 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinqi Song
Benchmarking and Improving Compositional Generalization of Multi-aspect Controllable Text Generation
Apr 05, 2024
Compositional generalization, representing the model's ability to generate text with new attribute combinations obtained by recombining single attributes from the training data, is a crucial property for multi-aspect controllable text generation (MCTG) methods. Nonetheless, a comprehensive compositional generalization evaluation benchmark of MCTG is still lacking. We propose CompMCTG, a benchmark encompassing diverse multi-aspect labeled datasets and a crafted three-dimensional evaluation protocol, to holistically evaluate the compositional generalization of MCTG approaches. We observe that existing MCTG works generally confront a noticeable performance drop in compositional testing. To mitigate this issue, we introduce Meta-MCTG, a training framework incorporating meta-learning, where we enable models to learn how to generalize by simulating compositional generalization scenarios in the training phase. We demonstrate the effectiveness of Meta-MCTG through achieving obvious improvement (by at most 3.64%) for compositional testing performance in 94.4% cases.
Learning From Correctness Without Prompting Makes LLM Efficient Reasoner
Mar 28, 2024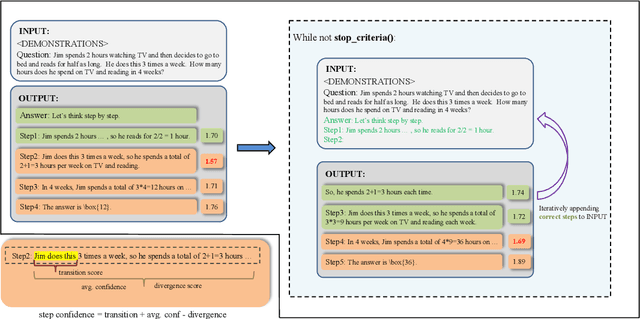
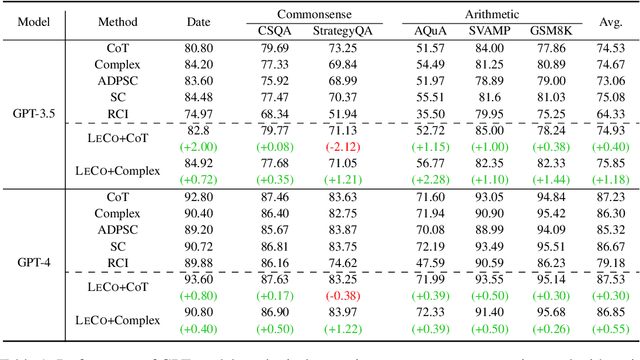
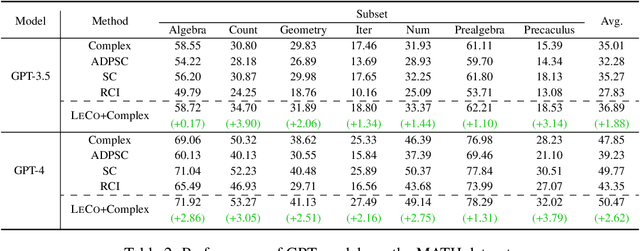
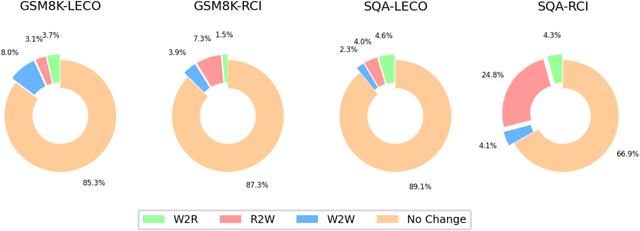
Large language models (LLMs) have demonstrated outstanding performance across various tasks, yet they still exhibit limitations such as hallucination, unfaithful reasoning, and toxic content. One potential approach to mitigate these issues is learning from human or external feedback (e.g. tools). In this paper, we introduce an intrinsic self-correct reasoning framework for LLMs that eliminates the need for human feedback, external tools, and handcraft prompts. The proposed framework, based on a multi-step reasoning paradigm \textbf{Le}arning from \textbf{Co}rrectness (\textsc{LeCo}), improves reasoning performance without needing to learn from errors. This paradigm prioritizes learning from correct reasoning steps, and a unique method to measure confidence for each reasoning step based on generation logits. Experimental results across various multi-step reasoning tasks demonstrate the effectiveness of the framework in improving reasoning performance with reduced token consumption.
Can LLM Substitute Human Labeling? A Case Study of Fine-grained Chinese Address Entity Recognition Dataset for UAV Delivery
Mar 19, 2024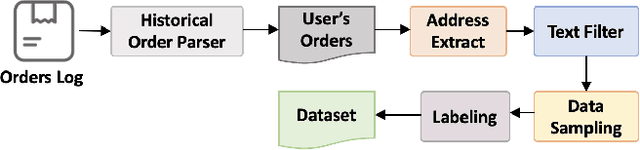
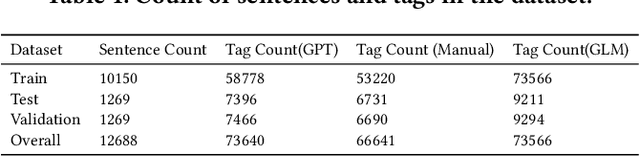
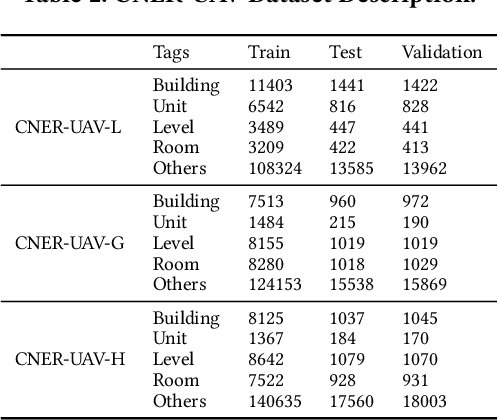
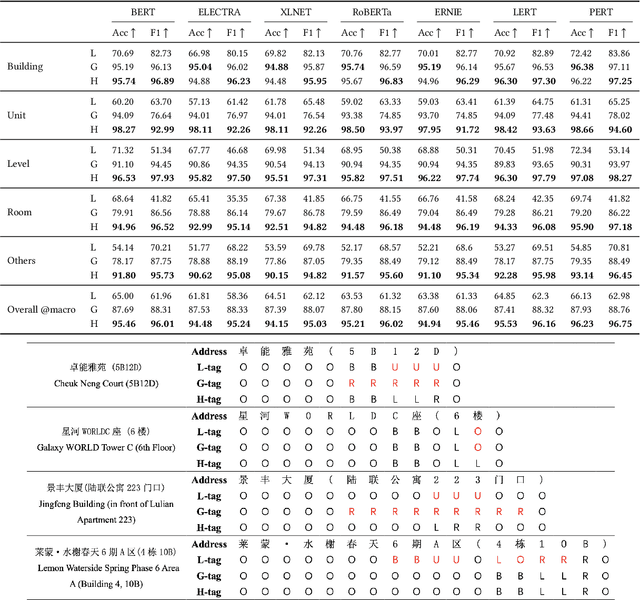
We present CNER-UAV, a fine-grained \textbf{C}hinese \textbf{N}ame \textbf{E}ntity \textbf{R}ecognition dataset specifically designed for the task of address resolution in \textbf{U}nmanned \textbf{A}erial \textbf{V}ehicle delivery systems. The dataset encompasses a diverse range of five categories, enabling comprehensive training and evaluation of NER models. To construct this dataset, we sourced the data from a real-world UAV delivery system and conducted a rigorous data cleaning and desensitization process to ensure privacy and data integrity. The resulting dataset, consisting of around 12,000 annotated samples, underwent human experts and \textbf{L}arge \textbf{L}anguage \textbf{M}odel annotation. We evaluated classical NER models on our dataset and provided in-depth analysis. The dataset and models are publicly available at \url{https://github.com/zhhvvv/CNER-UAV}.
MoPE-CLIP: Structured Pruning for Efficient Vision-Language Models with Module-wise Pruning Error Metric
Mar 12, 2024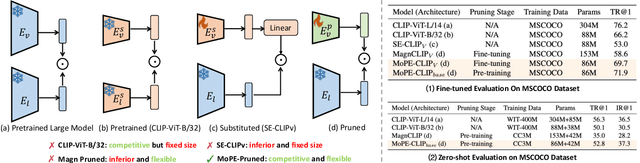
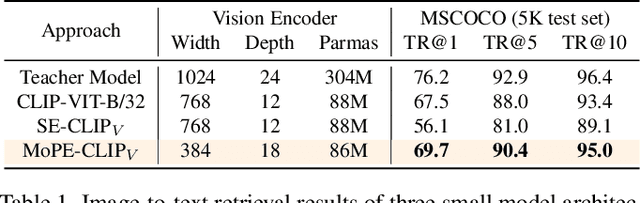
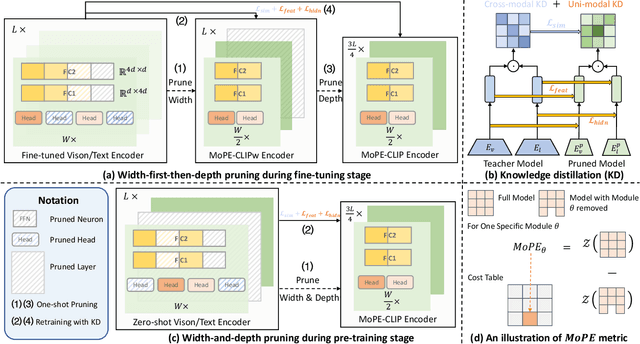
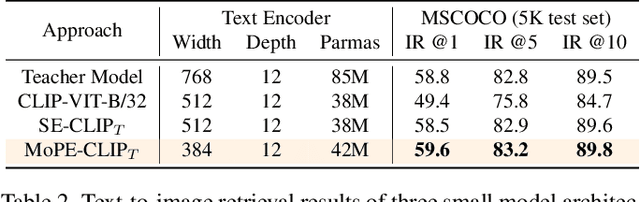
Vision-language pre-trained models have achieved impressive performance on various downstream tasks. However, their large model sizes hinder their utilization on platforms with limited computational resources. We find that directly using smaller pre-trained models and applying magnitude-based pruning on CLIP models leads to inflexibility and inferior performance. Recent efforts for VLP compression either adopt uni-modal compression metrics resulting in limited performance or involve costly mask-search processes with learnable masks. In this paper, we first propose the Module-wise Pruning Error (MoPE) metric, accurately assessing CLIP module importance by performance decline on cross-modal tasks. Using the MoPE metric, we introduce a unified pruning framework applicable to both pre-training and task-specific fine-tuning compression stages. For pre-training, MoPE-CLIP effectively leverages knowledge from the teacher model, significantly reducing pre-training costs while maintaining strong zero-shot capabilities. For fine-tuning, consecutive pruning from width to depth yields highly competitive task-specific models. Extensive experiments in two stages demonstrate the effectiveness of the MoPE metric, and MoPE-CLIP outperforms previous state-of-the-art VLP compression methods.
* 18 pages, 8 figures, Published in CVPR2024
Understanding and Patching Compositional Reasoning in LLMs
Feb 22, 2024LLMs have marked a revolutonary shift, yet they falter when faced with compositional reasoning tasks. Our research embarks on a quest to uncover the root causes of compositional reasoning failures of LLMs, uncovering that most of them stem from the improperly generated or leveraged implicit reasoning results. Inspired by our empirical findings, we resort to Logit Lens and an intervention experiment to dissect the inner hidden states of LLMs. This deep dive reveals that implicit reasoning results indeed surface within middle layers and play a causative role in shaping the final explicit reasoning results. Our exploration further locates multi-head self-attention (MHSA) modules within these layers, which emerge as the linchpins in accurate generation and leveraing of implicit reasoning results. Grounded on the above findings, we develop CREME, a lightweight method to patch errors in compositional reasoning via editing the located MHSA modules. Our empirical evidence stands testament to CREME's effectiveness, paving the way for autonomously and continuously enhancing compositional reasoning capabilities in language models.
MUSTARD: Mastering Uniform Synthesis of Theorem and Proof Data
Feb 14, 2024Recent large language models (LLMs) have witnessed significant advancement in various tasks, including mathematical reasoning and theorem proving. As these two tasks require strict and formal multi-step inference, they are appealing domains for exploring the reasoning ability of LLMs but still face important challenges. Previous studies such as Chain-of-Thought (CoT) have revealed the effectiveness of intermediate steps guidance. However, such step-wise annotation requires heavy labor, leading to insufficient training steps for current benchmarks. To fill this gap, this work introduces MUSTARD, a data generation framework that masters uniform synthesis of theorem and proof data of high quality and diversity. MUSTARD synthesizes data in three stages: (1) It samples a few mathematical concept seeds as the problem category. (2) Then, it prompts a generative language model with the sampled concepts to obtain both the problems and their step-wise formal solutions. (3) Lastly, the framework utilizes a proof assistant (e.g., Lean Prover) to filter the valid proofs. With the proposed MUSTARD, we present a theorem-and-proof benchmark MUSTARDSAUCE with 5,866 valid data points. Each data point contains an informal statement, an informal proof, and a translated formal proof that passes the prover validation. We perform extensive analysis and demonstrate that MUSTARD generates validated high-quality step-by-step data. We further apply the MUSTARDSAUCE for fine-tuning smaller language models. The fine-tuned Llama 2-7B achieves a 15.41% average relative performance gain in automated theorem proving, and 8.18% in math word problems. Codes and data are available at https://github.com/Eleanor-H/MUSTARD.
Truncated Non-Uniform Quantization for Distributed SGD
Feb 02, 2024To address the communication bottleneck challenge in distributed learning, our work introduces a novel two-stage quantization strategy designed to enhance the communication efficiency of distributed Stochastic Gradient Descent (SGD). The proposed method initially employs truncation to mitigate the impact of long-tail noise, followed by a non-uniform quantization of the post-truncation gradients based on their statistical characteristics. We provide a comprehensive convergence analysis of the quantized distributed SGD, establishing theoretical guarantees for its performance. Furthermore, by minimizing the convergence error, we derive optimal closed-form solutions for the truncation threshold and non-uniform quantization levels under given communication constraints. Both theoretical insights and extensive experimental evaluations demonstrate that our proposed algorithm outperforms existing quantization schemes, striking a superior balance between communication efficiency and convergence performance.
Improved Quantization Strategies for Managing Heavy-tailed Gradients in Distributed Learning
Feb 02, 2024Gradient compression has surfaced as a key technique to address the challenge of communication efficiency in distributed learning. In distributed deep learning, however, it is observed that gradient distributions are heavy-tailed, with outliers significantly influencing the design of compression strategies. Existing parameter quantization methods experience performance degradation when this heavy-tailed feature is ignored. In this paper, we introduce a novel compression scheme specifically engineered for heavy-tailed gradients, which effectively combines gradient truncation with quantization. This scheme is adeptly implemented within a communication-limited distributed Stochastic Gradient Descent (SGD) framework. We consider a general family of heavy-tail gradients that follow a power-law distribution, we aim to minimize the error resulting from quantization, thereby determining optimal values for two critical parameters: the truncation threshold and the quantization density. We provide a theoretical analysis on the convergence error bound under both uniform and non-uniform quantization scenarios. Comparative experiments with other benchmarks demonstrate the effectiveness of our proposed method in managing the heavy-tailed gradients in a distributed learning environment.
PROXYQA: An Alternative Framework for Evaluating Long-Form Text Generation with Large Language Models
Jan 26, 2024Large Language Models (LLMs) have exhibited remarkable success in long-form context comprehension tasks. However, their capacity to generate long contents, such as reports and articles, remains insufficiently explored. Current benchmarks do not adequately assess LLMs' ability to produce informative and comprehensive content, necessitating a more rigorous evaluation approach. In this study, we introduce \textsc{ProxyQA}, a framework for evaluating long-form text generation, comprising in-depth human-curated \textit{meta-questions} spanning various domains. Each meta-question contains corresponding \textit{proxy-questions} with annotated answers. LLMs are prompted to generate extensive content in response to these meta-questions. Utilizing an evaluator and incorporating generated content as background context, \textsc{ProxyQA} evaluates the quality of generated content based on the evaluator's performance in answering the \textit{proxy-questions}. We examine multiple LLMs, emphasizing \textsc{ProxyQA}'s demanding nature as a high-quality assessment tool. Human evaluation demonstrates that evaluating through \textit{proxy-questions} is a highly self-consistent and human-criteria-correlated validation method. The dataset and leaderboard will be available at \url{https://github.com/Namco0816/ProxyQA}.
Integrating Large Language Models into Recommendation via Mutual Augmentation and Adaptive Aggregation
Jan 25, 2024Conventional recommendation methods have achieved notable advancements by harnessing collaborative or sequential information from user behavior. Recently, large language models (LLMs) have gained prominence for their capabilities in understanding and reasoning over textual semantics, and have found utility in various domains, including recommendation. Conventional recommendation methods and LLMs each have their strengths and weaknesses. While conventional methods excel at mining collaborative information and modeling sequential behavior, they struggle with data sparsity and the long-tail problem. LLMs, on the other hand, are proficient at utilizing rich textual contexts but face challenges in mining collaborative or sequential information. Despite their individual successes, there is a significant gap in leveraging their combined potential to enhance recommendation performance. In this paper, we introduce a general and model-agnostic framework known as \textbf{L}arge \textbf{la}nguage model with \textbf{m}utual augmentation and \textbf{a}daptive aggregation for \textbf{Rec}ommendation (\textbf{Llama4Rec}). Llama4Rec synergistically combines conventional and LLM-based recommendation models. Llama4Rec proposes data augmentation and prompt augmentation strategies tailored to enhance the conventional model and LLM respectively. An adaptive aggregation module is adopted to combine the predictions of both kinds of models to refine the final recommendation results. Empirical studies on three real-world datasets validate the superiority of Llama4Rec, demonstrating its consistent outperformance of baseline methods and significant improvements in recommendation performance.