 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTodd M. Gureckis
Fast and flexible: Human program induction in abstract reasoning tasks
Mar 10, 2021


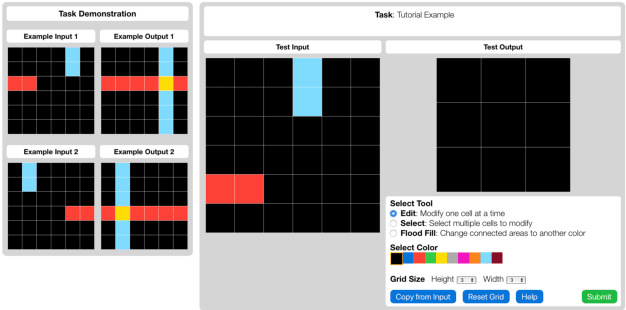
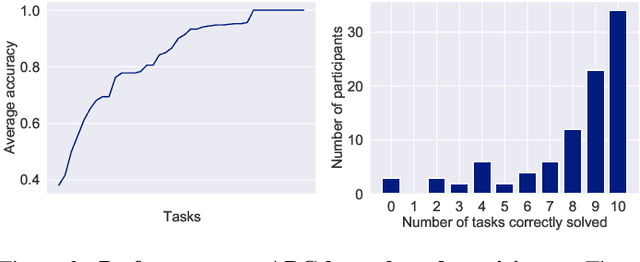
The Abstraction and Reasoning Corpus (ARC) is a challenging program induction dataset that was recently proposed by Chollet (2019). Here, we report the first set of results collected from a behavioral study of humans solving a subset of tasks from ARC (40 out of 1000). Although this subset of tasks contains considerable variation, our results showed that humans were able to infer the underlying program and generate the correct test output for a novel test input example, with an average of 80% of tasks solved per participant, and with 65% of tasks being solved by more than 80% of participants. Additionally, we find interesting patterns of behavioral consistency and variability within the action sequences during the generation process, the natural language descriptions to describe the transformations for each task, and the errors people made. Our findings suggest that people can quickly and reliably determine the relevant features and properties of a task to compose a correct solution. Future modeling work could incorporate these findings, potentially by connecting the natural language descriptions we collected here to the underlying semantics of ARC.
Question Asking as Program Generation
Nov 16, 2017



A hallmark of human intelligence is the ability to ask rich, creative, and revealing questions. Here we introduce a cognitive model capable of constructing human-like questions. Our approach treats questions as formal programs that, when executed on the state of the world, output an answer. The model specifies a probability distribution over a complex, compositional space of programs, favoring concise programs that help the agent learn in the current context. We evaluate our approach by modeling the types of open-ended questions generated by humans who were attempting to learn about an ambiguous situation in a game. We find that our model predicts what questions people will ask, and can creatively produce novel questions that were not present in the training set. In addition, we compare a number of model variants, finding that both question informativeness and complexity are important for producing human-like questions.
* Published in Advances in Neural Information Processing Systems (NIPS) 30, December 2017