 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKrishan Rana
LHManip: A Dataset for Long-Horizon Language-Grounded Manipulation Tasks in Cluttered Tabletop Environments
Dec 20, 2023
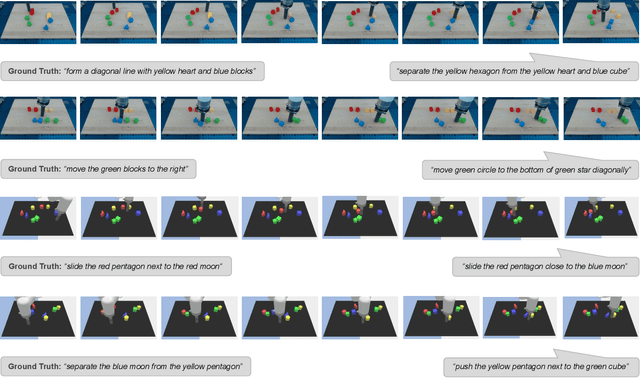
Instructing a robot to complete an everyday task within our homes has been a long-standing challenge for robotics. While recent progress in language-conditioned imitation learning and offline reinforcement learning has demonstrated impressive performance across a wide range of tasks, they are typically limited to short-horizon tasks -- not reflective of those a home robot would be expected to complete. While existing architectures have the potential to learn these desired behaviours, the lack of the necessary long-horizon, multi-step datasets for real robotic systems poses a significant challenge. To this end, we present the Long-Horizon Manipulation (LHManip) dataset comprising 200 episodes, demonstrating 20 different manipulation tasks via real robot teleoperation. The tasks entail multiple sub-tasks, including grasping, pushing, stacking and throwing objects in highly cluttered environments. Each task is paired with a natural language instruction and multi-camera viewpoints for point-cloud or NeRF reconstruction. In total, the dataset comprises 176,278 observation-action pairs which form part of the Open X-Embodiment dataset. The full LHManip dataset is made publicly available at https://github.com/fedeceola/LHManip.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023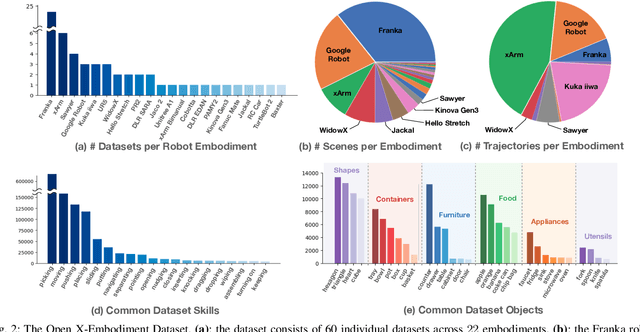
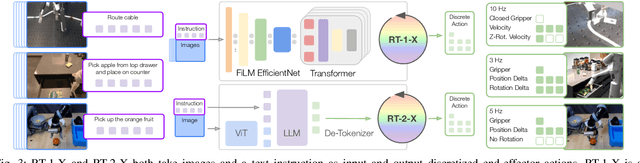
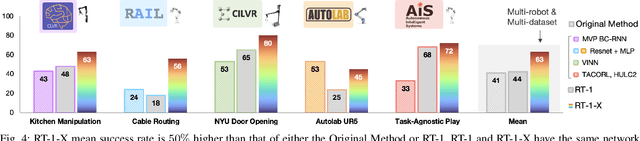

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Task Planning
Jul 12, 2023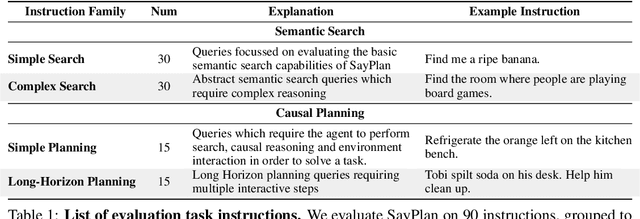
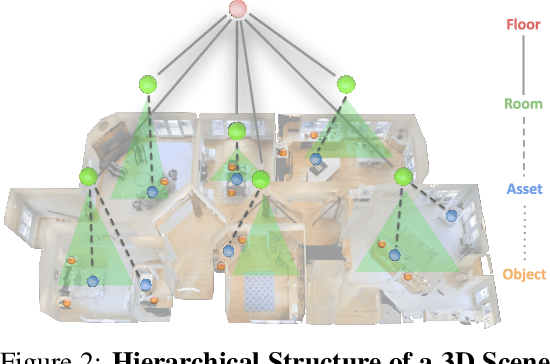
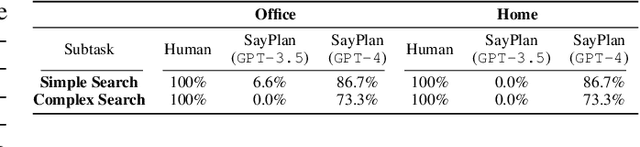
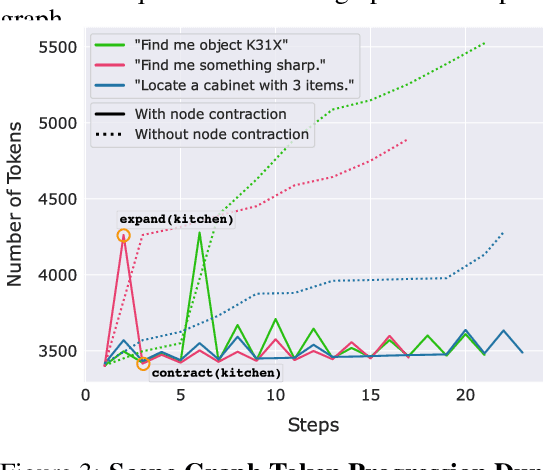
Large language models (LLMs) have demonstrated impressive results in developing generalist planning agents for diverse tasks. However, grounding these plans in expansive, multi-floor, and multi-room environments presents a significant challenge for robotics. We introduce SayPlan, a scalable approach to LLM-based, large-scale task planning for robotics using 3D scene graph (3DSG) representations. To ensure the scalability of our approach, we: (1) exploit the hierarchical nature of 3DSGs to allow LLMs to conduct a semantic search for task-relevant subgraphs from a smaller, collapsed representation of the full graph; (2) reduce the planning horizon for the LLM by integrating a classical path planner and (3) introduce an iterative replanning pipeline that refines the initial plan using feedback from a scene graph simulator, correcting infeasible actions and avoiding planning failures. We evaluate our approach on two large-scale environments spanning up to 3 floors, 36 rooms and 140 objects, and show that our approach is capable of grounding large-scale, long-horizon task plans from abstract, and natural language instruction for a mobile manipulator robot to execute.
Contrastive Language, Action, and State Pre-training for Robot Learning
Apr 21, 2023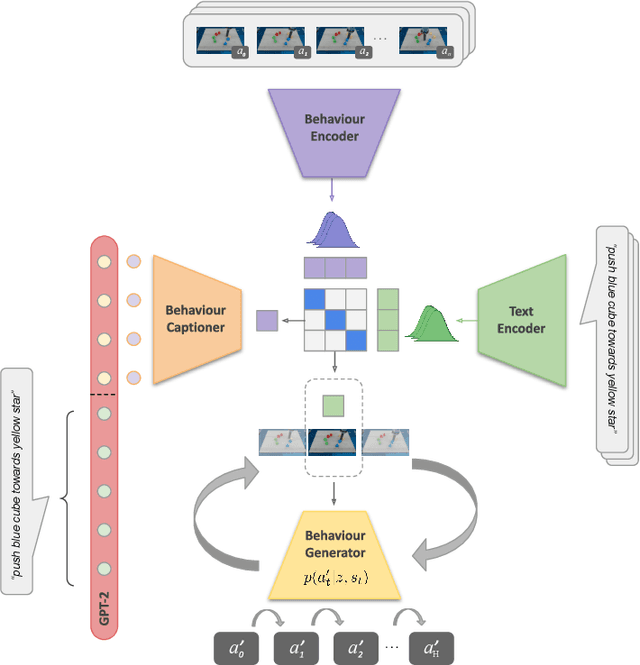
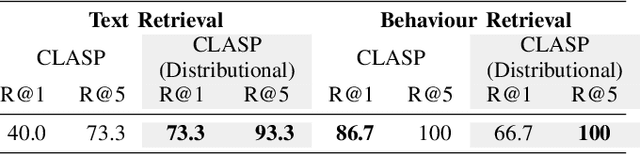

In this paper, we introduce a method for unifying language, action, and state information in a shared embedding space to facilitate a range of downstream tasks in robot learning. Our method, Contrastive Language, Action, and State Pre-training (CLASP), extends the CLIP formulation by incorporating distributional learning, capturing the inherent complexities and one-to-many relationships in behaviour-text alignment. By employing distributional outputs for both text and behaviour encoders, our model effectively associates diverse textual commands with a single behaviour and vice-versa. We demonstrate the utility of our method for the following downstream tasks: zero-shot text-behaviour retrieval, captioning unseen robot behaviours, and learning a behaviour prior for language-conditioned reinforcement learning. Our distributional encoders exhibit superior retrieval and captioning performance on unseen datasets, and the ability to generate meaningful exploratory behaviours from textual commands, capturing the intricate relationships between language, action, and state. This work represents an initial step towards developing a unified pre-trained model for robotics, with the potential to generalise to a broad range of downstream tasks.
Residual Skill Policies: Learning an Adaptable Skill-based Action Space for Reinforcement Learning for Robotics
Nov 04, 2022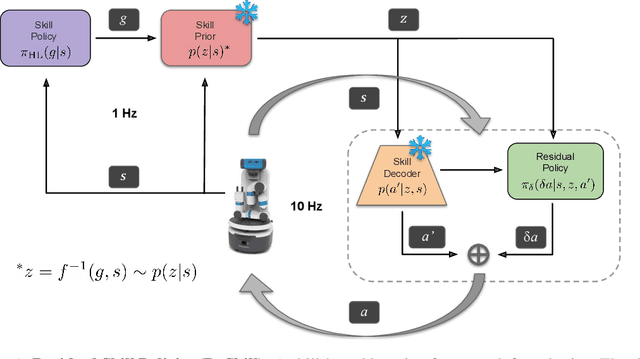
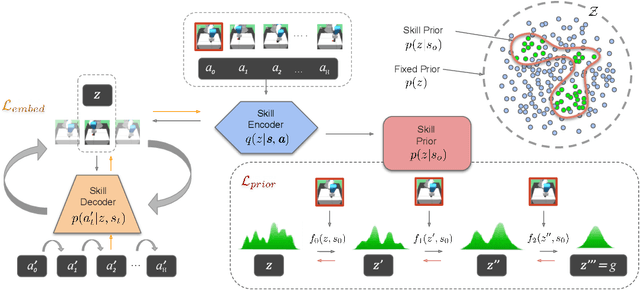
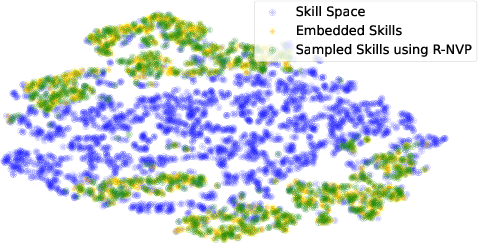
Skill-based reinforcement learning (RL) has emerged as a promising strategy to leverage prior knowledge for accelerated robot learning. Skills are typically extracted from expert demonstrations and are embedded into a latent space from which they can be sampled as actions by a high-level RL agent. However, this skill space is expansive, and not all skills are relevant for a given robot state, making exploration difficult. Furthermore, the downstream RL agent is limited to learning structurally similar tasks to those used to construct the skill space. We firstly propose accelerating exploration in the skill space using state-conditioned generative models to directly bias the high-level agent towards only sampling skills relevant to a given state based on prior experience. Next, we propose a low-level residual policy for fine-grained skill adaptation enabling downstream RL agents to adapt to unseen task variations. Finally, we validate our approach across four challenging manipulation tasks that differ from those used to build the skill space, demonstrating our ability to learn across task variations while significantly accelerating exploration, outperforming prior works. Code and videos are available on our project website: https://krishanrana.github.io/reskill.
Zero-Shot Uncertainty-Aware Deployment of Simulation Trained Policies on Real-World Robots
Dec 10, 2021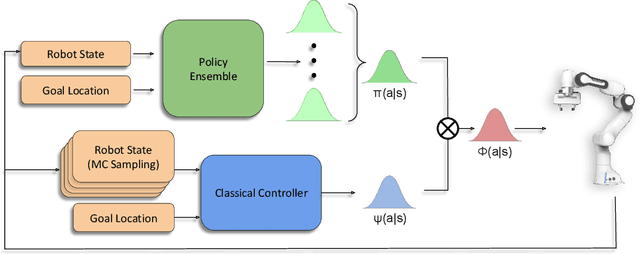
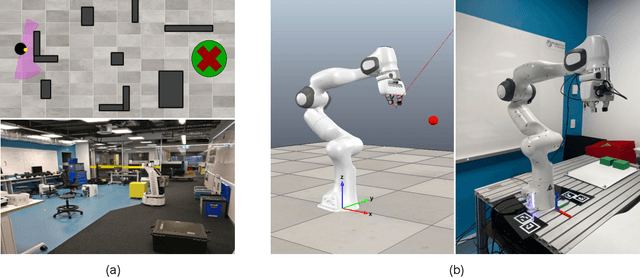

While deep reinforcement learning (RL) agents have demonstrated incredible potential in attaining dexterous behaviours for robotics, they tend to make errors when deployed in the real world due to mismatches between the training and execution environments. In contrast, the classical robotics community have developed a range of controllers that can safely operate across most states in the real world given their explicit derivation. These controllers however lack the dexterity required for complex tasks given limitations in analytical modelling and approximations. In this paper, we propose Bayesian Controller Fusion (BCF), a novel uncertainty-aware deployment strategy that combines the strengths of deep RL policies and traditional handcrafted controllers. In this framework, we can perform zero-shot sim-to-real transfer, where our uncertainty based formulation allows the robot to reliably act within out-of-distribution states by leveraging the handcrafted controller while gaining the dexterity of the learned system otherwise. We show promising results on two real-world continuous control tasks, where BCF outperforms both the standalone policy and controller, surpassing what either can achieve independently. A supplementary video demonstrating our system is provided at https://bit.ly/bcf_deploy.
Bayesian Controller Fusion: Leveraging Control Priors in Deep Reinforcement Learning for Robotics
Jul 22, 2021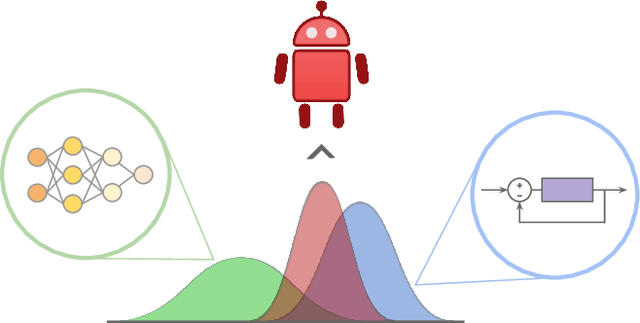



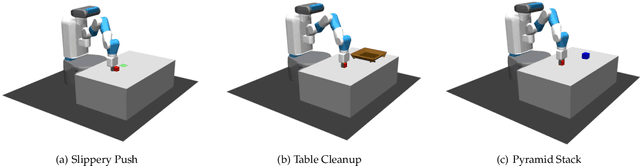
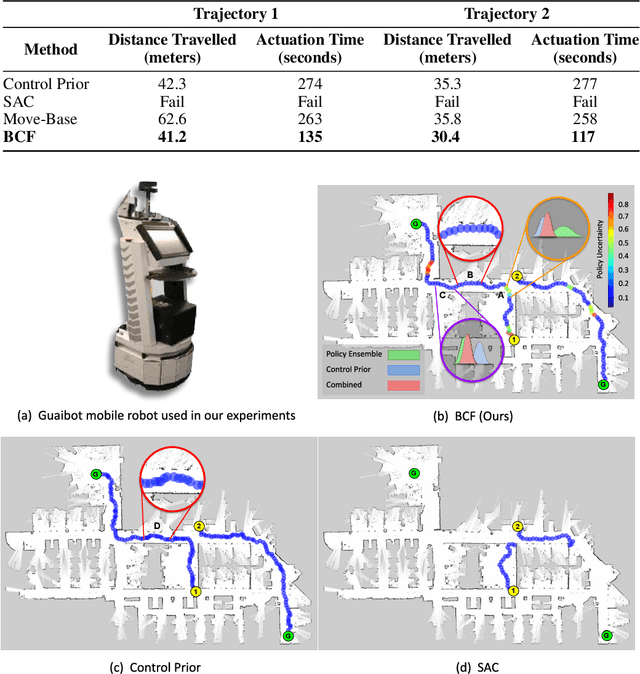
We present Bayesian Controller Fusion (BCF): a hybrid control strategy that combines the strengths of traditional hand-crafted controllers and model-free deep reinforcement learning (RL). BCF thrives in the robotics domain, where reliable but suboptimal control priors exist for many tasks, but RL from scratch remains unsafe and data-inefficient. By fusing uncertainty-aware distributional outputs from each system, BCF arbitrates control between them, exploiting their respective strengths. We study BCF on two real-world robotics tasks involving navigation in a vast and long-horizon environment, and a complex reaching task that involves manipulability maximisation. For both these domains, there exist simple handcrafted controllers that can solve the task at hand in a risk-averse manner but do not necessarily exhibit the optimal solution given limitations in analytical modelling, controller miscalibration and task variation. As exploration is naturally guided by the prior in the early stages of training, BCF accelerates learning, while substantially improving beyond the performance of the control prior, as the policy gains more experience. More importantly, given the risk-aversity of the control prior, BCF ensures safe exploration and deployment, where the control prior naturally dominates the action distribution in states unknown to the policy. We additionally show BCF's applicability to the zero-shot sim-to-real setting and its ability to deal with out-of-distribution states in the real-world. BCF is a promising approach for combining the complementary strengths of deep RL and traditional robotic control, surpassing what either can achieve independently. The code and supplementary video material are made publicly available at https://krishanrana.github.io/bcf.
Critic Guided Segmentation of Rewarding Objects in First-Person Views
Jul 20, 2021
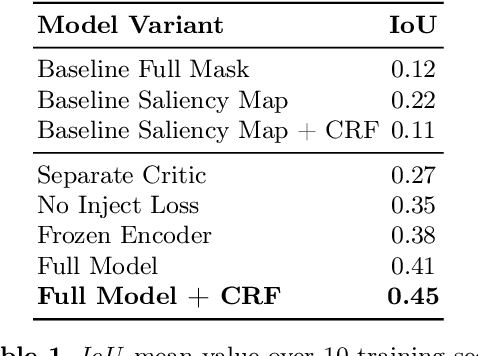

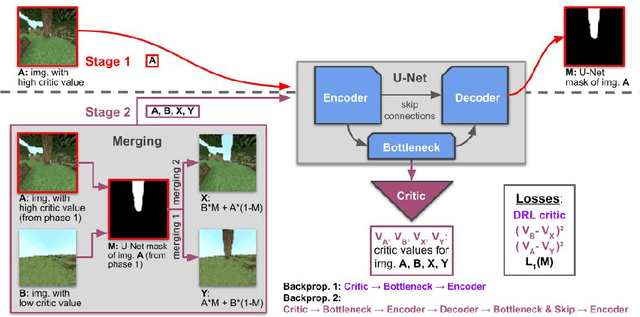
This work discusses a learning approach to mask rewarding objects in images using sparse reward signals from an imitation learning dataset. For that, we train an Hourglass network using only feedback from a critic model. The Hourglass network learns to produce a mask to decrease the critic's score of a high score image and increase the critic's score of a low score image by swapping the masked areas between these two images. We trained the model on an imitation learning dataset from the NeurIPS 2020 MineRL Competition Track, where our model learned to mask rewarding objects in a complex interactive 3D environment with a sparse reward signal. This approach was part of the 1st place winning solution in this competition. Video demonstration and code: https://rebrand.ly/critic-guided-segmentation
Multiplicative Controller Fusion: A Hybrid Navigation Strategy For Deployment in Unknown Environments
Mar 13, 2020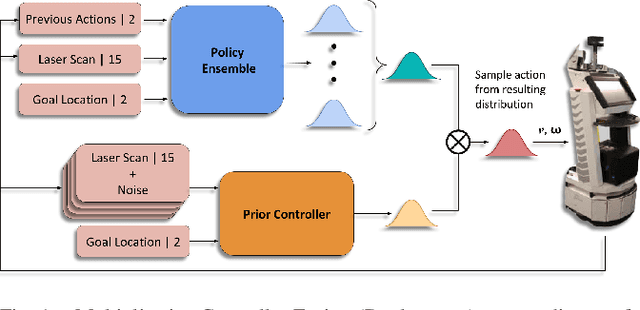
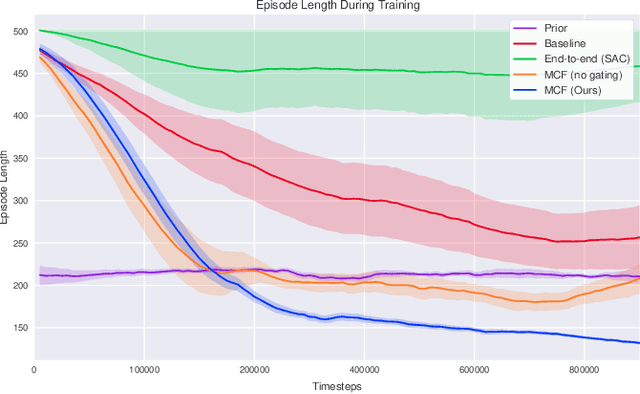
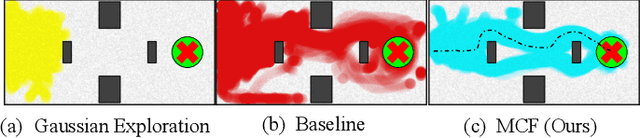

Learning-based approaches often outperform hand-coded algorithmic solutions for many problems in robotics. However, learning long-horizon tasks on real robot hardware can be intractable, and transferring a learned policy from simulation to reality is still extremely challenging. We present a novel approach to model-free reinforcement learning that can leverage existing sub-optimal solutions as an algorithmic prior during training and deployment. During training, our gated fusion approach enables the prior to guide the initial stages of exploration, increasing sample-efficiency and enabling learning from sparse long-horizon reward signals. Importantly, the policy can learn to improve beyond the performance of the sub-optimal prior since the prior's influence is annealed gradually. During deployment, the policy's uncertainty provides a reliable strategy for transferring a simulation-trained policy to the real world by falling back to the prior controller in uncertain states. We show the efficacy of our Multiplicative Controller Fusion approach on the task of robot navigation and demonstrate safe transfer from simulation to the real world without any fine tuning. The code for this project is made publicly available at https://sites.google.com/view/mcf-nav/home.
Residual Reactive Navigation: Combining Classical and Learned Navigation Strategies For Deployment in Unknown Environments
Sep 24, 2019
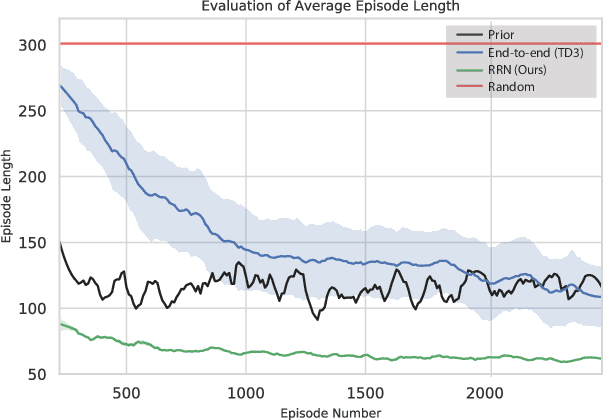

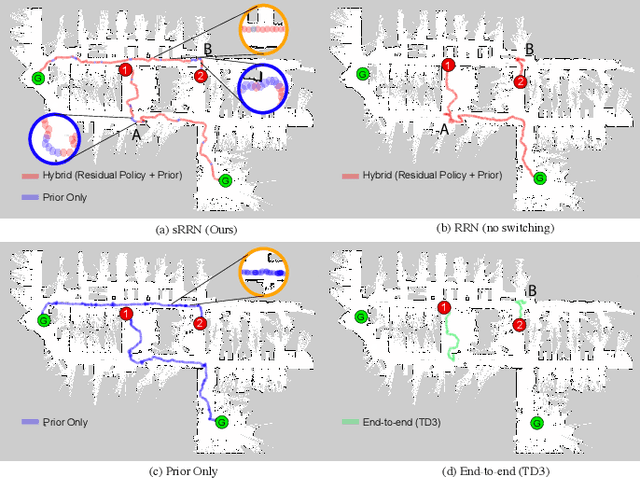
In this work we focus on improving the efficiency and generalisation of learned navigation strategies when transferred from its training environment to previously unseen ones. We present an extension of the residual reinforcement learning framework from the robotic manipulation literature and adapt it to the vast and unstructured environments that mobile robots can operate in. The concept is based on learning a residual control effect to add to a typical sub-optimal classical controller in order to close the performance gap, whilst guiding the exploration process during training for improved data efficiency. We exploit this tight coupling and propose a novel deployment strategy, switching Residual Reactive Navigation (sRNN), which yields efficient trajectories whilst probabilistically switching to a classical controller in cases of high policy uncertainty. Our approach achieves improved performance over end-to-end alternatives and can be incorporated as part of a complete navigation stack for cluttered indoor navigation tasks in the real world. The code and training environment for this project is made publicly available at https://github.com/krishanrana/2D_SRRN.