 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriya Sundaresan
RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches
Mar 05, 2024
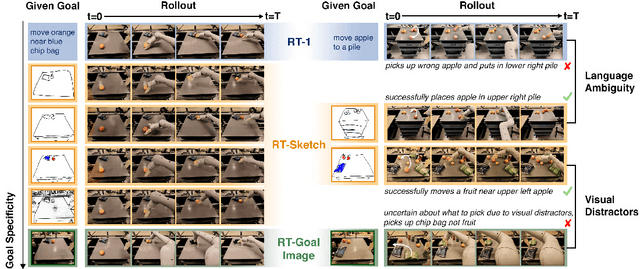
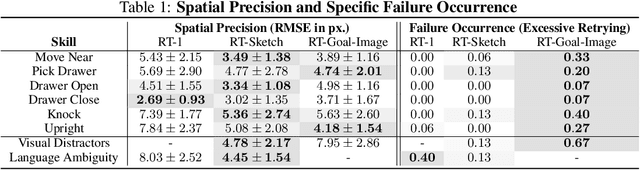
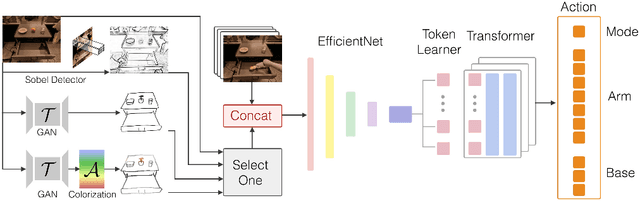
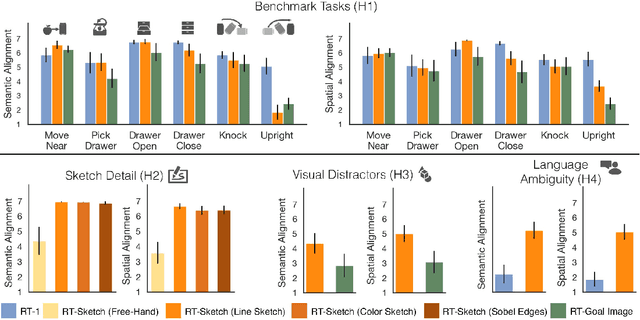
Natural language and images are commonly used as goal representations in goal-conditioned imitation learning (IL). However, natural language can be ambiguous and images can be over-specified. In this work, we propose hand-drawn sketches as a modality for goal specification in visual imitation learning. Sketches are easy for users to provide on the fly like language, but similar to images they can also help a downstream policy to be spatially-aware and even go beyond images to disambiguate task-relevant from task-irrelevant objects. We present RT-Sketch, a goal-conditioned policy for manipulation that takes a hand-drawn sketch of the desired scene as input, and outputs actions. We train RT-Sketch on a dataset of paired trajectories and corresponding synthetically generated goal sketches. We evaluate this approach on six manipulation skills involving tabletop object rearrangements on an articulated countertop. Experimentally we find that RT-Sketch is able to perform on a similar level to image or language-conditioned agents in straightforward settings, while achieving greater robustness when language goals are ambiguous or visual distractors are present. Additionally, we show that RT-Sketch has the capacity to interpret and act upon sketches with varied levels of specificity, ranging from minimal line drawings to detailed, colored drawings. For supplementary material and videos, please refer to our website: http://rt-sketch.github.io.
RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
Nov 06, 2023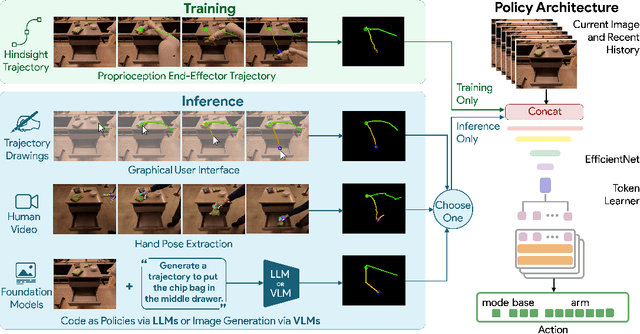
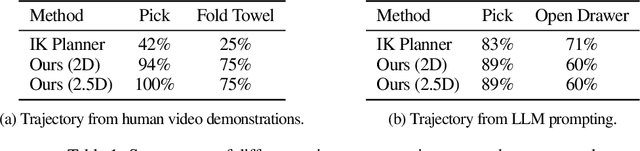
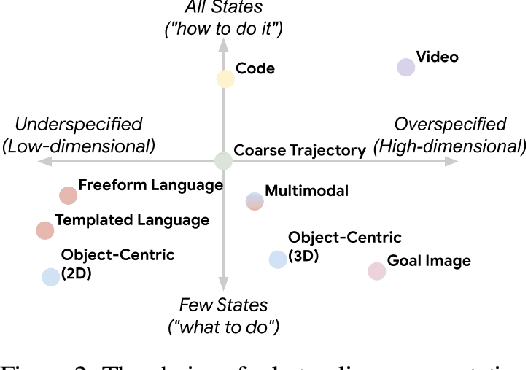

Generalization remains one of the most important desiderata for robust robot learning systems. While recently proposed approaches show promise in generalization to novel objects, semantic concepts, or visual distribution shifts, generalization to new tasks remains challenging. For example, a language-conditioned policy trained on pick-and-place tasks will not be able to generalize to a folding task, even if the arm trajectory of folding is similar to pick-and-place. Our key insight is that this kind of generalization becomes feasible if we represent the task through rough trajectory sketches. We propose a policy conditioning method using such rough trajectory sketches, which we call RT-Trajectory, that is practical, easy to specify, and allows the policy to effectively perform new tasks that would otherwise be challenging to perform. We find that trajectory sketches strike a balance between being detailed enough to express low-level motion-centric guidance while being coarse enough to allow the learned policy to interpret the trajectory sketch in the context of situational visual observations. In addition, we show how trajectory sketches can provide a useful interface to communicate with robotic policies: they can be specified through simple human inputs like drawings or videos, or through automated methods such as modern image-generating or waypoint-generating methods. We evaluate RT-Trajectory at scale on a variety of real-world robotic tasks, and find that RT-Trajectory is able to perform a wider range of tasks compared to language-conditioned and goal-conditioned policies, when provided the same training data.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023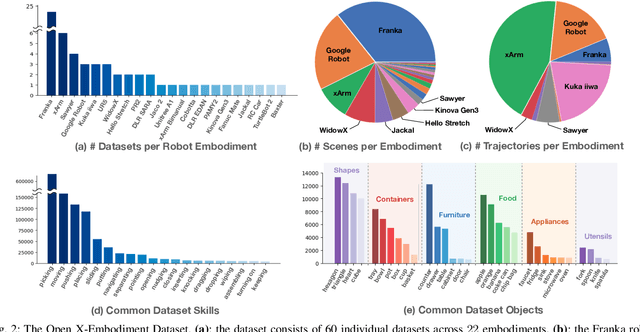
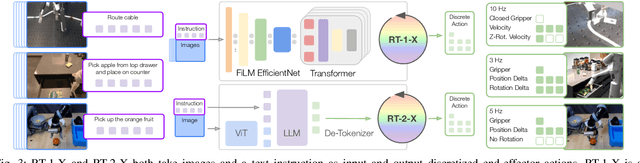
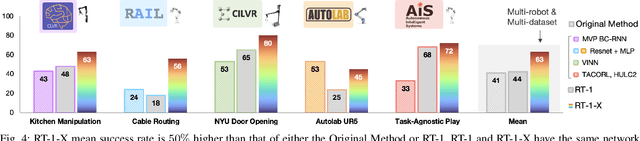

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Learning Sequential Acquisition Policies for Robot-Assisted Feeding
Sep 11, 2023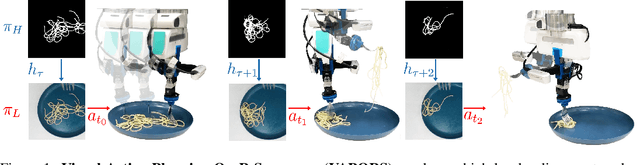
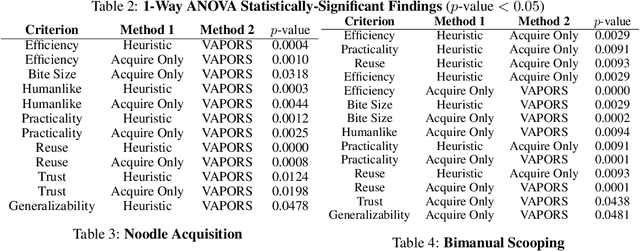
A robot providing mealtime assistance must perform specialized maneuvers with various utensils in order to pick up and feed a range of food items. Beyond these dexterous low-level skills, an assistive robot must also plan these strategies in sequence over a long horizon to clear a plate and complete a meal. Previous methods in robot-assisted feeding introduce highly specialized primitives for food handling without a means to compose them together. Meanwhile, existing approaches to long-horizon manipulation lack the flexibility to embed highly specialized primitives into their frameworks. We propose Visual Action Planning OveR Sequences (VAPORS), a framework for long-horizon food acquisition. VAPORS learns a policy for high-level action selection by leveraging learned latent plate dynamics in simulation. To carry out sequential plans in the real world, VAPORS delegates action execution to visually parameterized primitives. We validate our approach on complex real-world acquisition trials involving noodle acquisition and bimanual scooping of jelly beans. Across 38 plates, VAPORS acquires much more efficiently than baselines, generalizes across realistic plate variations such as toppings and sauces, and qualitatively appeals to user feeding preferences in a survey conducted across 49 individuals. Code, datasets, videos, and supplementary materials can be found on our website: https://sites.google.com/view/vaporsbot.
KITE: Keypoint-Conditioned Policies for Semantic Manipulation
Jul 06, 2023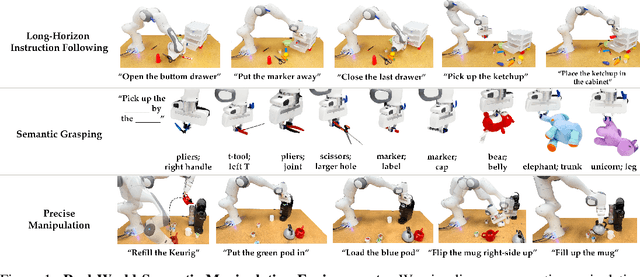
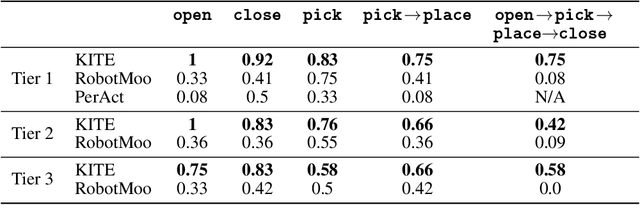
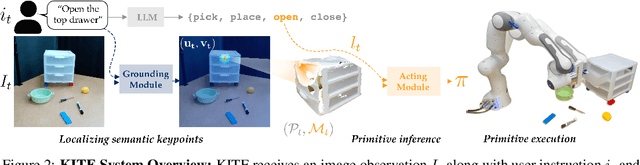

While natural language offers a convenient shared interface for humans and robots, enabling robots to interpret and follow language commands remains a longstanding challenge in manipulation. A crucial step to realizing a performant instruction-following robot is achieving semantic manipulation, where a robot interprets language at different specificities, from high-level instructions like "Pick up the stuffed animal" to more detailed inputs like "Grab the left ear of the elephant." To tackle this, we propose Keypoints + Instructions to Execution (KITE), a two-step framework for semantic manipulation which attends to both scene semantics (distinguishing between different objects in a visual scene) and object semantics (precisely localizing different parts within an object instance). KITE first grounds an input instruction in a visual scene through 2D image keypoints, providing a highly accurate object-centric bias for downstream action inference. Provided an RGB-D scene observation, KITE then executes a learned keypoint-conditioned skill to carry out the instruction. The combined precision of keypoints and parameterized skills enables fine-grained manipulation with generalization to scene and object variations. Empirically, we demonstrate KITE in 3 real-world environments: long-horizon 6-DoF tabletop manipulation, semantic grasping, and a high-precision coffee-making task. In these settings, KITE achieves a 75%, 70%, and 71% overall success rate for instruction-following, respectively. KITE outperforms frameworks that opt for pre-trained visual language models over keypoint-based grounding, or omit skills in favor of end-to-end visuomotor control, all while being trained from fewer or comparable amounts of demonstrations. Supplementary material, datasets, code, and videos can be found on our website: http://tinyurl.com/kite-site.
Learning Visuo-Haptic Skewering Strategies for Robot-Assisted Feeding
Nov 30, 2022

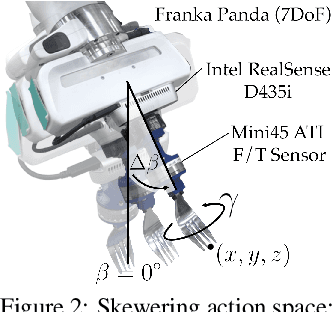

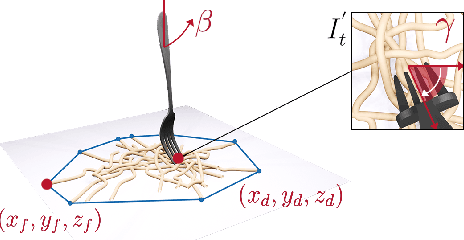
Acquiring food items with a fork poses an immense challenge to a robot-assisted feeding system, due to the wide range of material properties and visual appearances present across food groups. Deformable foods necessitate different skewering strategies than firm ones, but inferring such characteristics for several previously unseen items on a plate remains nontrivial. Our key insight is to leverage visual and haptic observations during interaction with an item to rapidly and reactively plan skewering motions. We learn a generalizable, multimodal representation for a food item from raw sensory inputs which informs the optimal skewering strategy. Given this representation, we propose a zero-shot framework to sense visuo-haptic properties of a previously unseen item and reactively skewer it, all within a single interaction. Real-robot experiments with foods of varying levels of visual and textural diversity demonstrate that our multimodal policy outperforms baselines which do not exploit both visual and haptic cues or do not reactively plan. Across 6 plates of different food items, our proposed framework achieves 71% success over 69 skewering attempts total. Supplementary material, datasets, code, and videos are available on our website: https://sites.google.com/view/hapticvisualnet-corl22/home
In-Mouth Robotic Bite Transfer with Visual and Haptic Sensing
Nov 23, 2022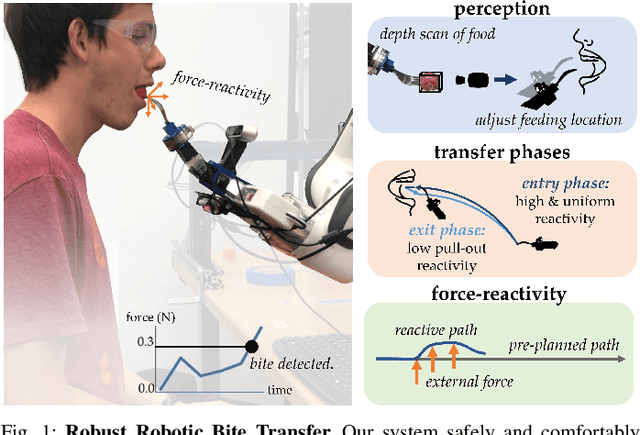


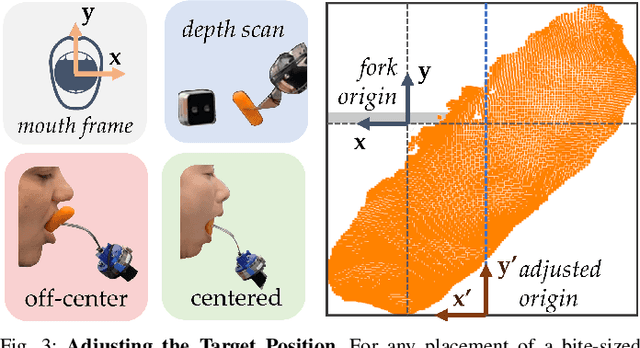
Assistance during eating is essential for those with severe mobility issues or eating risks. However, dependence on traditional human caregivers is linked to malnutrition, weight loss, and low self-esteem. For those who require eating assistance, a semi-autonomous robotic platform can provide independence and a healthier lifestyle. We demonstrate an essential capability of this platform: safe, comfortable, and effective transfer of a bite-sized food item from a utensil directly to the inside of a person's mouth. Our system uses a force-reactive controller to safely accommodate the user's motions throughout the transfer, allowing full reactivity until bite detection then reducing reactivity in the direction of exit. Additionally, we introduce a novel dexterous wrist-like end effector capable of small, unimposing movements to reduce user discomfort. We conduct a user study with 11 participants covering 8 diverse food categories to evaluate our system end-to-end, and we find that users strongly prefer our method to a wide range of baselines. Appendices and videos are available at our website: https://tinyurl.com/btICRA.
DiffCloud: Real-to-Sim from Point Clouds with Differentiable Simulation and Rendering of Deformable Objects
Apr 07, 2022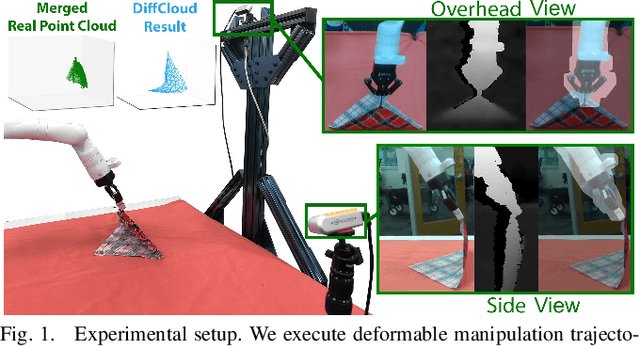

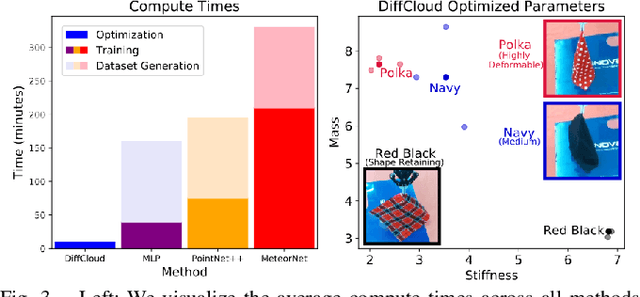
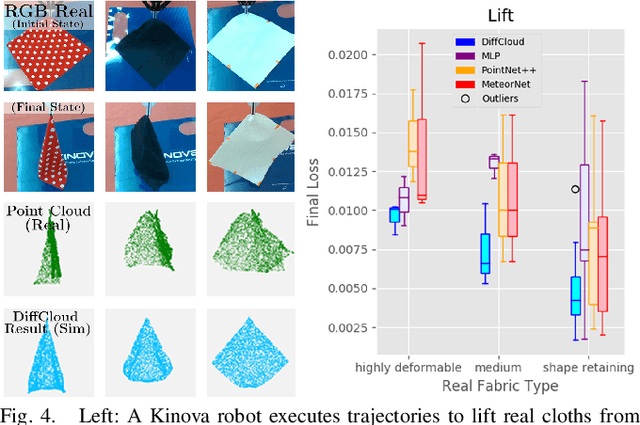
Research in manipulation of deformable objects is typically conducted on a limited range of scenarios, because handling each scenario on hardware takes significant effort. Realistic simulators with support for various types of deformations and interactions have the potential to speed up experimentation with novel tasks and algorithms. However, for highly deformable objects it is challenging to align the output of a simulator with the behavior of real objects. Manual tuning is not intuitive, hence automated methods are needed. We view this alignment problem as a joint perception-inference challenge and demonstrate how to use recent neural network architectures to successfully perform simulation parameter inference from real point clouds. We analyze the performance of various architectures, comparing their data and training requirements. Furthermore, we propose to leverage differentiable point cloud sampling and differentiable simulation to significantly reduce the time to achieve the alignment. We employ an efficient way to propagate gradients from point clouds to simulated meshes and further through to the physical simulation parameters, such as mass and stiffness. Experiments with highly deformable objects show that our method can achieve comparable or better alignment with real object behavior, while reducing the time needed to achieve this by more than an order of magnitude. Videos and supplementary material are available at https://tinyurl.com/diffcloud.
A Bayesian Treatment of Real-to-Sim for Deformable Object Manipulation
Dec 09, 2021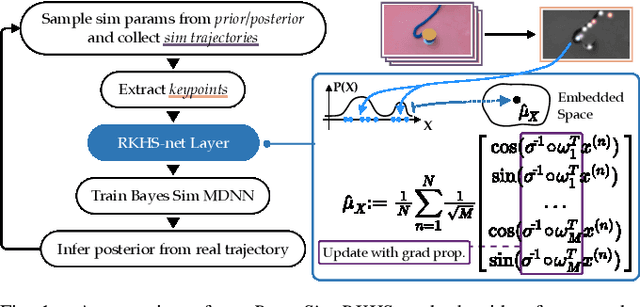


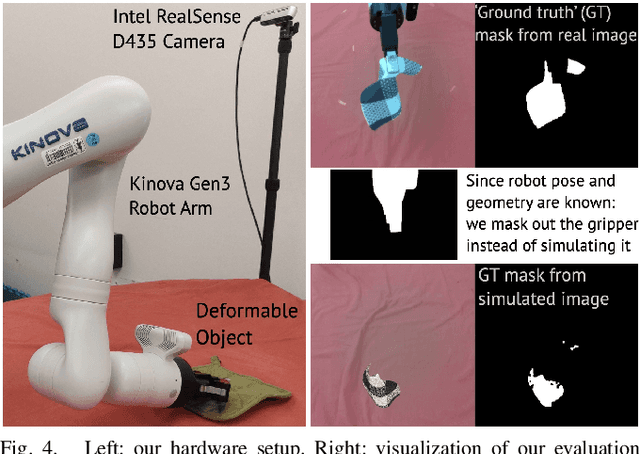
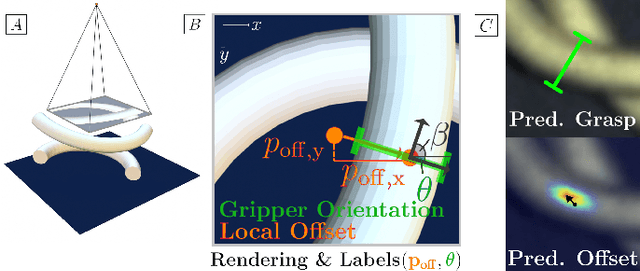
Deformable object manipulation remains a challenging task in robotics research. Conventional techniques for parameter inference and state estimation typically rely on a precise definition of the state space and its dynamics. While this is appropriate for rigid objects and robot states, it is challenging to define the state space of a deformable object and how it evolves in time. In this work, we pose the problem of inferring physical parameters of deformable objects as a probabilistic inference task defined with a simulator. We propose a novel methodology for extracting state information from image sequences via a technique to represent the state of a deformable object as a distribution embedding. This allows to incorporate noisy state observations directly into modern Bayesian simulation-based inference tools in a principled manner. Our experiments confirm that we can estimate posterior distributions of physical properties, such as elasticity, friction and scale of highly deformable objects, such as cloth and ropes. Overall, our method addresses the real-to-sim problem probabilistically and helps to better represent the evolution of the state of deformable objects.
Untangling Dense Non-Planar Knots by Learning Manipulation Features and Recovery Policies
Jun 29, 2021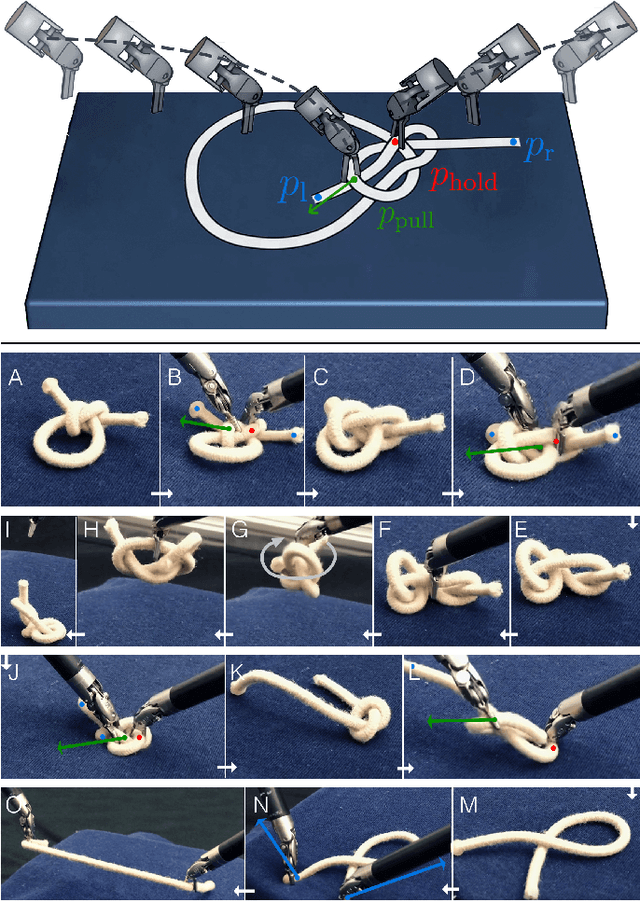

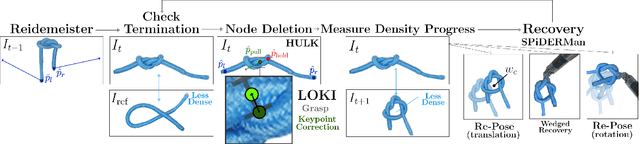
Robot manipulation for untangling 1D deformable structures such as ropes, cables, and wires is challenging due to their infinite dimensional configuration space, complex dynamics, and tendency to self-occlude. Analytical controllers often fail in the presence of dense configurations, due to the difficulty of grasping between adjacent cable segments. We present two algorithms that enhance robust cable untangling, LOKI and SPiDERMan, which operate alongside HULK, a high-level planner from prior work. LOKI uses a learned model of manipulation features to refine a coarse grasp keypoint prediction to a precise, optimized location and orientation, while SPiDERMan uses a learned model to sense task progress and apply recovery actions. We evaluate these algorithms in physical cable untangling experiments with 336 knots and over 1500 actions on real cables using the da Vinci surgical robot. We find that the combination of HULK, LOKI, and SPiDERMan is able to untangle dense overhand, figure-eight, double-overhand, square, bowline, granny, stevedore, and triple-overhand knots. The composition of these methods successfully untangles a cable from a dense initial configuration in 68.3% of 60 physical experiments and achieves 50% higher success rates than baselines from prior work. Supplementary material, code, and videos can be found at https://tinyurl.com/rssuntangling.