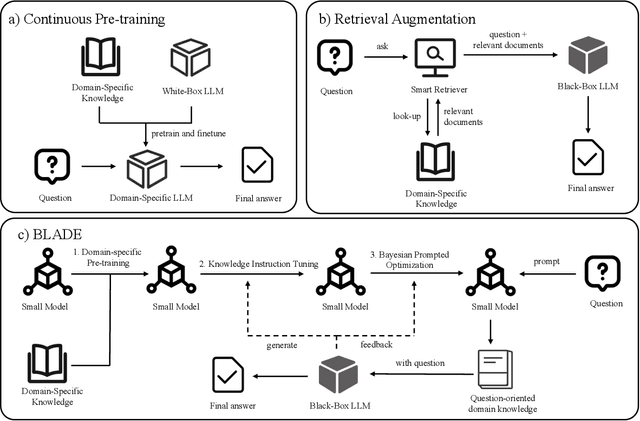
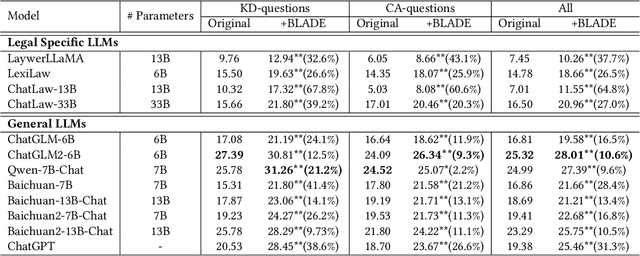
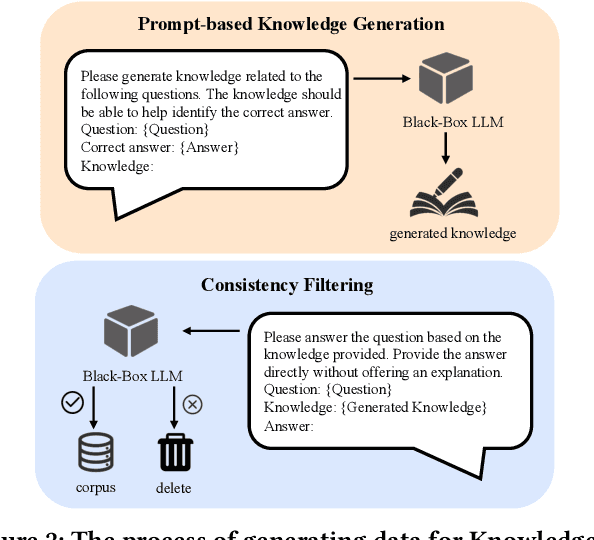
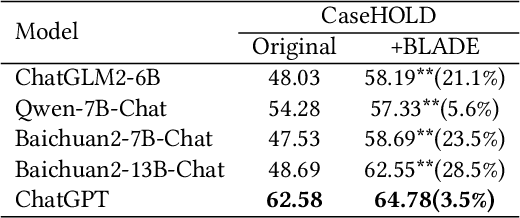
Large Language Models (LLMs) like ChatGPT and GPT-4 are versatile and capable of addressing a diverse range of tasks. However, general LLMs, which are developed on open-domain data, may lack the domain-specific knowledge essential for tasks in vertical domains, such as legal, medical, etc. To address this issue, previous approaches either conduct continuous pre-training with domain-specific data or employ retrieval augmentation to support general LLMs. Unfortunately, these strategies are either cost-intensive or unreliable in practical applications. To this end, we present a novel framework named BLADE, which enhances Black-box LArge language models with small Domain-spEcific models. BLADE consists of a black-box LLM and a small domain-specific LM. The small LM preserves domain-specific knowledge and offers specialized insights, while the general LLM contributes robust language comprehension and reasoning capabilities. Specifically, our method involves three steps: 1) pre-training the small LM with domain-specific data, 2) fine-tuning this model using knowledge instruction data, and 3) joint Bayesian optimization of the general LLM and the small LM. Extensive experiments conducted on public legal and medical benchmarks reveal that BLADE significantly outperforms existing approaches. This shows the potential of BLADE as an effective and cost-efficient solution in adapting general LLMs for vertical domains.
Scaling Laws For Dense Retrieval
Mar 27, 2024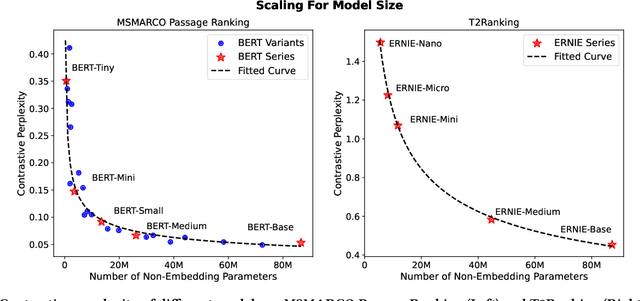

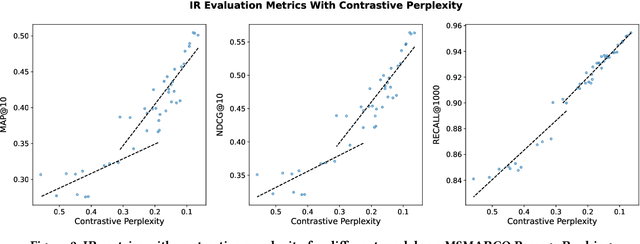

Scaling up neural models has yielded significant advancements in a wide array of tasks, particularly in language generation. Previous studies have found that the performance of neural models frequently adheres to predictable scaling laws, correlated with factors such as training set size and model size. This insight is invaluable, especially as large-scale experiments grow increasingly resource-intensive. Yet, such scaling law has not been fully explored in dense retrieval due to the discrete nature of retrieval metrics and complex relationships between training data and model sizes in retrieval tasks. In this study, we investigate whether the performance of dense retrieval models follows the scaling law as other neural models. We propose to use contrastive log-likelihood as the evaluation metric and conduct extensive experiments with dense retrieval models implemented with different numbers of parameters and trained with different amounts of annotated data. Results indicate that, under our settings, the performance of dense retrieval models follows a precise power-law scaling related to the model size and the number of annotations. Additionally, we examine scaling with prevalent data augmentation methods to assess the impact of annotation quality, and apply the scaling law to find the best resource allocation strategy under a budget constraint. We believe that these insights will significantly contribute to understanding the scaling effect of dense retrieval models and offer meaningful guidance for future research endeavors.
Wikiformer: Pre-training with Structured Information of Wikipedia for Ad-hoc Retrieval
Jan 01, 2024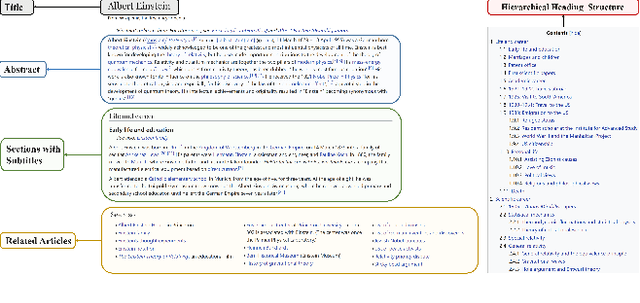
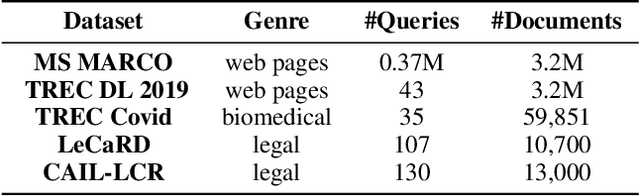

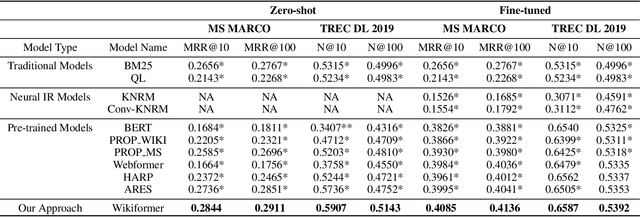
With the development of deep learning and natural language processing techniques, pre-trained language models have been widely used to solve information retrieval (IR) problems. Benefiting from the pre-training and fine-tuning paradigm, these models achieve state-of-the-art performance. In previous works, plain texts in Wikipedia have been widely used in the pre-training stage. However, the rich structured information in Wikipedia, such as the titles, abstracts, hierarchical heading (multi-level title) structure, relationship between articles, references, hyperlink structures, and the writing organizations, has not been fully explored. In this paper, we devise four pre-training objectives tailored for IR tasks based on the structured knowledge of Wikipedia. Compared to existing pre-training methods, our approach can better capture the semantic knowledge in the training corpus by leveraging the human-edited structured data from Wikipedia. Experimental results on multiple IR benchmark datasets show the superior performance of our model in both zero-shot and fine-tuning settings compared to existing strong retrieval baselines. Besides, experimental results in biomedical and legal domains demonstrate that our approach achieves better performance in vertical domains compared to previous models, especially in scenarios where long text similarity matching is needed.
Random resistive memory-based deep extreme point learning machine for unified visual processing
Dec 14, 2023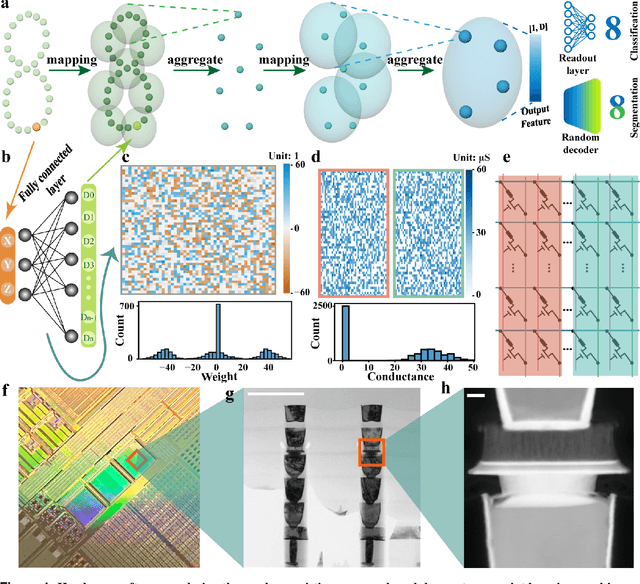
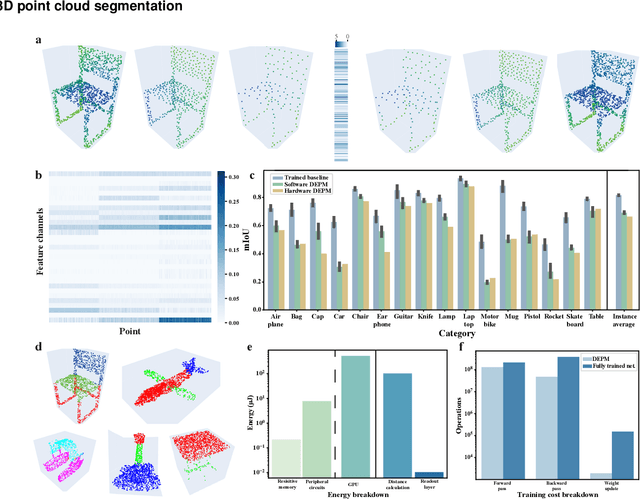
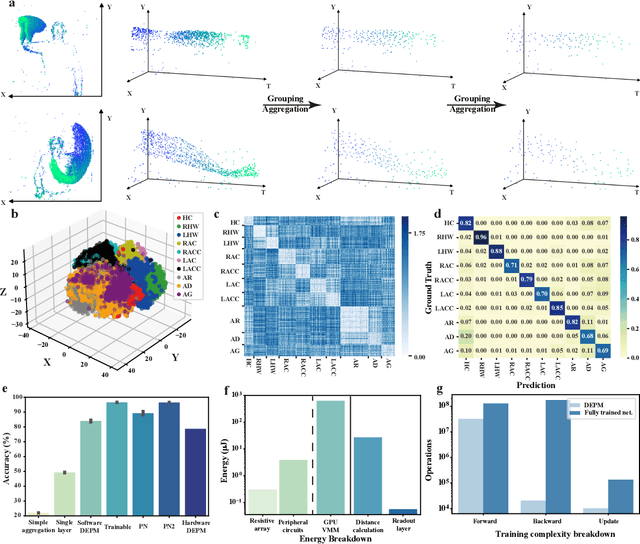
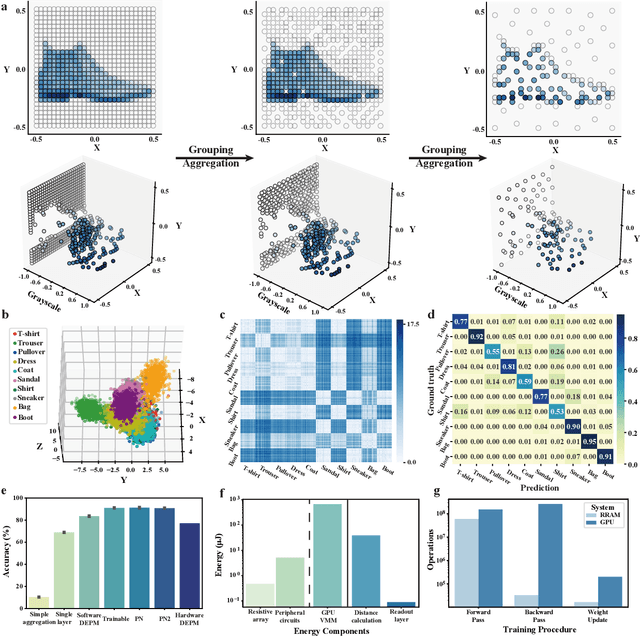
Visual sensors, including 3D LiDAR, neuromorphic DVS sensors, and conventional frame cameras, are increasingly integrated into edge-side intelligent machines. Realizing intensive multi-sensory data analysis directly on edge intelligent machines is crucial for numerous emerging edge applications, such as augmented and virtual reality and unmanned aerial vehicles, which necessitates unified data representation, unprecedented hardware energy efficiency and rapid model training. However, multi-sensory data are intrinsically heterogeneous, causing significant complexity in the system development for edge-side intelligent machines. In addition, the performance of conventional digital hardware is limited by the physically separated processing and memory units, known as the von Neumann bottleneck, and the physical limit of transistor scaling, which contributes to the slowdown of Moore's law. These limitations are further intensified by the tedious training of models with ever-increasing sizes. We propose a novel hardware-software co-design, random resistive memory-based deep extreme point learning machine (DEPLM), that offers efficient unified point set analysis. We show the system's versatility across various data modalities and two different learning tasks. Compared to a conventional digital hardware-based system, our co-design system achieves huge energy efficiency improvements and training cost reduction when compared to conventional systems. Our random resistive memory-based deep extreme point learning machine may pave the way for energy-efficient and training-friendly edge AI across various data modalities and tasks.
Towards Aligned Canonical Correlation Analysis: Preliminary Formulation and Proof-of-Concept Results
Dec 08, 2023Canonical Correlation Analysis (CCA) has been widely applied to jointly embed multiple views of data in a maximally correlated latent space. However, the alignment between various data perspectives, which is required by traditional approaches, is unclear in many practical cases. In this work we propose a new framework Aligned Canonical Correlation Analysis (ACCA), to address this challenge by iteratively solving the alignment and multi-view embedding.
Can SAM recognize crops? Quantifying the zero-shot performance of a semantic segmentation foundation model on generating crop-type maps using satellite imagery for precision agriculture
Dec 04, 2023Climate change is increasingly disrupting worldwide agriculture, making global food production less reliable. To tackle the growing challenges in feeding the planet, cutting-edge management strategies, such as precision agriculture, empower farmers and decision-makers with rich and actionable information to increase the efficiency and sustainability of their farming practices. Crop-type maps are key information for decision-support tools but are challenging and costly to generate. We investigate the capabilities of Meta AI's Segment Anything Model (SAM) for crop-map prediction task, acknowledging its recent successes at zero-shot image segmentation. However, SAM being limited to up-to 3 channel inputs and its zero-shot usage being class-agnostic in nature pose unique challenges in using it directly for crop-type mapping. We propose using clustering consensus metrics to assess SAM's zero-shot performance in segmenting satellite imagery and producing crop-type maps. Although direct crop-type mapping is challenging using SAM in zero-shot setting, experiments reveal SAM's potential for swiftly and accurately outlining fields in satellite images, serving as a foundation for subsequent crop classification. This paper attempts to highlight a use-case of state-of-the-art image segmentation models like SAM for crop-type mapping and related specific needs of the agriculture industry, offering a potential avenue for automatic, efficient, and cost-effective data products for precision agriculture practices.
THUIR at WSDM Cup 2023 Task 1: Unbiased Learning to Rank
Apr 25, 2023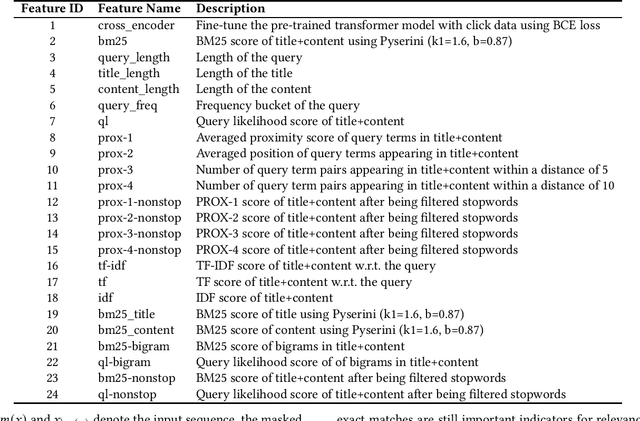
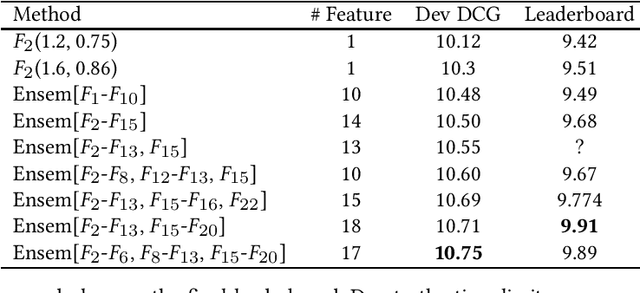
This paper introduces the approaches we have used to participate in the WSDM Cup 2023 Task 1: Unbiased Learning to Rank. In brief, we have attempted a combination of both traditional IR models and transformer-based cross-encoder architectures. To further enhance the ranking performance, we also considered a series of features for learning to rank. As a result, we won 2nd place on the final leaderboard.