 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaolin Zhang
Lifelong Knowledge Editing for LLMs with Retrieval-Augmented Continuous Prompt Learning
May 08, 2024
Model editing aims to correct outdated or erroneous knowledge in large language models (LLMs) without the need for costly retraining. Lifelong model editing is the most challenging task that caters to the continuous editing requirements of LLMs. Prior works primarily focus on single or batch editing; nevertheless, these methods fall short in lifelong editing scenarios due to catastrophic knowledge forgetting and the degradation of model performance. Although retrieval-based methods alleviate these issues, they are impeded by slow and cumbersome processes of integrating the retrieved knowledge into the model. In this work, we introduce RECIPE, a RetriEval-augmented ContInuous Prompt lEarning method, to boost editing efficacy and inference efficiency in lifelong learning. RECIPE first converts knowledge statements into short and informative continuous prompts, prefixed to the LLM's input query embedding, to efficiently refine the response grounded on the knowledge. It further integrates the Knowledge Sentinel (KS) that acts as an intermediary to calculate a dynamic threshold, determining whether the retrieval repository contains relevant knowledge. Our retriever and prompt encoder are jointly trained to achieve editing properties, i.e., reliability, generality, and locality. In our experiments, RECIPE is assessed extensively across multiple LLMs and editing datasets, where it achieves superior editing performance. RECIPE also demonstrates its capability to maintain the overall performance of LLMs alongside showcasing fast editing and inference speed.
R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models
May 04, 2024Retrieval-augmented large language models (LLMs) leverage relevant content retrieved by information retrieval systems to generate correct responses, aiming to alleviate the hallucination problem. However, existing retriever-responder methods typically append relevant documents to the prompt of LLMs to perform text generation tasks without considering the interaction of fine-grained structural semantics between the retrieved documents and the LLMs. This issue is particularly important for accurate response generation as LLMs tend to ``lose in the middle'' when dealing with input prompts augmented with lengthy documents. In this work, we propose a new pipeline named ``Reinforced Retriever-Reorder-Responder'' (R$^4$) to learn document orderings for retrieval-augmented LLMs, thereby further enhancing their generation abilities while the large numbers of parameters of LLMs remain frozen. The reordering learning process is divided into two steps according to the quality of the generated responses: document order adjustment and document representation enhancement. Specifically, document order adjustment aims to organize retrieved document orderings into beginning, middle, and end positions based on graph attention learning, which maximizes the reinforced reward of response quality. Document representation enhancement further refines the representations of retrieved documents for responses of poor quality via document-level gradient adversarial learning. Extensive experiments demonstrate that our proposed pipeline achieves better factual question-answering performance on knowledge-intensive tasks compared to strong baselines across various public datasets. The source codes and trained models will be released upon paper acceptance.
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024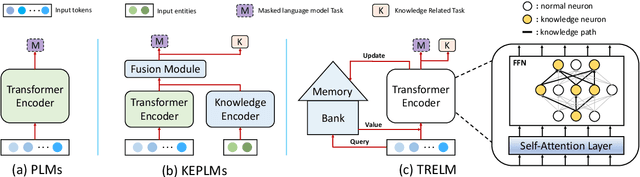

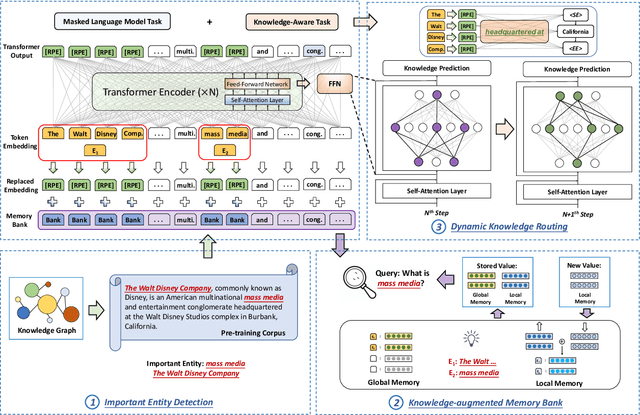
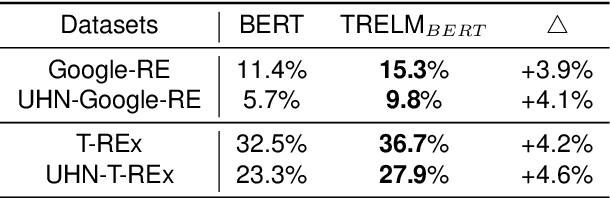
KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.
CIDR: A Cooperative Integrated Dynamic Refining Method for Minimal Feature Removal Problem
Dec 13, 2023The minimal feature removal problem in the post-hoc explanation area aims to identify the minimal feature set (MFS). Prior studies using the greedy algorithm to calculate the minimal feature set lack the exploration of feature interactions under a monotonic assumption which cannot be satisfied in general scenarios. In order to address the above limitations, we propose a Cooperative Integrated Dynamic Refining method (CIDR) to efficiently discover minimal feature sets. Specifically, we design Cooperative Integrated Gradients (CIG) to detect interactions between features. By incorporating CIG and characteristics of the minimal feature set, we transform the minimal feature removal problem into a knapsack problem. Additionally, we devise an auxiliary Minimal Feature Refinement algorithm to determine the minimal feature set from numerous candidate sets. To the best of our knowledge, our work is the first to address the minimal feature removal problem in the field of natural language processing. Extensive experiments demonstrate that CIDR is capable of tracing representative minimal feature sets with improved interpretability across various models and datasets.
From Complex to Simple: Unraveling the Cognitive Tree for Reasoning with Small Language Models
Nov 12, 2023Reasoning is a distinctive human capacity, enabling us to address complex problems by breaking them down into a series of manageable cognitive steps. Yet, complex logical reasoning is still cumbersome for language models. Based on the dual process theory in cognitive science, we are the first to unravel the cognitive reasoning abilities of language models. Our framework employs an iterative methodology to construct a Cognitive Tree (CogTree). The root node of this tree represents the initial query, while the leaf nodes consist of straightforward questions that can be answered directly. This construction involves two main components: the implicit extraction module (referred to as the intuitive system) and the explicit reasoning module (referred to as the reflective system). The intuitive system rapidly generates multiple responses by utilizing in-context examples, while the reflective system scores these responses using comparative learning. The scores guide the intuitive system in its subsequent generation step. Our experimental results on two popular and challenging reasoning tasks indicate that it is possible to achieve a performance level comparable to that of GPT-3.5 (with 175B parameters), using a significantly smaller language model that contains fewer parameters (<=7B) than 5% of GPT-3.5.
Learning Knowledge-Enhanced Contextual Language Representations for Domain Natural Language Understanding
Nov 12, 2023Knowledge-Enhanced Pre-trained Language Models (KEPLMs) improve the performance of various downstream NLP tasks by injecting knowledge facts from large-scale Knowledge Graphs (KGs). However, existing methods for pre-training KEPLMs with relational triples are difficult to be adapted to close domains due to the lack of sufficient domain graph semantics. In this paper, we propose a Knowledge-enhanced lANGuAge Representation learning framework for various clOsed dOmains (KANGAROO) via capturing the implicit graph structure among the entities. Specifically, since the entity coverage rates of closed-domain KGs can be relatively low and may exhibit the global sparsity phenomenon for knowledge injection, we consider not only the shallow relational representations of triples but also the hyperbolic embeddings of deep hierarchical entity-class structures for effective knowledge fusion.Moreover, as two closed-domain entities under the same entity-class often have locally dense neighbor subgraphs counted by max point biconnected component, we further propose a data augmentation strategy based on contrastive learning over subgraphs to construct hard negative samples of higher quality. It makes the underlying KELPMs better distinguish the semantics of these neighboring entities to further complement the global semantic sparsity. In the experiments, we evaluate KANGAROO over various knowledge-aware and general NLP tasks in both full and few-shot learning settings, outperforming various KEPLM training paradigms performance in closed-domains significantly.
Vision-Language Pre-training with Object Contrastive Learning for 3D Scene Understanding
May 18, 2023



In recent years, vision language pre-training frameworks have made significant progress in natural language processing and computer vision, achieving remarkable performance improvement on various downstream tasks. However, when extended to point cloud data, existing works mainly focus on building task-specific models, and fail to extract universal 3D vision-language embedding that generalize well. We carefully investigate three common tasks in semantic 3D scene understanding, and derive key insights into the development of a pre-training model. Motivated by these observations, we propose a vision-language pre-training framework 3DVLP (3D vision-language pre-training with object contrastive learning), which transfers flexibly on 3D vision-language downstream tasks. 3DVLP takes visual grounding as the proxy task and introduces Object-level IoU-guided Detection (OID) loss to obtain high-quality proposals in the scene. Moreover, we design Object-level Cross-Contrastive alignment (OCC) task and Object-level Self-Contrastive learning (OSC) task to align the objects with descriptions and distinguish different objects in the scene, respectively. Extensive experiments verify the excellent performance of 3DVLP on three 3D vision-language tasks, reflecting its superiority in semantic 3D scene understanding.
Revisiting and Advancing Chinese Natural Language Understanding with Accelerated Heterogeneous Knowledge Pre-training
Oct 12, 2022



Recently, knowledge-enhanced pre-trained language models (KEPLMs) improve context-aware representations via learning from structured relations in knowledge graphs, and/or linguistic knowledge from syntactic or dependency analysis. Unlike English, there is a lack of high-performing open-source Chinese KEPLMs in the natural language processing (NLP) community to support various language understanding applications. In this paper, we revisit and advance the development of Chinese natural language understanding with a series of novel Chinese KEPLMs released in various parameter sizes, namely CKBERT (Chinese knowledge-enhanced BERT).Specifically, both relational and linguistic knowledge is effectively injected into CKBERT based on two novel pre-training tasks, i.e., linguistic-aware masked language modeling and contrastive multi-hop relation modeling. Based on the above two pre-training paradigms and our in-house implemented TorchAccelerator, we have pre-trained base (110M), large (345M) and huge (1.3B) versions of CKBERT efficiently on GPU clusters. Experiments demonstrate that CKBERT outperforms strong baselines for Chinese over various benchmark NLP tasks and in terms of different model sizes.
FedEgo: Privacy-preserving Personalized Federated Graph Learning with Ego-graphs
Aug 29, 2022



As special information carriers containing both structure and feature information, graphs are widely used in graph mining, e.g., Graph Neural Networks (GNNs). However, in some practical scenarios, graph data are stored separately in multiple distributed parties, which may not be directly shared due to conflicts of interest. Hence, federated graph neural networks are proposed to address such data silo problems while preserving the privacy of each party (or client). Nevertheless, different graph data distributions among various parties, which is known as the statistical heterogeneity, may degrade the performance of naive federated learning algorithms like FedAvg. In this paper, we propose FedEgo, a federated graph learning framework based on ego-graphs to tackle the challenges above, where each client will train their local models while also contributing to the training of a global model. FedEgo applies GraphSAGE over ego-graphs to make full use of the structure information and utilizes Mixup for privacy concerns. To deal with the statistical heterogeneity, we integrate personalization into learning and propose an adaptive mixing coefficient strategy that enables clients to achieve their optimal personalization. Extensive experimental results and in-depth analysis demonstrate the effectiveness of FedEgo.
EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing
Apr 30, 2022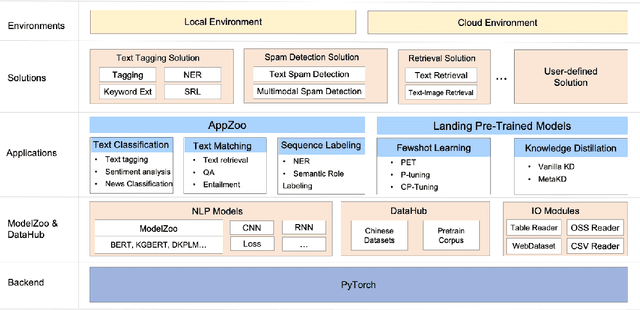
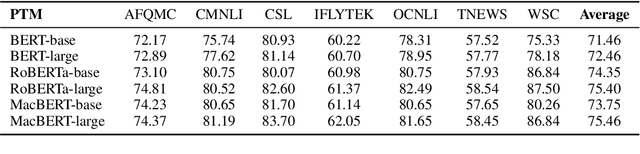
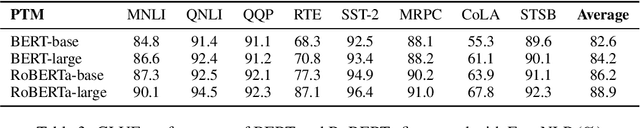
The success of Pre-Trained Models (PTMs) has reshaped the development of Natural Language Processing (NLP). Yet, it is not easy to obtain high-performing models and deploy them online for industrial practitioners. To bridge this gap, EasyNLP is designed to make it easy to build NLP applications, which supports a comprehensive suite of NLP algorithms. It further features knowledge-enhanced pre-training, knowledge distillation and few-shot learning functionalities for large-scale PTMs, and provides a unified framework of model training, inference and deployment for real-world applications. Currently, EasyNLP has powered over ten business units within Alibaba Group and is seamlessly integrated to the Platform of AI (PAI) products on Alibaba Cloud. The source code of our EasyNLP toolkit is released at GitHub (https://github.com/alibaba/EasyNLP).