 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOier Mees
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
Feb 13, 2024
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that are grounded in visual observations and encode semantic features based on the VLM's internal knowledge, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings extracted from general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023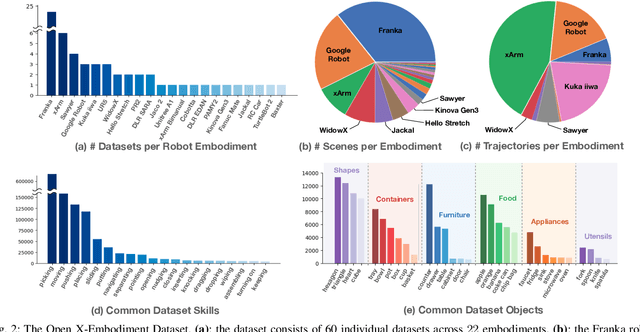
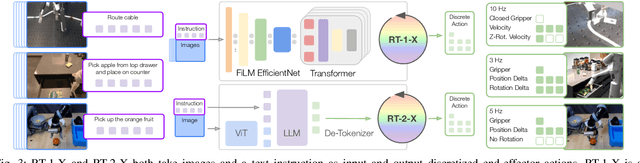
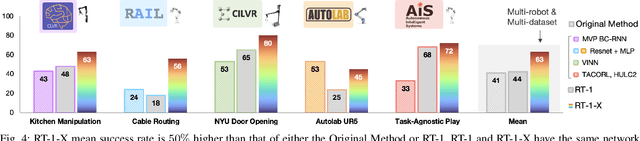

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Audio Visual Language Maps for Robot Navigation
Mar 27, 2023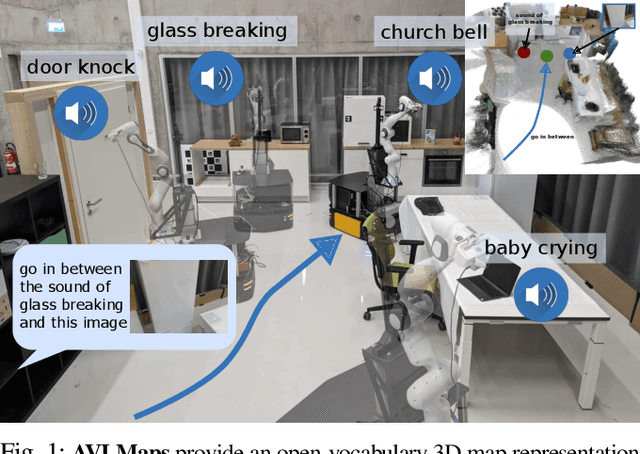
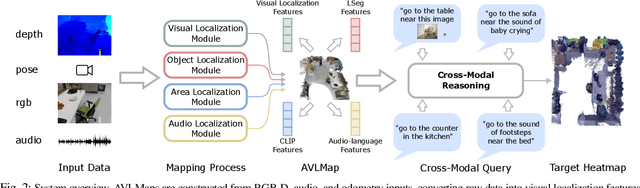


While interacting in the world is a multi-sensory experience, many robots continue to predominantly rely on visual perception to map and navigate in their environments. In this work, we propose Audio-Visual-Language Maps (AVLMaps), a unified 3D spatial map representation for storing cross-modal information from audio, visual, and language cues. AVLMaps integrate the open-vocabulary capabilities of multimodal foundation models pre-trained on Internet-scale data by fusing their features into a centralized 3D voxel grid. In the context of navigation, we show that AVLMaps enable robot systems to index goals in the map based on multimodal queries, e.g., textual descriptions, images, or audio snippets of landmarks. In particular, the addition of audio information enables robots to more reliably disambiguate goal locations. Extensive experiments in simulation show that AVLMaps enable zero-shot multimodal goal navigation from multimodal prompts and provide 50% better recall in ambiguous scenarios. These capabilities extend to mobile robots in the real world - navigating to landmarks referring to visual, audio, and spatial concepts. Videos and code are available at: https://avlmaps.github.io.
Visual Language Maps for Robot Navigation
Oct 17, 2022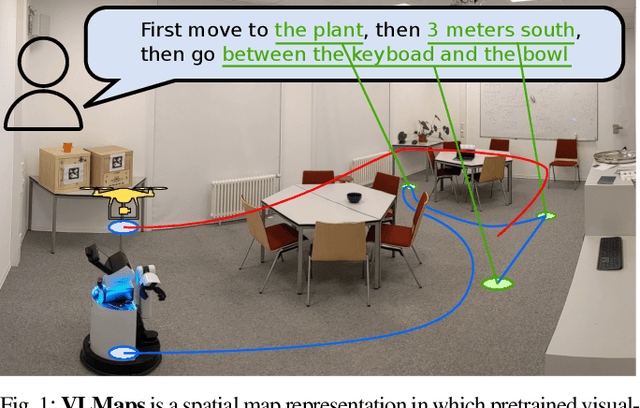

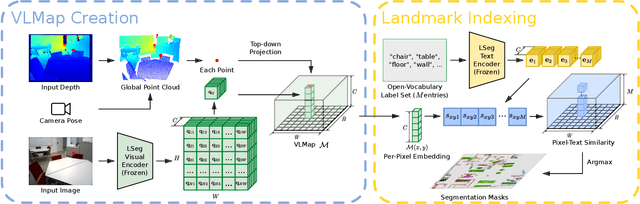

Grounding language to the visual observations of a navigating agent can be performed using off-the-shelf visual-language models pretrained on Internet-scale data (e.g., image captions). While this is useful for matching images to natural language descriptions of object goals, it remains disjoint from the process of mapping the environment, so that it lacks the spatial precision of classic geometric maps. To address this problem, we propose VLMaps, a spatial map representation that directly fuses pretrained visual-language features with a 3D reconstruction of the physical world. VLMaps can be autonomously built from video feed on robots using standard exploration approaches and enables natural language indexing of the map without additional labeled data. Specifically, when combined with large language models (LLMs), VLMaps can be used to (i) translate natural language commands into a sequence of open-vocabulary navigation goals (which, beyond prior work, can be spatial by construction, e.g., "in between the sofa and TV" or "three meters to the right of the chair") directly localized in the map, and (ii) can be shared among multiple robots with different embodiments to generate new obstacle maps on-the-fly (by using a list of obstacle categories). Extensive experiments carried out in simulated and real world environments show that VLMaps enable navigation according to more complex language instructions than existing methods. Videos are available at https://vlmaps.github.io.
Grounding Language with Visual Affordances over Unstructured Data
Oct 10, 2022
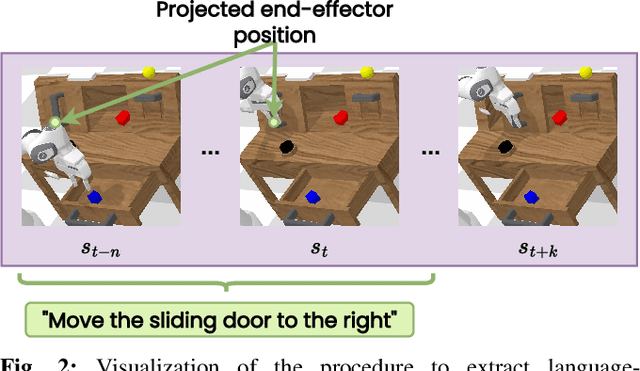
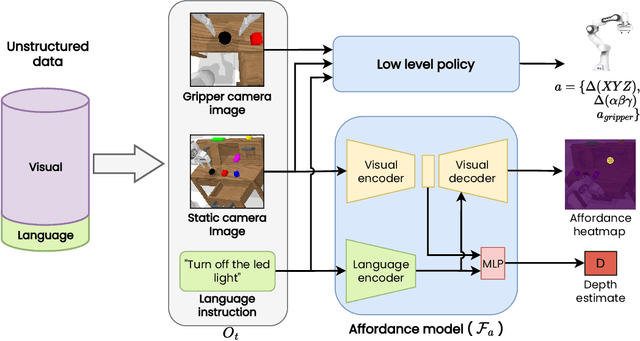
Recent works have shown that Large Language Models (LLMs) can be applied to ground natural language to a wide variety of robot skills. However, in practice, learning multi-task, language-conditioned robotic skills typically requires large-scale data collection and frequent human intervention to reset the environment or help correcting the current policies. In this work, we propose a novel approach to efficiently learn general-purpose language-conditioned robot skills from unstructured, offline and reset-free data in the real world by exploiting a self-supervised visuo-lingual affordance model, which requires annotating as little as 1% of the total data with language. We evaluate our method in extensive experiments both in simulated and real-world robotic tasks, achieving state-of-the-art performance on the challenging CALVIN benchmark and learning over 25 distinct visuomotor manipulation tasks with a single policy in the real world. We find that when paired with LLMs to break down abstract natural language instructions into subgoals via few-shot prompting, our method is capable of completing long-horizon, multi-tier tasks in the real world, while requiring an order of magnitude less data than previous approaches. Code and videos are available at http://hulc2.cs.uni-freiburg.de
Latent Plans for Task-Agnostic Offline Reinforcement Learning
Sep 19, 2022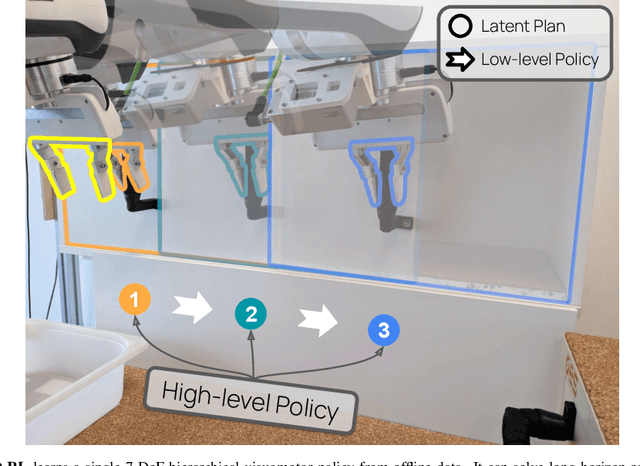

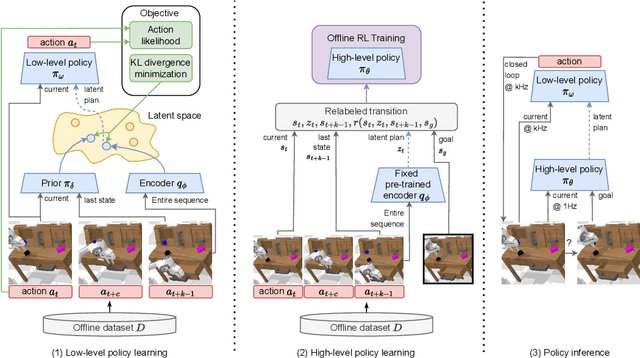

Everyday tasks of long-horizon and comprising a sequence of multiple implicit subtasks still impose a major challenge in offline robot control. While a number of prior methods aimed to address this setting with variants of imitation and offline reinforcement learning, the learned behavior is typically narrow and often struggles to reach configurable long-horizon goals. As both paradigms have complementary strengths and weaknesses, we propose a novel hierarchical approach that combines the strengths of both methods to learn task-agnostic long-horizon policies from high-dimensional camera observations. Concretely, we combine a low-level policy that learns latent skills via imitation learning and a high-level policy learned from offline reinforcement learning for skill-chaining the latent behavior priors. Experiments in various simulated and real robot control tasks show that our formulation enables producing previously unseen combinations of skills to reach temporally extended goals by "stitching" together latent skills through goal chaining with an order-of-magnitude improvement in performance upon state-of-the-art baselines. We even learn one multi-task visuomotor policy for 25 distinct manipulation tasks in the real world which outperforms both imitation learning and offline reinforcement learning techniques.
What Matters in Language Conditioned Robotic Imitation Learning
Apr 13, 2022
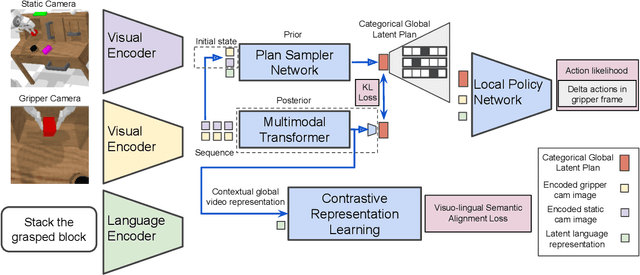
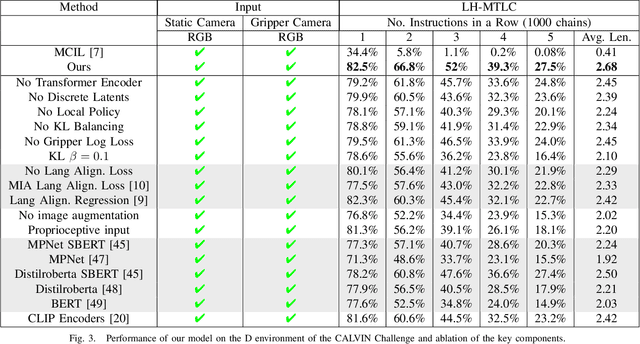
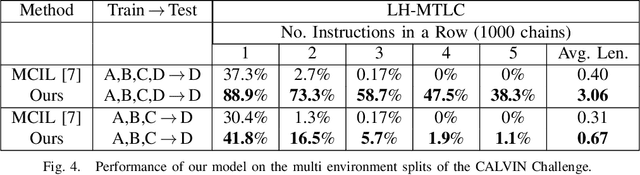
A long-standing goal in robotics is to build robots that can perform a wide range of daily tasks from perceptions obtained with their onboard sensors and specified only via natural language. While recently substantial advances have been achieved in language-driven robotics by leveraging end-to-end learning from pixels, there is no clear and well-understood process for making various design choices due to the underlying variation in setups. In this paper, we conduct an extensive study of the most critical challenges in learning language conditioned policies from offline free-form imitation datasets. We further identify architectural and algorithmic techniques that improve performance, such as a hierarchical decomposition of the robot control learning, a multimodal transformer encoder, discrete latent plans and a self-supervised contrastive loss that aligns video and language representations. By combining the results of our investigation with our improved model components, we are able to present a novel approach that significantly outperforms the state of the art on the challenging language conditioned long-horizon robot manipulation CALVIN benchmark. We have open-sourced our implementation to facilitate future research in learning to perform many complex manipulation skills in a row specified with natural language. Codebase and trained models available at http://hulc.cs.uni-freiburg.de
Affordance Learning from Play for Sample-Efficient Policy Learning
Mar 01, 2022
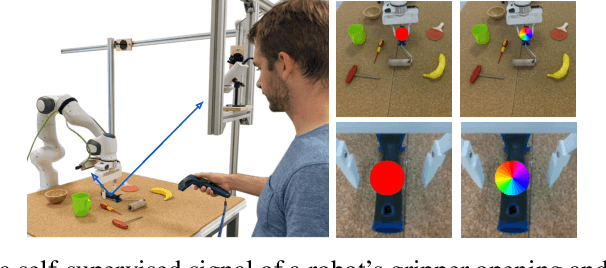

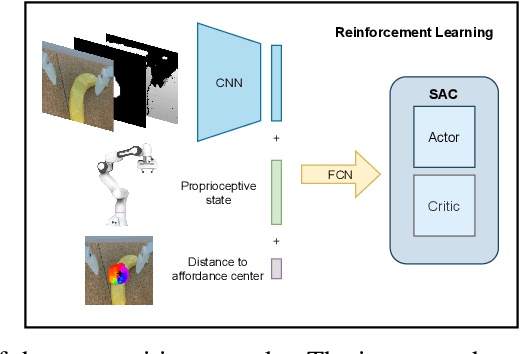
Robots operating in human-centered environments should have the ability to understand how objects function: what can be done with each object, where this interaction may occur, and how the object is used to achieve a goal. To this end, we propose a novel approach that extracts a self-supervised visual affordance model from human teleoperated play data and leverages it to enable efficient policy learning and motion planning. We combine model-based planning with model-free deep reinforcement learning (RL) to learn policies that favor the same object regions favored by people, while requiring minimal robot interactions with the environment. We evaluate our algorithm, Visual Affordance-guided Policy Optimization (VAPO), with both diverse simulation manipulation tasks and real world robot tidy-up experiments to demonstrate the effectiveness of our affordance-guided policies. We find that our policies train 4x faster than the baselines and generalize better to novel objects because our visual affordance model can anticipate their affordance regions.
CALVIN: A Benchmark for Language-conditioned Policy Learning for Long-horizon Robot Manipulation Tasks
Dec 08, 2021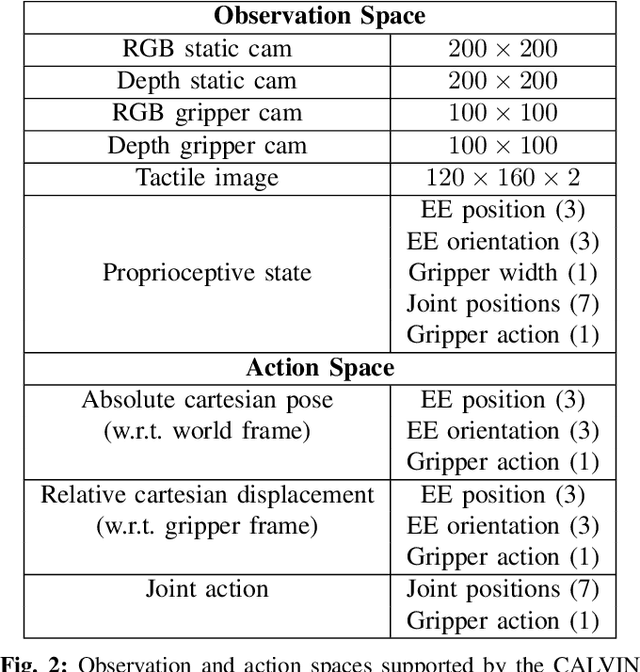
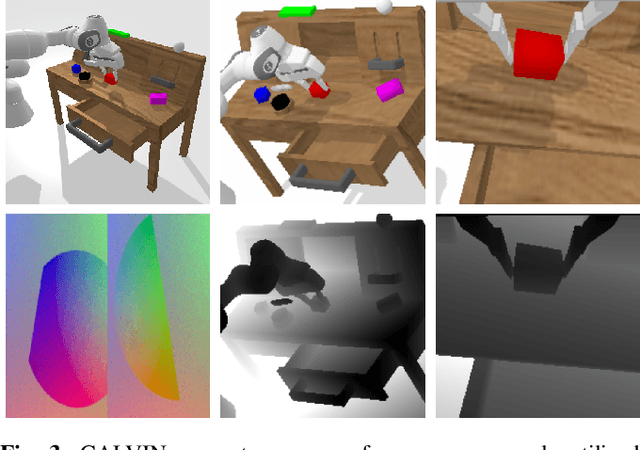
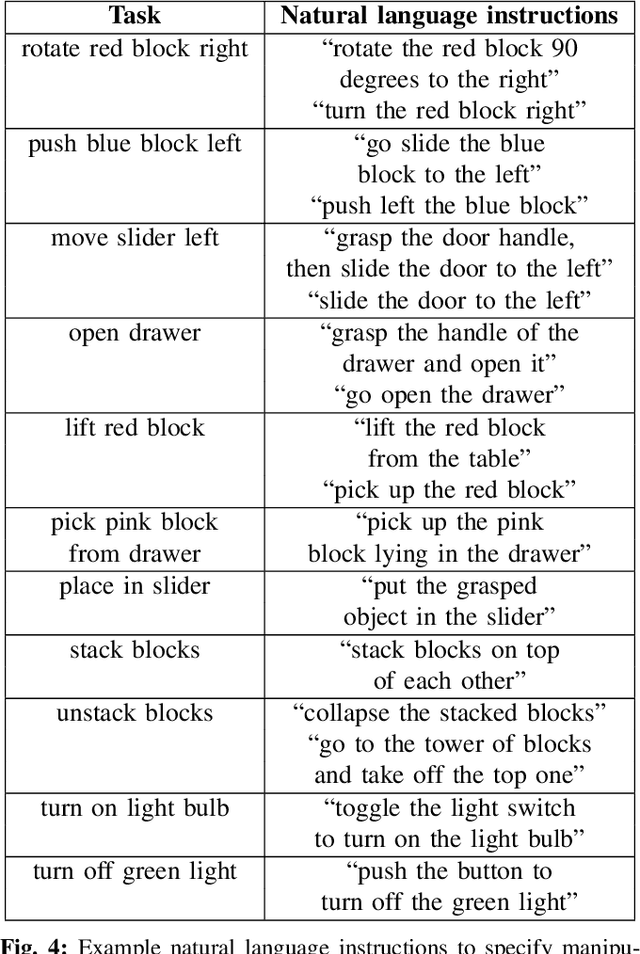

General-purpose robots coexisting with humans in their environment must learn to relate human language to their perceptions and actions to be useful in a range of daily tasks. Moreover, they need to acquire a diverse repertoire of general-purpose skills that allow composing long-horizon tasks by following unconstrained language instructions. In this paper, we present CALVIN (Composing Actions from Language and Vision), an open-source simulated benchmark to learn long-horizon language-conditioned tasks. Our aim is to make it possible to develop agents that can solve many robotic manipulation tasks over a long horizon, from onboard sensors, and specified only via human language. CALVIN tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets and supports flexible specification of sensor suites. We evaluate the agents in zero-shot to novel language instructions and to novel environments and objects. We show that a baseline model based on multi-context imitation learning performs poorly on CALVIN, suggesting that there is significant room for developing innovative agents that learn to relate human language to their world models with this benchmark.
Composing Pick-and-Place Tasks By Grounding Language
Feb 16, 2021
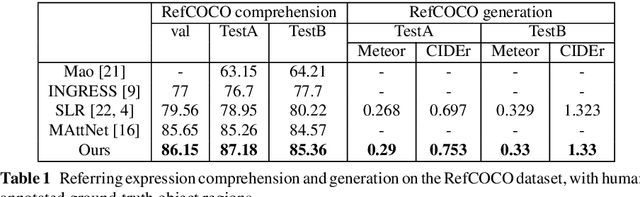
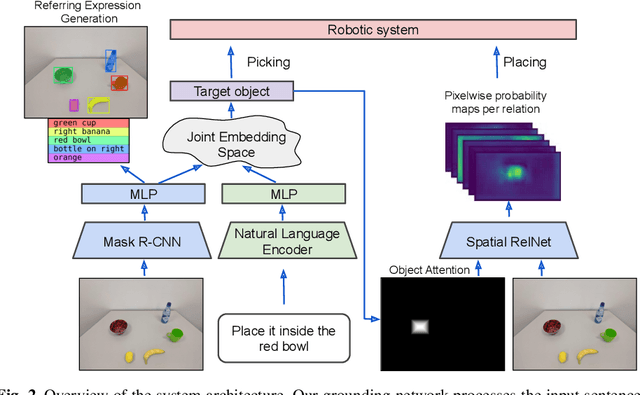
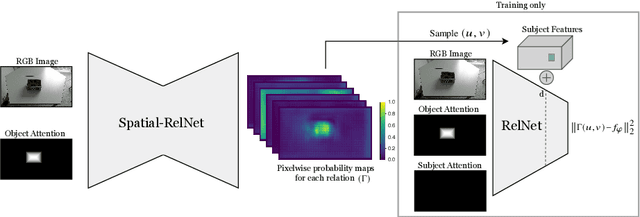
Controlling robots to perform tasks via natural language is one of the most challenging topics in human-robot interaction. In this work, we present a robot system that follows unconstrained language instructions to pick and place arbitrary objects and effectively resolves ambiguities through dialogues. Our approach infers objects and their relationships from input images and language expressions and can place objects in accordance with the spatial relations expressed by the user. Unlike previous approaches, we consider grounding not only for the picking but also for the placement of everyday objects from language. Specifically, by grounding objects and their spatial relations, we allow specification of complex placement instructions, e.g. "place it behind the middle red bowl". Our results obtained using a real-world PR2 robot demonstrate the effectiveness of our method in understanding pick-and-place language instructions and sequentially composing them to solve tabletop manipulation tasks. Videos are available at http://speechrobot.cs.uni-freiburg.de