 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLei Li
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
CMU-Flownet: Exploring Point Cloud Scene Flow Estimation in Occluded Scenario
Apr 16, 2024Occlusions hinder point cloud frame alignment in LiDAR data, a challenge inadequately addressed by scene flow models tested mainly on occlusion-free datasets. Attempts to integrate occlusion handling within networks often suffer accuracy issues due to two main limitations: a) the inadequate use of occlusion information, often merging it with flow estimation without an effective integration strategy, and b) reliance on distance-weighted upsampling that falls short in correcting occlusion-related errors. To address these challenges, we introduce the Correlation Matrix Upsampling Flownet (CMU-Flownet), incorporating an occlusion estimation module within its cost volume layer, alongside an Occlusion-aware Cost Volume (OCV) mechanism. Specifically, we propose an enhanced upsampling approach that expands the sensory field of the sampling process which integrates a Correlation Matrix designed to evaluate point-level similarity. Meanwhile, our model robustly integrates occlusion data within the context of scene flow, deploying this information strategically during the refinement phase of the flow estimation. The efficacy of this approach is demonstrated through subsequent experimental validation. Empirical assessments reveal that CMU-Flownet establishes state-of-the-art performance within the realms of occluded Flyingthings3D and KITTY datasets, surpassing previous methodologies across a majority of evaluated metrics.
CHOPS: CHat with custOmer Profile Systems for Customer Service with LLMs
Apr 15, 2024Businesses and software platforms are increasingly turning to Large Language Models (LLMs) such as GPT-3.5, GPT-4, GLM-3, and LLaMa-2 for chat assistance with file access or as reasoning agents for customer service. However, current LLM-based customer service models have limited integration with customer profiles and lack the operational capabilities necessary for effective service. Moreover, existing API integrations emphasize diversity over the precision and error avoidance essential in real-world customer service scenarios. To address these issues, we propose an LLM agent named CHOPS (CHat with custOmer Profile in existing System), designed to: (1) efficiently utilize existing databases or systems for accessing user information or interacting with these systems following existing guidelines; (2) provide accurate and reasonable responses or carry out required operations in the system while avoiding harmful operations; and (3) leverage a combination of small and large LLMs to achieve satisfying performance at a reasonable inference cost. We introduce a practical dataset, the CPHOS-dataset, which includes a database, guiding files, and QA pairs collected from CPHOS, an online platform that facilitates the organization of simulated Physics Olympiads for high school teachers and students. We have conducted extensive experiments to validate the performance of our proposed CHOPS architecture using the CPHOS-dataset, with the aim of demonstrating how LLMs can enhance or serve as alternatives to human customer service. Code for our proposed architecture and dataset can be found at {https://github.com/JingzheShi/CHOPS}.
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Apr 07, 2024
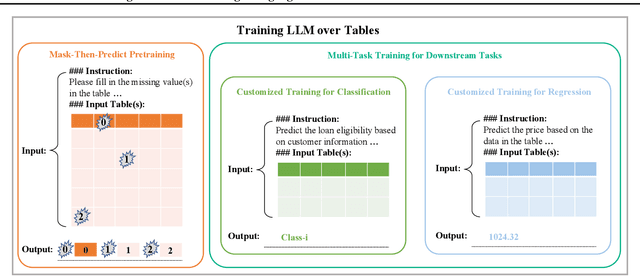
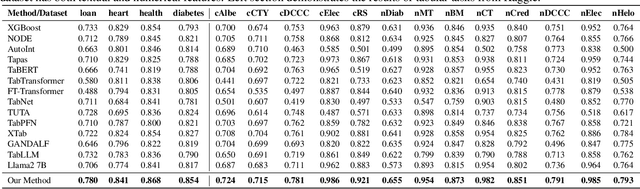
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
Design and Evaluation of a Compact 3D End-effector Assistive Robot for Adaptive Arm Support
Apr 04, 2024We developed a 3D end-effector type of upper limb assistive robot, named as Assistive Robotic Arm Extender (ARAE), that provides transparency movement and adaptive arm support control to achieve home-based therapy and training in the real environment. The proposed system composes five degrees of freedom, including three active motors and two passive joints at the end-effector module. The core structure of the system is based on a parallel mechanism. The kinematic and dynamic modeling are illustrated in detail. The proposed adaptive arm support control framework calculates the compensated force based on the estimated human arm posture in 3D space. It firstly estimates human arm joint angles using two proposed methods: fixed torso and sagittal plane models without using external sensors such as IMUs, magnetic sensors, or depth cameras. The experiments were carried out to evaluate the performance of the two proposed angle estimation methods. Then, the estimated human joint angles were input into the human upper limb dynamics model to derive the required support force generated by the robot. The muscular activities were measured to evaluate the effects of the proposed framework. The obvious reduction of muscular activities was exhibited when participants were tested with the ARAE under an adaptive arm gravity compensation control framework. The overall results suggest that the ARAE system, when combined with the proposed control framework, has the potential to offer adaptive arm support. This integration could enable effective training with Activities of Daily Living (ADLs) and interaction with real environments.
Towards Multimodal Video Paragraph Captioning Models Robust to Missing Modality
Mar 28, 2024Video paragraph captioning (VPC) involves generating detailed narratives for long videos, utilizing supportive modalities such as speech and event boundaries. However, the existing models are constrained by the assumption of constant availability of a single auxiliary modality, which is impractical given the diversity and unpredictable nature of real-world scenarios. To this end, we propose a Missing-Resistant framework MR-VPC that effectively harnesses all available auxiliary inputs and maintains resilience even in the absence of certain modalities. Under this framework, we propose the Multimodal VPC (MVPC) architecture integrating video, speech, and event boundary inputs in a unified manner to process various auxiliary inputs. Moreover, to fortify the model against incomplete data, we introduce DropAM, a data augmentation strategy that randomly omits auxiliary inputs, paired with DistillAM, a regularization target that distills knowledge from teacher models trained on modality-complete data, enabling efficient learning in modality-deficient environments. Through exhaustive experimentation on YouCook2 and ActivityNet Captions, MR-VPC has proven to deliver superior performance on modality-complete and modality-missing test data. This work highlights the significance of developing resilient VPC models and paves the way for more adaptive, robust multimodal video understanding.
To Supervise or Not to Supervise: Understanding and Addressing the Key Challenges of 3D Transfer Learning
Mar 26, 2024Transfer learning has long been a key factor in the advancement of many fields including 2D image analysis. Unfortunately, its applicability in 3D data processing has been relatively limited. While several approaches for 3D transfer learning have been proposed in recent literature, with contrastive learning gaining particular prominence, most existing methods in this domain have only been studied and evaluated in limited scenarios. Most importantly, there is currently a lack of principled understanding of both when and why 3D transfer learning methods are applicable. Remarkably, even the applicability of standard supervised pre-training is poorly understood. In this work, we conduct the first in-depth quantitative and qualitative investigation of supervised and contrastive pre-training strategies and their utility in downstream 3D tasks. We demonstrate that layer-wise analysis of learned features provides significant insight into the downstream utility of trained networks. Informed by this analysis, we propose a simple geometric regularization strategy, which improves the transferability of supervised pre-training. Our work thus sheds light onto both the specific challenges of 3D transfer learning, as well as strategies to overcome them.