 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoberto Martín-Martín
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024
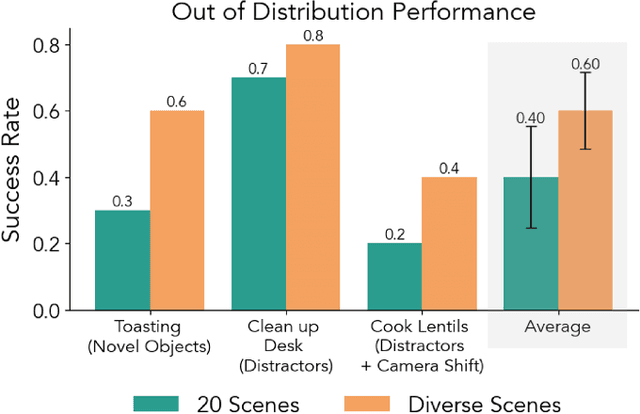


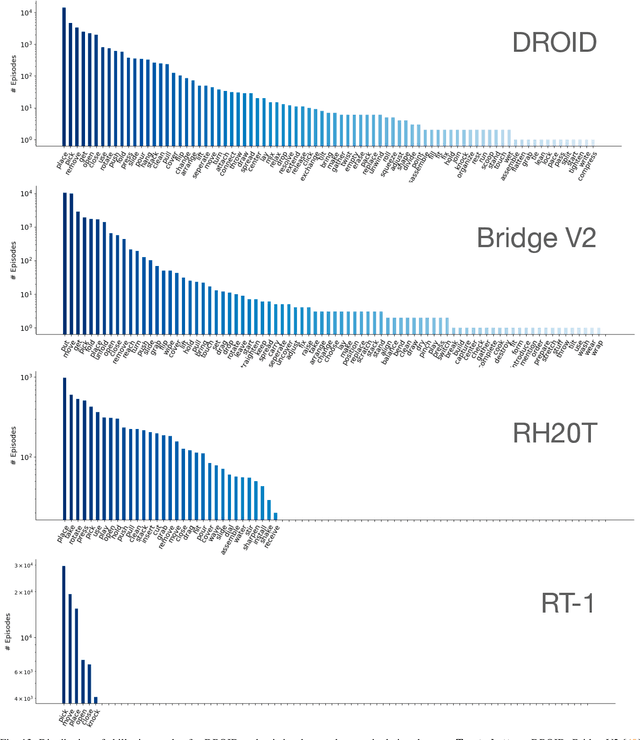
The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
Mar 14, 2024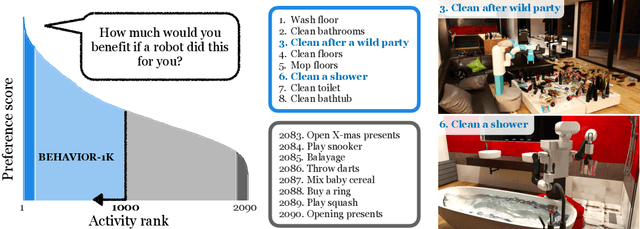
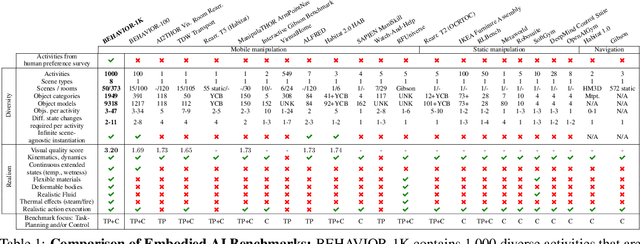


We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
BaRiFlex: A Robotic Gripper with Versatility and Collision Robustness for Robot Learning
Dec 08, 2023We present a new approach to robot hand design specifically suited for successfully implementing robot learning methods to accomplish tasks in daily human environments. We introduce BaRiFlex, an innovative gripper design that alleviates the issues caused by unexpected contact and collisions during robot learning, offering robustness, grasping versatility, task versatility, and simplicity to the learning processes. This achievement is enabled by the incorporation of low-inertia actuators, providing high Back-drivability, and the strategic combination of Rigid and Flexible materials which enhances versatility and the gripper's resilience against unpredicted collisions. Furthermore, the integration of flexible Fin-Ray linkages and rigid linkages allows the gripper to execute compliant grasping and precise pinching. We conducted rigorous performance tests to characterize the novel gripper's compliance, durability, grasping and task versatility, and precision. We also integrated the BaRiFlex with a 7 Degree of Freedom (DoF) Franka Emika's Panda robotic arm to evaluate its capacity to support a trial-and-error (reinforcement learning) training procedure. The results of our experimental study are then compared to those obtained using the original rigid Franka Hand and a reference Fin-Ray soft gripper, demonstrating the superior capabilities and advantages of our developed gripper system.
Model-Based Runtime Monitoring with Interactive Imitation Learning
Oct 26, 2023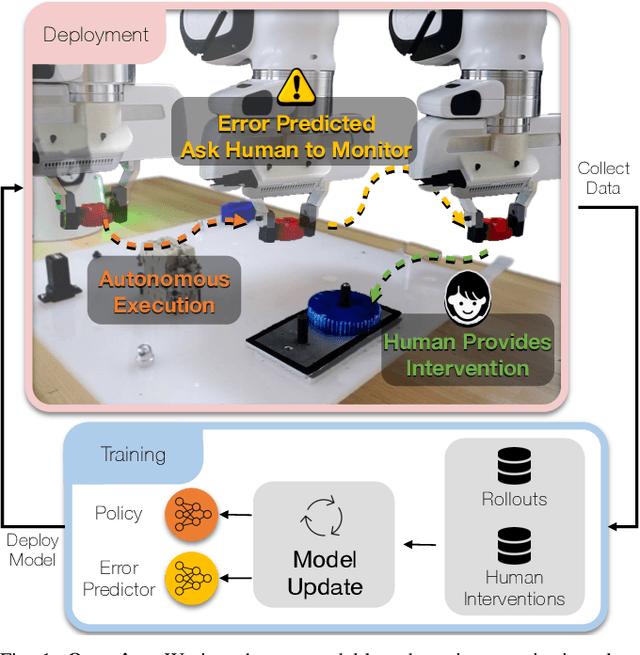
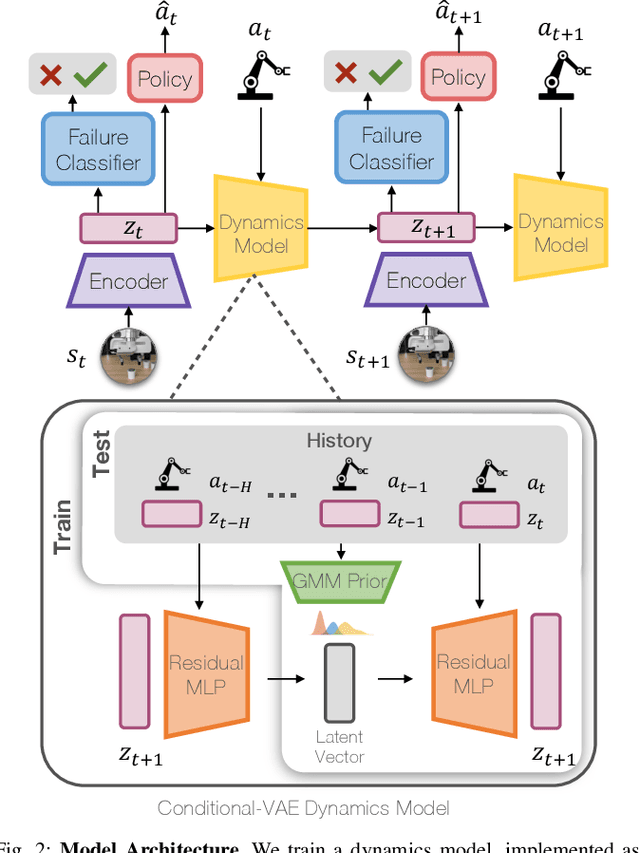
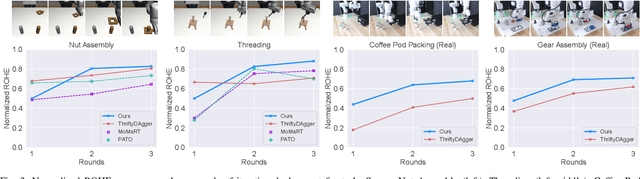

Robot learning methods have recently made great strides, but generalization and robustness challenges still hinder their widespread deployment. Failing to detect and address potential failures renders state-of-the-art learning systems not combat-ready for high-stakes tasks. Recent advances in interactive imitation learning have presented a promising framework for human-robot teaming, enabling the robots to operate safely and continually improve their performances over long-term deployments. Nonetheless, existing methods typically require constant human supervision and preemptive feedback, limiting their practicality in realistic domains. This work aims to endow a robot with the ability to monitor and detect errors during task execution. We introduce a model-based runtime monitoring algorithm that learns from deployment data to detect system anomalies and anticipate failures. Unlike prior work that cannot foresee future failures or requires failure experiences for training, our method learns a latent-space dynamics model and a failure classifier, enabling our method to simulate future action outcomes and detect out-of-distribution and high-risk states preemptively. We train our method within an interactive imitation learning framework, where it continually updates the model from the experiences of the human-robot team collected using trustworthy deployments. Consequently, our method reduces the human workload needed over time while ensuring reliable task execution. Our method outperforms the baselines across system-level and unit-test metrics, with 23% and 40% higher success rates in simulation and on physical hardware, respectively. More information at https://ut-austin-rpl.github.io/sirius-runtime-monitor/
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023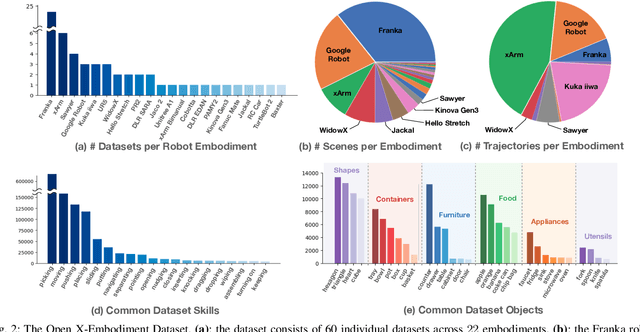
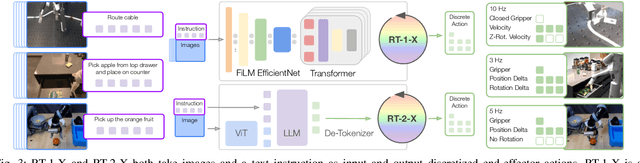
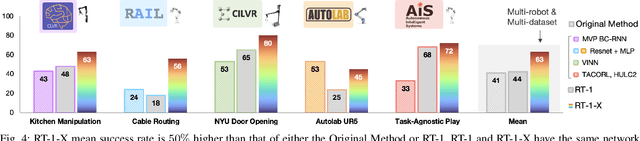

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Mini-BEHAVIOR: A Procedurally Generated Benchmark for Long-horizon Decision-Making in Embodied AI
Oct 03, 2023We present Mini-BEHAVIOR, a novel benchmark for embodied AI that challenges agents to use reasoning and decision-making skills to solve complex activities that resemble everyday human challenges. The Mini-BEHAVIOR environment is a fast, realistic Gridworld environment that offers the benefits of rapid prototyping and ease of use while preserving a symbolic level of physical realism and complexity found in complex embodied AI benchmarks. We introduce key features such as procedural generation, to enable the creation of countless task variations and support open-ended learning. Mini-BEHAVIOR provides implementations of various household tasks from the original BEHAVIOR benchmark, along with starter code for data collection and reinforcement learning agent training. In essence, Mini-BEHAVIOR offers a fast, open-ended benchmark for evaluating decision-making and planning solutions in embodied AI. It serves as a user-friendly entry point for research and facilitates the evaluation and development of solutions, simplifying their assessment and development while advancing the field of embodied AI. Code is publicly available at https://github.com/StanfordVL/mini_behavior.
MUTEX: Learning Unified Policies from Multimodal Task Specifications
Sep 25, 2023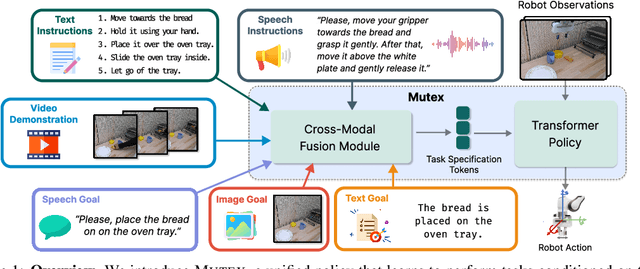
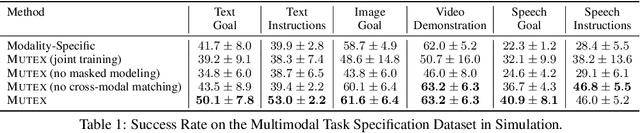
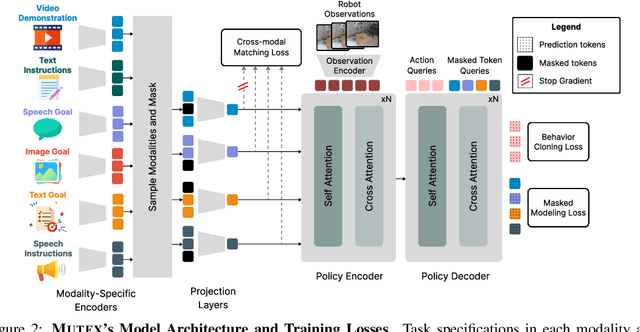
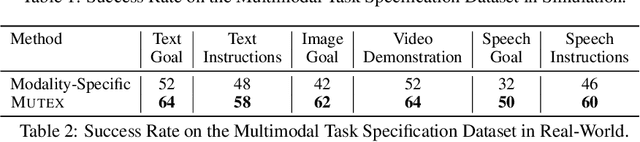
Humans use different modalities, such as speech, text, images, videos, etc., to communicate their intent and goals with teammates. For robots to become better assistants, we aim to endow them with the ability to follow instructions and understand tasks specified by their human partners. Most robotic policy learning methods have focused on one single modality of task specification while ignoring the rich cross-modal information. We present MUTEX, a unified approach to policy learning from multimodal task specifications. It trains a transformer-based architecture to facilitate cross-modal reasoning, combining masked modeling and cross-modal matching objectives in a two-stage training procedure. After training, MUTEX can follow a task specification in any of the six learned modalities (video demonstrations, goal images, text goal descriptions, text instructions, speech goal descriptions, and speech instructions) or a combination of them. We systematically evaluate the benefits of MUTEX in a newly designed dataset with 100 tasks in simulation and 50 tasks in the real world, annotated with multiple instances of task specifications in different modalities, and observe improved performance over methods trained specifically for any single modality. More information at https://ut-austin-rpl.github.io/MUTEX/
Task-Driven Graph Attention for Hierarchical Relational Object Navigation
Jun 23, 2023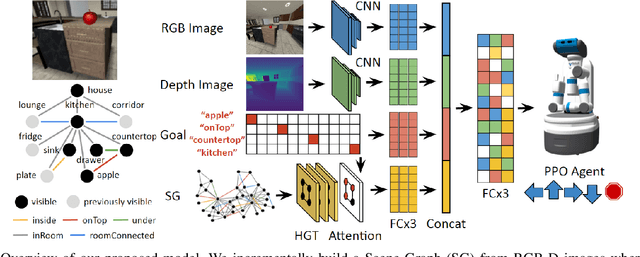

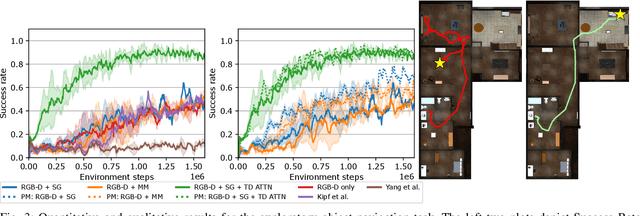

Embodied AI agents in large scenes often need to navigate to find objects. In this work, we study a naturally emerging variant of the object navigation task, hierarchical relational object navigation (HRON), where the goal is to find objects specified by logical predicates organized in a hierarchical structure - objects related to furniture and then to rooms - such as finding an apple on top of a table in the kitchen. Solving such a task requires an efficient representation to reason about object relations and correlate the relations in the environment and in the task goal. HRON in large scenes (e.g. homes) is particularly challenging due to its partial observability and long horizon, which invites solutions that can compactly store the past information while effectively exploring the scene. We demonstrate experimentally that scene graphs are the best-suited representation compared to conventional representations such as images or 2D maps. We propose a solution that uses scene graphs as part of its input and integrates graph neural networks as its backbone, with an integrated task-driven attention mechanism, and demonstrate its better scalability and learning efficiency than state-of-the-art baselines.
Modeling Dynamic Environments with Scene Graph Memory
Jun 12, 2023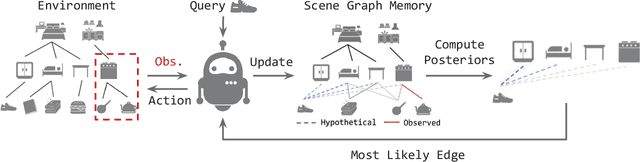
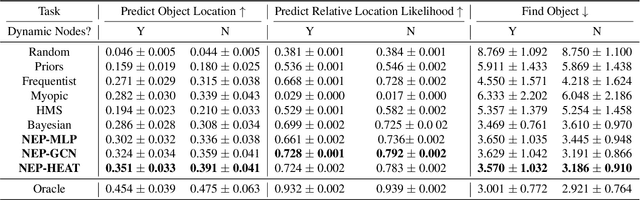
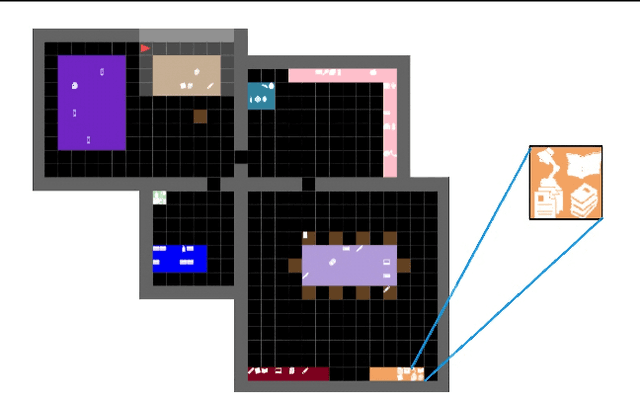

Embodied AI agents that search for objects in large environments such as households often need to make efficient decisions by predicting object locations based on partial information. We pose this as a new type of link prediction problem: link prediction on partially observable dynamic graphs. Our graph is a representation of a scene in which rooms and objects are nodes, and their relationships are encoded in the edges; only parts of the changing graph are known to the agent at each timestep. This partial observability poses a challenge to existing link prediction approaches, which we address. We propose a novel state representation -- Scene Graph Memory (SGM) -- with captures the agent's accumulated set of observations, as well as a neural net architecture called a Node Edge Predictor (NEP) that extracts information from the SGM to search efficiently. We evaluate our method in the Dynamic House Simulator, a new benchmark that creates diverse dynamic graphs following the semantic patterns typically seen at homes, and show that NEP can be trained to predict the locations of objects in a variety of environments with diverse object movement dynamics, outperforming baselines both in terms of new scene adaptability and overall accuracy. The codebase and more can be found at https://www.scenegraphmemory.com.
ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
May 18, 2023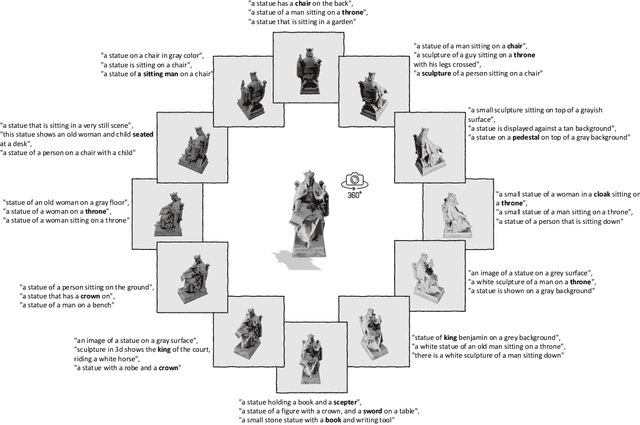

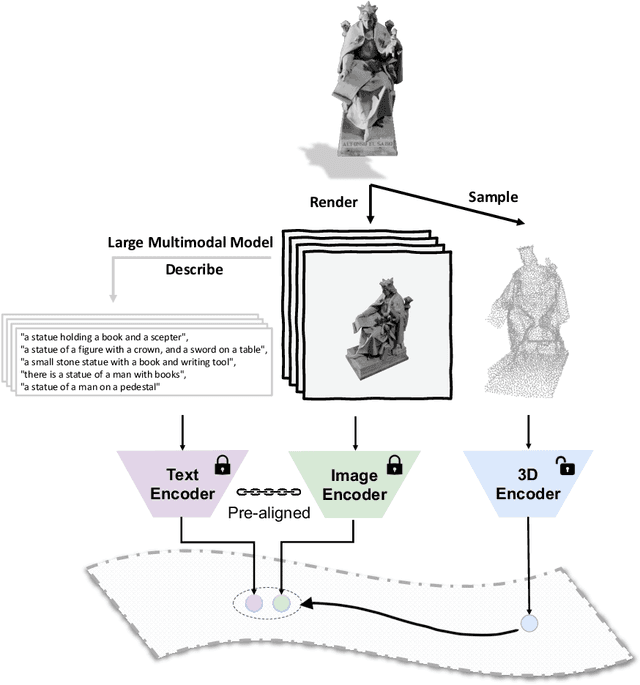
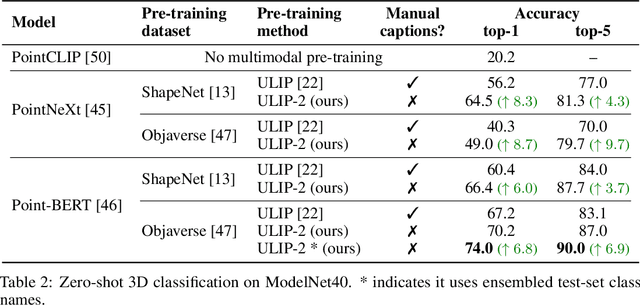
Recent advancements in multimodal pre-training methods have shown promising efficacy in 3D representation learning by aligning multimodal features across 3D shapes, their 2D counterparts, and language descriptions. However, the methods used by existing multimodal pre-training frameworks to gather multimodal data for 3D applications lack scalability and comprehensiveness, potentially constraining the full potential of multimodal learning. The main bottleneck lies in the language modality's scalability and comprehensiveness. To address this, we introduce ULIP-2, a tri-modal pre-training framework that leverages state-of-the-art large multimodal models to automatically generate holistic language counterparts for 3D objects. It does not require any 3D annotations, and is therefore scalable to large datasets. We conduct experiments on two large-scale 3D datasets, Objaverse and ShapeNet, and augment them with tri-modal datasets of 3D point clouds, images, and language for training ULIP-2. ULIP-2 achieves significant improvements on downstream zero-shot classification on ModelNet40 (74.0% in top-1 accuracy); on the real-world ScanObjectNN benchmark, it obtains 91.5% in overall accuracy with only 1.4 million parameters, signifying a breakthrough in scalable multimodal 3D representation learning without human 3D annotations. The code, along with the generated tri-modal datasets, can be found at https://github.com/salesforce/ULIP.