 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenhang Cui
Aligning Modalities in Vision Large Language Models via Preference Fine-tuning
Feb 18, 2024
Instruction-following Vision Large Language Models (VLLMs) have achieved significant progress recently on a variety of tasks. These approaches merge strong pre-trained vision models and large language models (LLMs). Since these components are trained separately, the learned representations need to be aligned with joint training on additional image-language pairs. This procedure is not perfect and can cause the model to hallucinate - provide answers that do not accurately reflect the image, even when the core LLM is highly factual and the vision backbone has sufficiently complete representations. In this work, we frame the hallucination problem as an alignment issue, tackle it with preference tuning. Specifically, we propose POVID to generate feedback data with AI models. We use ground-truth instructions as the preferred response and a two-stage approach to generate dispreferred data. First, we prompt GPT-4V to inject plausible hallucinations into the correct answer. Second, we distort the image to trigger the inherent hallucination behavior of the VLLM. This is an automated approach, which does not rely on human data generation or require a perfect expert, which makes it easily scalable. Finally, both of these generation strategies are integrated into an RLHF pipeline via Direct Preference Optimization. In experiments across broad benchmarks, we show that we can not only reduce hallucinations, but improve model performance across standard benchmarks, outperforming prior approaches. Our data and code are available at https://github.com/YiyangZhou/POVID.
How Many Unicorns Are in This Image? A Safety Evaluation Benchmark for Vision LLMs
Nov 27, 2023This work focuses on the potential of Vision LLMs (VLLMs) in visual reasoning. Different from prior studies, we shift our focus from evaluating standard performance to introducing a comprehensive safety evaluation suite, covering both out-of-distribution (OOD) generalization and adversarial robustness. For the OOD evaluation, we present two novel VQA datasets, each with one variant, designed to test model performance under challenging conditions. In exploring adversarial robustness, we propose a straightforward attack strategy for misleading VLLMs to produce visual-unrelated responses. Moreover, we assess the efficacy of two jailbreaking strategies, targeting either the vision or language component of VLLMs. Our evaluation of 21 diverse models, ranging from open-source VLLMs to GPT-4V, yields interesting observations: 1) Current VLLMs struggle with OOD texts but not images, unless the visual information is limited; and 2) These VLLMs can be easily misled by deceiving vision encoders only, and their vision-language training often compromise safety protocols. We release this safety evaluation suite at https://github.com/UCSC-VLAA/vllm-safety-benchmark.
Holistic Analysis of Hallucination in GPT-4V(ision): Bias and Interference Challenges
Nov 07, 2023While GPT-4V(ision) impressively models both visual and textual information simultaneously, it's hallucination behavior has not been systematically assessed. To bridge this gap, we introduce a new benchmark, namely, the Bias and Interference Challenges in Visual Language Models (Bingo). This benchmark is designed to evaluate and shed light on the two common types of hallucinations in visual language models: bias and interference. Here, bias refers to the model's tendency to hallucinate certain types of responses, possibly due to imbalance in its training data. Interference pertains to scenarios where the judgment of GPT-4V(ision) can be disrupted due to how the text prompt is phrased or how the input image is presented. We identify a notable regional bias, whereby GPT-4V(ision) is better at interpreting Western images or images with English writing compared to images from other countries or containing text in other languages. Moreover, GPT-4V(ision) is vulnerable to leading questions and is often confused when interpreting multiple images together. Popular mitigation approaches, such as self-correction and chain-of-thought reasoning, are not effective in resolving these challenges. We also identified similar biases and interference vulnerabilities with LLaVA and Bard. Our results characterize the hallucination challenges in GPT-4V(ision) and state-of-the-art visual-language models, and highlight the need for new solutions. The Bingo benchmark is available at https://github.com/gzcch/Bingo.
Analyzing and Mitigating Object Hallucination in Large Vision-Language Models
Oct 01, 2023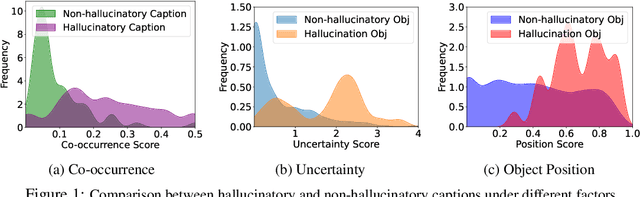
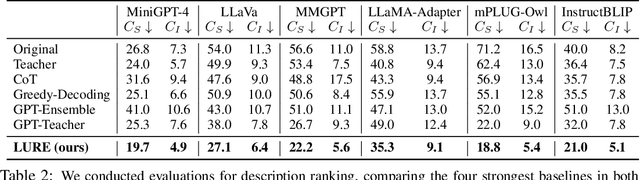
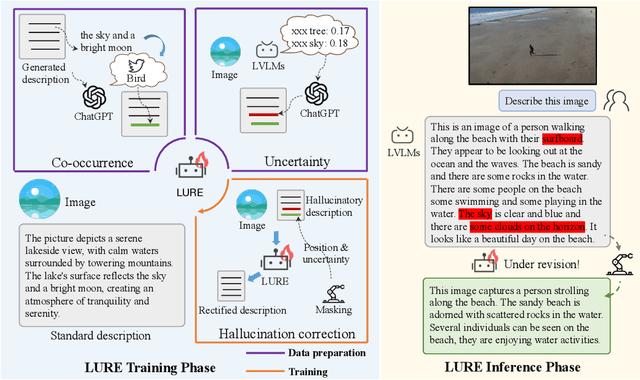
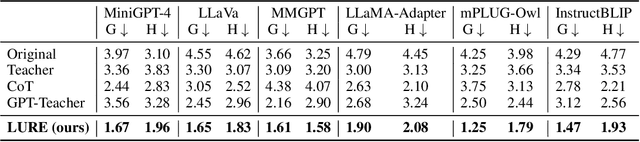
Large vision-language models (LVLMs) have shown remarkable abilities in understanding visual information with human languages. However, LVLMs still suffer from object hallucination, which is the problem of generating descriptions that include objects that do not actually exist in the images. This can negatively impact many vision-language tasks, such as visual summarization and reasoning. To address this issue, we propose a simple yet powerful algorithm, LVLM Hallucination Revisor (LURE), to post-hoc rectify object hallucination in LVLMs by reconstructing less hallucinatory descriptions. LURE is grounded in a rigorous statistical analysis of the key factors underlying object hallucination, including co-occurrence (the frequent appearance of certain objects alongside others in images), uncertainty (objects with higher uncertainty during LVLM decoding), and object position (hallucination often appears in the later part of the generated text). LURE can also be seamlessly integrated with any LVLMs. We evaluate LURE on six open-source LVLMs, achieving a 23% improvement in general object hallucination evaluation metrics over the previous best approach. In both GPT and human evaluations, LURE consistently ranks at the top. Our data and code are available at https://github.com/YiyangZhou/LURE.
A Novel Approach for Effective Multi-View Clustering with Information-Theoretic Perspective
Sep 25, 2023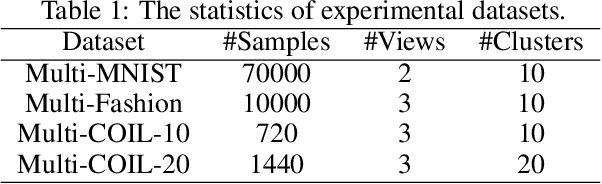
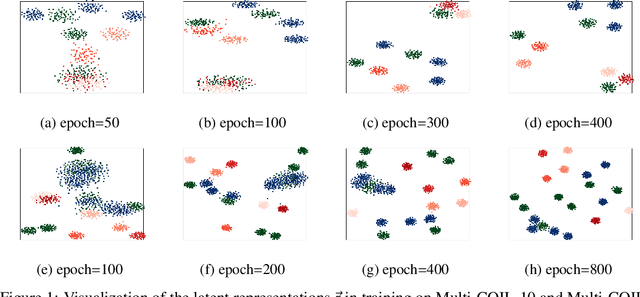
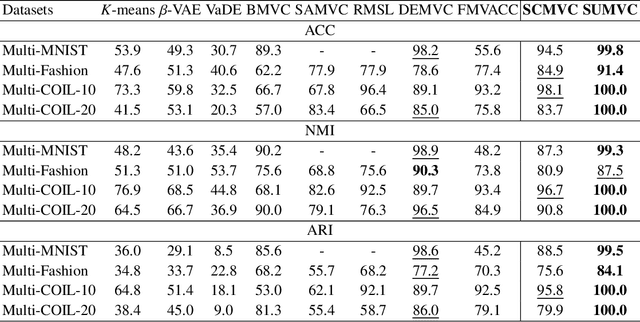

Multi-view clustering (MVC) is a popular technique for improving clustering performance using various data sources. However, existing methods primarily focus on acquiring consistent information while often neglecting the issue of redundancy across multiple views. This study presents a new approach called Sufficient Multi-View Clustering (SUMVC) that examines the multi-view clustering framework from an information-theoretic standpoint. Our proposed method consists of two parts. Firstly, we develop a simple and reliable multi-view clustering method SCMVC (simple consistent multi-view clustering) that employs variational analysis to generate consistent information. Secondly, we propose a sufficient representation lower bound to enhance consistent information and minimise unnecessary information among views. The proposed SUMVC method offers a promising solution to the problem of multi-view clustering and provides a new perspective for analyzing multi-view data. To verify the effectiveness of our model, we conducted a theoretical analysis based on the Bayes Error Rate, and experiments on multiple multi-view datasets demonstrate the superior performance of SUMVC.
Bright Channel Prior Attention for Multispectral Pedestrian Detection
May 22, 2023


Multispectral methods have gained considerable attention due to their promising performance across various fields. However, most existing methods cannot effectively utilize information from two modalities while optimizing time efficiency. These methods often prioritize accuracy or time efficiency, leaving room for improvement in their performance. To this end, we propose a new method bright channel prior attention for enhancing pedestrian detection in low-light conditions by integrating image enhancement and detection within a unified framework. The method uses the V-channel of the HSV image of the thermal image as an attention map to trigger the unsupervised auto-encoder for visible light images, which gradually emphasizes pedestrian features across layers. Moreover, we utilize unsupervised bright channel prior algorithms to address light compensation in low light images. The proposed method includes a self-attention enhancement module and a detection module, which work together to improve object detection. An initial illumination map is estimated using the BCP, guiding the learning of the self-attention map from the enhancement network to obtain more informative representation focused on pedestrians. The extensive experiments show effectiveness of the proposed method is demonstrated through.
Deep Multi-View Subspace Clustering with Anchor Graph
May 11, 2023



Deep multi-view subspace clustering (DMVSC) has recently attracted increasing attention due to its promising performance. However, existing DMVSC methods still have two issues: (1) they mainly focus on using autoencoders to nonlinearly embed the data, while the embedding may be suboptimal for clustering because the clustering objective is rarely considered in autoencoders, and (2) existing methods typically have a quadratic or even cubic complexity, which makes it challenging to deal with large-scale data. To address these issues, in this paper we propose a novel deep multi-view subspace clustering method with anchor graph (DMCAG). To be specific, DMCAG firstly learns the embedded features for each view independently, which are used to obtain the subspace representations. To significantly reduce the complexity, we construct an anchor graph with small size for each view. Then, spectral clustering is performed on an integrated anchor graph to obtain pseudo-labels. To overcome the negative impact caused by suboptimal embedded features, we use pseudo-labels to refine the embedding process to make it more suitable for the clustering task. Pseudo-labels and embedded features are updated alternately. Furthermore, we design a strategy to keep the consistency of the labels based on contrastive learning to enhance the clustering performance. Empirical studies on real-world datasets show that our method achieves superior clustering performance over other state-of-the-art methods.