 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoli Bai
Visually Guided Generative Text-Layout Pre-training for Document Intelligence
Mar 27, 2024
Prior study shows that pre-training techniques can boost the performance of visual document understanding (VDU), which typically requires models to gain abilities to perceive and reason both document texts and layouts (e.g., locations of texts and table-cells). To this end, we propose visually guided generative text-layout pre-training, named ViTLP. Given a document image, the model optimizes hierarchical language and layout modeling objectives to generate the interleaved text and layout sequence. In addition, to address the limitation of processing long documents by Transformers, we introduce a straightforward yet effective multi-segment generative pre-training scheme, facilitating ViTLP to process word-intensive documents of any length. ViTLP can function as a native OCR model to localize and recognize texts of document images. Besides, ViTLP can be effectively applied to various downstream VDU tasks. Extensive experiments show that ViTLP achieves competitive performance over existing baselines on benchmark VDU tasks, including information extraction, document classification, and document question answering.
MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
Mar 12, 2024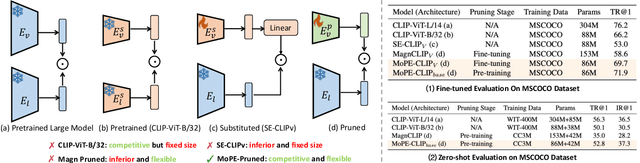
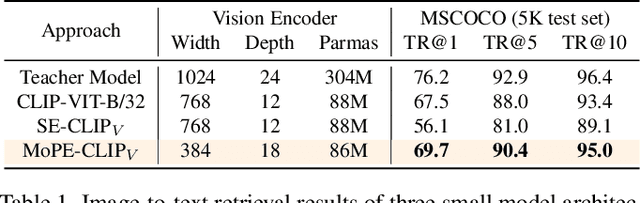
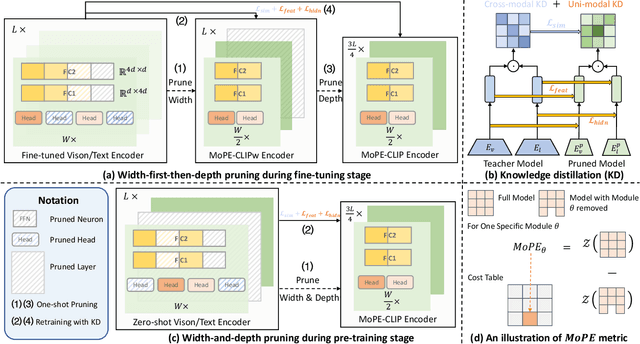
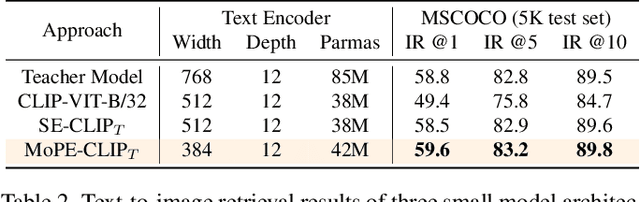
Vision-language pre-trained models have achieved impressive performance on various downstream tasks. However, their large model sizes hinder their utilization on platforms with limited computational resources. We find that directly using smaller pre-trained models and applying magnitude-based pruning on CLIP models leads to inflexibility and inferior performance. Recent efforts for VLP compression either adopt uni-modal compression metrics resulting in limited performance or involve costly mask-search processes with learnable masks. In this paper, we first propose the Module-wise Pruning Error (MoPE) metric, accurately assessing CLIP module importance by performance decline on cross-modal tasks. Using the MoPE metric, we introduce a unified pruning framework applicable to both pre-training and task-specific fine-tuning compression stages. For pre-training, MoPE-CLIP effectively leverages knowledge from the teacher model, significantly reducing pre-training costs while maintaining strong zero-shot capabilities. For fine-tuning, consecutive pruning from width to depth yields highly competitive task-specific models. Extensive experiments in two stages demonstrate the effectiveness of the MoPE metric, and MoPE-CLIP outperforms previous state-of-the-art VLP compression methods.
* 18 pages, 8 figures, Published in CVPR2024
IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact
Mar 02, 2024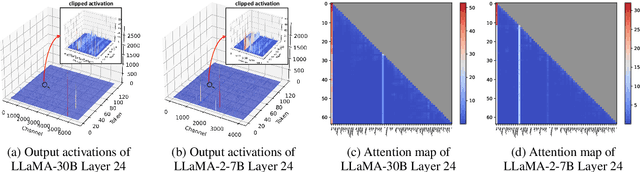
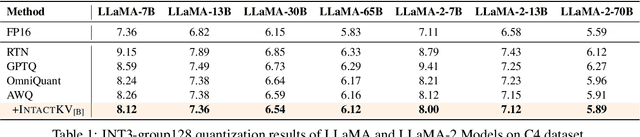

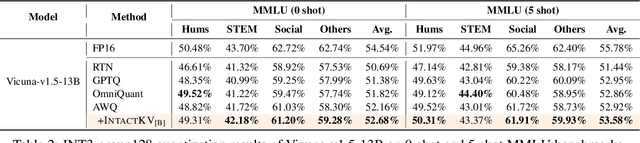
Large language models (LLMs) excel in natural language processing but demand intensive computation. To mitigate this, various quantization methods have been explored, yet they compromise LLM performance. This paper unveils a previously overlooked type of outlier in LLMs. Such outliers are found to allocate most of the attention scores on initial tokens of input, termed as pivot tokens, which is crucial to the performance of quantized LLMs. Given that, we propose IntactKV to generate the KV cache of pivot tokens losslessly from the full-precision model. The approach is simple and easy to combine with existing quantization solutions. Besides, IntactKV can be calibrated as additional LLM parameters to boost the quantized LLMs further. Mathematical analysis also proves that IntactKV effectively reduces the upper bound of quantization error. Empirical results show that IntactKV brings consistent improvement and achieves lossless weight-only INT4 quantization on various downstream tasks, leading to the new state-of-the-art for LLM quantization.
Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding
Dec 19, 2022
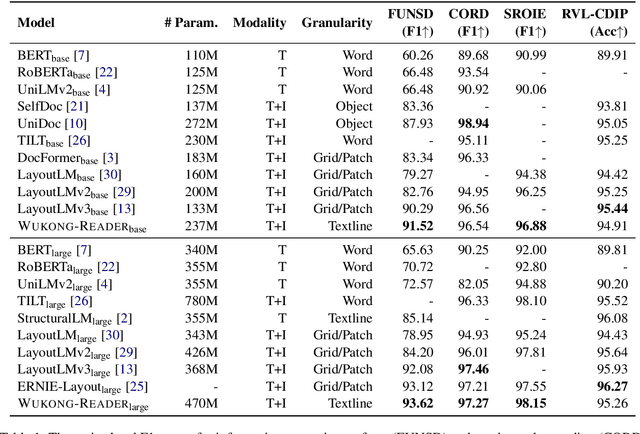
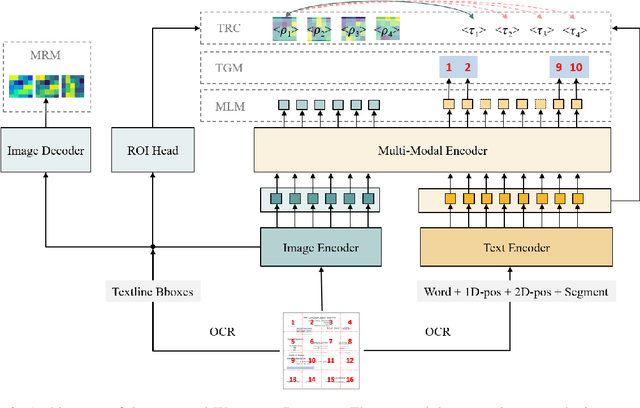
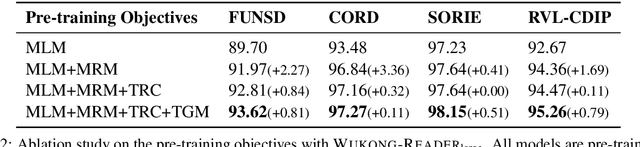
Unsupervised pre-training on millions of digital-born or scanned documents has shown promising advances in visual document understanding~(VDU). While various vision-language pre-training objectives are studied in existing solutions, the document textline, as an intrinsic granularity in VDU, has seldom been explored so far. A document textline usually contains words that are spatially and semantically correlated, which can be easily obtained from OCR engines. In this paper, we propose Wukong-Reader, trained with new pre-training objectives to leverage the structural knowledge nested in document textlines. We introduce textline-region contrastive learning to achieve fine-grained alignment between the visual regions and texts of document textlines. Furthermore, masked region modeling and textline-grid matching are also designed to enhance the visual and layout representations of textlines. Experiments show that our Wukong-Reader has superior performance on various VDU tasks such as information extraction. The fine-grained alignment over textlines also empowers Wukong-Reader with promising localization ability.
Dynamically pruning segformer for efficient semantic segmentation
Nov 18, 2021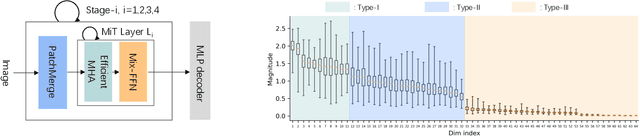
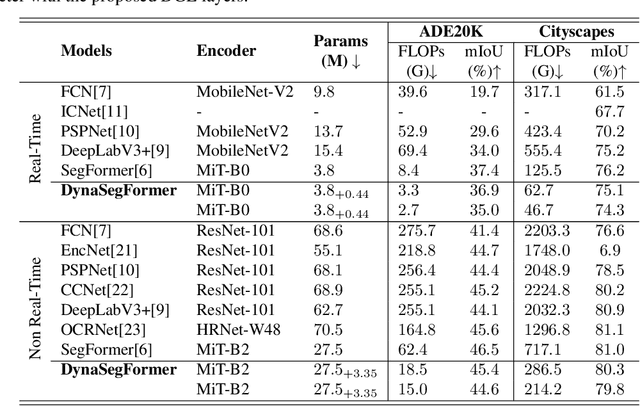
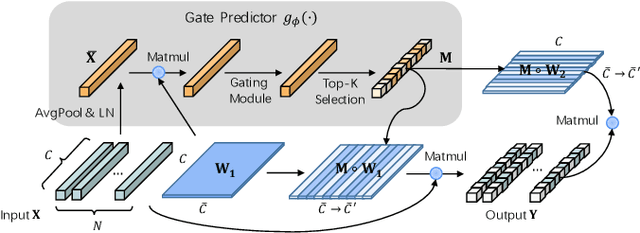
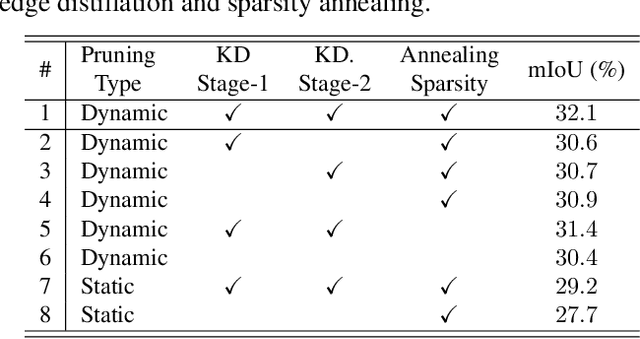
As one of the successful Transformer-based models in computer vision tasks, SegFormer demonstrates superior performance in semantic segmentation. Nevertheless, the high computational cost greatly challenges the deployment of SegFormer on edge devices. In this paper, we seek to design a lightweight SegFormer for efficient semantic segmentation. Based on the observation that neurons in SegFormer layers exhibit large variances across different images, we propose a dynamic gated linear layer, which prunes the most uninformative set of neurons based on the input instance. To improve the dynamically pruned SegFormer, we also introduce two-stage knowledge distillation to transfer the knowledge within the original teacher to the pruned student network. Experimental results show that our method can significantly reduce the computation overhead of SegFormer without an apparent performance drop. For instance, we can achieve 36.9% mIoU with only 3.3G FLOPs on ADE20K, saving more than 60% computation with the drop of only 0.5% in mIoU
Towards Efficient Post-training Quantization of Pre-trained Language Models
Sep 30, 2021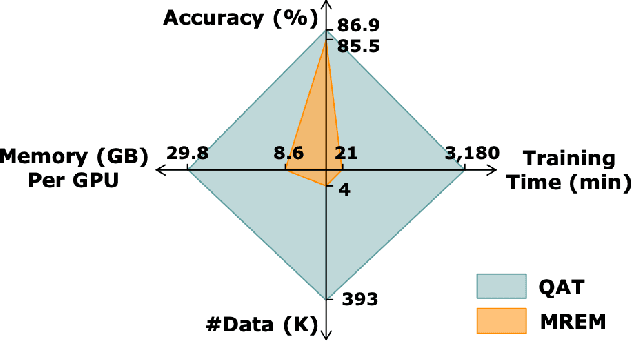
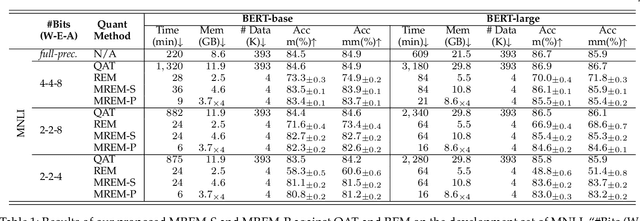
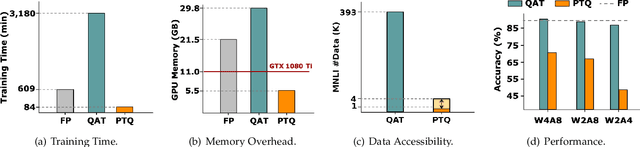
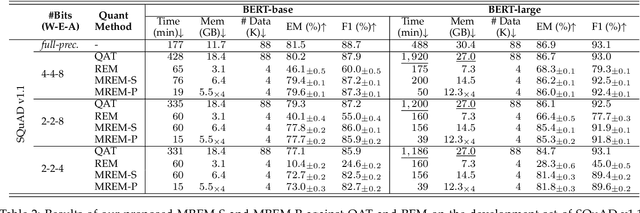
Network quantization has gained increasing attention with the rapid growth of large pre-trained language models~(PLMs). However, most existing quantization methods for PLMs follow quantization-aware training~(QAT) that requires end-to-end training with full access to the entire dataset. Therefore, they suffer from slow training, large memory overhead, and data security issues. In this paper, we study post-training quantization~(PTQ) of PLMs, and propose module-wise quantization error minimization~(MREM), an efficient solution to mitigate these issues. By partitioning the PLM into multiple modules, we minimize the reconstruction error incurred by quantization for each module. In addition, we design a new model parallel training strategy such that each module can be trained locally on separate computing devices without waiting for preceding modules, which brings nearly the theoretical training speed-up (e.g., $4\times$ on $4$ GPUs). Experiments on GLUE and SQuAD benchmarks show that our proposed PTQ solution not only performs close to QAT, but also enjoys significant reductions in training time, memory overhead, and data consumption.
Discrete Auto-regressive Variational Attention Models for Text Modeling
Jun 16, 2021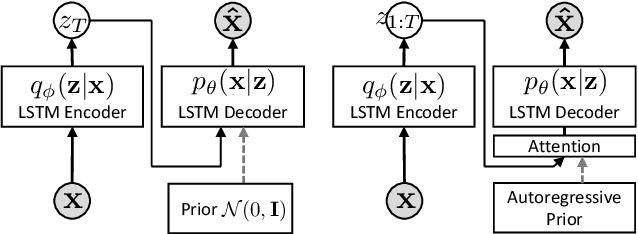
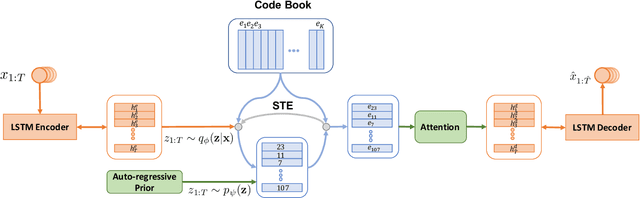
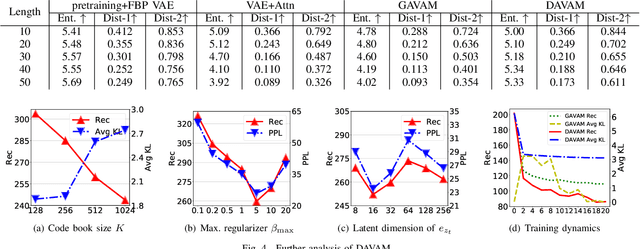
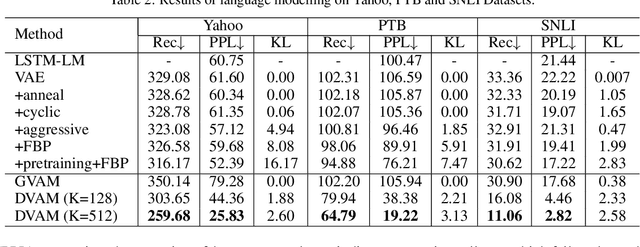
Variational autoencoders (VAEs) have been widely applied for text modeling. In practice, however, they are troubled by two challenges: information underrepresentation and posterior collapse. The former arises as only the last hidden state of LSTM encoder is transformed into the latent space, which is generally insufficient to summarize the data. The latter is a long-standing problem during the training of VAEs as the optimization is trapped to a disastrous local optimum. In this paper, we propose Discrete Auto-regressive Variational Attention Model (DAVAM) to address the challenges. Specifically, we introduce an auto-regressive variational attention approach to enrich the latent space by effectively capturing the semantic dependency from the input. We further design discrete latent space for the variational attention and mathematically show that our model is free from posterior collapse. Extensive experiments on language modeling tasks demonstrate the superiority of DAVAM against several VAE counterparts.
BinaryBERT: Pushing the Limit of BERT Quantization
Dec 31, 2020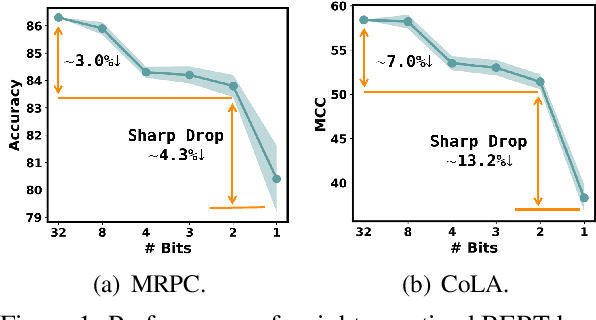
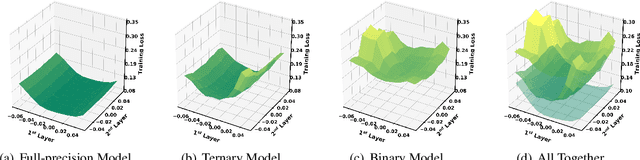
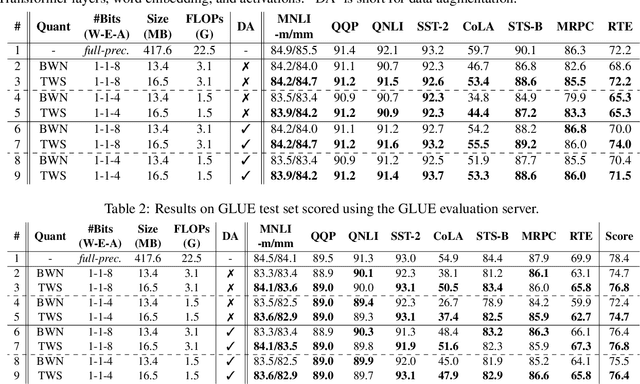
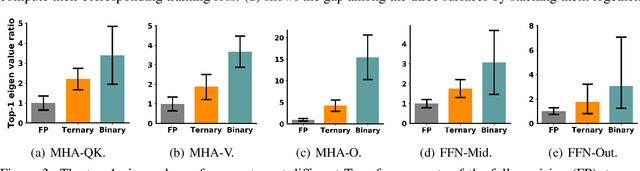
The rapid development of large pre-trained language models has greatly increased the demand for model compression techniques, among which quantization is a popular solution. In this paper, we propose BinaryBERT, which pushes BERT quantization to the limit with weight binarization. We find that a binary BERT is hard to be trained directly than a ternary counterpart due to its complex and irregular loss landscapes. Therefore, we propose ternary weight splitting, which initializes the binary model by equivalent splitting from a half-sized ternary network. The binary model thus inherits the good performance of the ternary model, and can be further enhanced by fine-tuning the new architecture after splitting. Empirical results show that BinaryBERT has negligible performance drop compared to the full-precision BERT-base while being $24\times$ smaller, achieving the state-of-the-art results on GLUE and SQuAD benchmarks.
Discrete Variational Attention Models for Language Generation
Apr 21, 2020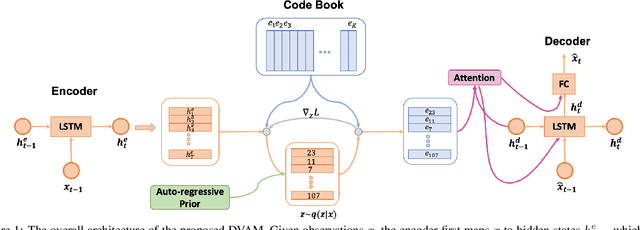
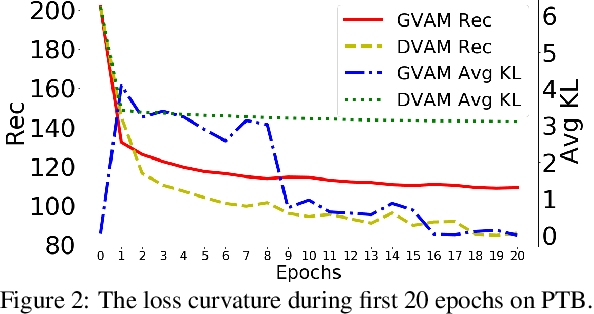
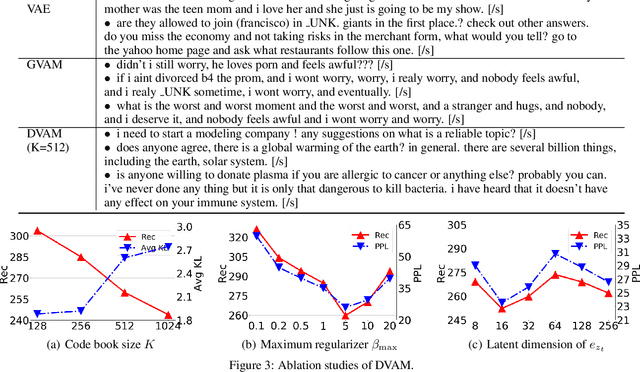
Variational autoencoders have been widely applied for natural language generation, however, there are two long-standing problems: information under-representation and posterior collapse. The former arises from the fact that only the last hidden state from the encoder is transformed to the latent space, which is insufficient to summarize data. The latter comes as a result of the imbalanced scale between the reconstruction loss and the KL divergence in the objective function. To tackle these issues, in this paper we propose the discrete variational attention model with categorical distribution over the attention mechanism owing to the discrete nature in languages. Our approach is combined with an auto-regressive prior to capture the sequential dependency from observations, which can enhance the latent space for language generation. Moreover, thanks to the property of discreteness, the training of our proposed approach does not suffer from posterior collapse. Furthermore, we carefully analyze the superiority of discrete latent space over the continuous space with the common Gaussian distribution. Extensive experiments on language generation demonstrate superior advantages of our proposed approach in comparison with the state-of-the-art counterparts.
Efficient Bitwidth Search for Practical Mixed Precision Neural Network
Mar 17, 2020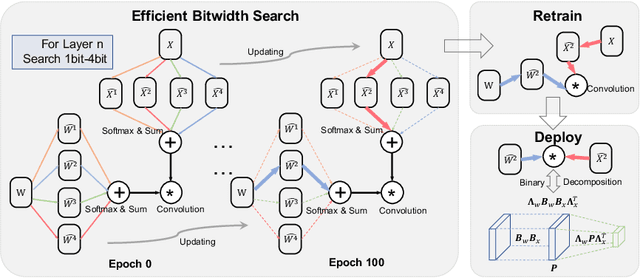
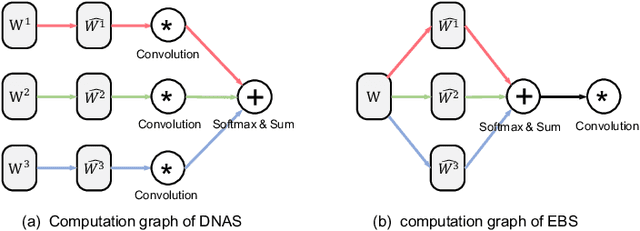
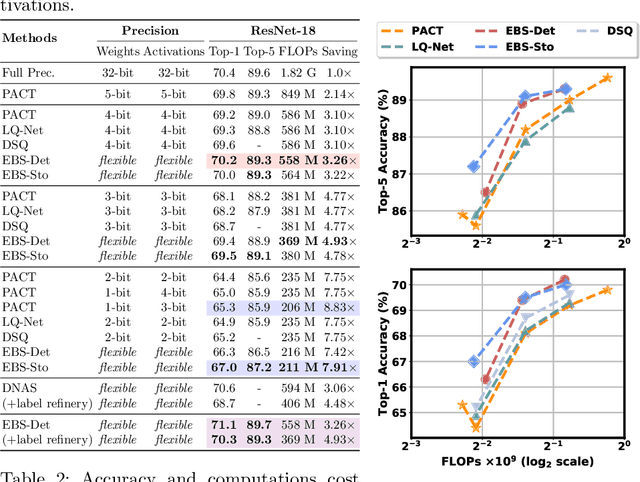

Network quantization has rapidly become one of the most widely used methods to compress and accelerate deep neural networks. Recent efforts propose to quantize weights and activations from different layers with different precision to improve the overall performance. However, it is challenging to find the optimal bitwidth (i.e., precision) for weights and activations of each layer efficiently. Meanwhile, it is yet unclear how to perform convolution for weights and activations of different precision efficiently on generic hardware platforms. To resolve these two issues, in this paper, we first propose an Efficient Bitwidth Search (EBS) algorithm, which reuses the meta weights for different quantization bitwidth and thus the strength for each candidate precision can be optimized directly w.r.t the objective without superfluous copies, reducing both the memory and computational cost significantly. Second, we propose a binary decomposition algorithm that converts weights and activations of different precision into binary matrices to make the mixed precision convolution efficient and practical. Experiment results on CIFAR10 and ImageNet datasets demonstrate our mixed precision QNN outperforms the handcrafted uniform bitwidth counterparts and other mixed precision techniques.