 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiankai Sun
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
Mar 14, 2024
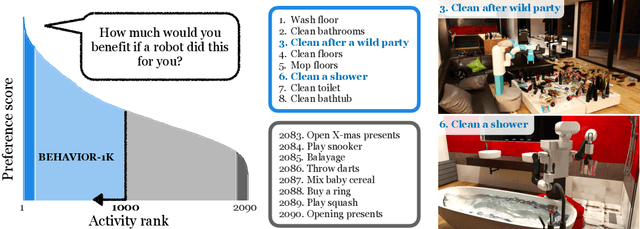
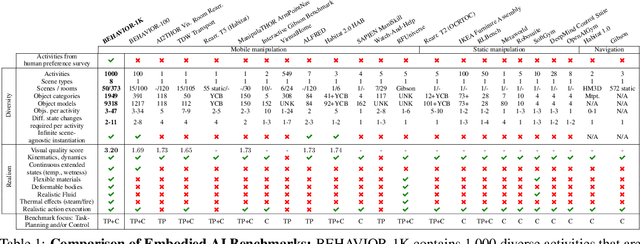


We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
Leveraging Print Debugging to Improve Code Generation in Large Language Models
Jan 10, 2024Large language models (LLMs) have made significant progress in code generation tasks, but their performance in tackling programming problems with complex data structures and algorithms remains suboptimal. To address this issue, we propose an in-context learning approach that guides LLMs to debug by using a "print debugging" method, which involves inserting print statements to trace and analysing logs for fixing the bug. We collect a Leetcode problem dataset and evaluate our method using the Leetcode online judging system. Experiments with GPT-4 demonstrate the effectiveness of our approach, outperforming rubber duck debugging in easy and medium-level Leetcode problems by 1.5% and 17.9%.
A Survey of Reasoning with Foundation Models
Dec 26, 2023Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation. It serves as a fundamental methodology in the field of Artificial General Intelligence (AGI). With the ongoing development of foundation models, there is a growing interest in exploring their abilities in reasoning tasks. In this paper, we introduce seminal foundation models proposed or adaptable for reasoning, highlighting the latest advancements in various reasoning tasks, methods, and benchmarks. We then delve into the potential future directions behind the emergence of reasoning abilities within foundation models. We also discuss the relevance of multimodal learning, autonomous agents, and super alignment in the context of reasoning. By discussing these future research directions, we hope to inspire researchers in their exploration of this field, stimulate further advancements in reasoning with foundation models, and contribute to the development of AGI.
Foundation Models in Robotics: Applications, Challenges, and the Future
Dec 13, 2023
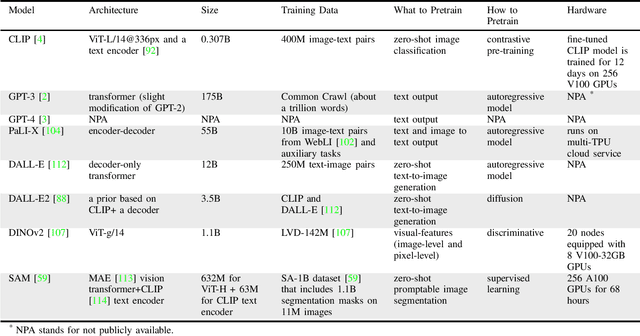
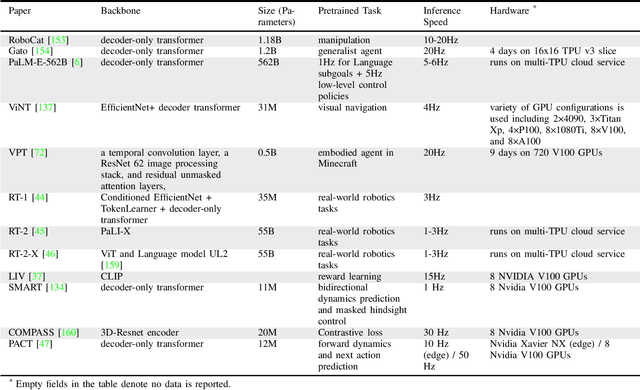
We survey applications of pretrained foundation models in robotics. Traditional deep learning models in robotics are trained on small datasets tailored for specific tasks, which limits their adaptability across diverse applications. In contrast, foundation models pretrained on internet-scale data appear to have superior generalization capabilities, and in some instances display an emergent ability to find zero-shot solutions to problems that are not present in the training data. Foundation models may hold the potential to enhance various components of the robot autonomy stack, from perception to decision-making and control. For example, large language models can generate code or provide common sense reasoning, while vision-language models enable open-vocabulary visual recognition. However, significant open research challenges remain, particularly around the scarcity of robot-relevant training data, safety guarantees and uncertainty quantification, and real-time execution. In this survey, we study recent papers that have used or built foundation models to solve robotics problems. We explore how foundation models contribute to improving robot capabilities in the domains of perception, decision-making, and control. We discuss the challenges hindering the adoption of foundation models in robot autonomy and provide opportunities and potential pathways for future advancements. The GitHub project corresponding to this paper (Preliminary release. We are committed to further enhancing and updating this work to ensure its quality and relevance) can be found here: https://github.com/robotics-survey/Awesome-Robotics-Foundation-Models
Aria-NeRF: Multimodal Egocentric View Synthesis
Nov 11, 2023We seek to accelerate research in developing rich, multimodal scene models trained from egocentric data, based on differentiable volumetric ray-tracing inspired by Neural Radiance Fields (NeRFs). The construction of a NeRF-like model from an egocentric image sequence plays a pivotal role in understanding human behavior and holds diverse applications within the realms of VR/AR. Such egocentric NeRF-like models may be used as realistic simulations, contributing significantly to the advancement of intelligent agents capable of executing tasks in the real-world. The future of egocentric view synthesis may lead to novel environment representations going beyond today's NeRFs by augmenting visual data with multimodal sensors such as IMU for egomotion tracking, audio sensors to capture surface texture and human language context, and eye-gaze trackers to infer human attention patterns in the scene. To support and facilitate the development and evaluation of egocentric multimodal scene modeling, we present a comprehensive multimodal egocentric video dataset. This dataset offers a comprehensive collection of sensory data, featuring RGB images, eye-tracking camera footage, audio recordings from a microphone, atmospheric pressure readings from a barometer, positional coordinates from GPS, connectivity details from Wi-Fi and Bluetooth, and information from dual-frequency IMU datasets (1kHz and 800Hz) paired with a magnetometer. The dataset was collected with the Meta Aria Glasses wearable device platform. The diverse data modalities and the real-world context captured within this dataset serve as a robust foundation for furthering our understanding of human behavior and enabling more immersive and intelligent experiences in the realms of VR, AR, and robotics.
Lyra: Orchestrating Dual Correction in Automated Theorem Proving
Oct 07, 2023
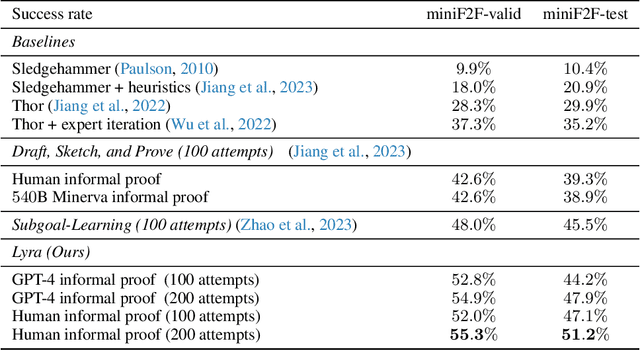
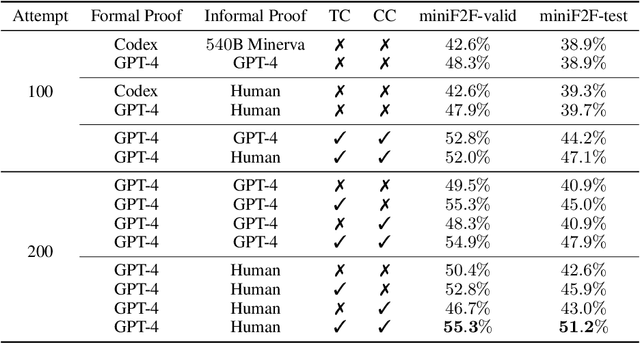
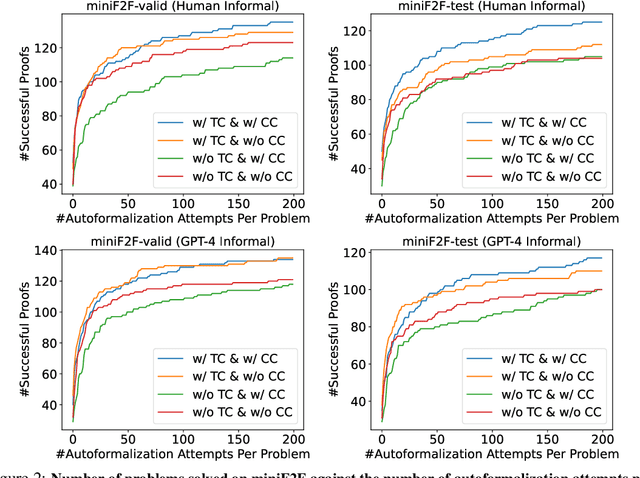
Large Language Models (LLMs) present an intriguing avenue for exploration in the field of formal theorem proving. Nevertheless, their full potential, particularly concerning the mitigation of hallucinations and refinement through prover error messages, remains an area that has yet to be thoroughly investigated. To enhance the effectiveness of LLMs in the field, we introduce the Lyra, a new framework that employs two distinct correction mechanisms: Tool Correction (TC) and Conjecture Correction (CC). To implement Tool Correction in the post-processing of formal proofs, we leverage prior knowledge to utilize predefined prover tools (e.g., Sledgehammer) for guiding the replacement of incorrect tools. Tool Correction significantly contributes to mitigating hallucinations, thereby improving the overall accuracy of the proof. In addition, we introduce Conjecture Correction, an error feedback mechanism designed to interact with prover to refine formal proof conjectures with prover error messages. Compared to the previous refinement framework, the proposed Conjecture Correction refines generation with instruction but does not collect paired (generation, error & refinement) prompts. Our method has achieved state-of-the-art (SOTA) performance on both miniF2F validation (48.0% -> 55.3%) and test (45.5% -> 51.2%). We also present 3 IMO problems solved by Lyra. We believe Tool Correction (post-process for hallucination mitigation) and Conjecture Correction (subgoal adjustment from interaction with environment) could provide a promising avenue for future research in this field.
Connected Autonomous Vehicle Motion Planning with Video Predictions from Smart, Self-Supervised Infrastructure
Sep 14, 2023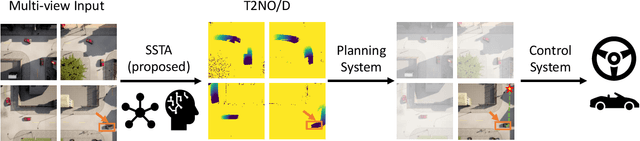
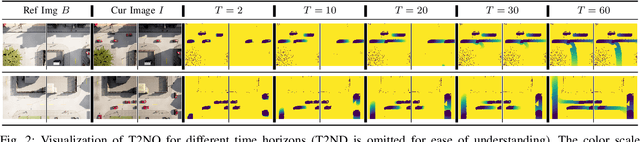
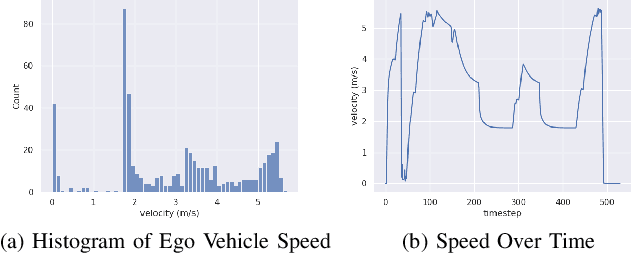

Connected autonomous vehicles (CAVs) promise to enhance safety, efficiency, and sustainability in urban transportation. However, this is contingent upon a CAV correctly predicting the motion of surrounding agents and planning its own motion safely. Doing so is challenging in complex urban environments due to frequent occlusions and interactions among many agents. One solution is to leverage smart infrastructure to augment a CAV's situational awareness; the present work leverages a recently proposed "Self-Supervised Traffic Advisor" (SSTA) framework of smart sensors that teach themselves to generate and broadcast useful video predictions of road users. In this work, SSTA predictions are modified to predict future occupancy instead of raw video, which reduces the data footprint of broadcast predictions. The resulting predictions are used within a planning framework, demonstrating that this design can effectively aid CAV motion planning. A variety of numerical experiments study the key factors that make SSTA outputs useful for practical CAV planning in crowded urban environments.
Graph-Based Model-Agnostic Data Subsampling for Recommendation Systems
May 25, 2023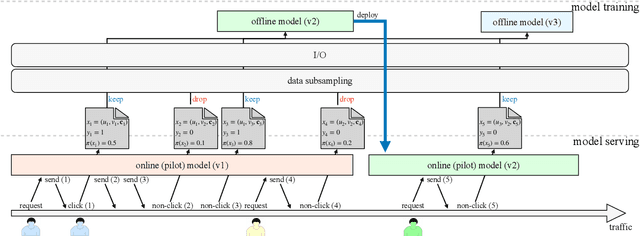
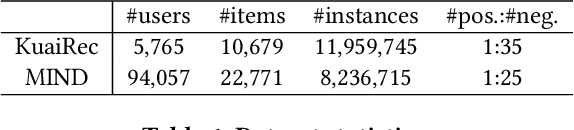
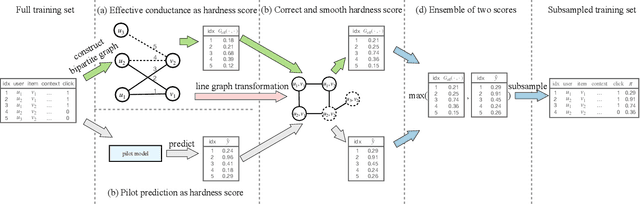

Data subsampling is widely used to speed up the training of large-scale recommendation systems. Most subsampling methods are model-based and often require a pre-trained pilot model to measure data importance via e.g. sample hardness. However, when the pilot model is misspecified, model-based subsampling methods deteriorate. Since model misspecification is persistent in real recommendation systems, we instead propose model-agnostic data subsampling methods by only exploring input data structure represented by graphs. Specifically, we study the topology of the user-item graph to estimate the importance of each user-item interaction (an edge in the user-item graph) via graph conductance, followed by a propagation step on the network to smooth out the estimated importance value. Since our proposed method is model-agnostic, we can marry the merits of both model-agnostic and model-based subsampling methods. Empirically, we show that combing the two consistently improves over any single method on the used datasets. Experimental results on KuaiRec and MIND datasets demonstrate that our proposed methods achieve superior results compared to baseline approaches.
Large AI Models in Health Informatics: Applications, Challenges, and the Future
Mar 21, 2023

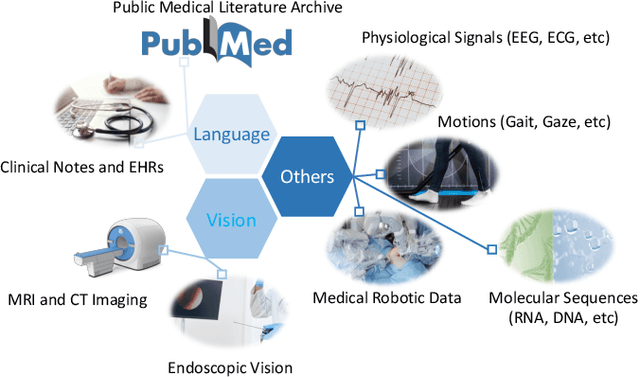

Large AI models, or foundation models, are models recently emerging with massive scales both parameter-wise and data-wise, the magnitudes of which often reach beyond billions. Once pretrained, large AI models demonstrate impressive performance in various downstream tasks. A concrete example is the recent debut of ChatGPT, whose capability has compelled people's imagination about the far-reaching influence that large AI models can have and their potential to transform different domains of our life. In health informatics, the advent of large AI models has brought new paradigms for the design of methodologies. The scale of multimodality data in the biomedical and health domain has been ever-expanding especially since the community embraced the era of deep learning, which provides the ground to develop, validate, and advance large AI models for breakthroughs in health-related areas. This article presents an up-to-date comprehensive review of large AI models, from background to their applications. We identify seven key sectors that large AI models are applicable and might have substantial influence, including 1) molecular biology and drug discovery; 2) medical diagnosis and decision-making; 3) medical imaging and vision; 4) medical informatics; 5) medical education; 6) public health; and 7) medical robotics. We examine their challenges in health informatics, followed by a critical discussion about potential future directions and pitfalls of large AI models in transforming the field of health informatics.