 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRafael Rafailov
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data
Apr 23, 2024
Learning from preference labels plays a crucial role in fine-tuning large language models. There are several distinct approaches for preference fine-tuning, including supervised learning, on-policy reinforcement learning (RL), and contrastive learning. Different methods come with different implementation tradeoffs and performance differences, and existing empirical findings present different conclusions, for instance, some results show that online RL is quite important to attain good fine-tuning results, while others find (offline) contrastive or even purely supervised methods sufficient. This raises a natural question: what kind of approaches are important for fine-tuning with preference data and why? In this paper, we answer this question by performing a rigorous analysis of a number of fine-tuning techniques on didactic and full-scale LLM problems. Our main finding is that, in general, approaches that use on-policy sampling or attempt to push down the likelihood on certain responses (i.e., employ a "negative gradient") outperform offline and maximum likelihood objectives. We conceptualize our insights and unify methods that use on-policy sampling or negative gradient under a notion of mode-seeking objectives for categorical distributions. Mode-seeking objectives are able to alter probability mass on specific bins of a categorical distribution at a fast rate compared to maximum likelihood, allowing them to relocate masses across bins more effectively. Our analysis prescribes actionable insights for preference fine-tuning of LLMs and informs how data should be collected for maximal improvement.
Self-Supervised Alignment with Mutual Information: Learning to Follow Principles without Preference Labels
Apr 22, 2024When prompting a language model (LM), users frequently expect the model to adhere to a set of behavioral principles across diverse tasks, such as producing insightful content while avoiding harmful or biased language. Instilling such principles into a model can be resource-intensive and technically challenging, generally requiring human preference labels or examples. We introduce SAMI, a method for teaching a pretrained LM to follow behavioral principles that does not require any preference labels or demonstrations. SAMI is an iterative algorithm that finetunes a pretrained LM to increase the conditional mutual information between constitutions and self-generated responses given queries from a datasest. On single-turn dialogue and summarization, a SAMI-trained mistral-7b outperforms the initial pretrained model, with win rates between 66% and 77%. Strikingly, it also surpasses an instruction-finetuned baseline (mistral-7b-instruct) with win rates between 55% and 57% on single-turn dialogue. SAMI requires a "principle writer" model; to avoid dependence on stronger models, we further evaluate aligning a strong pretrained model (mixtral-8x7b) using constitutions written by a weak instruction-finetuned model (mistral-7b-instruct). The SAMI-trained mixtral-8x7b outperforms both the initial model and the instruction-finetuned model, achieving a 65% win rate on summarization. Our results indicate that a pretrained LM can learn to follow constitutions without using preference labels, demonstrations, or human oversight.
From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function
Apr 18, 2024Reinforcement Learning From Human Feedback (RLHF) has been a critical to the success of the latest generation of generative AI models. In response to the complex nature of the classical RLHF pipeline, direct alignment algorithms such as Direct Preference Optimization (DPO) have emerged as an alternative approach. Although DPO solves the same objective as the standard RLHF setup, there is a mismatch between the two approaches. Standard RLHF deploys reinforcement learning in a specific token-level MDP, while DPO is derived as a bandit problem in which the whole response of the model is treated as a single arm. In this work we rectify this difference, first we theoretically show that we can derive DPO in the token-level MDP as a general inverse Q-learning algorithm, which satisfies the Bellman equation. Using our theoretical results, we provide three concrete empirical insights. First, we show that because of its token level interpretation, DPO is able to perform some type of credit assignment. Next, we prove that under the token level formulation, classical search-based algorithms, such as MCTS, which have recently been applied to the language generation space, are equivalent to likelihood-based search on a DPO policy. Empirically we show that a simple beam search yields meaningful improvement over the base DPO policy. Finally, we show how the choice of reference policy causes implicit rewards to decline during training. We conclude by discussing applications of our work, including information elicitation in multi-tun dialogue, reasoning, agentic applications and end-to-end training of multi-model systems.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.
Disentangling Length from Quality in Direct Preference Optimization
Mar 28, 2024



Reinforcement Learning from Human Feedback (RLHF) has been a crucial component in the recent success of Large Language Models. However, RLHF is know to exploit biases in human preferences, such as verbosity. A well-formatted and eloquent answer is often more highly rated by users, even when it is less helpful and objective. A number of approaches have been developed to control those biases in the classical RLHF literature, but the problem remains relatively under-explored for Direct Alignment Algorithms such as Direct Preference Optimization (DPO). Unlike classical RLHF, DPO does not train a separate reward model or use reinforcement learning directly, so previous approaches developed to control verbosity cannot be directly applied to this setting. Our work makes several contributions. For the first time, we study the length problem in the DPO setting, showing significant exploitation in DPO and linking it to out-of-distribution bootstrapping. We then develop a principled but simple regularization strategy that prevents length exploitation, while still maintaining improvements in model quality. We demonstrate these effects across datasets on summarization and dialogue, where we achieve up to 20\% improvement in win rates when controlling for length, despite the GPT4 judge's well-known verbosity bias.
Aligning Modalities in Vision Large Language Models via Preference Fine-tuning
Feb 18, 2024Instruction-following Vision Large Language Models (VLLMs) have achieved significant progress recently on a variety of tasks. These approaches merge strong pre-trained vision models and large language models (LLMs). Since these components are trained separately, the learned representations need to be aligned with joint training on additional image-language pairs. This procedure is not perfect and can cause the model to hallucinate - provide answers that do not accurately reflect the image, even when the core LLM is highly factual and the vision backbone has sufficiently complete representations. In this work, we frame the hallucination problem as an alignment issue, tackle it with preference tuning. Specifically, we propose POVID to generate feedback data with AI models. We use ground-truth instructions as the preferred response and a two-stage approach to generate dispreferred data. First, we prompt GPT-4V to inject plausible hallucinations into the correct answer. Second, we distort the image to trigger the inherent hallucination behavior of the VLLM. This is an automated approach, which does not rely on human data generation or require a perfect expert, which makes it easily scalable. Finally, both of these generation strategies are integrated into an RLHF pipeline via Direct Preference Optimization. In experiments across broad benchmarks, we show that we can not only reduce hallucinations, but improve model performance across standard benchmarks, outperforming prior approaches. Our data and code are available at https://github.com/YiyangZhou/POVID.
MOTO: Offline Pre-training to Online Fine-tuning for Model-based Robot Learning
Jan 06, 2024We study the problem of offline pre-training and online fine-tuning for reinforcement learning from high-dimensional observations in the context of realistic robot tasks. Recent offline model-free approaches successfully use online fine-tuning to either improve the performance of the agent over the data collection policy or adapt to novel tasks. At the same time, model-based RL algorithms have achieved significant progress in sample efficiency and the complexity of the tasks they can solve, yet remain under-utilized in the fine-tuning setting. In this work, we argue that existing model-based offline RL methods are not suitable for offline-to-online fine-tuning in high-dimensional domains due to issues with distribution shifts, off-dynamics data, and non-stationary rewards. We propose an on-policy model-based method that can efficiently reuse prior data through model-based value expansion and policy regularization, while preventing model exploitation by controlling epistemic uncertainty. We find that our approach successfully solves tasks from the MetaWorld benchmark, as well as the Franka Kitchen robot manipulation environment completely from images. To the best of our knowledge, MOTO is the first method to solve this environment from pixels.
* This is an updated version of a manuscript that originally appeared at CoRL 2023. The project website is here https://sites.google.com/view/mo2o
Diffusion Model Alignment Using Direct Preference Optimization
Nov 21, 2023Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback (RLHF) methods to make them better aligned with users' preferences. In contrast to LLMs, human preference learning has not been widely explored in text-to-image diffusion models; the best existing approach is to fine-tune a pretrained model using carefully curated high quality images and captions to improve visual appeal and text alignment. We propose Diffusion-DPO, a method to align diffusion models to human preferences by directly optimizing on human comparison data. Diffusion-DPO is adapted from the recently developed Direct Preference Optimization (DPO), a simpler alternative to RLHF which directly optimizes a policy that best satisfies human preferences under a classification objective. We re-formulate DPO to account for a diffusion model notion of likelihood, utilizing the evidence lower bound to derive a differentiable objective. Using the Pick-a-Pic dataset of 851K crowdsourced pairwise preferences, we fine-tune the base model of the state-of-the-art Stable Diffusion XL (SDXL)-1.0 model with Diffusion-DPO. Our fine-tuned base model significantly outperforms both base SDXL-1.0 and the larger SDXL-1.0 model consisting of an additional refinement model in human evaluation, improving visual appeal and prompt alignment. We also develop a variant that uses AI feedback and has comparable performance to training on human preferences, opening the door for scaling of diffusion model alignment methods.
Contrastive Preference Learning: Learning from Human Feedback without RL
Oct 24, 2023Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for aligning models with human intent. Typically RLHF algorithms operate in two phases: first, use human preferences to learn a reward function and second, align the model by optimizing the learned reward via reinforcement learning (RL). This paradigm assumes that human preferences are distributed according to reward, but recent work suggests that they instead follow the regret under the user's optimal policy. Thus, learning a reward function from feedback is not only based on a flawed assumption of human preference, but also leads to unwieldy optimization challenges that stem from policy gradients or bootstrapping in the RL phase. Because of these optimization challenges, contemporary RLHF methods restrict themselves to contextual bandit settings (e.g., as in large language models) or limit observation dimensionality (e.g., state-based robotics). We overcome these limitations by introducing a new family of algorithms for optimizing behavior from human feedback using the regret-based model of human preferences. Using the principle of maximum entropy, we derive Contrastive Preference Learning (CPL), an algorithm for learning optimal policies from preferences without learning reward functions, circumventing the need for RL. CPL is fully off-policy, uses only a simple contrastive objective, and can be applied to arbitrary MDPs. This enables CPL to elegantly scale to high-dimensional and sequential RLHF problems while being simpler than prior methods.
An Emulator for Fine-Tuning Large Language Models using Small Language Models
Oct 19, 2023
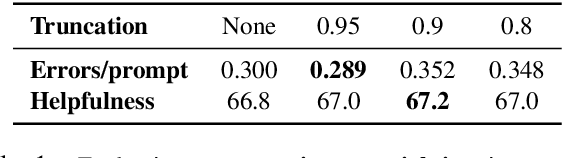
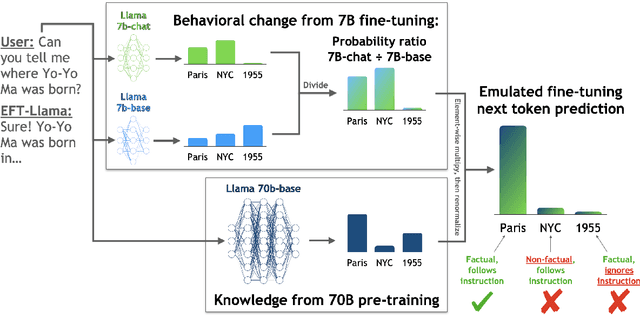
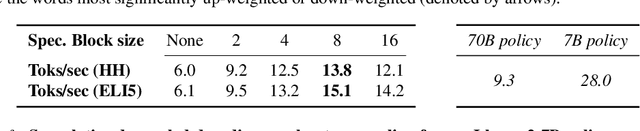
Widely used language models (LMs) are typically built by scaling up a two-stage training pipeline: a pre-training stage that uses a very large, diverse dataset of text and a fine-tuning (sometimes, 'alignment') stage that uses targeted examples or other specifications of desired behaviors. While it has been hypothesized that knowledge and skills come from pre-training, and fine-tuning mostly filters this knowledge and skillset, this intuition has not been extensively tested. To aid in doing so, we introduce a novel technique for decoupling the knowledge and skills gained in these two stages, enabling a direct answer to the question, "What would happen if we combined the knowledge learned by a large model during pre-training with the knowledge learned by a small model during fine-tuning (or vice versa)?" Using an RL-based framework derived from recent developments in learning from human preferences, we introduce emulated fine-tuning (EFT), a principled and practical method for sampling from a distribution that approximates (or 'emulates') the result of pre-training and fine-tuning at different scales. Our experiments with EFT show that scaling up fine-tuning tends to improve helpfulness, while scaling up pre-training tends to improve factuality. Beyond decoupling scale, we show that EFT enables test-time adjustment of competing behavioral traits like helpfulness and harmlessness without additional training. Finally, a special case of emulated fine-tuning, which we call LM up-scaling, avoids resource-intensive fine-tuning of large pre-trained models by ensembling them with small fine-tuned models, essentially emulating the result of fine-tuning the large pre-trained model. Up-scaling consistently improves helpfulness and factuality of instruction-following models in the Llama, Llama-2, and Falcon families, without additional hyperparameters or training.