 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaqi Xu
Unveiling the Generalization Power of Fine-Tuned Large Language Models
Mar 14, 2024
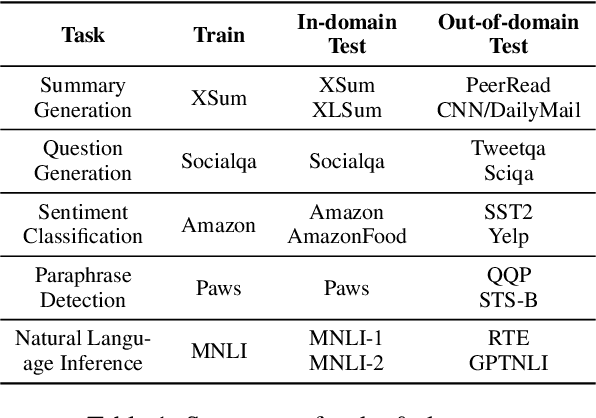
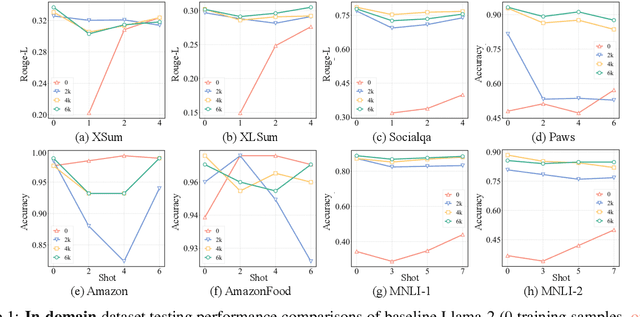
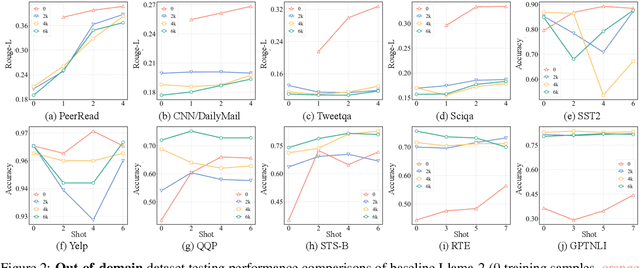
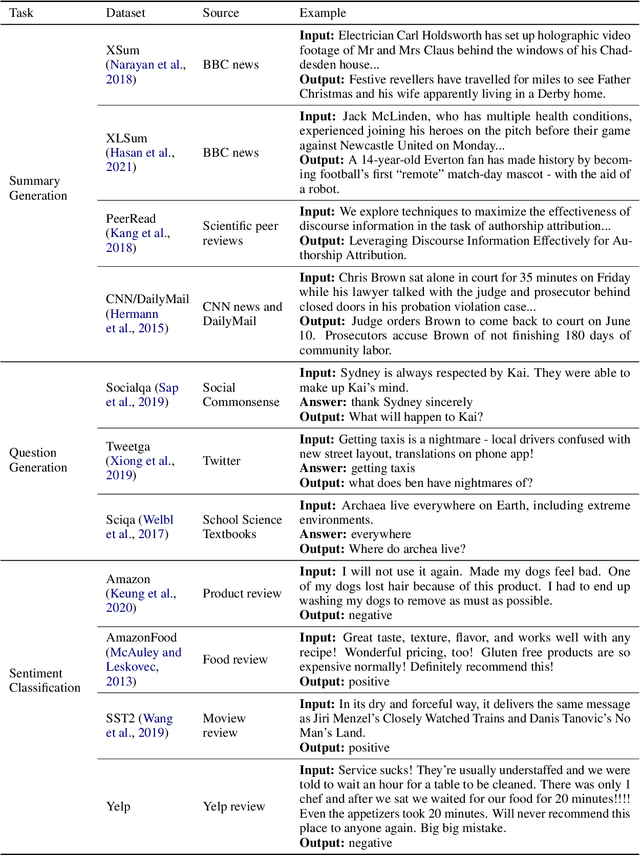
While Large Language Models (LLMs) have demonstrated exceptional multitasking abilities, fine-tuning these models on downstream, domain-specific datasets is often necessary to yield superior performance on test sets compared to their counterparts without fine-tuning. However, the comprehensive effects of fine-tuning on the LLMs' generalization ability are not fully understood. This paper delves into the differences between original, unmodified LLMs and their fine-tuned variants. Our primary investigation centers on whether fine-tuning affects the generalization ability intrinsic to LLMs. To elaborate on this, we conduct extensive experiments across five distinct language tasks on various datasets. Our main findings reveal that models fine-tuned on generation and classification tasks exhibit dissimilar behaviors in generalizing to different domains and tasks. Intriguingly, we observe that integrating the in-context learning strategy during fine-tuning on generation tasks can enhance the model's generalization ability. Through this systematic investigation, we aim to contribute valuable insights into the evolving landscape of fine-tuning practices for LLMs.
Slot-VLM: SlowFast Slots for Video-Language Modeling
Feb 20, 2024Video-Language Models (VLMs), powered by the advancements in Large Language Models (LLMs), are charting new frontiers in video understanding. A pivotal challenge is the development of an efficient method to encapsulate video content into a set of representative tokens to align with LLMs. In this work, we introduce Slot-VLM, a novel framework designed to generate semantically decomposed video tokens, in terms of object-wise and event-wise visual representations, to facilitate LLM inference. Particularly, we design a SlowFast Slots module, i.e., SF-Slots, that adaptively aggregates the dense video tokens from the CLIP vision encoder to a set of representative slots. In order to take into account both the spatial object details and the varied temporal dynamics, SF-Slots is built with a dual-branch structure. The Slow-Slots branch focuses on extracting object-centric slots from features at high spatial resolution but low (slow) frame sample rate, emphasizing detailed object information. Conversely, Fast-Slots branch is engineered to learn event-centric slots from high temporal sample rate but low spatial resolution features. These complementary slots are combined to form the vision context, serving as the input to the LLM for efficient question answering. Our experimental results demonstrate the effectiveness of our Slot-VLM, which achieves the state-of-the-art performance on video question-answering.
Near-Field Communications: A Comprehensive Survey
Jan 11, 2024Multiple-antenna technologies are evolving towards large-scale aperture sizes, extremely high frequencies, and innovative antenna types. This evolution is giving rise to the emergence of near-field communications (NFC) in future wireless systems. Considerable attention has been directed towards this cutting-edge technology due to its potential to enhance the capacity of wireless networks by introducing increased spatial degrees of freedom (DoFs) in the range domain. Within this context, a comprehensive review of the state of the art on NFC is presented, with a specific focus on its 1) fundamental operating principles, 2) channel modeling, 3) performance analysis, 4) signal processing, and 5) integration with other emerging technologies. Specifically, 1) the basic principles of NFC are characterized from both physics and communications perspectives, unveiling its unique properties in contrast to far-field communications. 2) Based on these principles, deterministic and stochastic near-field channel models are investigated for spatially-discrete (SPD) and continuous-aperture (CAP) antenna arrays. 3) Rooted in these models, existing contributions on near-field performance analysis are reviewed in terms of DoFs/effective DoFs (EDoFs), power scaling law, and transmission rate. 4) Existing signal processing techniques for NFC are systematically surveyed, encompassing channel estimation, beamforming design, and low-complexity beam training. 5) Major issues and research opportunities associated with the integration of NFC and other emerging technologies are identified to facilitate NFC applications in next-generation networks. Promising directions are highlighted throughout the paper to inspire future research endeavors in the realm of NFC.
A Survey of Reasoning with Foundation Models
Dec 26, 2023Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation. It serves as a fundamental methodology in the field of Artificial General Intelligence (AGI). With the ongoing development of foundation models, there is a growing interest in exploring their abilities in reasoning tasks. In this paper, we introduce seminal foundation models proposed or adaptable for reasoning, highlighting the latest advancements in various reasoning tasks, methods, and benchmarks. We then delve into the potential future directions behind the emergence of reasoning abilities within foundation models. We also discuss the relevance of multimodal learning, autonomous agents, and super alignment in the context of reasoning. By discussing these future research directions, we hope to inspire researchers in their exploration of this field, stimulate further advancements in reasoning with foundation models, and contribute to the development of AGI.
RIS-Aided Near-field Communications for 6G: Opportunities and Challenges
Dec 20, 2023Reconfigurable intelligent surface (RIS)-aided near-field communications is investigated. First, the necessity of investigating RIS-aided near-field communications and the advantages brought about by the unique spherical-wave-based near-field propagation are discussed. Then, the family of patch-array-based RISs and metasurface-based RISs are introduced along with their respective near-field channel models. A pair of fundamental performance limits of RIS-aided near-field communications, namely their power scaling law and effective degrees-of-freedom, are analyzed for both patch-array-based and metasurface-based RISs, which reveals the potential performance gains that can be achieved. Furthermore, the associated near-field beam training and beamforming design issues are studied, where a two-stage hierarchical beam training approach and a low-complexity element-wise beamforming design are proposed for RIS-aided near-field communications. Finally, a suite of open research problems is highlighted for motivating future research.
Retrieval-based Video Language Model for Efficient Long Video Question Answering
Dec 08, 2023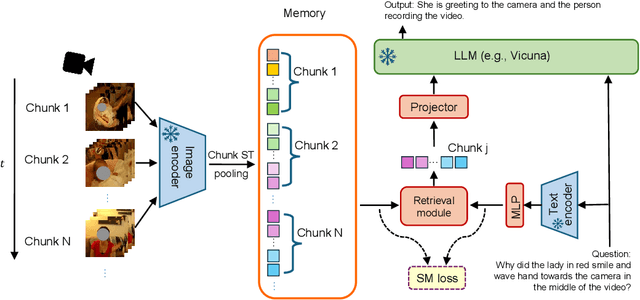
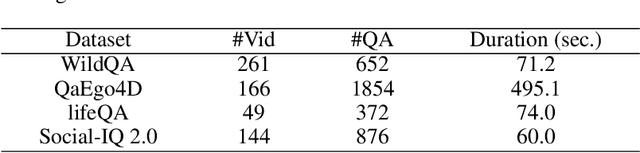


The remarkable natural language understanding, reasoning, and generation capabilities of large language models (LLMs) have made them attractive for application to video question answering (Video QA) tasks, utilizing video tokens as contextual input. However, employing LLMs for long video understanding presents significant challenges and remains under-explored. The extensive number of video tokens leads to considerable computational costs for LLMs while using aggregated tokens results in loss of vision details. Moreover, the presence of abundant question-irrelevant tokens introduces noise to the video QA process. To address these issues, we introduce a simple yet effective retrieval-based video language model (R-VLM) for efficient and interpretable long video QA. Specifically, given a question (query) and a long video, our model identifies and selects the most relevant $K$ video chunks and uses their associated visual tokens to serve as context for the LLM inference. This effectively reduces the number of video tokens, eliminates noise interference, and enhances system performance. Our experimental results validate the effectiveness of our framework for comprehending long videos. Furthermore, based on the retrieved chunks, our model is interpretable that provides the justifications on where we get the answers.
EasyPhoto: Your Smart AI Photo Generator
Oct 07, 2023



Stable Diffusion web UI (SD-WebUI) is a comprehensive project that provides a browser interface based on Gradio library for Stable Diffusion models. In this paper, We propose a novel WebUI plugin called EasyPhoto, which enables the generation of AI portraits. By training a digital doppelganger of a specific user ID using 5 to 20 relevant images, the finetuned model (according to the trained LoRA model) allows for the generation of AI photos using arbitrary templates. Our current implementation supports the modification of multiple persons and different photo styles. Furthermore, we allow users to generate fantastic template image with the strong SDXL model, enhancing EasyPhoto's capabilities to deliver more diverse and satisfactory results. The source code for EasyPhoto is available at: https://github.com/aigc-apps/sd-webui-EasyPhoto. We also support a webui-free version by using diffusers: https://github.com/aigc-apps/EasyPhoto. We are continuously enhancing our efforts to expand the EasyPhoto pipeline, making it suitable for any identification (not limited to just the face), and we enthusiastically welcome any intriguing ideas or suggestions.
MRecGen: Multimodal Appropriate Reaction Generator
Jul 05, 2023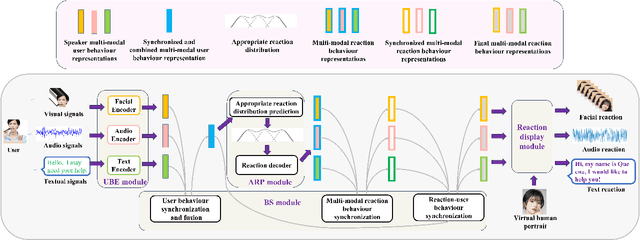
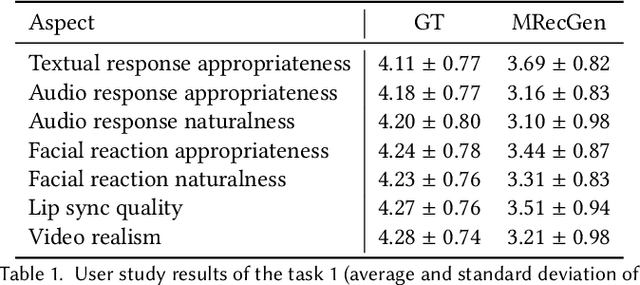
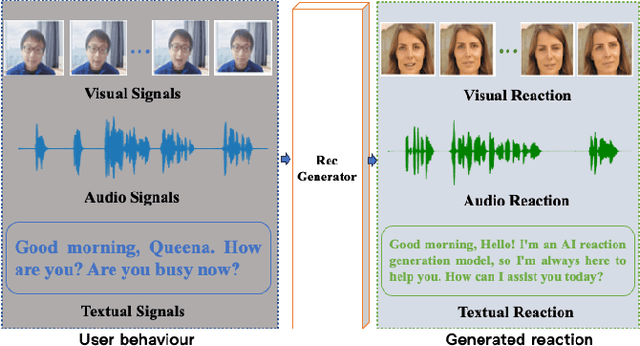
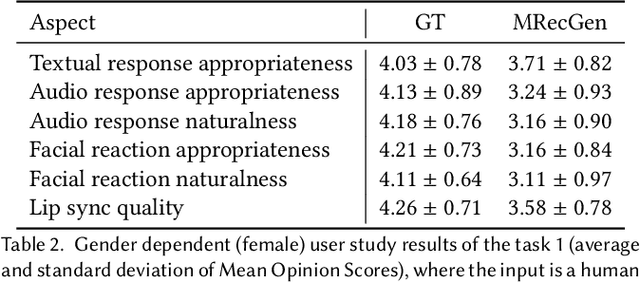
Verbal and non-verbal human reaction generation is a challenging task, as different reactions could be appropriate for responding to the same behaviour. This paper proposes the first multiple and multimodal (verbal and nonverbal) appropriate human reaction generation framework that can generate appropriate and realistic human-style reactions (displayed in the form of synchronised text, audio and video streams) in response to an input user behaviour. This novel technique can be applied to various human-computer interaction scenarios by generating appropriate virtual agent/robot behaviours. Our demo is available at \url{https://github.com/SSYSteve/MRecGen}.
Shape Guided Gradient Voting for Domain Generalization
Jun 19, 2023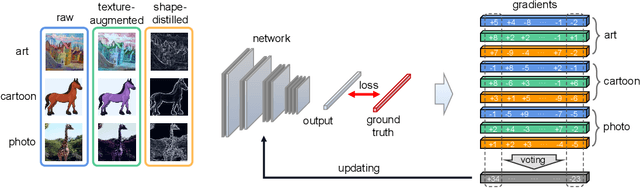
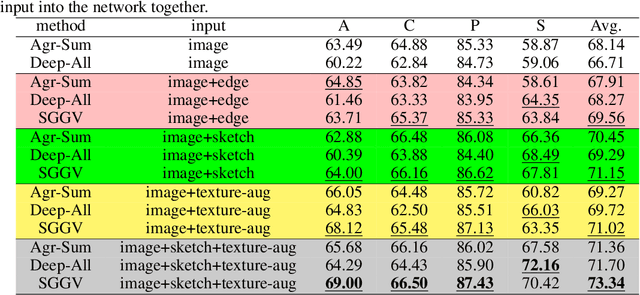
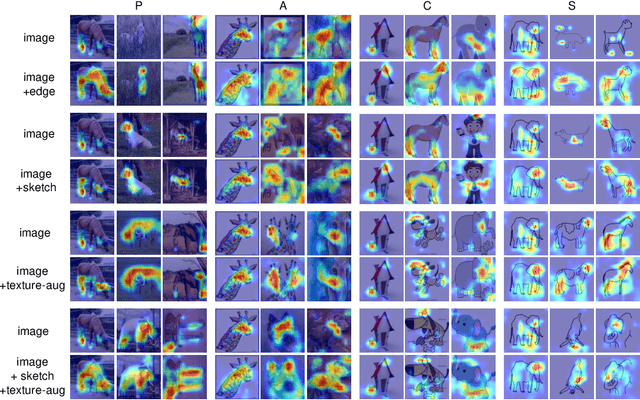

Domain generalization aims to address the domain shift between training and testing data. To learn the domain invariant representations, the model is usually trained on multiple domains. It has been found that the gradients of network weight relative to a specific task loss can characterize the task itself. In this work, with the assumption that the gradients of a specific domain samples under the classification task could also reflect the property of the domain, we propose a Shape Guided Gradient Voting (SGGV) method for domain generalization. Firstly, we introduce shape prior via extra inputs of the network to guide gradient descending towards a shape-biased direction for better generalization. Secondly, we propose a new gradient voting strategy to remove the outliers for robust optimization in the presence of shape guidance. To provide shape guidance, we add edge/sketch extracted from the training data as an explicit way, and also use texture augmented images as an implicit way. We conduct experiments on several popular domain generalization datasets in image classification task, and show that our shape guided gradient updating strategy brings significant improvement of the generalization.
Near-Field Communications: A Tutorial Review
May 28, 2023



Extremely large-scale antenna arrays, tremendously high frequencies, and new types of antennas are three clear trends in multi-antenna technology for supporting the sixth-generation (6G) networks. To properly account for the new characteristics introduced by these three trends in communication system design, the near-field spherical-wave propagation model needs to be used, which differs from the classical far-field planar-wave one. As such, near-field communication (NFC) will become essential in 6G networks. In this tutorial, we cover three key aspects of NFC. 1) Channel Modelling: We commence by reviewing near-field spherical-wave-based channel models for spatially-discrete (SPD) antennas. Then, uniform spherical wave (USW) and non-uniform spherical wave (NUSW) models are discussed. Subsequently, we introduce a general near-field channel model for SPD antennas and a Green's function-based channel model for continuous-aperture (CAP) antennas. 2) Beamfocusing and Antenna Architectures: We highlight the properties of near-field beamfocusing and discuss NFC antenna architectures for both SPD and CAP antennas. Moreover, the basic principles of near-field beam training are introduced. 3) Performance Analysis: Finally, we provide a comprehensive performance analysis framework for NFC. For near-field line-of-sight channels, the received signal-to-noise ratio and power-scaling law are derived. For statistical near-field multipath channels, a general analytical framework is proposed, based on which analytical expression for the outage probability, ergodic channel capacity, and ergodic mutual information are derived. Finally, for each aspect, the topics for future research are discussed.