 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQian Chen
Study on the static detection of ICF target based on muonic X-ray sphere encoded imaging
Apr 18, 2024
Muon Induced X-ray Emission (MIXE) was discovered by Chinese physicist Zhang Wenyu as early as 1947, and it can conduct non-destructive elemental analysis inside samples. Research has shown that MIXE can retain the high efficiency of direct imaging while benefiting from the low noise of pinhole imaging through encoding holes. The related technology significantly improves the counting rate while maintaining imaging quality. The sphere encoding technology effectively solves the imaging blurring caused by the tilting of the encoding system, and successfully images micrometer sized X-ray sources. This paper will combine MIXE and X-ray sphere coding imaging techniques, including ball coding and zone plates, to study the method of non-destructive deep structure imaging of ICF targets and obtaining sub element distribution. This method aims to develop a new method for ICF target detection, which is particularly important for inertial confinement fusion. At the same time, this method can be used to detect and analyze materials that are difficult to penetrate or sensitive, and is expected to solve the problem of element resolution and imaging that traditional technologies cannot overcome. It will provide new methods for the future development of multiple fields such as particle physics, material science, and X-ray optics.
3D-Speaker-Toolkit: An Open Source Toolkit for Multi-modal Speaker Verification and Diarization
Mar 29, 2024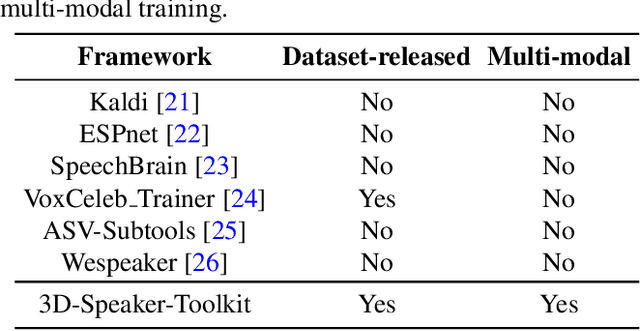
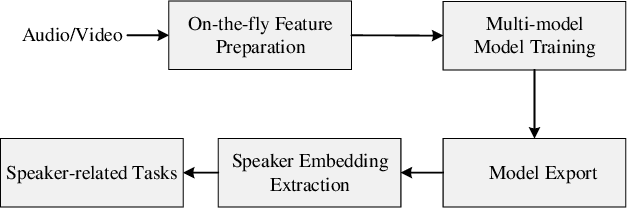
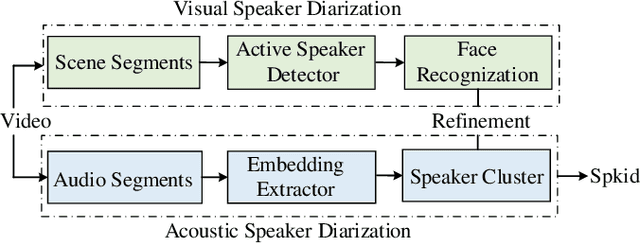
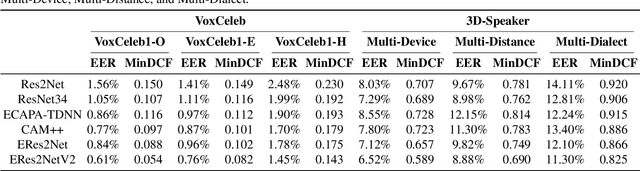
This paper introduces 3D-Speaker-Toolkit, an open source toolkit for multi-modal speaker verification and diarization. It is designed for the needs of academic researchers and industrial practitioners. The 3D-Speaker-Toolkit adeptly leverages the combined strengths of acoustic, semantic, and visual data, seamlessly fusing these modalities to offer robust speaker recognition capabilities. The acoustic module extracts speaker embeddings from acoustic features, employing both fully-supervised and self-supervised learning approaches. The semantic module leverages advanced language models to apprehend the substance and context of spoken language, thereby augmenting the system's proficiency in distinguishing speakers through linguistic patterns. Finally, the visual module applies image processing technologies to scrutinize facial features, which bolsters the precision of speaker diarization in multi-speaker environments. Collectively, these modules empower the 3D-Speaker-Toolkit to attain elevated levels of accuracy and dependability in executing speaker-related tasks, establishing a new benchmark in multi-modal speaker analysis. The 3D-Speaker project also includes a handful of open-sourced state-of-the-art models and a large dataset containing over 10,000 speakers. The toolkit is publicly available at https://github.com/alibaba-damo-academy/3D-Speaker.
PE: A Poincare Explanation Method for Fast Text Hierarchy Generation
Mar 25, 2024The black-box nature of deep learning models in NLP hinders their widespread application. The research focus has shifted to Hierarchical Attribution (HA) for its ability to model feature interactions. Recent works model non-contiguous combinations with a time-costly greedy search in Eculidean spaces, neglecting underlying linguistic information in feature representations. In this work, we introduce a novel method, namely Poincar\'e Explanation (PE), for modeling feature interactions using hyperbolic spaces in an $O(n^2logn)$ time complexity. Inspired by Poincar\'e model, we propose a framework to project the embeddings into hyperbolic spaces, which exhibit better inductive biases for syntax and semantic hierarchical structures. Eventually, we prove that the hierarchical clustering process in the projected space could be viewed as building a minimum spanning tree and propose a time efficient algorithm. Experimental results demonstrate the effectiveness of our approach.
Interpreting What Typical Fault Signals Look Like via Prototype-matching
Mar 11, 2024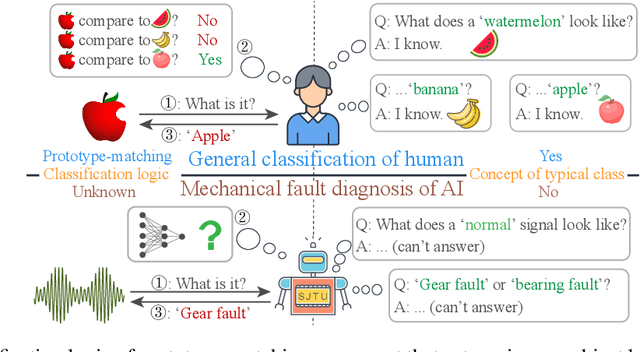


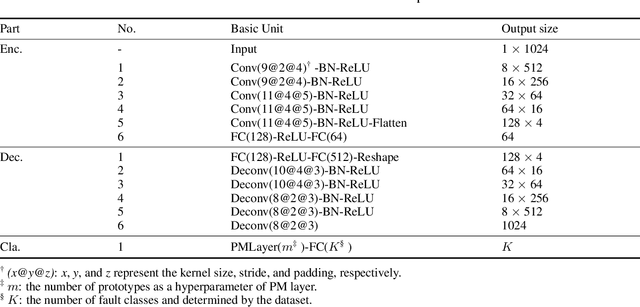
Neural networks, with powerful nonlinear mapping and classification capabilities, are widely applied in mechanical fault diagnosis to ensure safety. However, being typical black-box models, their application is limited in high-reliability-required scenarios. To understand the classification logic and explain what typical fault signals look like, the prototype matching network (PMN) is proposed by combining the human-inherent prototype-matching with autoencoder (AE). The PMN matches AE-extracted feature with each prototype and selects the most similar prototype as the prediction result. It has three interpreting paths on classification logic, fault prototypes, and matching contributions. Conventional diagnosis and domain generalization experiments demonstrate its competitive diagnostic performance and distinguished advantages in representation learning. Besides, the learned typical fault signals (i.e., sample-level prototypes) showcase the ability for denoising and extracting subtle key features that experts find challenging to capture. This ability broadens human understanding and provides a promising solution from interpretability research to AI-for-Science.
EasyRL4Rec: A User-Friendly Code Library for Reinforcement Learning Based Recommender Systems
Feb 23, 2024Reinforcement Learning (RL)-Based Recommender Systems (RSs) are increasingly recognized for their ability to improve long-term user engagement. Yet, the field grapples with challenges such as the absence of accessible frameworks, inconsistent evaluation standards, and the complexity of replicating prior work. Addressing these obstacles, we present EasyRL4Rec, a user-friendly and efficient library tailored for RL-based RSs. EasyRL4Rec features lightweight, diverse RL environments built on five widely-used public datasets, and is equipped with comprehensive core modules that offer rich options to ease the development of models. It establishes consistent evaluation criteria with a focus on long-term impacts and introduces customized solutions for state modeling and action representation tailored to recommender systems. Additionally, we share valuable insights gained from extensive experiments with current methods. EasyRL4Rec aims to facilitate the model development and experimental process in the domain of RL-based RSs. The library is openly accessible at https://github.com/chongminggao/EasyRL4Rec.
An Embarrassingly Simple Approach for LLM with Strong ASR Capacity
Feb 13, 2024In this paper, we focus on solving one of the most important tasks in the field of speech processing, i.e., automatic speech recognition (ASR), with speech foundation encoders and large language models (LLM). Recent works have complex designs such as compressing the output temporally for the speech encoder, tackling modal alignment for the projector, and utilizing parameter-efficient fine-tuning for the LLM. We found that delicate designs are not necessary, while an embarrassingly simple composition of off-the-shelf speech encoder, LLM, and the only trainable linear projector is competent for the ASR task. To be more specific, we benchmark and explore various combinations of LLMs and speech encoders, leading to the optimal LLM-based ASR system, which we call SLAM-ASR. The proposed SLAM-ASR provides a clean setup and little task-specific design, where only the linear projector is trained. To the best of our knowledge, SLAM-ASR achieves the best performance on the Librispeech benchmark among LLM-based ASR models and even outperforms the latest LLM-based audio-universal model trained on massive pair data. Finally, we explore the capability emergence of LLM-based ASR in the process of modal alignment. We hope that our study can facilitate the research on extending LLM with cross-modality capacity and shed light on the LLM-based ASR community.
ChatGraph: Chat with Your Graphs
Jan 23, 2024Graph analysis is fundamental in real-world applications. Traditional approaches rely on SPARQL-like languages or clicking-and-dragging interfaces to interact with graph data. However, these methods either require users to possess high programming skills or support only a limited range of graph analysis functionalities. To address the limitations, we propose a large language model (LLM)-based framework called ChatGraph. With ChatGraph, users can interact with graphs through natural language, making it easier to use and more flexible than traditional approaches. The core of ChatGraph lies in generating chains of graph analysis APIs based on the understanding of the texts and graphs inputted in the user prompts. To achieve this, ChatGraph consists of three main modules: an API retrieval module that searches for relevant APIs, a graph-aware LLM module that enables the LLM to comprehend graphs, and an API chain-oriented finetuning module that guides the LLM in generating API chains.
E-chat: Emotion-sensitive Spoken Dialogue System with Large Language Models
Jan 06, 2024This study focuses on emotion-sensitive spoken dialogue in human-machine speech interaction. With the advancement of Large Language Models (LLMs), dialogue systems can handle multimodal data, including audio. Recent models have enhanced the understanding of complex audio signals through the integration of various audio events. However, they are unable to generate appropriate responses based on emotional speech. To address this, we introduce the Emotional chat Model (E-chat), a novel spoken dialogue system capable of comprehending and responding to emotions conveyed from speech. This model leverages an emotion embedding extracted by a speech encoder, combined with LLMs, enabling it to respond according to different emotional contexts. Additionally, we introduce the E-chat200 dataset, designed explicitly for emotion-sensitive spoken dialogue. In various evaluation metrics, E-chat consistently outperforms baseline LLMs, demonstrating its potential in emotional comprehension and human-machine interaction.
CIDR: A Cooperative Integrated Dynamic Refining Method for Minimal Feature Removal Problem
Dec 13, 2023The minimal feature removal problem in the post-hoc explanation area aims to identify the minimal feature set (MFS). Prior studies using the greedy algorithm to calculate the minimal feature set lack the exploration of feature interactions under a monotonic assumption which cannot be satisfied in general scenarios. In order to address the above limitations, we propose a Cooperative Integrated Dynamic Refining method (CIDR) to efficiently discover minimal feature sets. Specifically, we design Cooperative Integrated Gradients (CIG) to detect interactions between features. By incorporating CIG and characteristics of the minimal feature set, we transform the minimal feature removal problem into a knapsack problem. Additionally, we devise an auxiliary Minimal Feature Refinement algorithm to determine the minimal feature set from numerous candidate sets. To the best of our knowledge, our work is the first to address the minimal feature removal problem in the field of natural language processing. Extensive experiments demonstrate that CIDR is capable of tracing representative minimal feature sets with improved interpretability across various models and datasets.
CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation
Nov 14, 2023Large Language Models (LLMs) have demonstrated remarkable performance on coding related tasks, particularly on assisting humans in programming and facilitating programming automation. However, existing benchmarks for evaluating the code understanding and generation capacities of LLMs suffer from severe limitations. First, most benchmarks are deficient as they focus on a narrow range of popular programming languages and specific tasks, whereas the real-world software development scenarios show dire need to implement systems with multilingual programming environments to satisfy diverse requirements. Practical programming practices also strongly expect multi-task settings for testing coding capabilities of LLMs comprehensively and robustly. Second, most benchmarks also fail to consider the actual executability and the consistency of execution results of the generated code. To bridge these gaps between existing benchmarks and expectations from practical applications, we introduce CodeScope, an execution-based, multilingual, multi-task, multi-dimensional evaluation benchmark for comprehensively gauging LLM capabilities on coding tasks. CodeScope covers 43 programming languages and 8 coding tasks. It evaluates the coding performance of LLMs from three dimensions (perspectives): difficulty, efficiency, and length. To facilitate execution-based evaluations of code generation, we develop MultiCodeEngine, an automated code execution engine that supports 14 programming languages. Finally, we systematically evaluate and analyze 8 mainstream LLMs on CodeScope tasks and demonstrate the superior breadth and challenges of CodeScope for evaluating LLMs on code understanding and generation tasks compared to other benchmarks. The CodeScope benchmark and datasets are publicly available at https://github.com/WeixiangYAN/CodeScope.