 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Su
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Apr 18, 2024
We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
Dynamic Gaussians Mesh: Consistent Mesh Reconstruction from Monocular Videos
Apr 18, 2024Modern 3D engines and graphics pipelines require mesh as a memory-efficient representation, which allows efficient rendering, geometry processing, texture editing, and many other downstream operations. However, it is still highly difficult to obtain high-quality mesh in terms of structure and detail from monocular visual observations. The problem becomes even more challenging for dynamic scenes and objects. To this end, we introduce Dynamic Gaussians Mesh (DG-Mesh), a framework to reconstruct a high-fidelity and time-consistent mesh given a single monocular video. Our work leverages the recent advancement in 3D Gaussian Splatting to construct the mesh sequence with temporal consistency from a video. Building on top of this representation, DG-Mesh recovers high-quality meshes from the Gaussian points and can track the mesh vertices over time, which enables applications such as texture editing on dynamic objects. We introduce the Gaussian-Mesh Anchoring, which encourages evenly distributed Gaussians, resulting better mesh reconstruction through mesh-guided densification and pruning on the deformed Gaussians. By applying cycle-consistent deformation between the canonical and the deformed space, we can project the anchored Gaussian back to the canonical space and optimize Gaussians across all time frames. During the evaluation on different datasets, DG-Mesh provides significantly better mesh reconstruction and rendering than baselines.
AdaDemo: Data-Efficient Demonstration Expansion for Generalist Robotic Agent
Apr 11, 2024Encouraged by the remarkable achievements of language and vision foundation models, developing generalist robotic agents through imitation learning, using large demonstration datasets, has become a prominent area of interest in robot learning. The efficacy of imitation learning is heavily reliant on the quantity and quality of the demonstration datasets. In this study, we aim to scale up demonstrations in a data-efficient way to facilitate the learning of generalist robotic agents. We introduce AdaDemo (Adaptive Online Demonstration Expansion), a general framework designed to improve multi-task policy learning by actively and continually expanding the demonstration dataset. AdaDemo strategically collects new demonstrations to address the identified weakness in the existing policy, ensuring data efficiency is maximized. Through a comprehensive evaluation on a total of 22 tasks across two robotic manipulation benchmarks (RLBench and Adroit), we demonstrate AdaDemo's capability to progressively improve policy performance by guiding the generation of high-quality demonstration datasets in a data-efficient manner.
Lift3D: Zero-Shot Lifting of Any 2D Vision Model to 3D
Mar 27, 2024In recent years, there has been an explosion of 2D vision models for numerous tasks such as semantic segmentation, style transfer or scene editing, enabled by large-scale 2D image datasets. At the same time, there has been renewed interest in 3D scene representations such as neural radiance fields from multi-view images. However, the availability of 3D or multiview data is still substantially limited compared to 2D image datasets, making extending 2D vision models to 3D data highly desirable but also very challenging. Indeed, extending a single 2D vision operator like scene editing to 3D typically requires a highly creative method specialized to that task and often requires per-scene optimization. In this paper, we ask the question of whether any 2D vision model can be lifted to make 3D consistent predictions. We answer this question in the affirmative; our new Lift3D method trains to predict unseen views on feature spaces generated by a few visual models (i.e. DINO and CLIP), but then generalizes to novel vision operators and tasks, such as style transfer, super-resolution, open vocabulary segmentation and image colorization; for some of these tasks, there is no comparable previous 3D method. In many cases, we even outperform state-of-the-art methods specialized for the task in question. Moreover, Lift3D is a zero-shot method, in the sense that it requires no task-specific training, nor scene-specific optimization.
Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
Mar 19, 2024
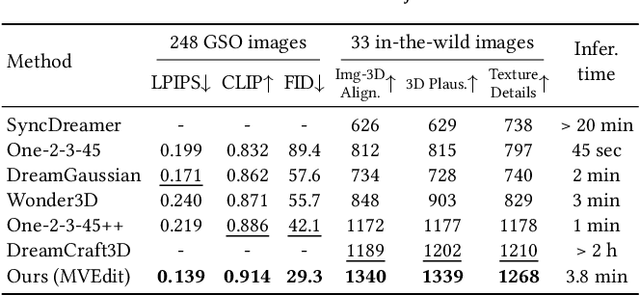
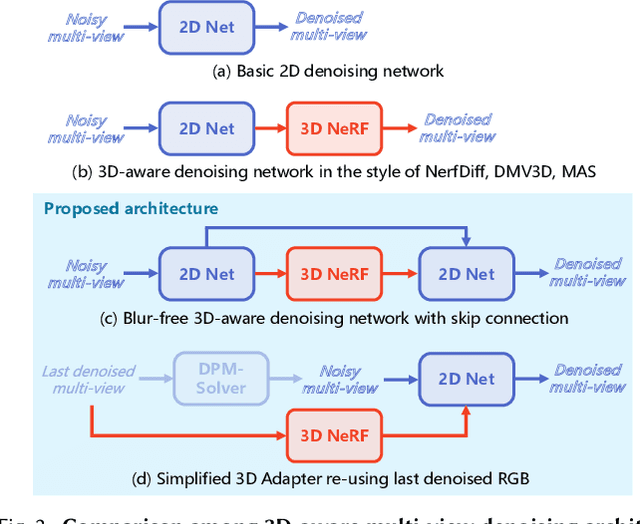
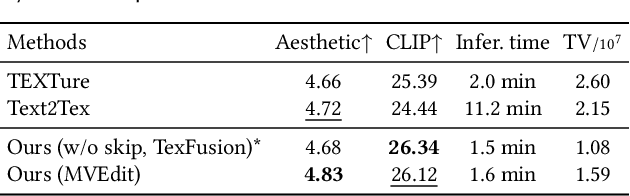
Open-domain 3D object synthesis has been lagging behind image synthesis due to limited data and higher computational complexity. To bridge this gap, recent works have investigated multi-view diffusion but often fall short in either 3D consistency, visual quality, or efficiency. This paper proposes MVEdit, which functions as a 3D counterpart of SDEdit, employing ancestral sampling to jointly denoise multi-view images and output high-quality textured meshes. Built on off-the-shelf 2D diffusion models, MVEdit achieves 3D consistency through a training-free 3D Adapter, which lifts the 2D views of the last timestep into a coherent 3D representation, then conditions the 2D views of the next timestep using rendered views, without uncompromising visual quality. With an inference time of only 2-5 minutes, this framework achieves better trade-off between quality and speed than score distillation. MVEdit is highly versatile and extendable, with a wide range of applications including text/image-to-3D generation, 3D-to-3D editing, and high-quality texture synthesis. In particular, evaluations demonstrate state-of-the-art performance in both image-to-3D and text-guided texture generation tasks. Additionally, we introduce a method for fine-tuning 2D latent diffusion models on small 3D datasets with limited resources, enabling fast low-resolution text-to-3D initialization.
EgoPAT3Dv2: Predicting 3D Action Target from 2D Egocentric Vision for Human-Robot Interaction
Mar 08, 2024
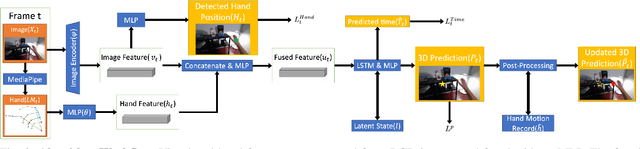
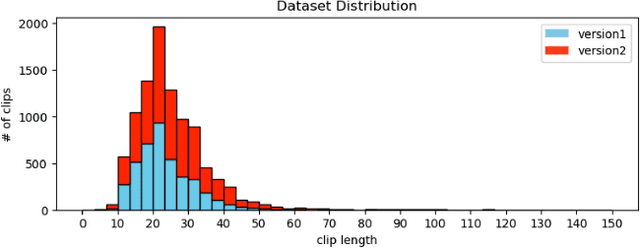
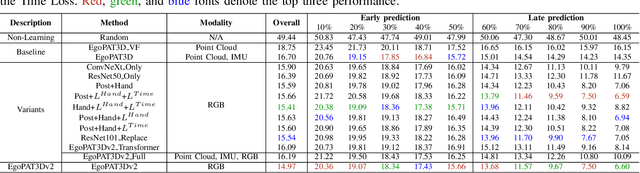
A robot's ability to anticipate the 3D action target location of a hand's movement from egocentric videos can greatly improve safety and efficiency in human-robot interaction (HRI). While previous research predominantly focused on semantic action classification or 2D target region prediction, we argue that predicting the action target's 3D coordinate could pave the way for more versatile downstream robotics tasks, especially given the increasing prevalence of headset devices. This study expands EgoPAT3D, the sole dataset dedicated to egocentric 3D action target prediction. We augment both its size and diversity, enhancing its potential for generalization. Moreover, we substantially enhance the baseline algorithm by introducing a large pre-trained model and human prior knowledge. Remarkably, our novel algorithm can now achieve superior prediction outcomes using solely RGB images, eliminating the previous need for 3D point clouds and IMU input. Furthermore, we deploy our enhanced baseline algorithm on a real-world robotic platform to illustrate its practical utility in straightforward HRI tasks. The demonstrations showcase the real-world applicability of our advancements and may inspire more HRI use cases involving egocentric vision. All code and data are open-sourced and can be found on the project website.
CyberDemo: Augmenting Simulated Human Demonstration for Real-World Dexterous Manipulation
Mar 01, 2024We introduce CyberDemo, a novel approach to robotic imitation learning that leverages simulated human demonstrations for real-world tasks. By incorporating extensive data augmentation in a simulated environment, CyberDemo outperforms traditional in-domain real-world demonstrations when transferred to the real world, handling diverse physical and visual conditions. Regardless of its affordability and convenience in data collection, CyberDemo outperforms baseline methods in terms of success rates across various tasks and exhibits generalizability with previously unseen objects. For example, it can rotate novel tetra-valve and penta-valve, despite human demonstrations only involving tri-valves. Our research demonstrates the significant potential of simulated human demonstrations for real-world dexterous manipulation tasks. More details can be found at https://cyber-demo.github.io
Constrained Online Two-stage Stochastic Optimization: Algorithm with (and without) Predictions
Jan 02, 2024We consider an online two-stage stochastic optimization with long-term constraints over a finite horizon of $T$ periods. At each period, we take the first-stage action, observe a model parameter realization and then take the second-stage action from a feasible set that depends both on the first-stage decision and the model parameter. We aim to minimize the cumulative objective value while guaranteeing that the long-term average second-stage decision belongs to a set. We develop online algorithms for the online two-stage problem from adversarial learning algorithms. Also, the regret bound of our algorithm can be reduced to the regret bound of embedded adversarial learning algorithms. Based on this framework, we obtain new results under various settings. When the model parameters are drawn from unknown non-stationary distributions and we are given machine-learned predictions of the distributions, we develop a new algorithm from our framework with a regret $O(W_T+\sqrt{T})$, where $W_T$ measures the total inaccuracy of the machine-learned predictions. We then develop another algorithm that works when no machine-learned predictions are given and show the performances.
ZeroRF: Fast Sparse View 360° Reconstruction with Zero Pretraining
Dec 14, 2023We present ZeroRF, a novel per-scene optimization method addressing the challenge of sparse view 360{\deg} reconstruction in neural field representations. Current breakthroughs like Neural Radiance Fields (NeRF) have demonstrated high-fidelity image synthesis but struggle with sparse input views. Existing methods, such as Generalizable NeRFs and per-scene optimization approaches, face limitations in data dependency, computational cost, and generalization across diverse scenarios. To overcome these challenges, we propose ZeroRF, whose key idea is to integrate a tailored Deep Image Prior into a factorized NeRF representation. Unlike traditional methods, ZeroRF parametrizes feature grids with a neural network generator, enabling efficient sparse view 360{\deg} reconstruction without any pretraining or additional regularization. Extensive experiments showcase ZeroRF's versatility and superiority in terms of both quality and speed, achieving state-of-the-art results on benchmark datasets. ZeroRF's significance extends to applications in 3D content generation and editing. Project page: https://sarahweiii.github.io/zerorf/