 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenyong Huang
YODA: Teacher-Student Progressive Learning for Language Models
Jan 28, 2024
Although large language models (LLMs) have demonstrated adeptness in a range of tasks, they still lag behind human learning efficiency. This disparity is often linked to the inherent human capacity to learn from basic examples, gradually generalize and handle more complex problems, and refine their skills with continuous feedback. Inspired by this, this paper introduces YODA, a novel teacher-student progressive learning framework that emulates the teacher-student education process to improve the efficacy of model fine-tuning. The framework operates on an interactive \textit{basic-generalized-harder} loop. The teacher agent provides tailored feedback on the student's answers, and systematically organizes the education process. This process unfolds by teaching the student basic examples, reinforcing understanding through generalized questions, and then enhancing learning by posing questions with progressively enhanced complexity. With the teacher's guidance, the student learns to iteratively refine its answer with feedback, and forms a robust and comprehensive understanding of the posed questions. The systematic procedural data, which reflects the progressive learning process of humans, is then utilized for model training. Taking math reasoning as a testbed, experiments show that training LLaMA2 with data from YODA improves SFT with significant performance gain (+17.01\% on GSM8K and +9.98\% on MATH). In addition, we find that training with curriculum learning further improves learning robustness.
Improving End-to-End Speech Processing by Efficient Text Data Utilization with Latent Synthesis
Oct 24, 2023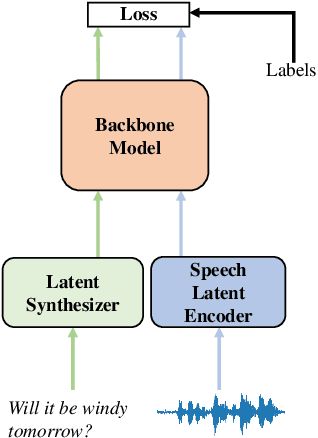
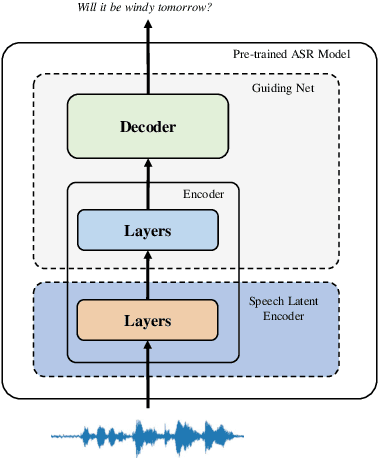

Training a high performance end-to-end speech (E2E) processing model requires an enormous amount of labeled speech data, especially in the era of data-centric artificial intelligence. However, labeled speech data are usually scarcer and more expensive for collection, compared to textual data. We propose Latent Synthesis (LaSyn), an efficient textual data utilization framework for E2E speech processing models. We train a latent synthesizer to convert textual data into an intermediate latent representation of a pre-trained speech model. These pseudo acoustic representations of textual data augment acoustic data for model training. We evaluate LaSyn on low-resource automatic speech recognition (ASR) and spoken language understanding (SLU) tasks. For ASR, LaSyn improves an E2E baseline trained on LibriSpeech train-clean-100, with relative word error rate reductions over 22.3% on different test sets. For SLU, LaSyn improves our E2E baseline by absolute 4.1% for intent classification accuracy and 3.8% for slot filling SLU-F1 on SLURP, and absolute 4.49% and 2.25% for exact match (EM) and EM-Tree accuracies on STOP respectively. With fewer parameters, the results of LaSyn are competitive to published state-of-the-art works. The results demonstrate the quality of the augmented training data.
Gaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis
Oct 20, 2023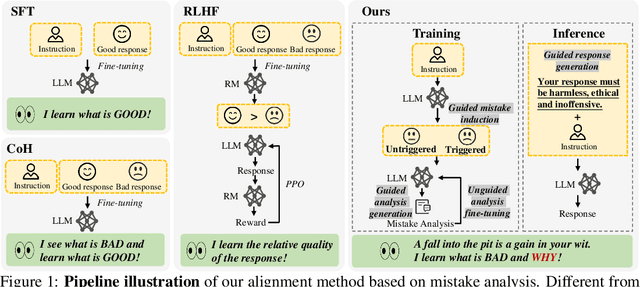
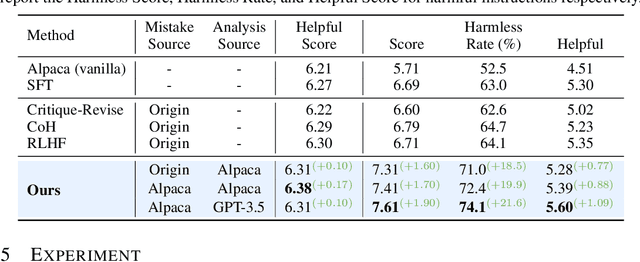
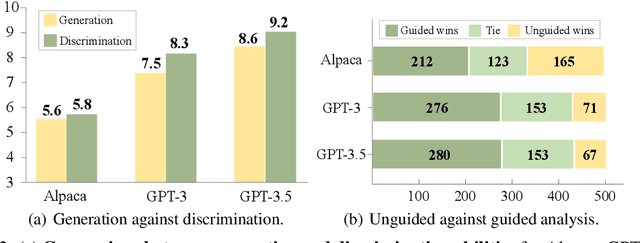
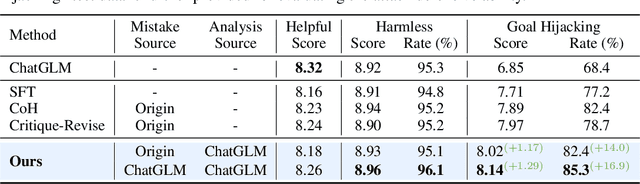
The rapid advancement of large language models (LLMs) presents both opportunities and challenges, particularly concerning unintentional generation of harmful and toxic responses. While the traditional alignment methods strive to steer LLMs towards desired performance and shield them from malicious content, this study proposes a novel alignment strategy rooted in mistake analysis by exposing LLMs to flawed outputs purposefully and then conducting a thorough assessment to fully comprehend internal reasons via natural language analysis. Thus, toxic responses can be transformed into instruction tuning corpus for model alignment, and LLMs can not only be deterred from generating flawed responses but also trained to self-criticize, leveraging its innate ability to discriminate toxic content. Experimental results demonstrate that the proposed method outperforms conventional alignment techniques for safety instruction following, while maintaining superior efficiency.
SELF: Language-Driven Self-Evolution for Large Language Model
Oct 07, 2023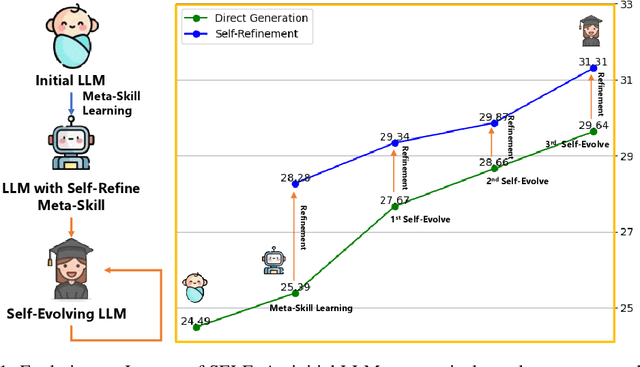
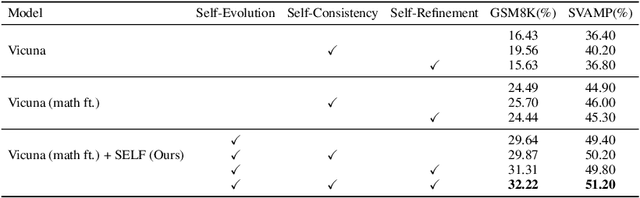
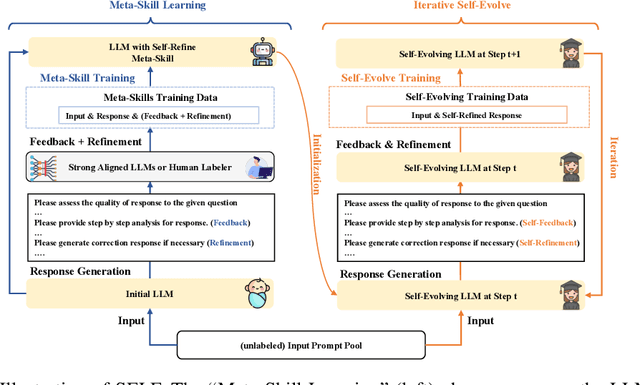

Large Language Models (LLMs) have showcased remarkable versatility across diverse domains. However, the pathway toward autonomous model development, a cornerstone for achieving human-level learning and advancing autonomous AI, remains largely uncharted. We introduce an innovative approach, termed "SELF" (Self-Evolution with Language Feedback). This methodology empowers LLMs to undergo continual self-evolution. Furthermore, SELF employs language-based feedback as a versatile and comprehensive evaluative tool, pinpointing areas for response refinement and bolstering the stability of self-evolutionary training. Initiating with meta-skill learning, SELF acquires foundational meta-skills with a focus on self-feedback and self-refinement. These meta-skills are critical, guiding the model's subsequent self-evolution through a cycle of perpetual training with self-curated data, thereby enhancing its intrinsic abilities. Given unlabeled instructions, SELF equips the model with the capability to autonomously generate and interactively refine responses. This synthesized training data is subsequently filtered and utilized for iterative fine-tuning, enhancing the model's capabilities. Experimental results on representative benchmarks substantiate that SELF can progressively advance its inherent abilities without the requirement of human intervention, thereby indicating a viable pathway for autonomous model evolution. Additionally, SELF can employ online self-refinement strategy to produce responses of superior quality. In essence, the SELF framework signifies a progressive step towards autonomous LLM development, transforming the LLM from a mere passive recipient of information into an active participant in its own evolution.
Aligning Large Language Models with Human: A Survey
Jul 24, 2023Large Language Models (LLMs) trained on extensive textual corpora have emerged as leading solutions for a broad array of Natural Language Processing (NLP) tasks. Despite their notable performance, these models are prone to certain limitations such as misunderstanding human instructions, generating potentially biased content, or factually incorrect (hallucinated) information. Hence, aligning LLMs with human expectations has become an active area of interest within the research community. This survey presents a comprehensive overview of these alignment technologies, including the following aspects. (1) Data collection: the methods for effectively collecting high-quality instructions for LLM alignment, including the use of NLP benchmarks, human annotations, and leveraging strong LLMs. (2) Training methodologies: a detailed review of the prevailing training methods employed for LLM alignment. Our exploration encompasses Supervised Fine-tuning, both Online and Offline human preference training, along with parameter-efficient training mechanisms. (3) Model Evaluation: the methods for evaluating the effectiveness of these human-aligned LLMs, presenting a multifaceted approach towards their assessment. In conclusion, we collate and distill our findings, shedding light on several promising future research avenues in the field. This survey, therefore, serves as a valuable resource for anyone invested in understanding and advancing the alignment of LLMs to better suit human-oriented tasks and expectations. An associated GitHub link collecting the latest papers is available at https://github.com/GaryYufei/AlignLLMHumanSurvey.
SPIRAL: Self-supervised Perturbation-Invariant Representation Learning for Speech Pre-Training
Jan 29, 2022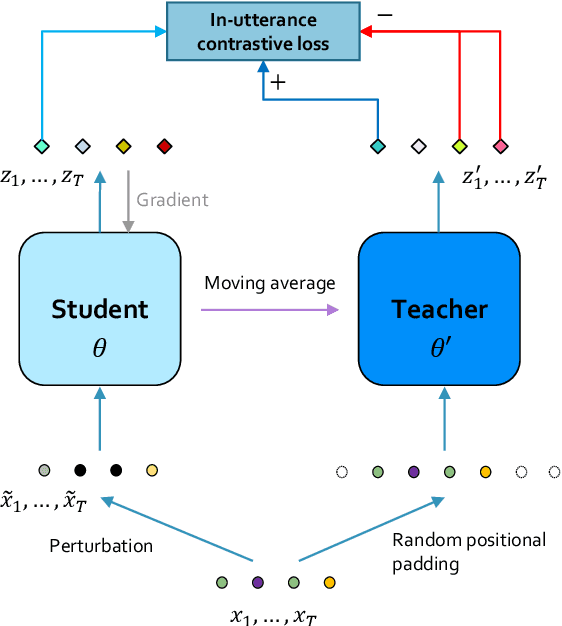
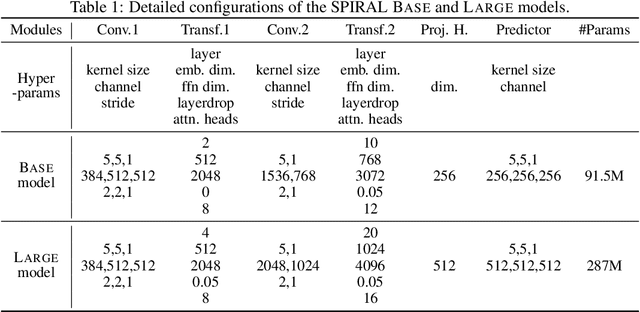


We introduce a new approach for speech pre-training named SPIRAL which works by learning denoising representation of perturbed data in a teacher-student framework. Specifically, given a speech utterance, we first feed the utterance to a teacher network to obtain corresponding representation. Then the same utterance is perturbed and fed to a student network. The student network is trained to output representation resembling that of the teacher. At the same time, the teacher network is updated as moving average of student's weights over training steps. In order to prevent representation collapse, we apply an in-utterance contrastive loss as pre-training objective and impose position randomization on the input to the teacher. SPIRAL achieves competitive or better results compared to state-of-the-art speech pre-training method wav2vec 2.0, with significant reduction of training cost (80% for Base model, 65% for Large model). Furthermore, we address the problem of noise-robustness that is critical to real-world speech applications. We propose multi-condition pre-training by perturbing the student's input with various types of additive noise. We demonstrate that multi-condition pre-trained SPIRAL models are more robust to noisy speech (9.0% - 13.3% relative word error rate reduction on real noisy test data), compared to applying multi-condition training solely in the fine-tuning stage. The code will be released after publication.
CCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis
Nov 16, 2021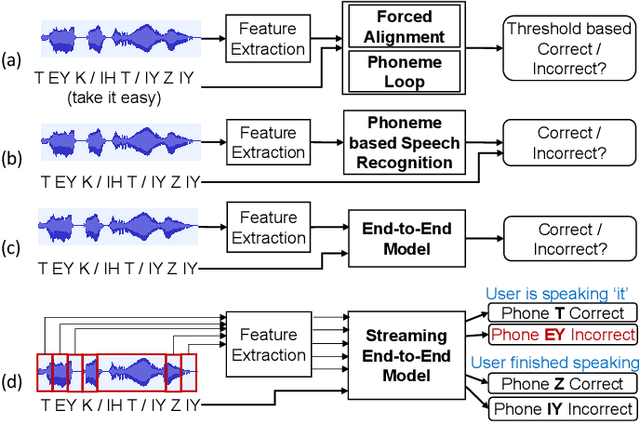
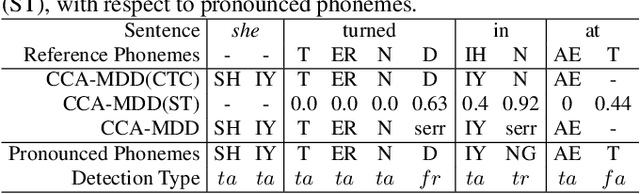
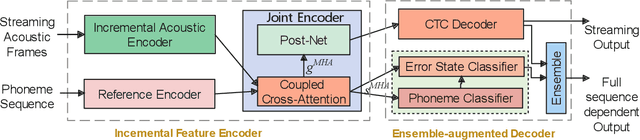

End-to-end models are becoming popular approaches for mispronunciation detection and diagnosis (MDD). A streaming MDD framework which is demanded by many practical applications still remains a challenge. This paper proposes a streaming end-to-end MDD framework called CCA-MDD. CCA-MDD supports online processing and is able to run strictly in real-time. The encoder of CCA-MDD consists of a conv-Transformer network based streaming acoustic encoder and an improved cross-attention named coupled cross-attention (CCA). The coupled cross-attention integrates encoded acoustic features with pre-encoded linguistic features. An ensemble of decoders trained from multi-task learning is applied for final MDD decision. Experiments on publicly available corpora demonstrate that CCA-MDD achieves comparable performance to published offline end-to-end MDD models.
Conv-Transformer Transducer: Low Latency, Low Frame Rate, Streamable End-to-End Speech Recognition
Aug 13, 2020
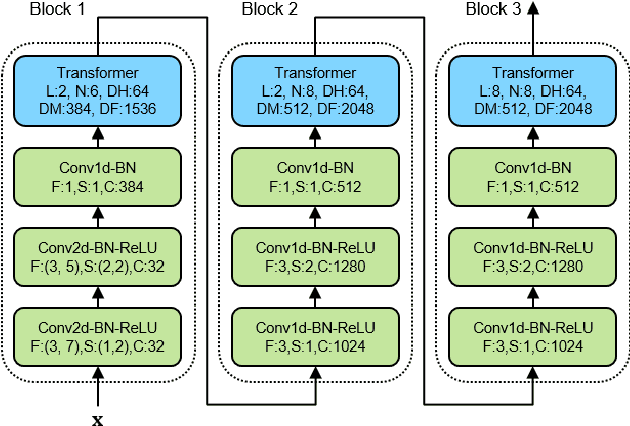
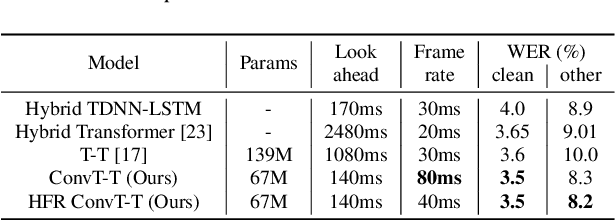
Transformer has achieved competitive performance against state-of-the-art end-to-end models in automatic speech recognition (ASR), and requires significantly less training time than RNN-based models. The original Transformer, with encoder-decoder architecture, is only suitable for offline ASR. It relies on an attention mechanism to learn alignments, and encodes input audio bidirectionally. The high computation cost of Transformer decoding also limits its use in production streaming systems. To make Transformer suitable for streaming ASR, we explore Transducer framework as a streamable way to learn alignments. For audio encoding, we apply unidirectional Transformer with interleaved convolution layers. The interleaved convolution layers are used for modeling future context which is important to performance. To reduce computation cost, we gradually downsample acoustic input, also with the interleaved convolution layers. Moreover, we limit the length of history context in self-attention to maintain constant computation cost for each decoding step. We show that this architecture, named Conv-Transformer Transducer, achieves competitive performance on LibriSpeech dataset (3.6\% WER on test-clean) without external language models. The performance is comparable to previously published streamable Transformer Transducer and strong hybrid streaming ASR systems, and is achieved with smaller look-ahead window (140~ms), fewer parameters and lower frame rate.
NEZHA: Neural Contextualized Representation for Chinese Language Understanding
Sep 05, 2019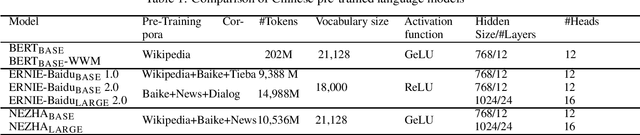

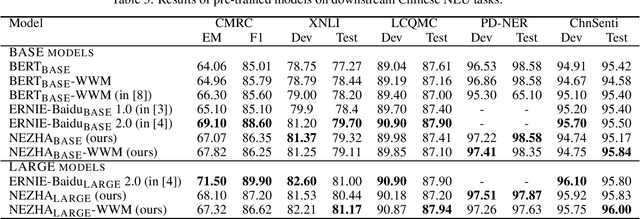
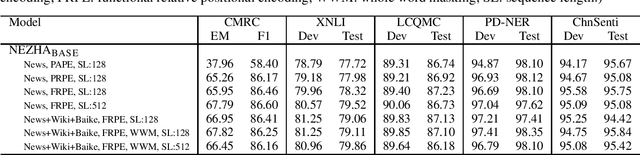
The pre-trained language models have achieved great successes in various natural language understanding (NLU) tasks due to its capacity to capture the deep contextualized information in text by pre-training on large-scale corpora. In this technical report, we present our practice of pre-training language models named NEZHA (NEural contextualiZed representation for CHinese lAnguage understanding) on Chinese corpora and finetuning for the Chinese NLU tasks. The current version of NEZHA is based on BERT with a collection of proven improvements, which include Functional Relative Positional Encoding as an effective positional encoding scheme, Whole Word Masking strategy, Mixed Precision Training and the LAMB Optimizer in training the models. The experimental results show that NEZHA achieves the state-of-the-art performances when finetuned on several representative Chinese tasks, including named entity recognition (People's Daily NER), sentence matching (LCQMC), Chinese sentiment classification (ChnSenti) and natural language inference (XNLI).