 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhengying Liu
MUSTARD: Mastering Uniform Synthesis of Theorem and Proof Data
Feb 14, 2024
Recent large language models (LLMs) have witnessed significant advancement in various tasks, including mathematical reasoning and theorem proving. As these two tasks require strict and formal multi-step inference, they are appealing domains for exploring the reasoning ability of LLMs but still face important challenges. Previous studies such as Chain-of-Thought (CoT) have revealed the effectiveness of intermediate steps guidance. However, such step-wise annotation requires heavy labor, leading to insufficient training steps for current benchmarks. To fill this gap, this work introduces MUSTARD, a data generation framework that masters uniform synthesis of theorem and proof data of high quality and diversity. MUSTARD synthesizes data in three stages: (1) It samples a few mathematical concept seeds as the problem category. (2) Then, it prompts a generative language model with the sampled concepts to obtain both the problems and their step-wise formal solutions. (3) Lastly, the framework utilizes a proof assistant (e.g., Lean Prover) to filter the valid proofs. With the proposed MUSTARD, we present a theorem-and-proof benchmark MUSTARDSAUCE with 5,866 valid data points. Each data point contains an informal statement, an informal proof, and a translated formal proof that passes the prover validation. We perform extensive analysis and demonstrate that MUSTARD generates validated high-quality step-by-step data. We further apply the MUSTARDSAUCE for fine-tuning smaller language models. The fine-tuned Llama 2-7B achieves a 15.41% average relative performance gain in automated theorem proving, and 8.18% in math word problems. Codes and data are available at https://github.com/Eleanor-H/MUSTARD.
A Survey of Reasoning with Foundation Models
Dec 26, 2023Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation. It serves as a fundamental methodology in the field of Artificial General Intelligence (AGI). With the ongoing development of foundation models, there is a growing interest in exploring their abilities in reasoning tasks. In this paper, we introduce seminal foundation models proposed or adaptable for reasoning, highlighting the latest advancements in various reasoning tasks, methods, and benchmarks. We then delve into the potential future directions behind the emergence of reasoning abilities within foundation models. We also discuss the relevance of multimodal learning, autonomous agents, and super alignment in the context of reasoning. By discussing these future research directions, we hope to inspire researchers in their exploration of this field, stimulate further advancements in reasoning with foundation models, and contribute to the development of AGI.
Large Language Models as Automated Aligners for benchmarking Vision-Language Models
Nov 24, 2023With the advancements in Large Language Models (LLMs), Vision-Language Models (VLMs) have reached a new level of sophistication, showing notable competence in executing intricate cognition and reasoning tasks. However, existing evaluation benchmarks, primarily relying on rigid, hand-crafted datasets to measure task-specific performance, face significant limitations in assessing the alignment of these increasingly anthropomorphic models with human intelligence. In this work, we address the limitations via Auto-Bench, which delves into exploring LLMs as proficient aligners, measuring the alignment between VLMs and human intelligence and value through automatic data curation and assessment. Specifically, for data curation, Auto-Bench utilizes LLMs (e.g., GPT-4) to automatically generate a vast set of question-answer-reasoning triplets via prompting on visual symbolic representations (e.g., captions, object locations, instance relationships, and etc.). The curated data closely matches human intent, owing to the extensive world knowledge embedded in LLMs. Through this pipeline, a total of 28.5K human-verified and 3,504K unfiltered question-answer-reasoning triplets have been curated, covering 4 primary abilities and 16 sub-abilities. We subsequently engage LLMs like GPT-3.5 to serve as judges, implementing the quantitative and qualitative automated assessments to facilitate a comprehensive evaluation of VLMs. Our validation results reveal that LLMs are proficient in both evaluation data curation and model assessment, achieving an average agreement rate of 85%. We envision Auto-Bench as a flexible, scalable, and comprehensive benchmark for evaluating the evolving sophisticated VLMs.
TRIGO: Benchmarking Formal Mathematical Proof Reduction for Generative Language Models
Oct 24, 2023

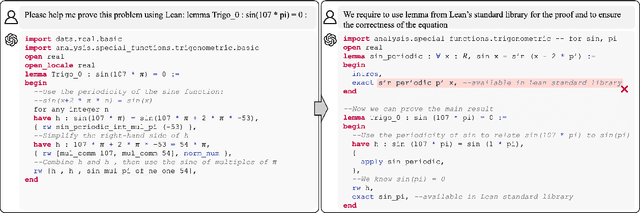
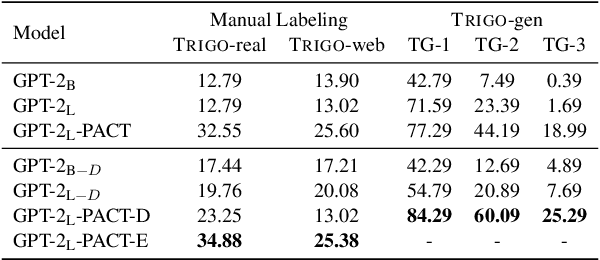
Automated theorem proving (ATP) has become an appealing domain for exploring the reasoning ability of the recent successful generative language models. However, current ATP benchmarks mainly focus on symbolic inference, but rarely involve the understanding of complex number combination reasoning. In this work, we propose TRIGO, an ATP benchmark that not only requires a model to reduce a trigonometric expression with step-by-step proofs but also evaluates a generative LM's reasoning ability on formulas and its capability to manipulate, group, and factor number terms. We gather trigonometric expressions and their reduced forms from the web, annotate the simplification process manually, and translate it into the Lean formal language system. We then automatically generate additional examples from the annotated samples to expand the dataset. Furthermore, we develop an automatic generator based on Lean-Gym to create dataset splits of varying difficulties and distributions in order to thoroughly analyze the model's generalization ability. Our extensive experiments show our proposed TRIGO poses a new challenge for advanced generative LM's including GPT-4 which is pre-trained on a considerable amount of open-source formal theorem-proving language data, and provide a new tool to study the generative LM's ability on both formal and mathematical reasoning.
Gaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis
Oct 20, 2023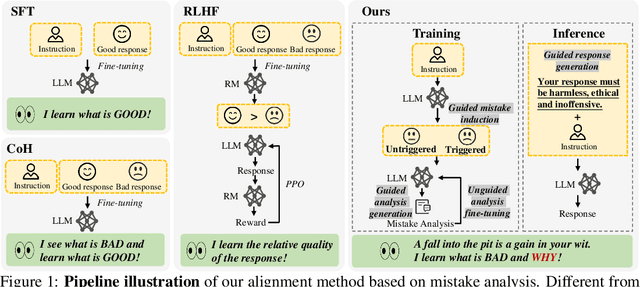
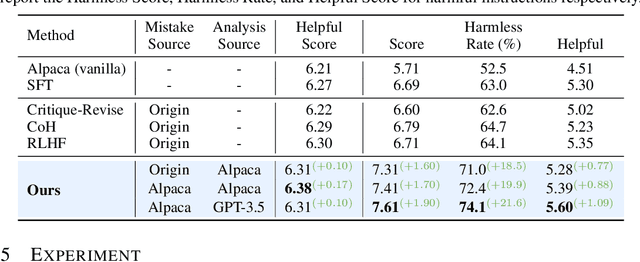
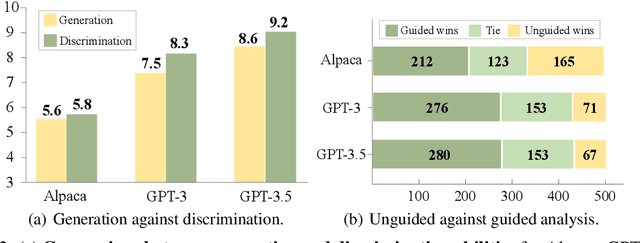
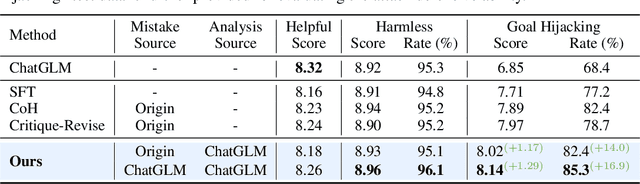
The rapid advancement of large language models (LLMs) presents both opportunities and challenges, particularly concerning unintentional generation of harmful and toxic responses. While the traditional alignment methods strive to steer LLMs towards desired performance and shield them from malicious content, this study proposes a novel alignment strategy rooted in mistake analysis by exposing LLMs to flawed outputs purposefully and then conducting a thorough assessment to fully comprehend internal reasons via natural language analysis. Thus, toxic responses can be transformed into instruction tuning corpus for model alignment, and LLMs can not only be deterred from generating flawed responses but also trained to self-criticize, leveraging its innate ability to discriminate toxic content. Experimental results demonstrate that the proposed method outperforms conventional alignment techniques for safety instruction following, while maintaining superior efficiency.
LEGO-Prover: Neural Theorem Proving with Growing Libraries
Oct 12, 2023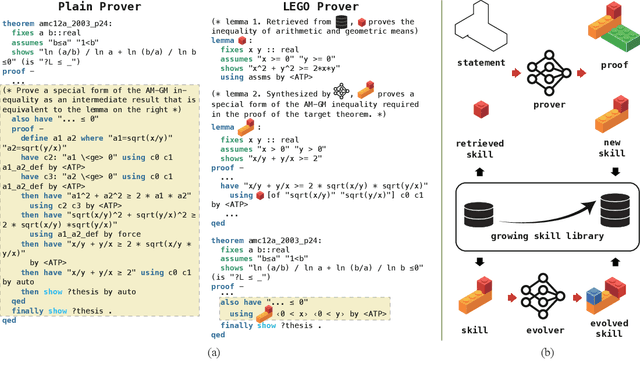
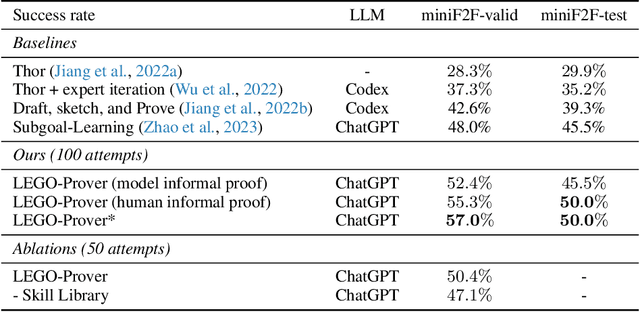
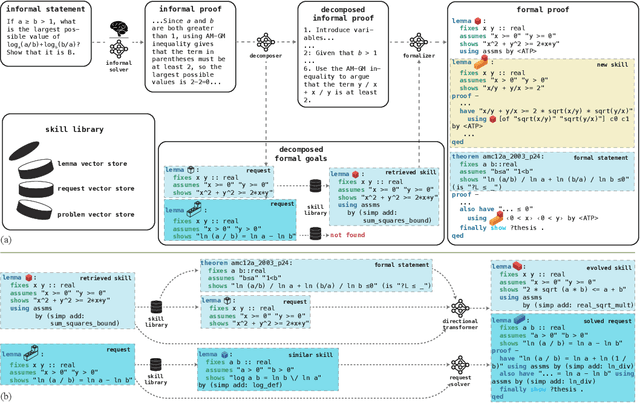

Despite the success of large language models (LLMs), the task of theorem proving still remains one of the hardest reasoning tasks that is far from being fully solved. Prior methods using language models have demonstrated promising results, but they still struggle to prove even middle school level theorems. One common limitation of these methods is that they assume a fixed theorem library during the whole theorem proving process. However, as we all know, creating new useful theorems or even new theories is not only helpful but crucial and necessary for advancing mathematics and proving harder and deeper results. In this work, we present LEGO-Prover, which employs a growing skill library containing verified lemmas as skills to augment the capability of LLMs used in theorem proving. By constructing the proof modularly, LEGO-Prover enables LLMs to utilize existing skills retrieved from the library and to create new skills during the proving process. These skills are further evolved (by prompting an LLM) to enrich the library on another scale. Modular and reusable skills are constantly added to the library to enable tackling increasingly intricate mathematical problems. Moreover, the learned library further bridges the gap between human proofs and formal proofs by making it easier to impute missing steps. LEGO-Prover advances the state-of-the-art pass rate on miniF2F-valid (48.0% to 57.0%) and miniF2F-test (45.5% to 47.1%). During the proving process, LEGO-Prover also manages to generate over 20,000 skills (theorems/lemmas) and adds them to the growing library. Our ablation study indicates that these newly added skills are indeed helpful for proving theorems, resulting in an improvement from a success rate of 47.1% to 50.4%. We also release our code and all the generated skills.
Lyra: Orchestrating Dual Correction in Automated Theorem Proving
Oct 07, 2023
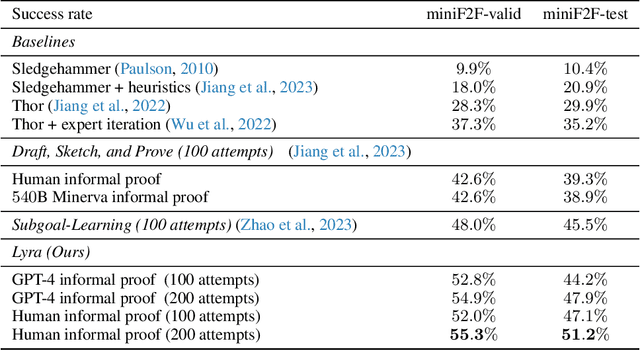
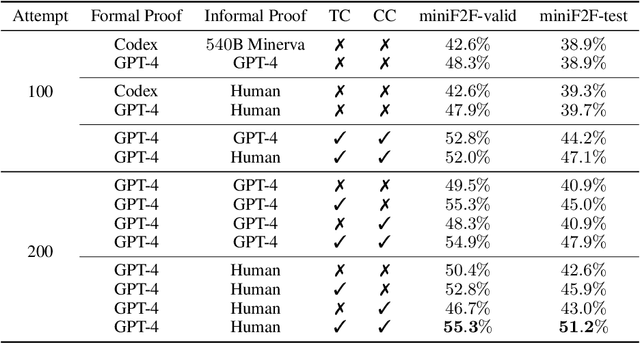
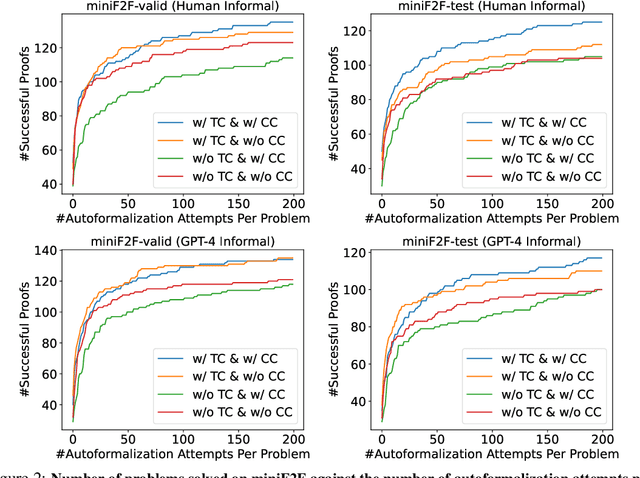
Large Language Models (LLMs) present an intriguing avenue for exploration in the field of formal theorem proving. Nevertheless, their full potential, particularly concerning the mitigation of hallucinations and refinement through prover error messages, remains an area that has yet to be thoroughly investigated. To enhance the effectiveness of LLMs in the field, we introduce the Lyra, a new framework that employs two distinct correction mechanisms: Tool Correction (TC) and Conjecture Correction (CC). To implement Tool Correction in the post-processing of formal proofs, we leverage prior knowledge to utilize predefined prover tools (e.g., Sledgehammer) for guiding the replacement of incorrect tools. Tool Correction significantly contributes to mitigating hallucinations, thereby improving the overall accuracy of the proof. In addition, we introduce Conjecture Correction, an error feedback mechanism designed to interact with prover to refine formal proof conjectures with prover error messages. Compared to the previous refinement framework, the proposed Conjecture Correction refines generation with instruction but does not collect paired (generation, error & refinement) prompts. Our method has achieved state-of-the-art (SOTA) performance on both miniF2F validation (48.0% -> 55.3%) and test (45.5% -> 51.2%). We also present 3 IMO problems solved by Lyra. We believe Tool Correction (post-process for hallucination mitigation) and Conjecture Correction (subgoal adjustment from interaction with environment) could provide a promising avenue for future research in this field.
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Sep 22, 2023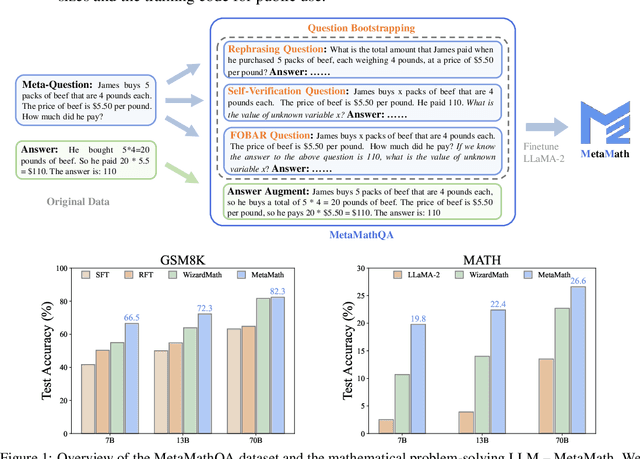
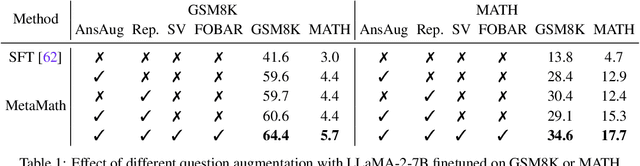
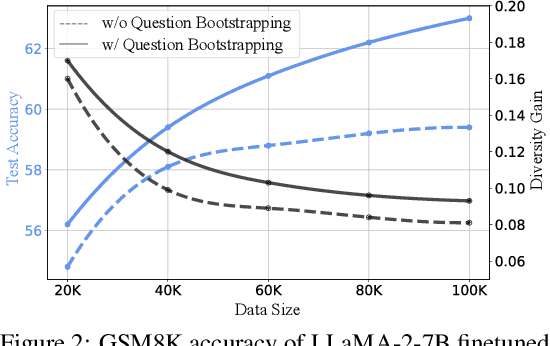

Large language models (LLMs) have pushed the limits of natural language understanding and exhibited excellent problem-solving ability. Despite the great success, most existing open-source LLMs (e.g., LLaMA-2) are still far away from satisfactory for solving mathematical problem due to the complex reasoning procedures. To bridge this gap, we propose MetaMath, a fine-tuned language model that specializes in mathematical reasoning. Specifically, we start by bootstrapping mathematical questions by rewriting the question from multiple perspectives without extra knowledge, which results in a new dataset called MetaMathQA. Then we fine-tune the LLaMA-2 models on MetaMathQA. Experimental results on two popular benchmarks (i.e., GSM8K and MATH) for mathematical reasoning demonstrate that MetaMath outperforms a suite of open-source LLMs by a significant margin. Our MetaMath-7B model achieves 66.4% on GSM8K and 19.4% on MATH, exceeding the state-of-the-art models of the same size by 11.5% and 8.7%. Particularly, MetaMath-70B achieves an accuracy of 82.3% on GSM8K, slightly better than GPT-3.5-Turbo. We release the MetaMathQA dataset, the MetaMath models with different model sizes and the training code for public use.
FIMO: A Challenge Formal Dataset for Automated Theorem Proving
Sep 08, 2023



We present FIMO, an innovative dataset comprising formal mathematical problem statements sourced from the International Mathematical Olympiad (IMO) Shortlisted Problems. Designed to facilitate advanced automated theorem proving at the IMO level, FIMO is currently tailored for the Lean formal language. It comprises 149 formal problem statements, accompanied by both informal problem descriptions and their corresponding LaTeX-based informal proofs. Through initial experiments involving GPT-4, our findings underscore the existing limitations in current methodologies, indicating a substantial journey ahead before achieving satisfactory IMO-level automated theorem proving outcomes.
Forward-Backward Reasoning in Large Language Models for Verification
Aug 23, 2023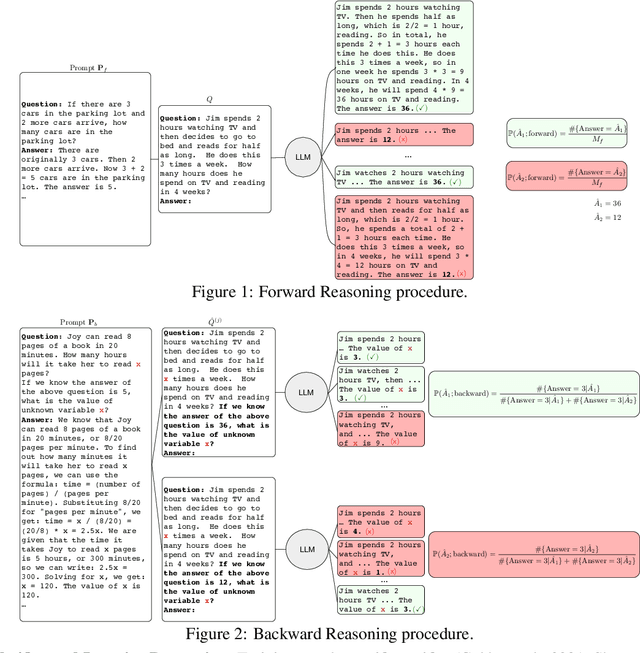

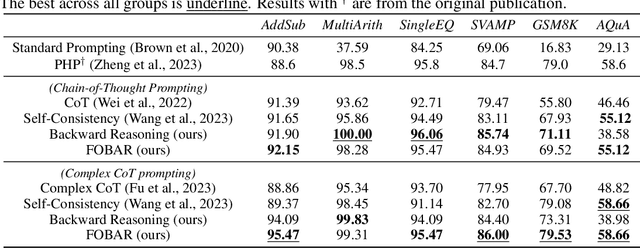
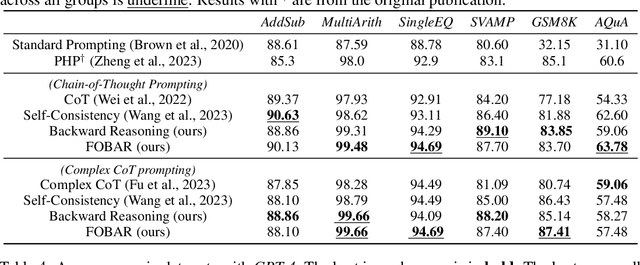
Chain-of-Though (CoT) prompting has shown promising performance in various reasoning tasks. Recently, Self-Consistency \citep{wang2023selfconsistency} proposes to sample a diverse set of reasoning chains which may lead to different answers while the answer that receives the most votes is selected. In this paper, we propose a novel method to use backward reasoning in verifying candidate answers. We mask a token in the question by ${\bf x}$ and ask the LLM to predict the masked token when a candidate answer is provided by \textit{a simple template}, i.e., "\textit{\textbf{If we know the answer of the above question is \{a candidate answer\}, what is the value of unknown variable ${\bf x}$?}}" Intuitively, the LLM is expected to predict the masked token successfully if the provided candidate answer is correct. We further propose FOBAR to combine forward and backward reasoning for estimating the probability of candidate answers. We conduct extensive experiments on six data sets and three LLMs. Experimental results demonstrate that FOBAR achieves state-of-the-art performance on various reasoning benchmarks.