 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Ting Yeung
Improving End-to-End Speech Processing by Efficient Text Data Utilization with Latent Synthesis
Oct 24, 2023
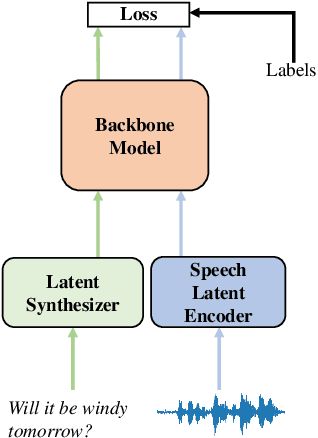
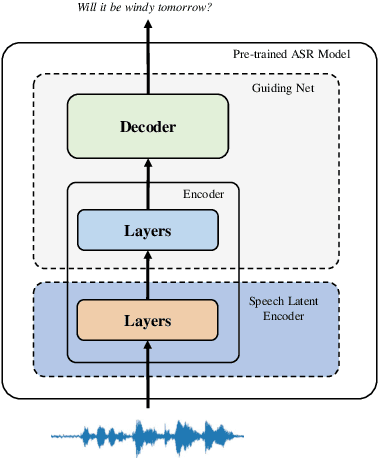

Training a high performance end-to-end speech (E2E) processing model requires an enormous amount of labeled speech data, especially in the era of data-centric artificial intelligence. However, labeled speech data are usually scarcer and more expensive for collection, compared to textual data. We propose Latent Synthesis (LaSyn), an efficient textual data utilization framework for E2E speech processing models. We train a latent synthesizer to convert textual data into an intermediate latent representation of a pre-trained speech model. These pseudo acoustic representations of textual data augment acoustic data for model training. We evaluate LaSyn on low-resource automatic speech recognition (ASR) and spoken language understanding (SLU) tasks. For ASR, LaSyn improves an E2E baseline trained on LibriSpeech train-clean-100, with relative word error rate reductions over 22.3% on different test sets. For SLU, LaSyn improves our E2E baseline by absolute 4.1% for intent classification accuracy and 3.8% for slot filling SLU-F1 on SLURP, and absolute 4.49% and 2.25% for exact match (EM) and EM-Tree accuracies on STOP respectively. With fewer parameters, the results of LaSyn are competitive to published state-of-the-art works. The results demonstrate the quality of the augmented training data.
CorrectSpeech: A Fully Automated System for Speech Correction and Accent Reduction
Apr 12, 2022
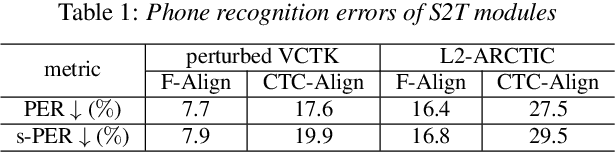

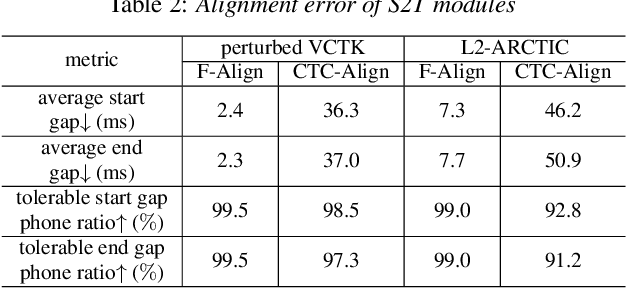
This study extends our previous work on text-based speech editing to developing a fully automated system for speech correction and accent reduction. Consider the application scenario that a recorded speech audio contains certain errors, e.g., inappropriate words, mispronunciations, that need to be corrected. The proposed system, named CorrectSpeech, performs the correction in three steps: recognizing the recorded speech and converting it into time-stamped symbol sequence, aligning recognized symbol sequence with target text to determine locations and types of required edit operations, and generating the corrected speech. Experiments show that the quality and naturalness of corrected speech depend on the performance of speech recognition and alignment modules, as well as the granularity level of editing operations. The proposed system is evaluated on two corpora: a manually perturbed version of VCTK and L2-ARCTIC. The results demonstrate that our system is able to correct mispronunciation and reduce accent in speech recordings. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/CorrectSpeech/ .
SPIRAL: Self-supervised Perturbation-Invariant Representation Learning for Speech Pre-Training
Jan 29, 2022
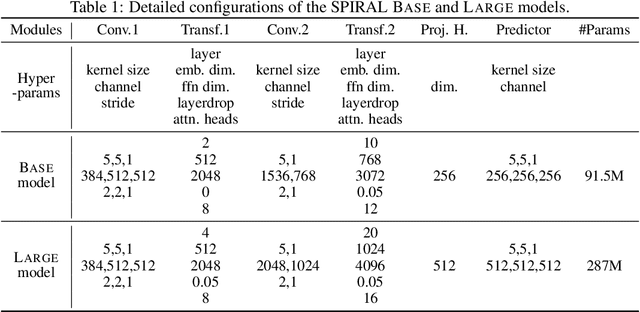


We introduce a new approach for speech pre-training named SPIRAL which works by learning denoising representation of perturbed data in a teacher-student framework. Specifically, given a speech utterance, we first feed the utterance to a teacher network to obtain corresponding representation. Then the same utterance is perturbed and fed to a student network. The student network is trained to output representation resembling that of the teacher. At the same time, the teacher network is updated as moving average of student's weights over training steps. In order to prevent representation collapse, we apply an in-utterance contrastive loss as pre-training objective and impose position randomization on the input to the teacher. SPIRAL achieves competitive or better results compared to state-of-the-art speech pre-training method wav2vec 2.0, with significant reduction of training cost (80% for Base model, 65% for Large model). Furthermore, we address the problem of noise-robustness that is critical to real-world speech applications. We propose multi-condition pre-training by perturbing the student's input with various types of additive noise. We demonstrate that multi-condition pre-trained SPIRAL models are more robust to noisy speech (9.0% - 13.3% relative word error rate reduction on real noisy test data), compared to applying multi-condition training solely in the fine-tuning stage. The code will be released after publication.
Reducing language context confusion for end-to-end code-switching automatic speech recognition
Jan 28, 2022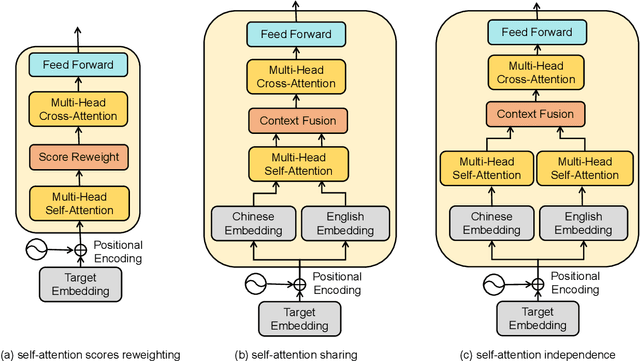
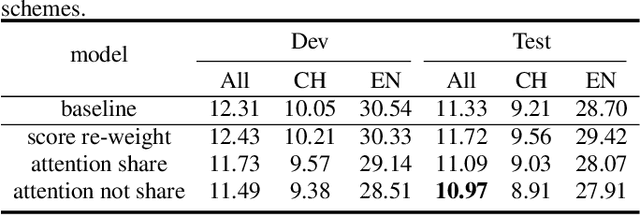
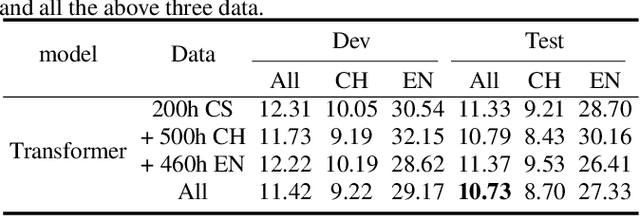
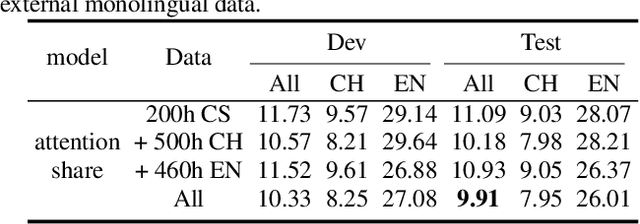
Code-switching is about dealing with alternative languages in the communication process. Training end-to-end (E2E) automatic speech recognition (ASR) systems for code-switching is known to be a challenging problem because of the lack of data compounded by the increased language context confusion due to the presence of more than one language. In this paper, we propose a language-related attention mechanism to reduce multilingual context confusion for the E2E code-switching ASR model based on the Equivalence Constraint Theory (EC). The linguistic theory requires that any monolingual fragment that occurs in the code-switching sentence must occur in one of the monolingual sentences. It establishes a bridge between monolingual data and code-switching data. By calculating the respective attention of multiple languages, our method can efficiently transfer language knowledge from rich monolingual data. We evaluate our method on ASRU 2019 Mandarin-English code-switching challenge dataset. Compared with the baseline model, the proposed method achieves 11.37% relative mix error rate reduction.
CCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis
Nov 16, 2021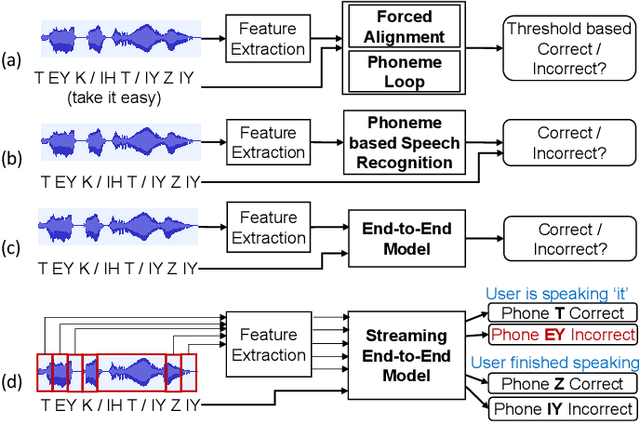
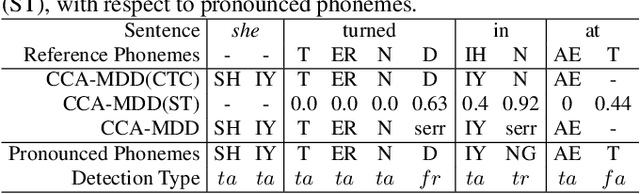
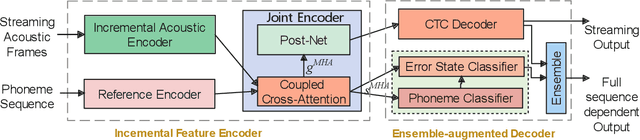

End-to-end models are becoming popular approaches for mispronunciation detection and diagnosis (MDD). A streaming MDD framework which is demanded by many practical applications still remains a challenge. This paper proposes a streaming end-to-end MDD framework called CCA-MDD. CCA-MDD supports online processing and is able to run strictly in real-time. The encoder of CCA-MDD consists of a conv-Transformer network based streaming acoustic encoder and an improved cross-attention named coupled cross-attention (CCA). The coupled cross-attention integrates encoded acoustic features with pre-encoded linguistic features. An ensemble of decoders trained from multi-task learning is applied for final MDD decision. Experiments on publicly available corpora demonstrate that CCA-MDD achieves comparable performance to published offline end-to-end MDD models.
EditSpeech: A Text Based Speech Editing System Using Partial Inference and Bidirectional Fusion
Jul 04, 2021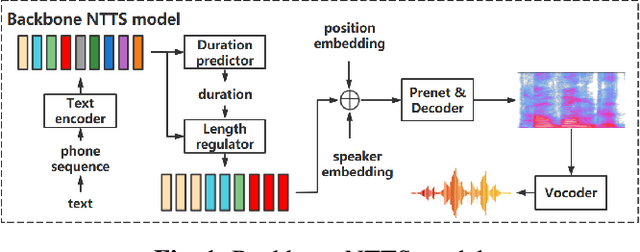
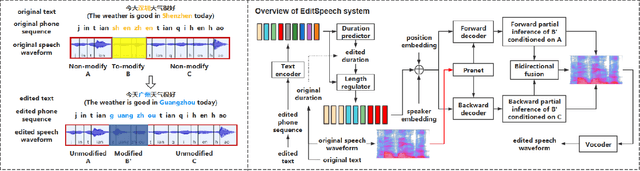

This paper presents the design, implementation and evaluation of a speech editing system, named EditSpeech, which allows a user to perform deletion, insertion and replacement of words in a given speech utterance, without causing audible degradation in speech quality and naturalness. The EditSpeech system is developed upon a neural text-to-speech (NTTS) synthesis framework. Partial inference and bidirectional fusion are proposed to effectively incorporate the contextual information related to the edited region and achieve smooth transition at both left and right boundaries. Distortion introduced to the unmodified parts of the utterance is alleviated. The EditSpeech system is developed and evaluated on English and Chinese in multi-speaker scenarios. Objective and subjective evaluation demonstrate that EditSpeech outperforms a few baseline systems in terms of low spectral distortion and preferred speech quality. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/EditSpeech/ .
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
Jun 18, 2021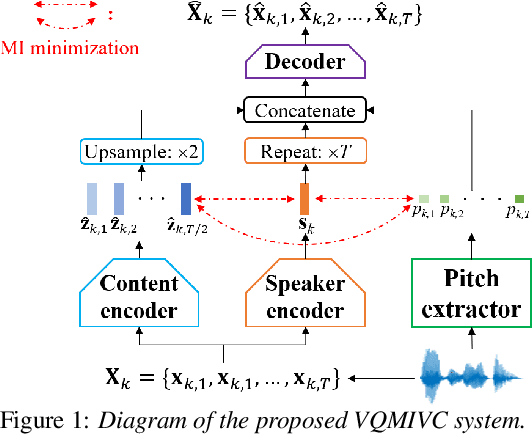


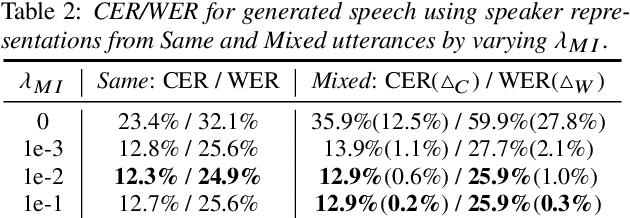
One-shot voice conversion (VC), which performs conversion across arbitrary speakers with only a single target-speaker utterance for reference, can be effectively achieved by speech representation disentanglement. Existing work generally ignores the correlation between different speech representations during training, which causes leakage of content information into the speaker representation and thus degrades VC performance. To alleviate this issue, we employ vector quantization (VQ) for content encoding and introduce mutual information (MI) as the correlation metric during training, to achieve proper disentanglement of content, speaker and pitch representations, by reducing their inter-dependencies in an unsupervised manner. Experimental results reflect the superiority of the proposed method in learning effective disentangled speech representations for retaining source linguistic content and intonation variations, while capturing target speaker characteristics. In doing so, the proposed approach achieves higher speech naturalness and speaker similarity than current state-of-the-art one-shot VC systems. Our code, pre-trained models and demo are available at https://github.com/Wendison/VQMIVC.
Unsupervised Domain Adaptation for Dysarthric Speech Detection via Domain Adversarial Training and Mutual Information Minimization
Jun 18, 2021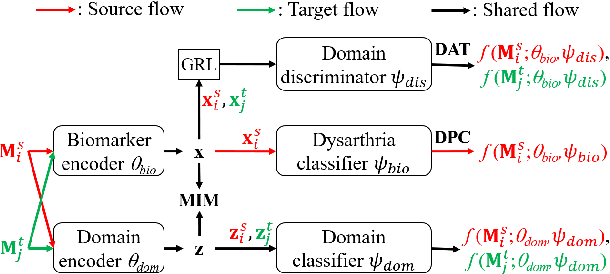



Dysarthric speech detection (DSD) systems aim to detect characteristics of the neuromotor disorder from speech. Such systems are particularly susceptible to domain mismatch where the training and testing data come from the source and target domains respectively, but the two domains may differ in terms of speech stimuli, disease etiology, etc. It is hard to acquire labelled data in the target domain, due to high costs of annotating sizeable datasets. This paper makes a first attempt to formulate cross-domain DSD as an unsupervised domain adaptation (UDA) problem. We use labelled source-domain data and unlabelled target-domain data, and propose a multi-task learning strategy, including dysarthria presence classification (DPC), domain adversarial training (DAT) and mutual information minimization (MIM), which aim to learn dysarthria-discriminative and domain-invariant biomarker embeddings. Specifically, DPC helps biomarker embeddings capture critical indicators of dysarthria; DAT forces biomarker embeddings to be indistinguishable in source and target domains; and MIM further reduces the correlation between biomarker embeddings and domain-related cues. By treating the UASPEECH and TORGO corpora respectively as the source and target domains, experiments show that the incorporation of UDA attains absolute increases of 22.2% and 20.0% respectively in utterance-level weighted average recall and speaker-level accuracy.
The HUAWEI Speaker Diarisation System for the VoxCeleb Speaker Diarisation Challenge
Oct 23, 2020
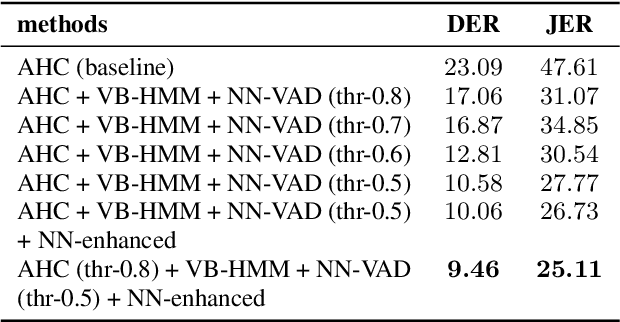


This paper describes system setup of our submission to speaker diarisation track (Track 4) of VoxCeleb Speaker Recognition Challenge 2020. Our diarisation system consists of a well-trained neural network based speech enhancement model as pre-processing front-end of input speech signals. We replace conventional energy-based voice activity detection (VAD) with a neural network based VAD. The neural network based VAD provides more accurate annotation of speech segments containing only background music, noise, and other interference, which is crucial to diarisation performance. We apply agglomerative hierarchical clustering (AHC) of x-vectors and variational Bayesian hidden Markov model (VB-HMM) based iterative clustering for speaker clustering. Experimental results demonstrate that our proposed system achieves substantial improvements over the baseline system, yielding diarisation error rate (DER) of 10.45%, and Jacard error rate (JER) of 22.46% on the evaluation set.
Conv-Transformer Transducer: Low Latency, Low Frame Rate, Streamable End-to-End Speech Recognition
Aug 13, 2020
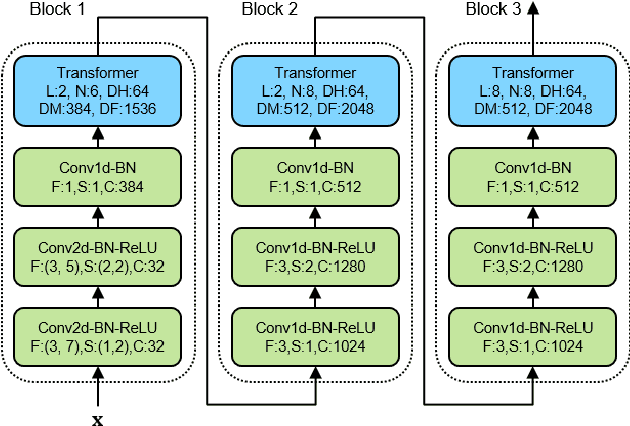
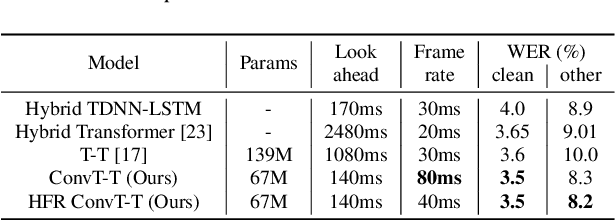
Transformer has achieved competitive performance against state-of-the-art end-to-end models in automatic speech recognition (ASR), and requires significantly less training time than RNN-based models. The original Transformer, with encoder-decoder architecture, is only suitable for offline ASR. It relies on an attention mechanism to learn alignments, and encodes input audio bidirectionally. The high computation cost of Transformer decoding also limits its use in production streaming systems. To make Transformer suitable for streaming ASR, we explore Transducer framework as a streamable way to learn alignments. For audio encoding, we apply unidirectional Transformer with interleaved convolution layers. The interleaved convolution layers are used for modeling future context which is important to performance. To reduce computation cost, we gradually downsample acoustic input, also with the interleaved convolution layers. Moreover, we limit the length of history context in self-attention to maintain constant computation cost for each decoding step. We show that this architecture, named Conv-Transformer Transducer, achieves competitive performance on LibriSpeech dataset (3.6\% WER on test-clean) without external language models. The performance is comparable to previously published streamable Transformer Transducer and strong hybrid streaming ASR systems, and is achieved with smaller look-ahead window (140~ms), fewer parameters and lower frame rate.