 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoão Silvério
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023
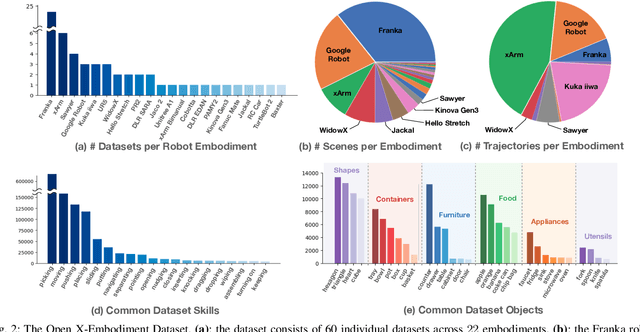
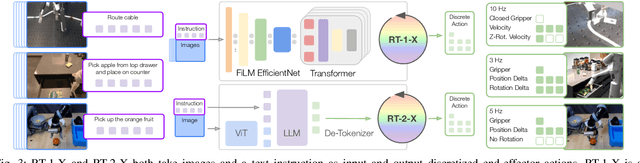
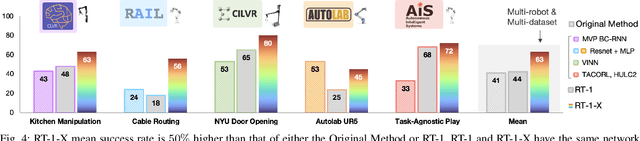

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
A Simple Open-Loop Baseline for Reinforcement Learning Locomotion Tasks
Oct 09, 2023In search of the simplest baseline capable of competing with Deep Reinforcement Learning on locomotion tasks, we propose a biologically inspired model-free open-loop strategy. Drawing upon prior knowledge and harnessing the elegance of simple oscillators to generate periodic joint motions, it achieves respectable performance in five different locomotion environments, with a number of tunable parameters that is a tiny fraction of the thousands typically required by RL algorithms. Unlike RL methods, which are prone to performance degradation when exposed to sensor noise or failure, our open-loop oscillators exhibit remarkable robustness due to their lack of reliance on sensors. Furthermore, we showcase a successful transfer from simulation to reality using an elastic quadruped, all without the need for randomization or reward engineering.
A Non-parametric Skill Representation with Soft Null Space Projectors for Fast Generalization
Sep 18, 2022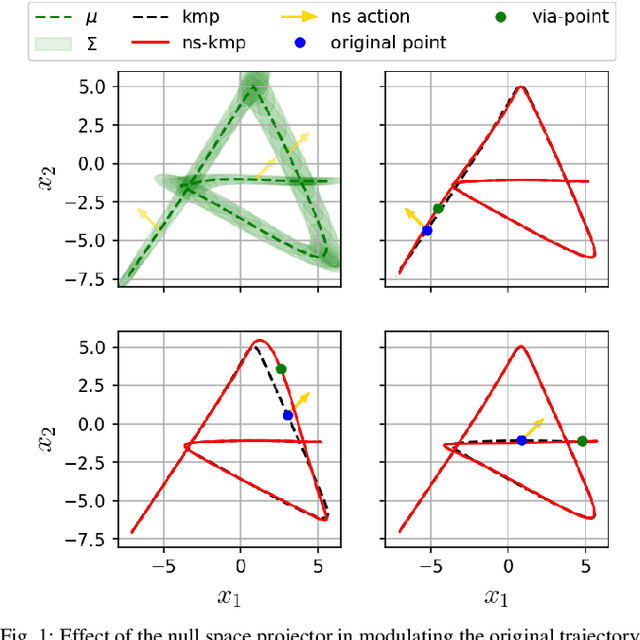

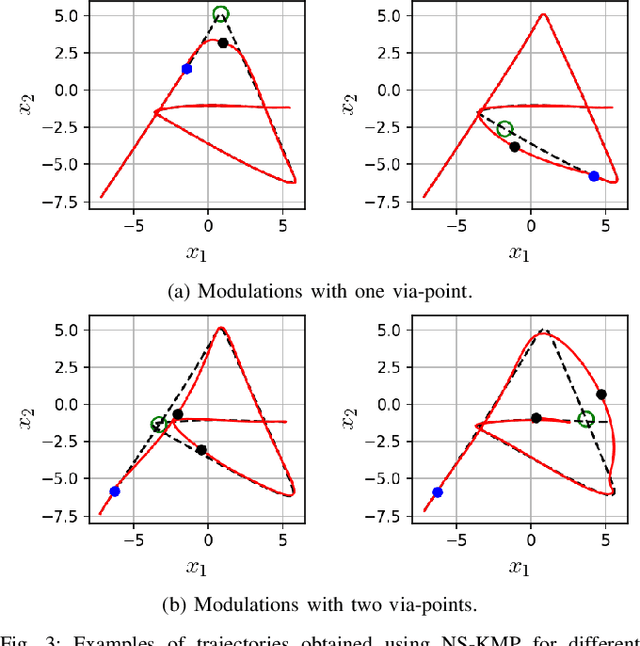

Over the last two decades, the robotics community witnessed the emergence of various motion representations that have been used extensively, particularly in behavorial cloning, to compactly encode and generalize skills. Among these, probabilistic approaches have earned a relevant place, owing to their encoding of variations, correlations and adaptability to new task conditions. Modulating such primitives, however, is often cumbersome due to the need for parameter re-optimization which frequently entails computationally costly operations. In this paper we derive a non-parametric movement primitive formulation that contains a null space projector. We show that such formulation allows for fast and efficient motion generation with computational complexity O(n2) without involving matrix inversions, whose complexity is O(n3). This is achieved by using the null space to track secondary targets, with a precision determined by the training dataset. Using a 2D example associated with time input we show that our non-parametric solution compares favourably with a state-of-the-art parametric approach. For demonstrated skills with high-dimensional inputs we show that it permits on-the-fly adaptation as well.
Learning to Exploit Elastic Actuators for Quadruped Locomotion
Sep 15, 2022
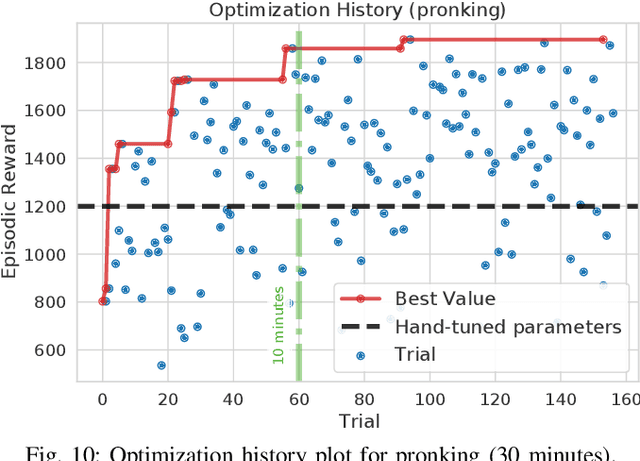

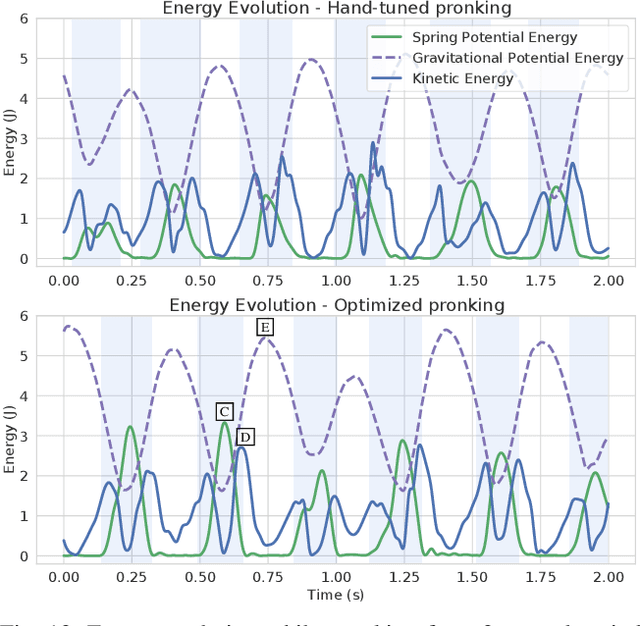
Spring-based actuators in legged locomotion provide energy-efficiency and improved performance, but increase the difficulty of controller design. Whereas previous works have focused on extensive modeling and simulation to find optimal controllers for such systems, we propose to learn model-free controllers directly on the real robot. In our approach, gaits are first synthesized by central pattern generators (CPGs), whose parameters are optimized to quickly obtain an open-loop controller that achieves efficient locomotion. Then, to make that controller more robust and further improve the performance, we use reinforcement learning to close the loop, to learn corrective actions on top of the CPGs. We evaluate the proposed approach in DLR's elastic quadruped bert. Our results in learning trotting and pronking gaits show that exploitation of the spring actuator dynamics emerges naturally from optimizing for dynamic motions, yielding high-performing locomotion despite being model-free. The whole process takes no more than 1.5 hours on the real robot and results in natural-looking gaits.
Ergodic Exploration using Tensor Train: Applications in Insertion Tasks
Jan 12, 2021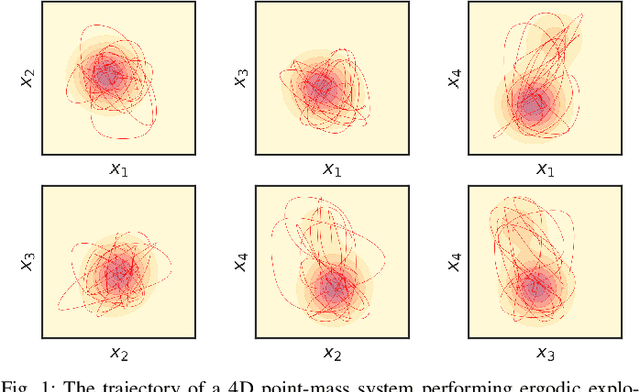

By generating control policies that create natural search behaviors in autonomous systems, ergodic control provides a principled solution to address tasks that require exploration. A large class of ergodic control algorithms relies on spectral analysis, which suffers from the curse of dimensionality, both in storage and computation. This drawback has prohibited the application of ergodic control in robot manipulation since it often requires exploration in state space with more than 2 dimensions. Indeed, the original ergodic control formulation will typically not allow exploratory behaviors to be generated for a complete 6D end-effector pose. In this paper, we propose a solution for ergodic exploration based on the spectral analysis in multidimensional spaces using low-rank tensor approximation techniques. We rely on tensor train decomposition, a recent approach from multilinear algebra for low-rank approximation and efficient computation of multidimensional arrays. The proposed solution is efficient both computationally and storage-wise, hence making it suitable for its online implementation in robotic systems. The approach is applied to a peg-in-hole insertion task using a 7-axis Franka Emika Panda robot, where ergodic exploration allows the task to be achieved without requiring the use of force/torque sensors.
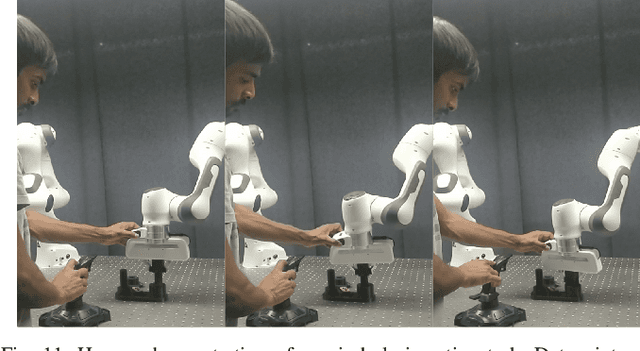
Motion Mappings for Continuous Bilateral Teleoperation
Dec 11, 2020
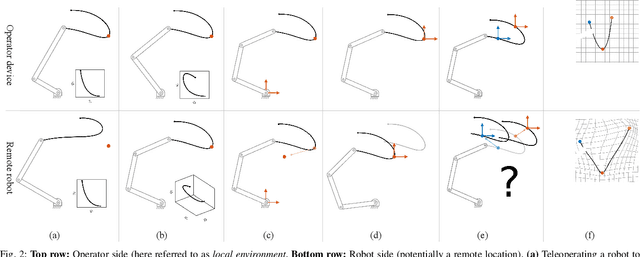
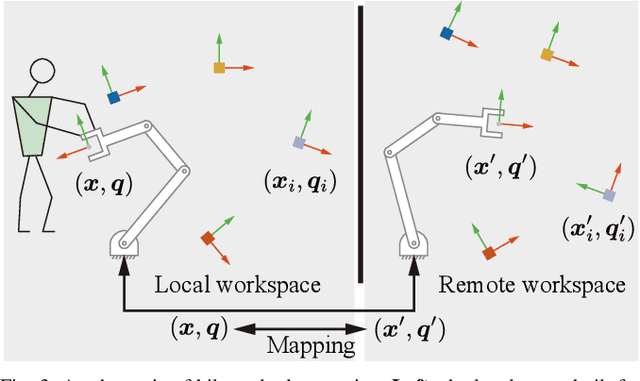

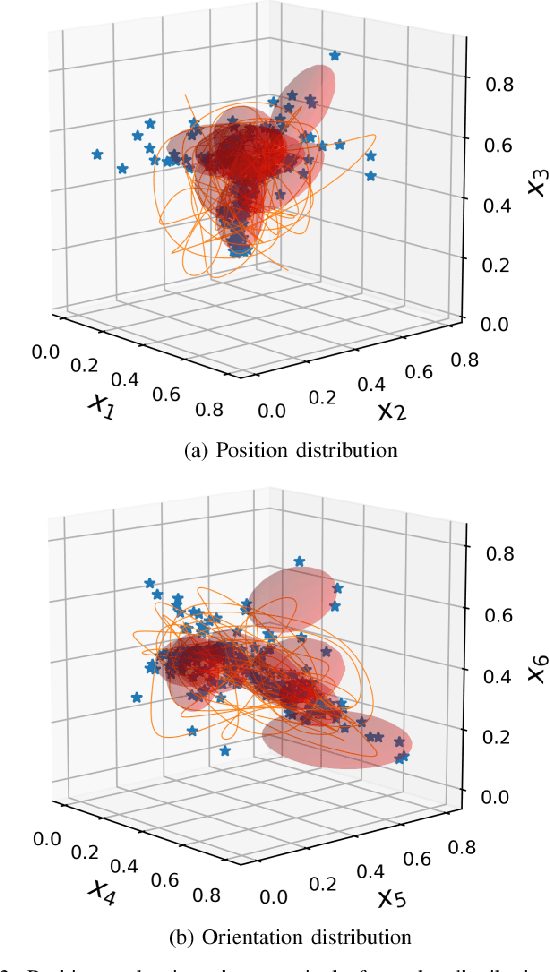
Mapping operator motions to a robot is a key problem in teleoperation. Due to differences between workspaces, such as object locations, it is particularly challenging to derive smooth motion mappings that fulfill different goals (e.g. picking objects with different poses on the two sides or passing through key points). Indeed, most state-of-the-art methods rely on mode switches, leading to a discontinuous, low-transparency experience. In this paper, we propose a unified formulation for position, orientation and velocity mappings based on the poses of objects of interest in the operator and robot workspaces. We apply it in the context of bilateral teleoperation. Two possible implementations to achieve the proposed mappings are studied: an iterative approach based on locally-weighted translations and rotations, and a neural network approach. Evaluations are conducted both in simulation and using two torque-controlled Franka Emika Panda robots. Our results show that, despite longer training times, the neural network approach provides faster mapping evaluations and lower interaction forces for the operator, which are crucial for continuous, real-time teleoperation.
A Laser-based Dual-arm System for Precise Control of Collaborative Robots
Nov 03, 2020
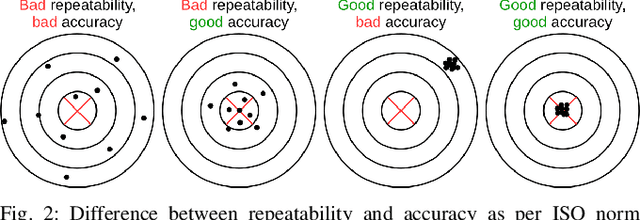


Collaborative robots offer increased interaction capabilities at relatively low cost but, in contrast to their industrial counterparts, they inevitably lack precision. Moreover, in addition to the robots' own imperfect models, day-to-day operations entail various sources of errors that, despite small, rapidly accumulate as tasks change and robots are re-programmed, often requiring time-consuming calibrations. These aspects strongly limit the application of collaborative robots in tasks demanding high precision such as watch-making. We address this problem by relying on a dual-arm system with laser-based sensing to measure relative poses between objects of interest and compensate for pose errors coming from robot proprioception. Our approach leverages previous knowledge of object 3D models in combination with point cloud registration to efficiently extract relevant poses and compute corrective trajectories. This results in high-precision assembly behaviors. The approach is validated in a needle threading experiment, with a $150\mu m$ thread and a $300\mu m$ needle hole, and a USB insertion task using two 7-axis Panda robots.
Learning from demonstration using products of experts: applications to manipulation and task prioritization
Oct 07, 2020

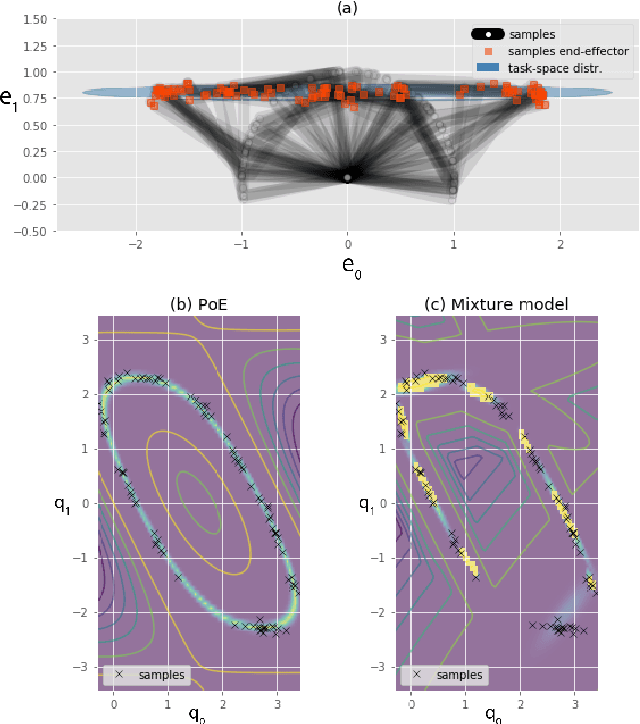

Probability distributions are key components of many learning from demonstration (LfD) approaches. While the configuration of a manipulator is defined by its joint angles, poses are often best explained within several task spaces. In many approaches, distributions within relevant task spaces are learned independently and only combined at the control level. This simplification implies several problems that are addressed in this work. We show that the fusion of models in different task spaces can be expressed as a product of experts (PoE), where the probabilities of the models are multiplied and renormalized so that it becomes a proper distribution of joint angles. Multiple experiments are presented to show that learning the different models jointly in the PoE framework significantly improves the quality of the model. The proposed approach particularly stands out when the robot has to learn competitive or hierarchical objectives. Training the model jointly usually relies on contrastive divergence, which requires costly approximations that can affect performance. We propose an alternative strategy using variational inference and mixture model approximations. In particular, we show that the proposed approach can be extended to PoE with a nullspace structure (PoENS), where the model is able to recover tasks that are masked by the resolution of higher-level objectives.
Towards Orientation Learning and Adaptation in Cartesian Space
Jul 09, 2019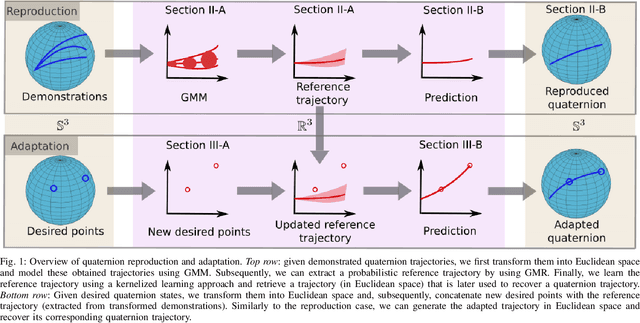


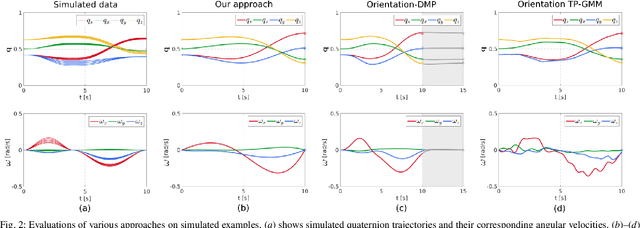
As a promising branch in robotics, imitation learning emerges as an important way to transfer human skills to robots, where human demonstrations represented in Cartesian or joint spaces are utilized to estimate task/skill models that can be subsequently generalized to new situations. While learning Cartesian positions suffices for many applications, the end-effector orientation is required in many others. Despite recent advancements in learning orientations from demonstrations, several crucial issues have not been adequately addressed yet. For instance, how can demonstrated orientations be adapted to pass through arbitrary desired points that comprise orientations and angular velocities? In this paper, we propose an approach that is capable of learning multiple orientation trajectories and adapting learned orientation skills to new situations (e.g., via-points and end-points), where both orientation and angular velocity are considered. Specifically, we introduce a kernelized treatment to alleviate explicit basis functions when learning orientations, which allows for learning orientation trajectories associated with high-dimensional inputs. In addition, we extend our approach to the learning of quaternions with jerk constraints, which allows for generating more smooth orientation profiles for robots. Several examples including comparison with state-of-the-art approaches as well as real experiments are provided to verify the effectiveness of our method.
Uncertainty-Aware Imitation Learning using Kernelized Movement Primitives
Mar 11, 2019

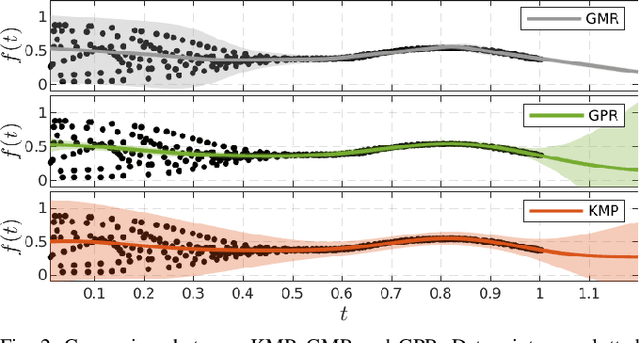

During the past few years, probabilistic approaches to imitation learning have earned a relevant place in the literature. One of their most prominent features, in addition to extracting a mean trajectory from task demonstrations, is that they provide a variance estimation. The intuitive meaning of this variance, however, changes across different techniques, indicating either variability or uncertainty. In this paper we leverage kernelized movement primitives (KMP) to provide a new perspective on imitation learning by predicting variability, correlations and uncertainty about robot actions. This rich set of information is used in combination with optimal controller fusion to learn actions from data, with two main advantages: i) robots become safe when uncertain about their actions and ii) they are able to leverage partial demonstrations, given as elementary sub-tasks, to optimally perform a higher level, more complex task. We showcase our approach in a painting task, where a human user and a KUKA robot collaborate to paint a wooden board. The task is divided into two sub-tasks and we show that using our approach the robot becomes compliant (hence safe) outside the training regions and executes the two sub-tasks with optimal gains.