 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrenden M. Lake
Compositional learning of functions in humans and machines
Mar 18, 2024
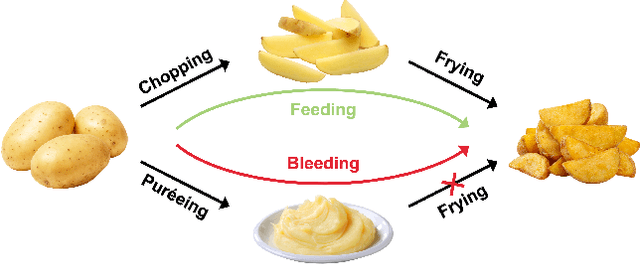
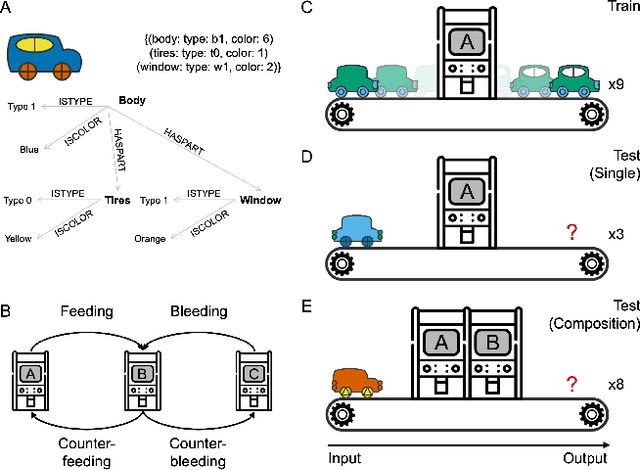
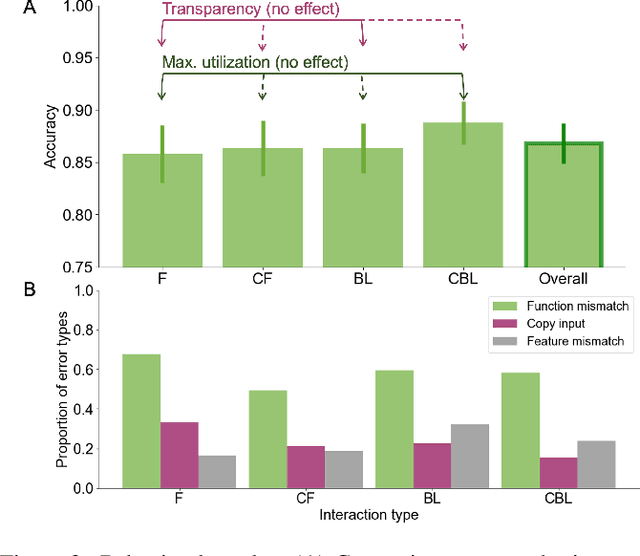
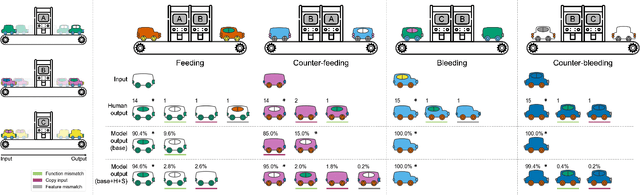
The ability to learn and compose functions is foundational to efficient learning and reasoning in humans, enabling flexible generalizations such as creating new dishes from known cooking processes. Beyond sequential chaining of functions, existing linguistics literature indicates that humans can grasp more complex compositions with interacting functions, where output production depends on context changes induced by different function orderings. Extending the investigation into the visual domain, we developed a function learning paradigm to explore the capacity of humans and neural network models in learning and reasoning with compositional functions under varied interaction conditions. Following brief training on individual functions, human participants were assessed on composing two learned functions, in ways covering four main interaction types, including instances in which the application of the first function creates or removes the context for applying the second function. Our findings indicate that humans can make zero-shot generalizations on novel visual function compositions across interaction conditions, demonstrating sensitivity to contextual changes. A comparison with a neural network model on the same task reveals that, through the meta-learning for compositionality (MLC) approach, a standard sequence-to-sequence Transformer can mimic human generalization patterns in composing functions.
A systematic investigation of learnability from single child linguistic input
Feb 12, 2024Language models (LMs) have demonstrated remarkable proficiency in generating linguistically coherent text, sparking discussions about their relevance to understanding human language learnability. However, a significant gap exists between the training data for these models and the linguistic input a child receives. LMs are typically trained on data that is orders of magnitude larger and fundamentally different from child-directed speech (Warstadt and Bowman, 2022; Warstadt et al., 2023; Frank, 2023a). Addressing this discrepancy, our research focuses on training LMs on subsets of a single child's linguistic input. Previously, Wang, Vong, Kim, and Lake (2023) found that LMs trained in this setting can form syntactic and semantic word clusters and develop sensitivity to certain linguistic phenomena, but they only considered LSTMs and simpler neural networks trained from just one single-child dataset. Here, to examine the robustness of learnability from single-child input, we systematically train six different model architectures on five datasets (3 single-child and 2 baselines). We find that the models trained on single-child datasets showed consistent results that matched with previous work, underscoring the robustness of forming meaningful syntactic and semantic representations from a subset of a child's linguistic input.
Self-supervised learning of video representations from a child's perspective
Feb 01, 2024Children learn powerful internal models of the world around them from a few years of egocentric visual experience. Can such internal models be learned from a child's visual experience with highly generic learning algorithms or do they require strong inductive biases? Recent advances in collecting large-scale, longitudinal, developmentally realistic video datasets and generic self-supervised learning (SSL) algorithms are allowing us to begin to tackle this nature vs. nurture question. However, existing work typically focuses on image-based SSL algorithms and visual capabilities that can be learned from static images (e.g. object recognition), thus ignoring temporal aspects of the world. To close this gap, here we train self-supervised video models on longitudinal, egocentric headcam recordings collected from a child over a two year period in their early development (6-31 months). The resulting models are highly effective at facilitating the learning of action concepts from a small number of labeled examples; they have favorable data size scaling properties; and they display emergent video interpolation capabilities. Video models also learn more robust object representations than image-based models trained with the exact same data. These results suggest that important temporal aspects of a child's internal model of the world may be learnable from their visual experience using highly generic learning algorithms and without strong inductive biases.
Deep Neural Networks Can Learn Generalizable Same-Different Visual Relations
Oct 14, 2023
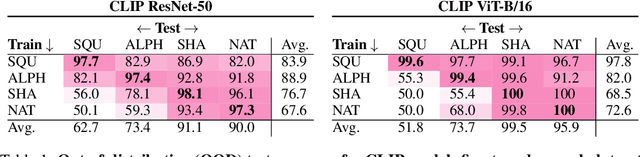
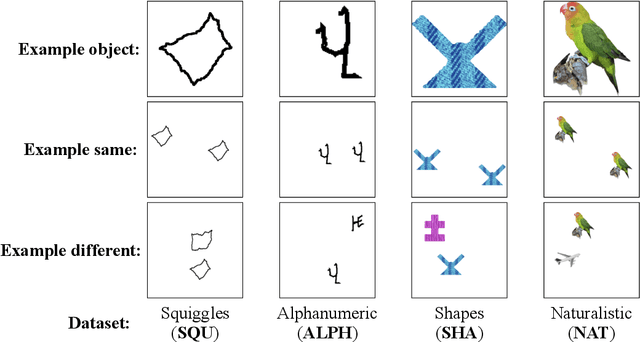
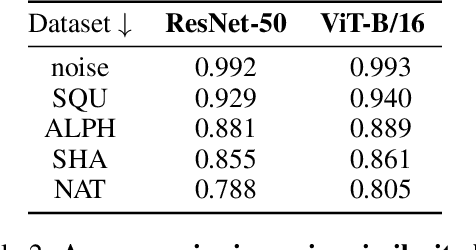
Although deep neural networks can achieve human-level performance on many object recognition benchmarks, prior work suggests that these same models fail to learn simple abstract relations, such as determining whether two objects are the same or different. Much of this prior work focuses on training convolutional neural networks to classify images of two same or two different abstract shapes, testing generalization on within-distribution stimuli. In this article, we comprehensively study whether deep neural networks can acquire and generalize same-different relations both within and out-of-distribution using a variety of architectures, forms of pretraining, and fine-tuning datasets. We find that certain pretrained transformers can learn a same-different relation that generalizes with near perfect accuracy to out-of-distribution stimuli. Furthermore, we find that fine-tuning on abstract shapes that lack texture or color provides the strongest out-of-distribution generalization. Our results suggest that, with the right approach, deep neural networks can learn generalizable same-different visual relations.
Compositional diversity in visual concept learning
May 30, 2023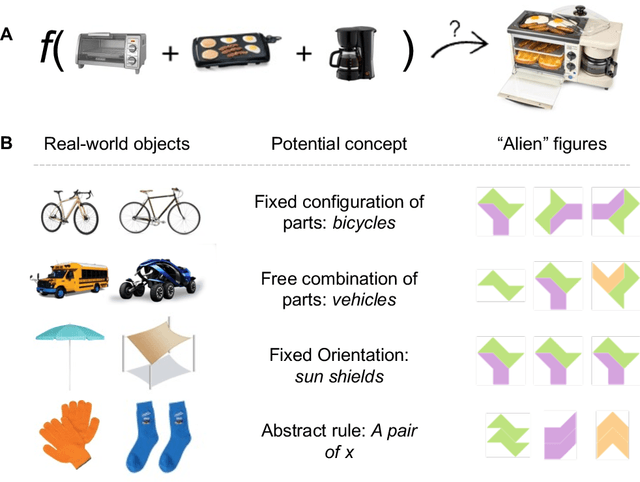

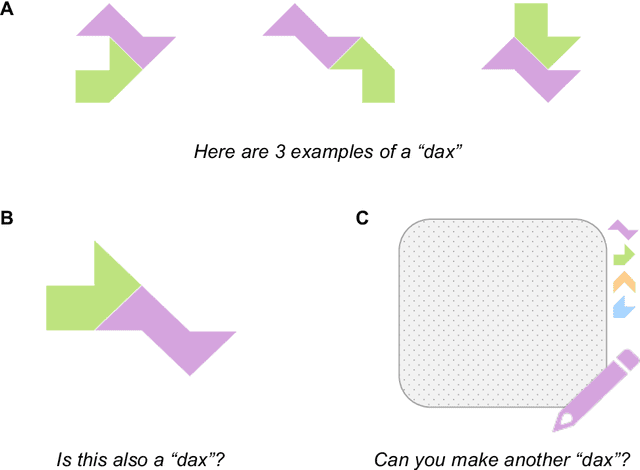

Humans leverage compositionality to efficiently learn new concepts, understanding how familiar parts can combine together to form novel objects. In contrast, popular computer vision models struggle to make the same types of inferences, requiring more data and generalizing less flexibly than people do. Here, we study these distinctively human abilities across a range of different types of visual composition, examining how people classify and generate ``alien figures'' with rich relational structure. We also develop a Bayesian program induction model which searches for the best programs for generating the candidate visual figures, utilizing a large program space containing different compositional mechanisms and abstractions. In few shot classification tasks, we find that people and the program induction model can make a range of meaningful compositional generalizations, with the model providing a strong account of the experimental data as well as interpretable parameters that reveal human assumptions about the factors invariant to category membership (here, to rotation and changing part attachment). In few shot generation tasks, both people and the models are able to construct compelling novel examples, with people behaving in additional structured ways beyond the model capabilities, e.g. making choices that complete a set or reconfiguring existing parts in highly novel ways. To capture these additional behavioral patterns, we develop an alternative model based on neuro-symbolic program induction: this model also composes new concepts from existing parts yet, distinctively, it utilizes neural network modules to successfully capture residual statistical structure. Together, our behavioral and computational findings show how people and models can produce a rich variety of compositional behavior when classifying and generating visual objects.
What can generic neural networks learn from a child's visual experience?
May 24, 2023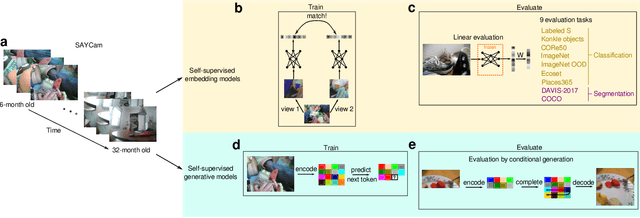
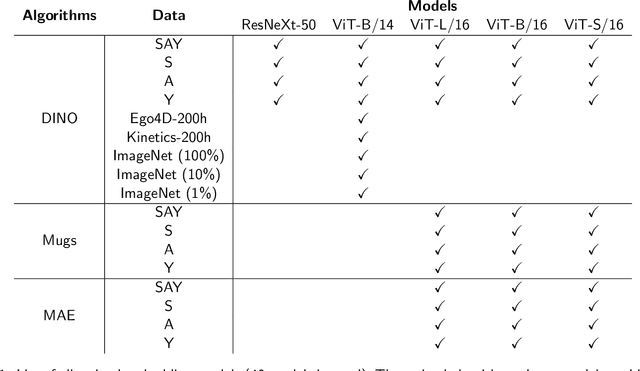
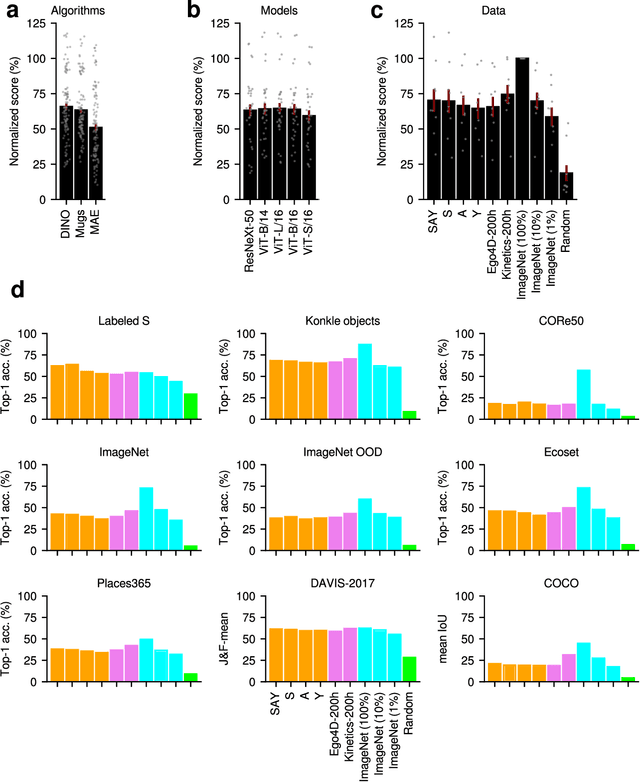
Young children develop sophisticated internal models of the world based on their egocentric visual experience. How much of this is driven by innate constraints and how much is driven by their experience? To investigate these questions, we train state-of-the-art neural networks on a realistic proxy of a child's visual experience without any explicit supervision or domain-specific inductive biases. Specifically, we train both embedding models and generative models on 200 hours of headcam video from a single child collected over two years. We train a total of 72 different models, exploring a range of model architectures and self-supervised learning algorithms, and comprehensively evaluate their performance in downstream tasks. The best embedding models perform at 70% of a highly performant ImageNet-trained model on average. They also learn broad semantic categories without any labeled examples and learn to localize semantic categories in an image without any location supervision. However, these models are less object-centric and more background-sensitive than comparable ImageNet-trained models. Generative models trained with the same data successfully extrapolate simple properties of partially masked objects, such as their texture, color, orientation, and rough outline, but struggle with finer object details. We replicate our experiments with two other children and find very similar results. Broadly useful high-level visual representations are thus robustly learnable from a representative sample of a child's visual experience without strong inductive biases.
A Developmentally-Inspired Examination of Shape versus Texture Bias in Machines
Feb 16, 2022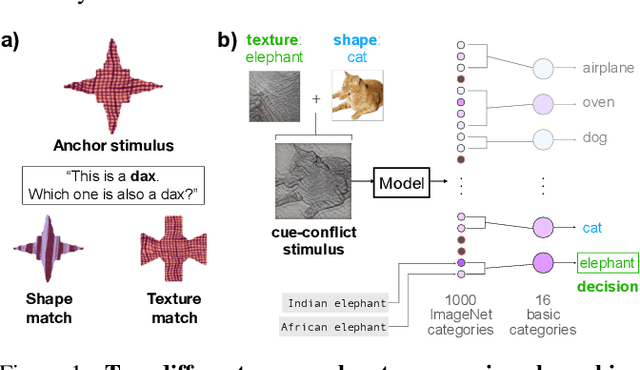
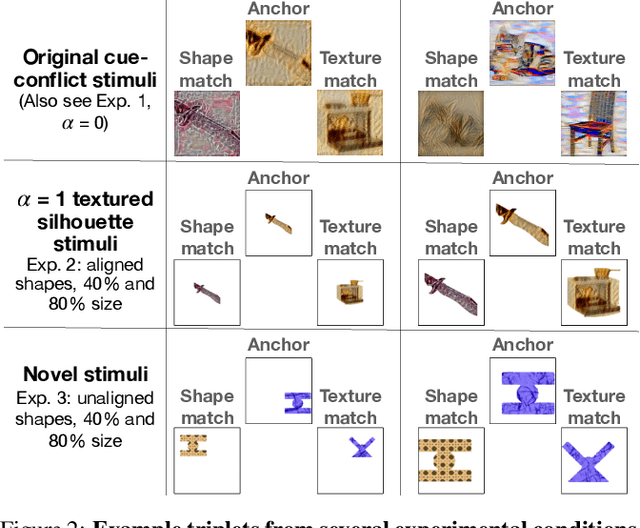
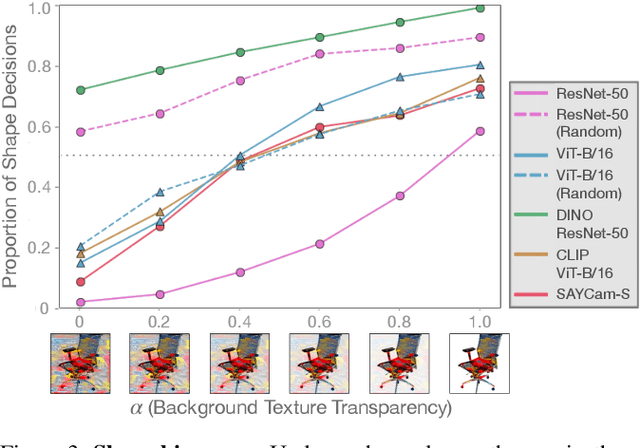
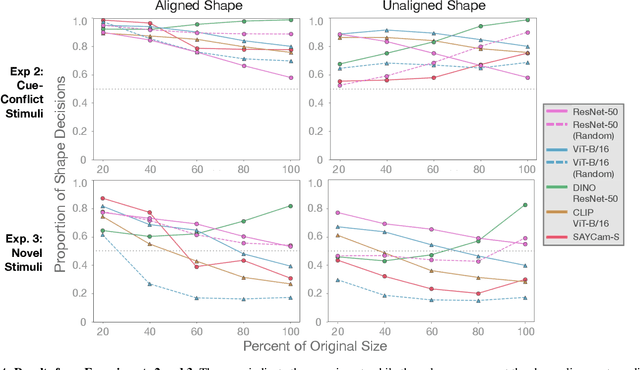
Early in development, children learn to extend novel category labels to objects with the same shape, a phenomenon known as the shape bias. Inspired by these findings, Geirhos et al. (2019) examined whether deep neural networks show a shape or texture bias by constructing images with conflicting shape and texture cues. They found that convolutional neural networks strongly preferred to classify familiar objects based on texture as opposed to shape, suggesting a texture bias. However, there are a number of differences between how the networks were tested in this study versus how children are typically tested. In this work, we re-examine the inductive biases of neural networks by adapting the stimuli and procedure from Geirhos et al. (2019) to more closely follow the developmental paradigm and test on a wide range of pre-trained neural networks. Across three experiments, we find that deep neural networks exhibit a preference for shape rather than texture when tested under conditions that more closely replicate the developmental procedure.
Improving Coherence and Consistency in Neural Sequence Models with Dual-System, Neuro-Symbolic Reasoning
Jul 06, 2021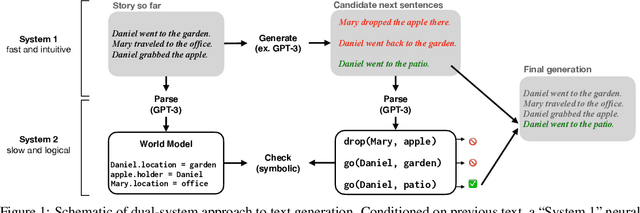


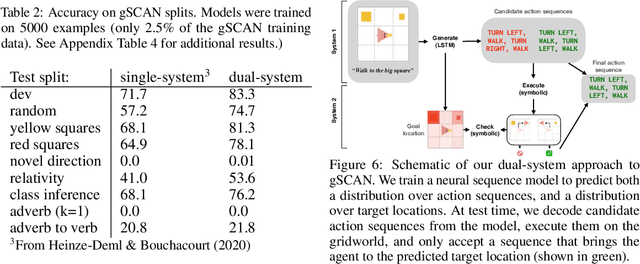
Human reasoning can often be understood as an interplay between two systems: the intuitive and associative ("System 1") and the deliberative and logical ("System 2"). Neural sequence models -- which have been increasingly successful at performing complex, structured tasks -- exhibit the advantages and failure modes of System 1: they are fast and learn patterns from data, but are often inconsistent and incoherent. In this work, we seek a lightweight, training-free means of improving existing System 1-like sequence models by adding System 2-inspired logical reasoning. We explore several variations on this theme in which candidate generations from a neural sequence model are examined for logical consistency by a symbolic reasoning module, which can either accept or reject the generations. Our approach uses neural inference to mediate between the neural System 1 and the logical System 2. Results in robust story generation and grounded instruction-following show that this approach can increase the coherence and accuracy of neurally-based generations.
Flexible Compositional Learning of Structured Visual Concepts
May 20, 2021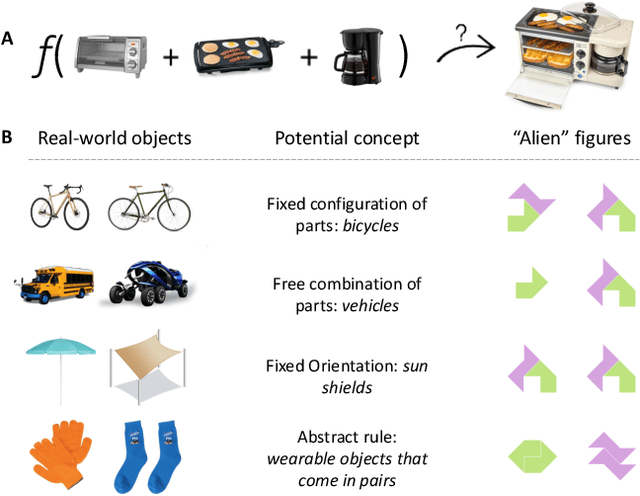

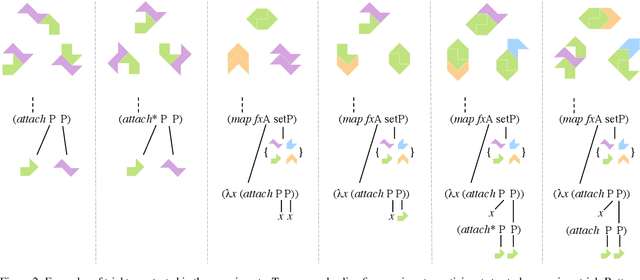

Humans are highly efficient learners, with the ability to grasp the meaning of a new concept from just a few examples. Unlike popular computer vision systems, humans can flexibly leverage the compositional structure of the visual world, understanding new concepts as combinations of existing concepts. In the current paper, we study how people learn different types of visual compositions, using abstract visual forms with rich relational structure. We find that people can make meaningful compositional generalizations from just a few examples in a variety of scenarios, and we develop a Bayesian program induction model that provides a close fit to the behavioral data. Unlike past work examining special cases of compositionality, our work shows how a single computational approach can account for many distinct types of compositional generalization.
Fast and flexible: Human program induction in abstract reasoning tasks
Mar 10, 2021

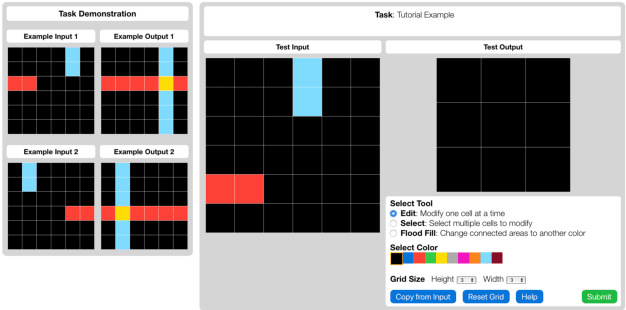
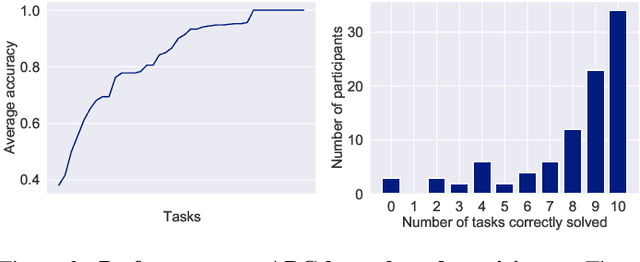
The Abstraction and Reasoning Corpus (ARC) is a challenging program induction dataset that was recently proposed by Chollet (2019). Here, we report the first set of results collected from a behavioral study of humans solving a subset of tasks from ARC (40 out of 1000). Although this subset of tasks contains considerable variation, our results showed that humans were able to infer the underlying program and generate the correct test output for a novel test input example, with an average of 80% of tasks solved per participant, and with 65% of tasks being solved by more than 80% of participants. Additionally, we find interesting patterns of behavioral consistency and variability within the action sequences during the generation process, the natural language descriptions to describe the transformations for each task, and the errors people made. Our findings suggest that people can quickly and reliably determine the relevant features and properties of a task to compose a correct solution. Future modeling work could incorporate these findings, potentially by connecting the natural language descriptions we collected here to the underlying semantics of ARC.