 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKanishk Gandhi
Self-Supervised Alignment with Mutual Information: Learning to Follow Principles without Preference Labels
Apr 22, 2024
When prompting a language model (LM), users frequently expect the model to adhere to a set of behavioral principles across diverse tasks, such as producing insightful content while avoiding harmful or biased language. Instilling such principles into a model can be resource-intensive and technically challenging, generally requiring human preference labels or examples. We introduce SAMI, a method for teaching a pretrained LM to follow behavioral principles that does not require any preference labels or demonstrations. SAMI is an iterative algorithm that finetunes a pretrained LM to increase the conditional mutual information between constitutions and self-generated responses given queries from a datasest. On single-turn dialogue and summarization, a SAMI-trained mistral-7b outperforms the initial pretrained model, with win rates between 66% and 77%. Strikingly, it also surpasses an instruction-finetuned baseline (mistral-7b-instruct) with win rates between 55% and 57% on single-turn dialogue. SAMI requires a "principle writer" model; to avoid dependence on stronger models, we further evaluate aligning a strong pretrained model (mixtral-8x7b) using constitutions written by a weak instruction-finetuned model (mistral-7b-instruct). The SAMI-trained mixtral-8x7b outperforms both the initial model and the instruction-finetuned model, achieving a 65% win rate on summarization. Our results indicate that a pretrained LM can learn to follow constitutions without using preference labels, demonstrations, or human oversight.
Procedural Dilemma Generation for Evaluating Moral Reasoning in Humans and Language Models
Apr 17, 2024As AI systems like language models are increasingly integrated into decision-making processes affecting people's lives, it's critical to ensure that these systems have sound moral reasoning. To test whether they do, we need to develop systematic evaluations. We provide a framework that uses a language model to translate causal graphs that capture key aspects of moral dilemmas into prompt templates. With this framework, we procedurally generated a large and diverse set of moral dilemmas -- the OffTheRails benchmark -- consisting of 50 scenarios and 400 unique test items. We collected moral permissibility and intention judgments from human participants for a subset of our items and compared these judgments to those from two language models (GPT-4 and Claude-2) across eight conditions. We find that moral dilemmas in which the harm is a necessary means (as compared to a side effect) resulted in lower permissibility and higher intention ratings for both participants and language models. The same pattern was observed for evitable versus inevitable harmful outcomes. However, there was no clear effect of whether the harm resulted from an agent's action versus from having omitted to act. We discuss limitations of our prompt generation pipeline and opportunities for improving scenarios to increase the strength of experimental effects.
Stream of Search (SoS): Learning to Search in Language
Apr 01, 2024Language models are rarely shown fruitful mistakes while training. They then struggle to look beyond the next token, suffering from a snowballing of errors and struggling to predict the consequence of their actions several steps ahead. In this paper, we show how language models can be taught to search by representing the process of search in language, as a flattened string -- a stream of search (SoS). We propose a unified language for search that captures an array of different symbolic search strategies. We demonstrate our approach using the simple yet difficult game of Countdown, where the goal is to combine input numbers with arithmetic operations to reach a target number. We pretrain a transformer-based language model from scratch on a dataset of streams of search generated by heuristic solvers. We find that SoS pretraining increases search accuracy by 25% over models trained to predict only the optimal search trajectory. We further finetune this model with two policy improvement methods: Advantage-Induced Policy Alignment (APA) and Self-Taught Reasoner (STaR). The finetuned SoS models solve 36% of previously unsolved problems, including problems that cannot be solved by any of the heuristic solvers. Our results indicate that language models can learn to solve problems via search, self-improve to flexibly use different search strategies, and potentially discover new ones.
Social Contract AI: Aligning AI Assistants with Implicit Group Norms
Oct 26, 2023We explore the idea of aligning an AI assistant by inverting a model of users' (unknown) preferences from observed interactions. To validate our proposal, we run proof-of-concept simulations in the economic ultimatum game, formalizing user preferences as policies that guide the actions of simulated players. We find that the AI assistant accurately aligns its behavior to match standard policies from the economic literature (e.g., selfish, altruistic). However, the assistant's learned policies lack robustness and exhibit limited generalization in an out-of-distribution setting when confronted with a currency (e.g., grams of medicine) that was not included in the assistant's training distribution. Additionally, we find that when there is inconsistency in the relationship between language use and an unknown policy (e.g., an altruistic policy combined with rude language), the assistant's learning of the policy is slowed. Overall, our preliminary results suggest that developing simulation frameworks in which AI assistants need to infer preferences from diverse users can provide a valuable approach for studying practical alignment questions.
Exciton-Polariton Condensates: A Fourier Neural Operator Approach
Sep 27, 2023
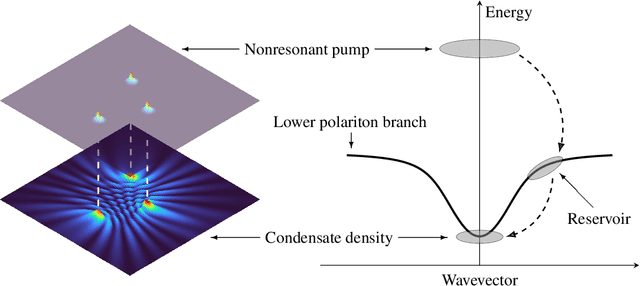
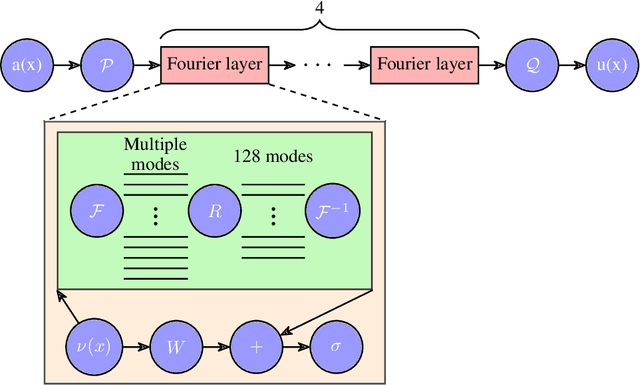
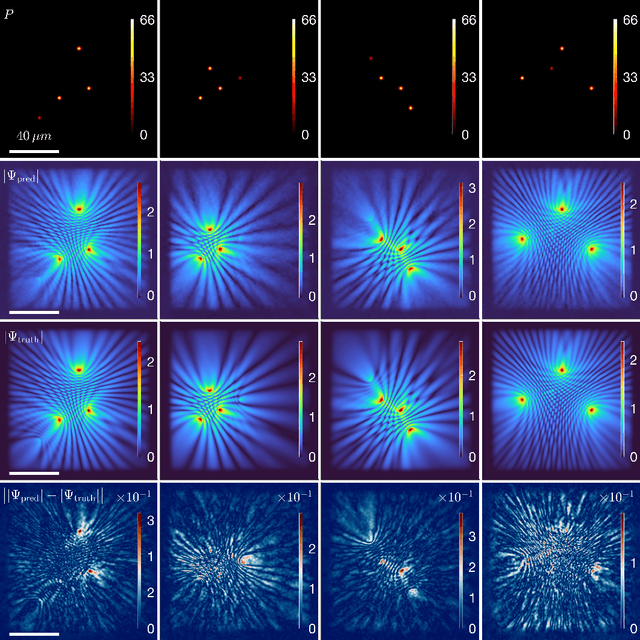
Advancements in semiconductor fabrication over the past decade have catalyzed extensive research into all-optical devices driven by exciton-polariton condensates. Preliminary validations of such devices, including transistors, have shown encouraging results even under ambient conditions. A significant challenge still remains for large scale application however: the lack of a robust solver that can be used to simulate complex nonlinear systems which require an extended period of time to stabilize. Addressing this need, we propose the application of a machine-learning-based Fourier Neural Operator approach to find the solution to the Gross-Pitaevskii equations coupled with extra exciton rate equations. This work marks the first direct application of Neural Operators to an exciton-polariton condensate system. Our findings show that the proposed method can predict final-state solutions to a high degree of accuracy almost 1000 times faster than CUDA-based GPU solvers. Moreover, this paves the way for potential all-optical chip design workflows by integrating experimental data.
Understanding Social Reasoning in Language Models with Language Models
Jun 21, 2023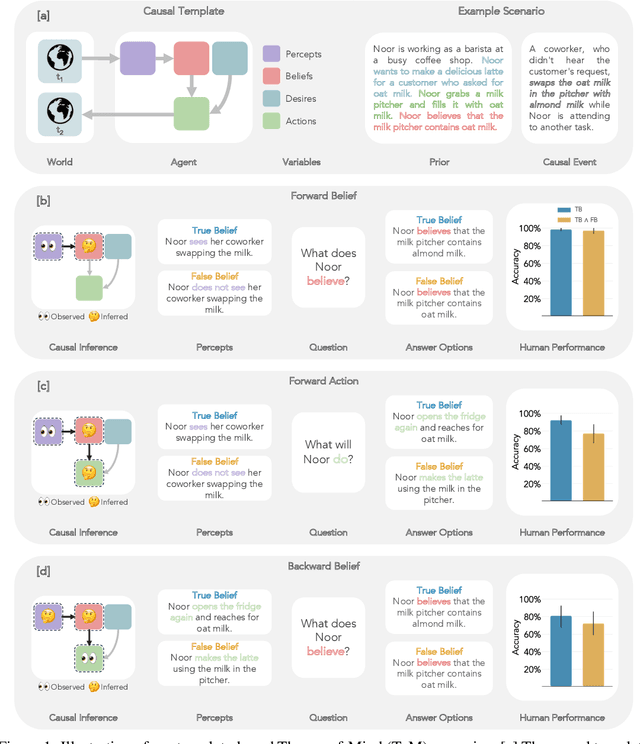

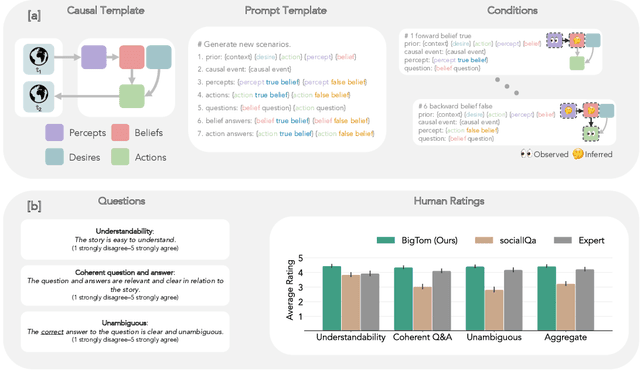
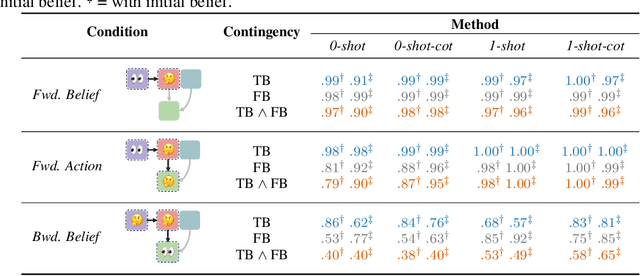
As Large Language Models (LLMs) become increasingly integrated into our everyday lives, understanding their ability to comprehend human mental states becomes critical for ensuring effective interactions. However, despite the recent attempts to assess the Theory-of-Mind (ToM) reasoning capabilities of LLMs, the degree to which these models can align with human ToM remains a nuanced topic of exploration. This is primarily due to two distinct challenges: (1) the presence of inconsistent results from previous evaluations, and (2) concerns surrounding the validity of existing evaluation methodologies. To address these challenges, we present a novel framework for procedurally generating evaluations with LLMs by populating causal templates. Using our framework, we create a new social reasoning benchmark (BigToM) for LLMs which consists of 25 controls and 5,000 model-written evaluations. We find that human participants rate the quality of our benchmark higher than previous crowd-sourced evaluations and comparable to expert-written evaluations. Using BigToM, we evaluate the social reasoning capabilities of a variety of LLMs and compare model performances with human performance. Our results suggest that GPT4 has ToM capabilities that mirror human inference patterns, though less reliable, while other LLMs struggle.
Certified Reasoning with Language Models
Jun 06, 2023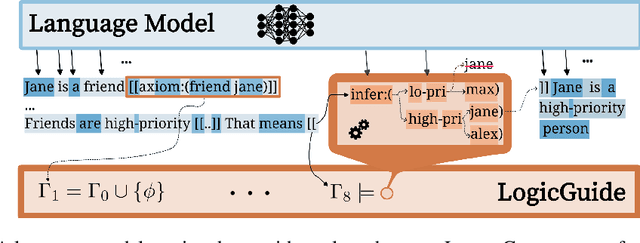

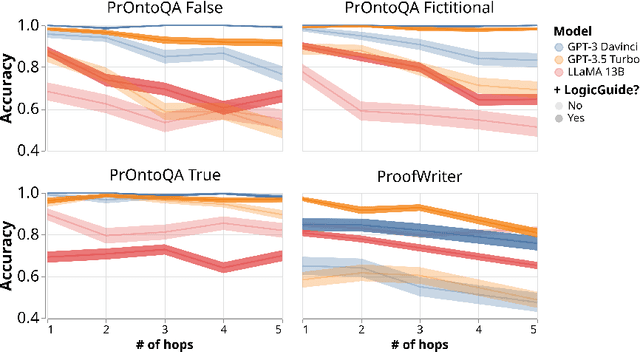

Language models often achieve higher accuracy when reasoning step-by-step in complex tasks. However, their reasoning can be unsound, inconsistent, or rely on undesirable prior assumptions. To tackle these issues, we introduce a class of tools for language models called guides that use state and incremental constraints to guide generation. A guide can be invoked by the model to constrain its own generation to a set of valid statements given by the tool. In turn, the model's choices can change the guide's state. We show how a general system for logical reasoning can be used as a guide, which we call LogicGuide. Given a reasoning problem in natural language, a model can formalize its assumptions for LogicGuide and then guarantee that its reasoning steps are sound. In experiments with the PrOntoQA and ProofWriter reasoning datasets, LogicGuide significantly improves the performance of GPT-3, GPT-3.5 Turbo and LLaMA (accuracy gains up to 35%). LogicGuide also drastically reduces content effects: the interference of prior and current assumptions that both humans and language models have been shown to suffer from. Finally, we explore bootstrapping LLaMA 13B from its own reasoning and find that LogicGuide is critical: by training only on certified self-generated reasoning, LLaMA can self-improve, avoiding learning from its own hallucinations.
Strategic Reasoning with Language Models
May 30, 2023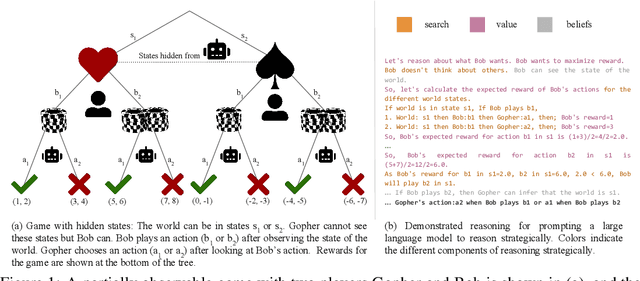

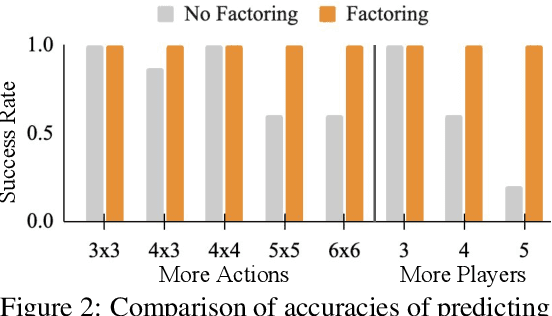

Strategic reasoning enables agents to cooperate, communicate, and compete with other agents in diverse situations. Existing approaches to solving strategic games rely on extensive training, yielding strategies that do not generalize to new scenarios or games without retraining. Large Language Models (LLMs), with their ability to comprehend and generate complex, context-rich language, could prove powerful as tools for strategic gameplay. This paper introduces an approach that uses pretrained LLMs with few-shot chain-of-thought examples to enable strategic reasoning for AI agents. Our approach uses systematically generated demonstrations of reasoning about states, values, and beliefs to prompt the model. Using extensive variations of simple matrix games, we show that strategies that are derived based on systematically generated prompts generalize almost perfectly to new game structures, alternate objectives, and hidden information. Additionally, we demonstrate our approach can lead to human-like negotiation strategies in realistic scenarios without any extra training or fine-tuning. Our results highlight the ability of LLMs, guided by systematic reasoning demonstrations, to adapt and excel in diverse strategic scenarios.
Eliciting Compatible Demonstrations for Multi-Human Imitation Learning
Oct 14, 2022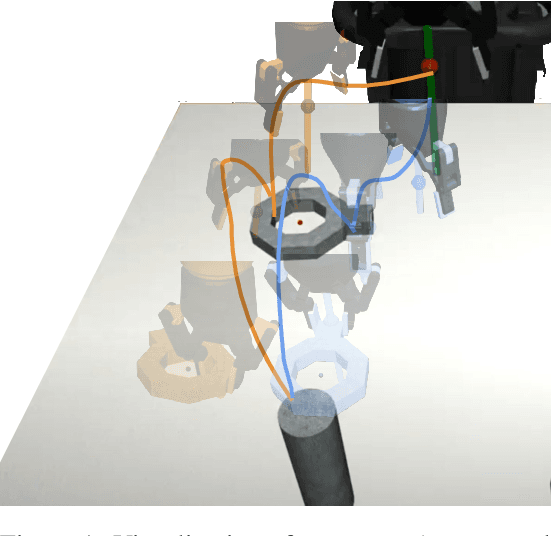
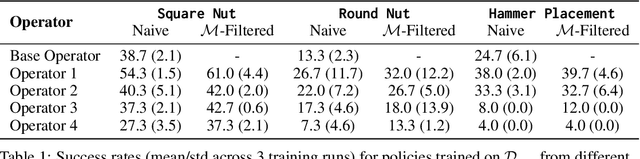
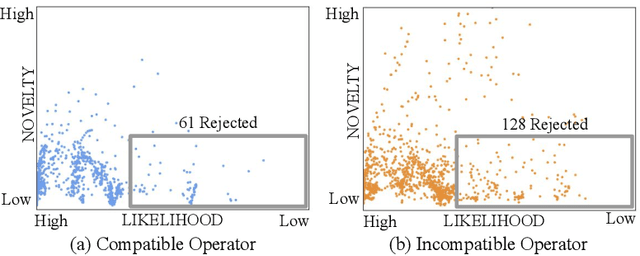

Imitation learning from human-provided demonstrations is a strong approach for learning policies for robot manipulation. While the ideal dataset for imitation learning is homogenous and low-variance -- reflecting a single, optimal method for performing a task -- natural human behavior has a great deal of heterogeneity, with several optimal ways to demonstrate a task. This multimodality is inconsequential to human users, with task variations manifesting as subconscious choices; for example, reaching down, then across to grasp an object, versus reaching across, then down. Yet, this mismatch presents a problem for interactive imitation learning, where sequences of users improve on a policy by iteratively collecting new, possibly conflicting demonstrations. To combat this problem of demonstrator incompatibility, this work designs an approach for 1) measuring the compatibility of a new demonstration given a base policy, and 2) actively eliciting more compatible demonstrations from new users. Across two simulation tasks requiring long-horizon, dexterous manipulation and a real-world "food plating" task with a Franka Emika Panda arm, we show that we can both identify incompatible demonstrations via post-hoc filtering, and apply our compatibility measure to actively elicit compatible demonstrations from new users, leading to improved task success rates across simulated and real environments.
Baby Intuitions Benchmark (BIB): Discerning the goals, preferences, and actions of others
Feb 23, 2021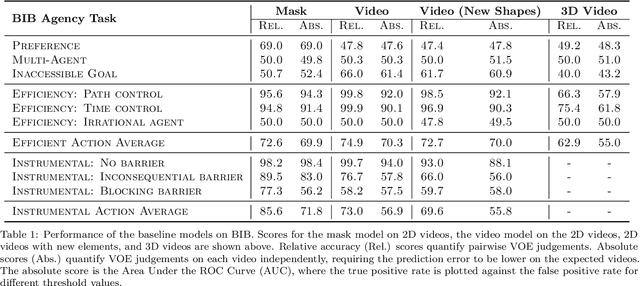
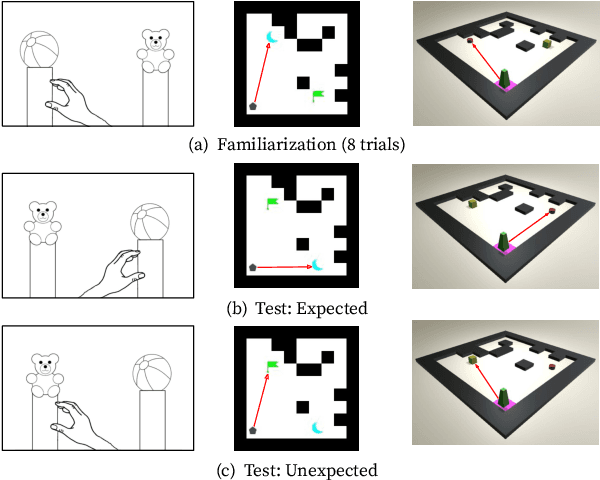


To achieve human-like common sense about everyday life, machine learning systems must understand and reason about the goals, preferences, and actions of others. Human infants intuitively achieve such common sense by making inferences about the underlying causes of other agents' actions. Directly informed by research on infant cognition, our benchmark BIB challenges machines to achieve generalizable, common-sense reasoning about other agents like human infants do. As in studies on infant cognition, moreover, we use a violation of expectation paradigm in which machines must predict the plausibility of an agent's behavior given a video sequence, making this benchmark appropriate for direct validation with human infants in future studies. We show that recently proposed, deep-learning-based agency reasoning models fail to show infant-like reasoning, leaving BIB an open challenge.