 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLu Hou
Towards Multimodal Video Paragraph Captioning Models Robust to Missing Modality
Mar 28, 2024
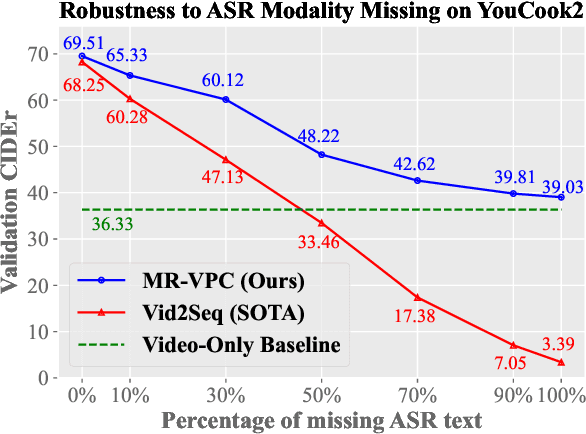
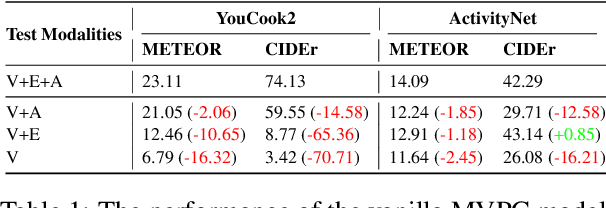

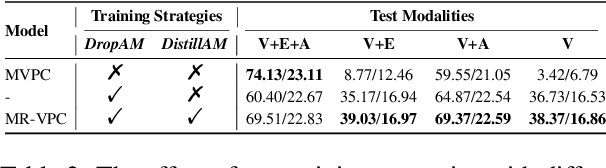
Video paragraph captioning (VPC) involves generating detailed narratives for long videos, utilizing supportive modalities such as speech and event boundaries. However, the existing models are constrained by the assumption of constant availability of a single auxiliary modality, which is impractical given the diversity and unpredictable nature of real-world scenarios. To this end, we propose a Missing-Resistant framework MR-VPC that effectively harnesses all available auxiliary inputs and maintains resilience even in the absence of certain modalities. Under this framework, we propose the Multimodal VPC (MVPC) architecture integrating video, speech, and event boundary inputs in a unified manner to process various auxiliary inputs. Moreover, to fortify the model against incomplete data, we introduce DropAM, a data augmentation strategy that randomly omits auxiliary inputs, paired with DistillAM, a regularization target that distills knowledge from teacher models trained on modality-complete data, enabling efficient learning in modality-deficient environments. Through exhaustive experimentation on YouCook2 and ActivityNet Captions, MR-VPC has proven to deliver superior performance on modality-complete and modality-missing test data. This work highlights the significance of developing resilient VPC models and paves the way for more adaptive, robust multimodal video understanding.
Visually Guided Generative Text-Layout Pre-training for Document Intelligence
Mar 27, 2024Prior study shows that pre-training techniques can boost the performance of visual document understanding (VDU), which typically requires models to gain abilities to perceive and reason both document texts and layouts (e.g., locations of texts and table-cells). To this end, we propose visually guided generative text-layout pre-training, named ViTLP. Given a document image, the model optimizes hierarchical language and layout modeling objectives to generate the interleaved text and layout sequence. In addition, to address the limitation of processing long documents by Transformers, we introduce a straightforward yet effective multi-segment generative pre-training scheme, facilitating ViTLP to process word-intensive documents of any length. ViTLP can function as a native OCR model to localize and recognize texts of document images. Besides, ViTLP can be effectively applied to various downstream VDU tasks. Extensive experiments show that ViTLP achieves competitive performance over existing baselines on benchmark VDU tasks, including information extraction, document classification, and document question answering.
MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
Mar 12, 2024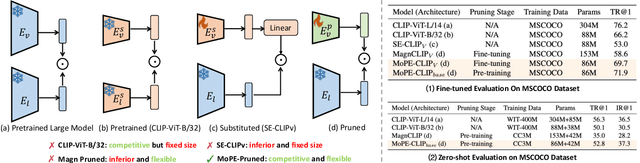
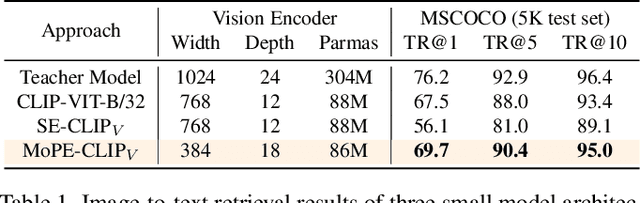
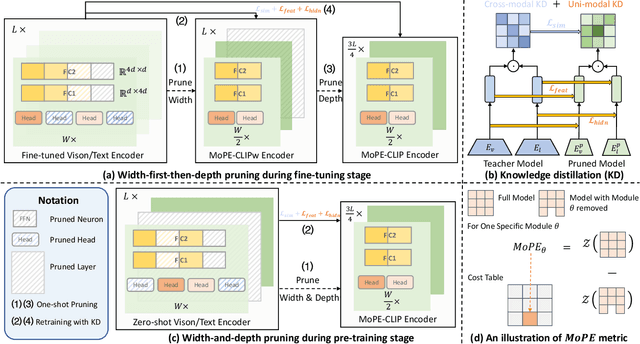
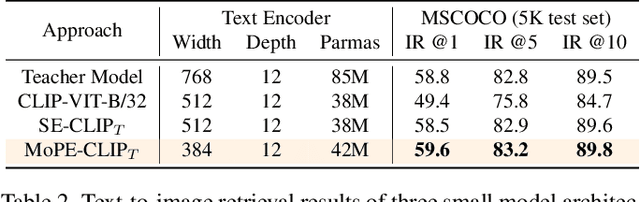
Vision-language pre-trained models have achieved impressive performance on various downstream tasks. However, their large model sizes hinder their utilization on platforms with limited computational resources. We find that directly using smaller pre-trained models and applying magnitude-based pruning on CLIP models leads to inflexibility and inferior performance. Recent efforts for VLP compression either adopt uni-modal compression metrics resulting in limited performance or involve costly mask-search processes with learnable masks. In this paper, we first propose the Module-wise Pruning Error (MoPE) metric, accurately assessing CLIP module importance by performance decline on cross-modal tasks. Using the MoPE metric, we introduce a unified pruning framework applicable to both pre-training and task-specific fine-tuning compression stages. For pre-training, MoPE-CLIP effectively leverages knowledge from the teacher model, significantly reducing pre-training costs while maintaining strong zero-shot capabilities. For fine-tuning, consecutive pruning from width to depth yields highly competitive task-specific models. Extensive experiments in two stages demonstrate the effectiveness of the MoPE metric, and MoPE-CLIP outperforms previous state-of-the-art VLP compression methods.
* 18 pages, 8 figures, Published in CVPR2024
IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact
Mar 02, 2024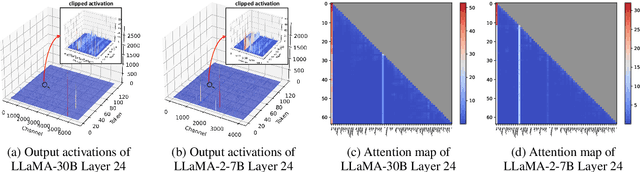
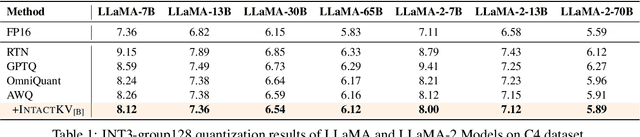

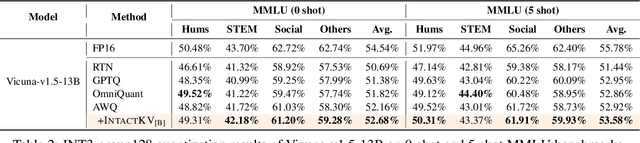
Large language models (LLMs) excel in natural language processing but demand intensive computation. To mitigate this, various quantization methods have been explored, yet they compromise LLM performance. This paper unveils a previously overlooked type of outlier in LLMs. Such outliers are found to allocate most of the attention scores on initial tokens of input, termed as pivot tokens, which is crucial to the performance of quantized LLMs. Given that, we propose IntactKV to generate the KV cache of pivot tokens losslessly from the full-precision model. The approach is simple and easy to combine with existing quantization solutions. Besides, IntactKV can be calibrated as additional LLM parameters to boost the quantized LLMs further. Mathematical analysis also proves that IntactKV effectively reduces the upper bound of quantization error. Empirical results show that IntactKV brings consistent improvement and achieves lossless weight-only INT4 quantization on various downstream tasks, leading to the new state-of-the-art for LLM quantization.
TempCompass: Do Video LLMs Really Understand Videos?
Mar 01, 2024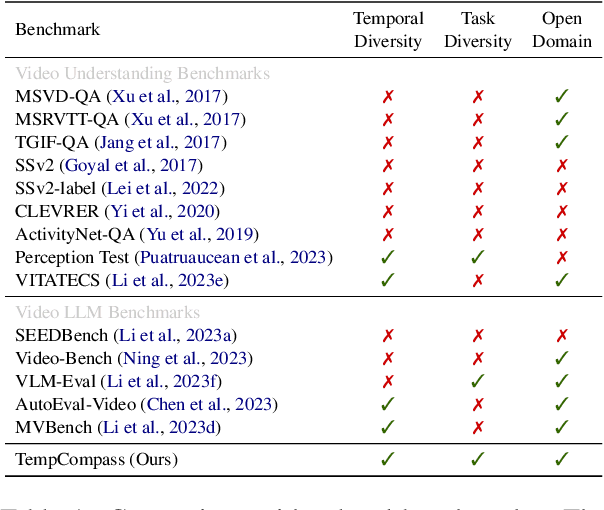
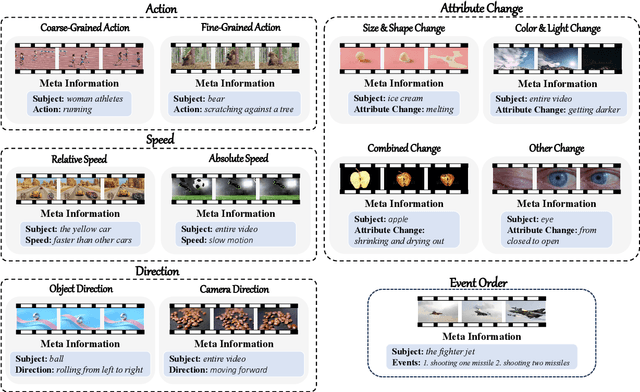
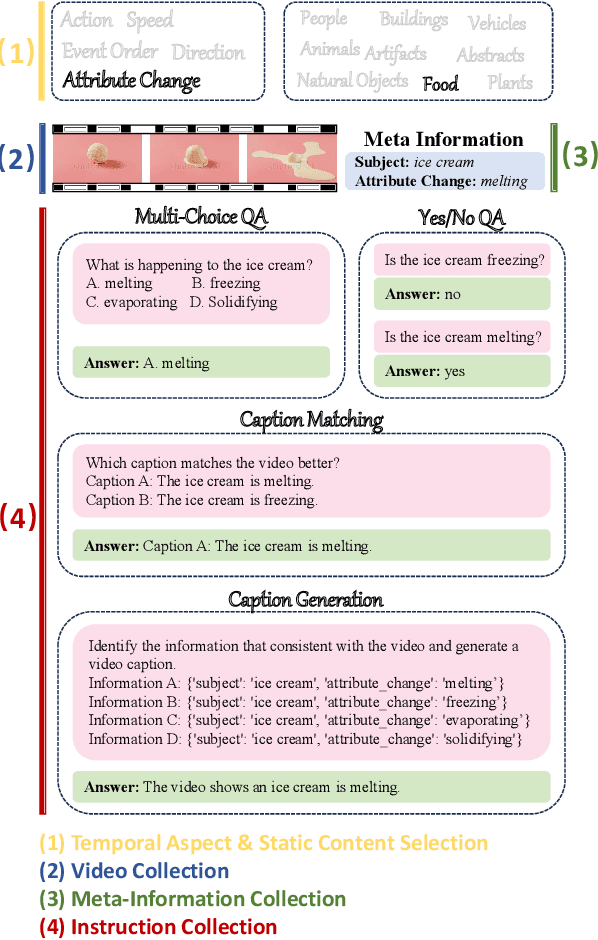
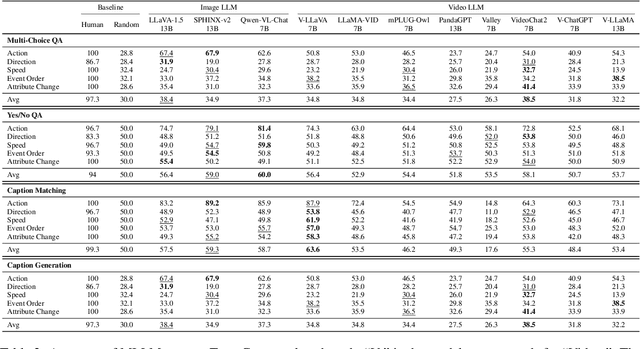
Recently, there is a surge in interest surrounding video large language models (Video LLMs). However, existing benchmarks fail to provide a comprehensive feedback on the temporal perception ability of Video LLMs. On the one hand, most of them are unable to distinguish between different temporal aspects (e.g., speed, direction) and thus cannot reflect the nuanced performance on these specific aspects. On the other hand, they are limited in the diversity of task formats (e.g., only multi-choice QA), which hinders the understanding of how temporal perception performance may vary across different types of tasks. Motivated by these two problems, we propose the \textbf{TempCompass} benchmark, which introduces a diversity of temporal aspects and task formats. To collect high-quality test data, we devise two novel strategies: (1) In video collection, we construct conflicting videos that share the same static content but differ in a specific temporal aspect, which prevents Video LLMs from leveraging single-frame bias or language priors. (2) To collect the task instructions, we propose a paradigm where humans first annotate meta-information for a video and then an LLM generates the instruction. We also design an LLM-based approach to automatically and accurately evaluate the responses from Video LLMs. Based on TempCompass, we comprehensively evaluate 8 state-of-the-art (SOTA) Video LLMs and 3 Image LLMs, and reveal the discerning fact that these models exhibit notably poor temporal perception ability. Our data will be available at \url{https://github.com/llyx97/TempCompass}.
Extending Context Window of Large Language Models via Semantic Compression
Dec 15, 2023Transformer-based Large Language Models (LLMs) often impose limitations on the length of the text input to ensure the generation of fluent and relevant responses. This constraint restricts their applicability in scenarios involving long texts. We propose a novel semantic compression method that enables generalization to texts that are 6-8 times longer, without incurring significant computational costs or requiring fine-tuning. Our proposed framework draws inspiration from source coding in information theory and employs a pre-trained model to reduce the semantic redundancy of long inputs before passing them to the LLMs for downstream tasks. Experimental results demonstrate that our method effectively extends the context window of LLMs across a range of tasks including question answering, summarization, few-shot learning, and information retrieval. Furthermore, the proposed semantic compression method exhibits consistent fluency in text generation while reducing the associated computational overhead.
TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding
Dec 04, 2023This work proposes TimeChat, a time-sensitive multimodal large language model specifically designed for long video understanding. Our model incorporates two key architectural contributions: (1) a timestamp-aware frame encoder that binds visual content with the timestamp of each frame, and (2) a sliding video Q-Former that produces a video token sequence of varying lengths to accommodate videos of various durations. Additionally, we construct an instruction-tuning dataset, encompassing 6 tasks and a total of 125K instances, to further enhance TimeChat's instruction-following performance. Experiment results across various video understanding tasks, such as dense captioning, temporal grounding, and highlight detection, demonstrate TimeChat's strong zero-shot temporal localization and reasoning capabilities. For example, it achieves +9.2 F1 score and +2.8 CIDEr on YouCook2, +5.8 HIT@1 on QVHighlights, and +27.5 R@1 (IoU=0.5) on Charades-STA, compared to state-of-the-art video large language models, holding the potential to serve as a versatile video assistant for long-form video comprehension tasks and satisfy realistic user requirements.
VITATECS: A Diagnostic Dataset for Temporal Concept Understanding of Video-Language Models
Nov 29, 2023The ability to perceive how objects change over time is a crucial ingredient in human intelligence. However, current benchmarks cannot faithfully reflect the temporal understanding abilities of video-language models (VidLMs) due to the existence of static visual shortcuts. To remedy this issue, we present VITATECS, a diagnostic VIdeo-Text dAtaset for the evaluation of TEmporal Concept underStanding. Specifically, we first introduce a fine-grained taxonomy of temporal concepts in natural language in order to diagnose the capability of VidLMs to comprehend different temporal aspects. Furthermore, to disentangle the correlation between static and temporal information, we generate counterfactual video descriptions that differ from the original one only in the specified temporal aspect. We employ a semi-automatic data collection framework using large language models and human-in-the-loop annotation to obtain high-quality counterfactual descriptions efficiently. Evaluation of representative video-language understanding models confirms their deficiency in temporal understanding, revealing the need for greater emphasis on the temporal elements in video-language research.
FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation
Nov 08, 2023
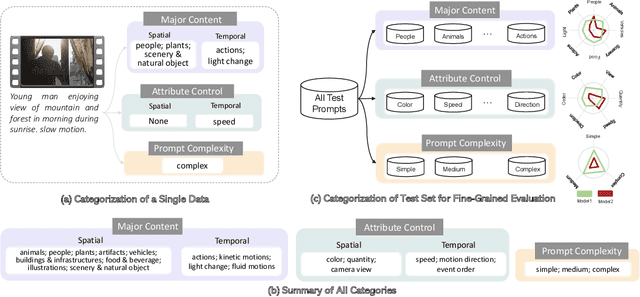


Recently, open-domain text-to-video (T2V) generation models have made remarkable progress. However, the promising results are mainly shown by the qualitative cases of generated videos, while the quantitative evaluation of T2V models still faces two critical problems. Firstly, existing studies lack fine-grained evaluation of T2V models on different categories of text prompts. Although some benchmarks have categorized the prompts, their categorization either only focuses on a single aspect or fails to consider the temporal information in video generation. Secondly, it is unclear whether the automatic evaluation metrics are consistent with human standards. To address these problems, we propose FETV, a benchmark for Fine-grained Evaluation of Text-to-Video generation. FETV is multi-aspect, categorizing the prompts based on three orthogonal aspects: the major content, the attributes to control and the prompt complexity. FETV is also temporal-aware, which introduces several temporal categories tailored for video generation. Based on FETV, we conduct comprehensive manual evaluations of four representative T2V models, revealing their pros and cons on different categories of prompts from different aspects. We also extend FETV as a testbed to evaluate the reliability of automatic T2V metrics. The multi-aspect categorization of FETV enables fine-grained analysis of the metrics' reliability in different scenarios. We find that existing automatic metrics (e.g., CLIPScore and FVD) correlate poorly with human evaluation. To address this problem, we explore several solutions to improve CLIPScore and FVD, and develop two automatic metrics that exhibit significant higher correlation with humans than existing metrics. Benchmark page: https://github.com/llyx97/FETV.
TESTA: Temporal-Spatial Token Aggregation for Long-form Video-Language Understanding
Oct 29, 2023Large-scale video-language pre-training has made remarkable strides in advancing video-language understanding tasks. However, the heavy computational burden of video encoding remains a formidable efficiency bottleneck, particularly for long-form videos. These videos contain massive visual tokens due to their inherent 3D properties and spatiotemporal redundancy, making it challenging to capture complex temporal and spatial relationships. To tackle this issue, we propose an efficient method called TEmporal-Spatial Token Aggregation (TESTA). TESTA condenses video semantics by adaptively aggregating similar frames, as well as similar patches within each frame. TESTA can reduce the number of visual tokens by 75% and thus accelerate video encoding. Building upon TESTA, we introduce a pre-trained video-language model equipped with a divided space-time token aggregation module in each video encoder block. We evaluate our model on five datasets for paragraph-to-video retrieval and long-form VideoQA tasks. Experimental results show that TESTA improves computing efficiency by 1.7 times, and achieves significant performance gains from its scalability in processing longer input frames, e.g., +13.7 R@1 on QuerYD and +6.5 R@1 on Condensed Movie.