 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZexiang Xu
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Apr 18, 2024
We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
Nov 23, 2023

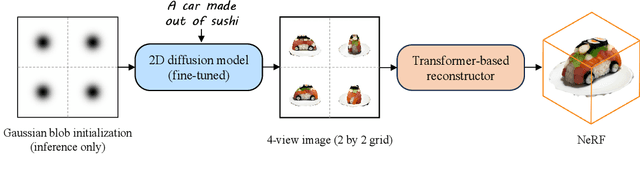
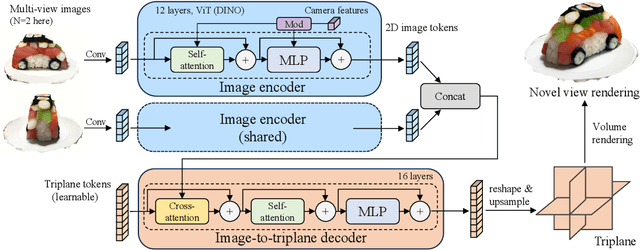
Text-to-3D with diffusion models has achieved remarkable progress in recent years. However, existing methods either rely on score distillation-based optimization which suffer from slow inference, low diversity and Janus problems, or are feed-forward methods that generate low-quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that generates high-quality and diverse 3D assets from text prompts in a feed-forward manner. We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a novel transformer-based sparse-view reconstructor. Through extensive experiments, we demonstrate that our method can generate diverse 3D assets of high visual quality within 20 seconds, which is two orders of magnitude faster than previous optimization-based methods that can take 1 to 10 hours. Our project webpage: https://jiahao.ai/instant3d/.
PF-LRM: Pose-Free Large Reconstruction Model for Joint Pose and Shape Prediction
Nov 23, 2023
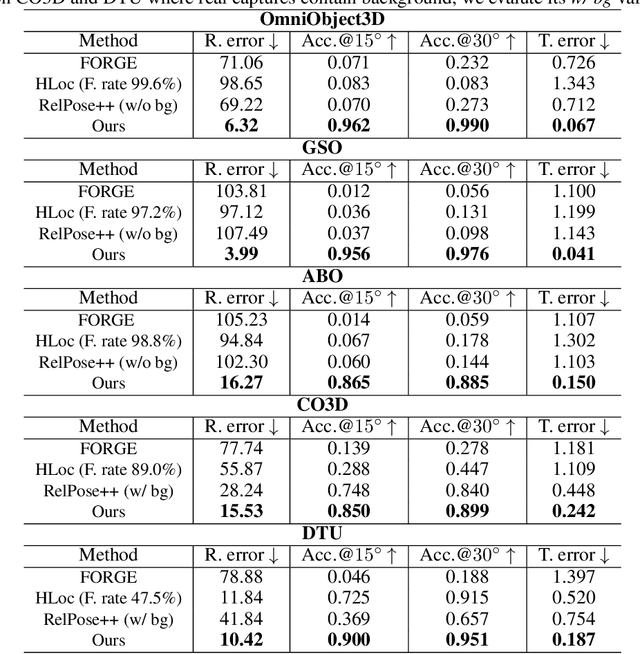
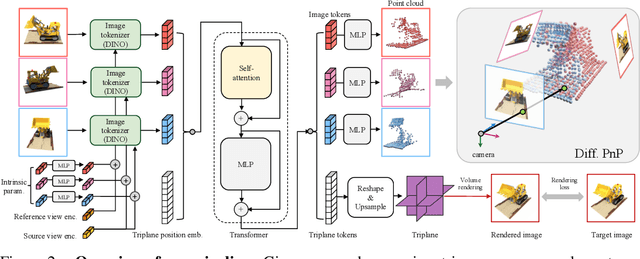
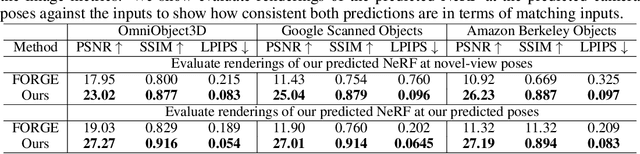
We propose a Pose-Free Large Reconstruction Model (PF-LRM) for reconstructing a 3D object from a few unposed images even with little visual overlap, while simultaneously estimating the relative camera poses in ~1.3 seconds on a single A100 GPU. PF-LRM is a highly scalable method utilizing the self-attention blocks to exchange information between 3D object tokens and 2D image tokens; we predict a coarse point cloud for each view, and then use a differentiable Perspective-n-Point (PnP) solver to obtain camera poses. When trained on a huge amount of multi-view posed data of ~1M objects, PF-LRM shows strong cross-dataset generalization ability, and outperforms baseline methods by a large margin in terms of pose prediction accuracy and 3D reconstruction quality on various unseen evaluation datasets. We also demonstrate our model's applicability in downstream text/image-to-3D task with fast feed-forward inference. Our project website is at: https://totoro97.github.io/pf-lrm .
DMV3D: Denoising Multi-View Diffusion using 3D Large Reconstruction Model
Nov 15, 2023
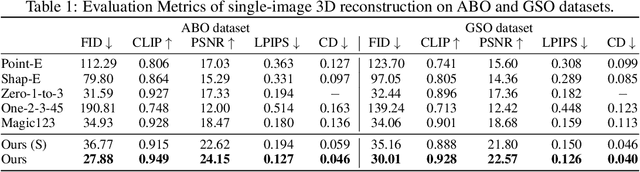

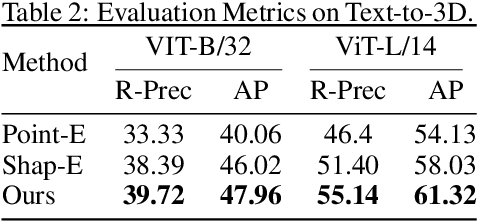
We propose \textbf{DMV3D}, a novel 3D generation approach that uses a transformer-based 3D large reconstruction model to denoise multi-view diffusion. Our reconstruction model incorporates a triplane NeRF representation and can denoise noisy multi-view images via NeRF reconstruction and rendering, achieving single-stage 3D generation in $\sim$30s on single A100 GPU. We train \textbf{DMV3D} on large-scale multi-view image datasets of highly diverse objects using only image reconstruction losses, without accessing 3D assets. We demonstrate state-of-the-art results for the single-image reconstruction problem where probabilistic modeling of unseen object parts is required for generating diverse reconstructions with sharp textures. We also show high-quality text-to-3D generation results outperforming previous 3D diffusion models. Our project website is at: https://justimyhxu.github.io/projects/dmv3d/ .
Controllable Dynamic Appearance for Neural 3D Portraits
Sep 21, 2023
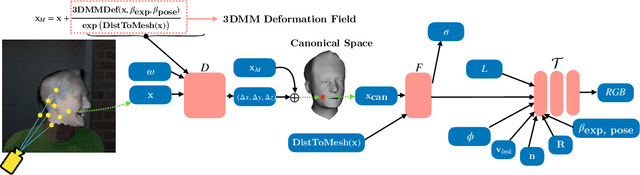
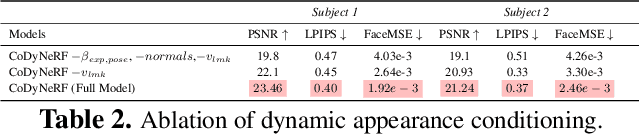
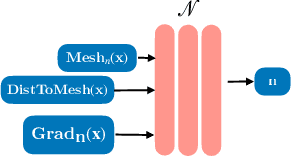
Recent advances in Neural Radiance Fields (NeRFs) have made it possible to reconstruct and reanimate dynamic portrait scenes with control over head-pose, facial expressions and viewing direction. However, training such models assumes photometric consistency over the deformed region e.g. the face must be evenly lit as it deforms with changing head-pose and facial expression. Such photometric consistency across frames of a video is hard to maintain, even in studio environments, thus making the created reanimatable neural portraits prone to artifacts during reanimation. In this work, we propose CoDyNeRF, a system that enables the creation of fully controllable 3D portraits in real-world capture conditions. CoDyNeRF learns to approximate illumination dependent effects via a dynamic appearance model in the canonical space that is conditioned on predicted surface normals and the facial expressions and head-pose deformations. The surface normals prediction is guided using 3DMM normals that act as a coarse prior for the normals of the human head, where direct prediction of normals is hard due to rigid and non-rigid deformations induced by head-pose and facial expression changes. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls, and realistic lighting effects. The project page can be found here: http://shahrukhathar.github.io/2023/08/22/CoDyNeRF.html
OpenIllumination: A Multi-Illumination Dataset for Inverse Rendering Evaluation on Real Objects
Sep 14, 2023
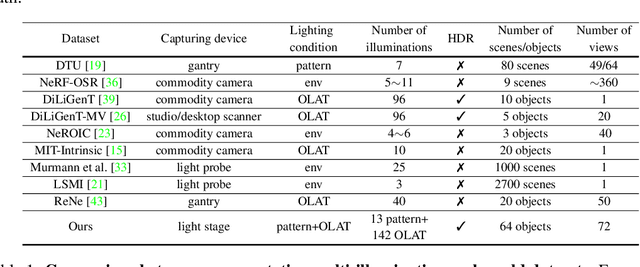

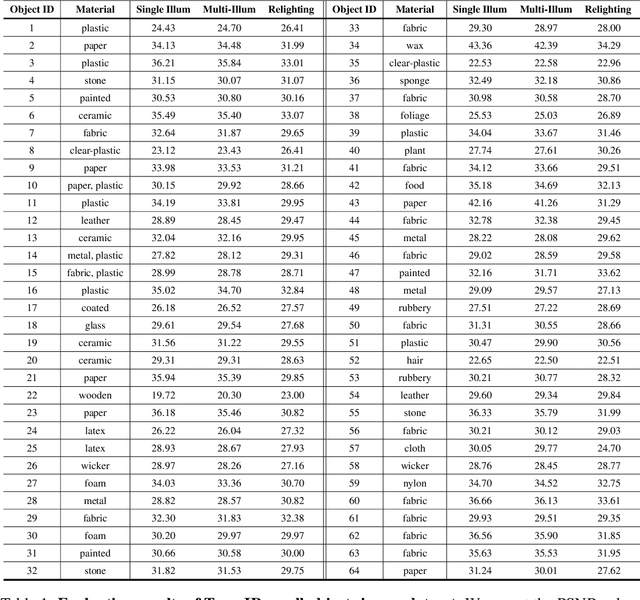
We introduce OpenIllumination, a real-world dataset containing over 108K images of 64 objects with diverse materials, captured under 72 camera views and a large number of different illuminations. For each image in the dataset, we provide accurate camera parameters, illumination ground truth, and foreground segmentation masks. Our dataset enables the quantitative evaluation of most inverse rendering and material decomposition methods for real objects. We examine several state-of-the-art inverse rendering methods on our dataset and compare their performances. The dataset and code can be found on the project page: https://oppo-us-research.github.io/OpenIllumination.
Strivec: Sparse Tri-Vector Radiance Fields
Jul 25, 2023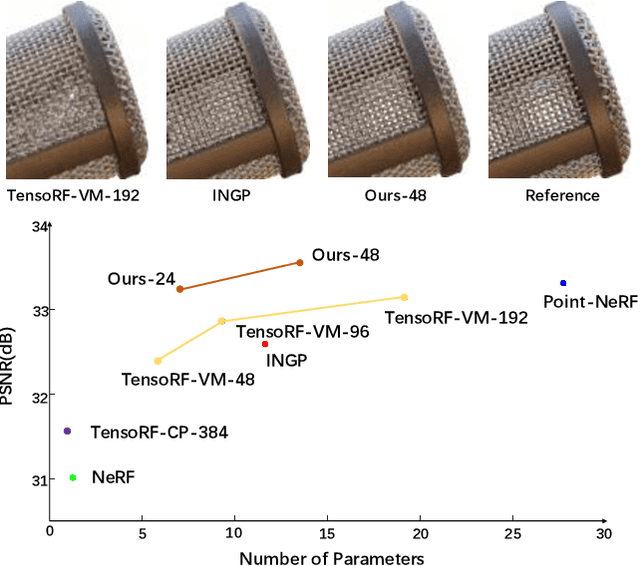
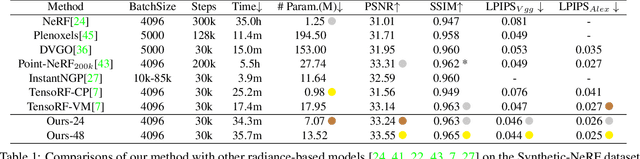
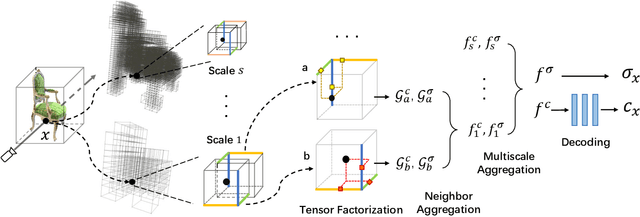
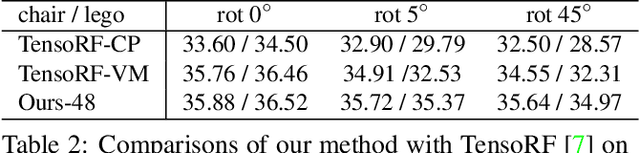
We propose Strivec, a novel neural representation that models a 3D scene as a radiance field with sparsely distributed and compactly factorized local tensor feature grids. Our approach leverages tensor decomposition, following the recent work TensoRF, to model the tensor grids. In contrast to TensoRF which uses a global tensor and focuses on their vector-matrix decomposition, we propose to utilize a cloud of local tensors and apply the classic CANDECOMP/PARAFAC (CP) decomposition to factorize each tensor into triple vectors that express local feature distributions along spatial axes and compactly encode a local neural field. We also apply multi-scale tensor grids to discover the geometry and appearance commonalities and exploit spatial coherence with the tri-vector factorization at multiple local scales. The final radiance field properties are regressed by aggregating neural features from multiple local tensors across all scales. Our tri-vector tensors are sparsely distributed around the actual scene surface, discovered by a fast coarse reconstruction, leveraging the sparsity of a 3D scene. We demonstrate that our model can achieve better rendering quality while using significantly fewer parameters than previous methods, including TensoRF and Instant-NGP.
Neural Free-Viewpoint Relighting for Glossy Indirect Illumination
Jul 12, 2023
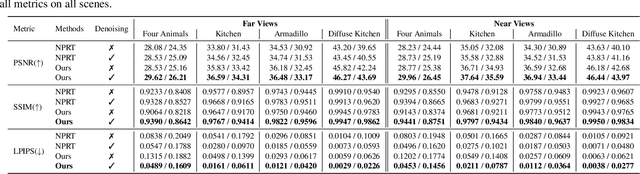

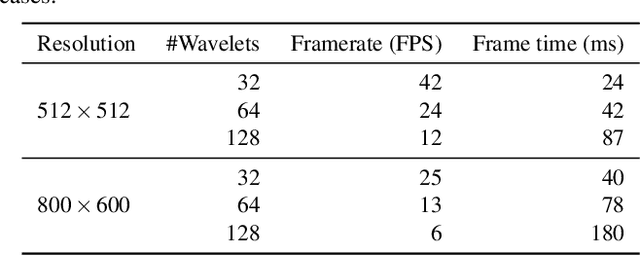
Precomputed Radiance Transfer (PRT) remains an attractive solution for real-time rendering of complex light transport effects such as glossy global illumination. After precomputation, we can relight the scene with new environment maps while changing viewpoint in real-time. However, practical PRT methods are usually limited to low-frequency spherical harmonic lighting. All-frequency techniques using wavelets are promising but have so far had little practical impact. The curse of dimensionality and much higher data requirements have typically limited them to relighting with fixed view or only direct lighting with triple product integrals. In this paper, we demonstrate a hybrid neural-wavelet PRT solution to high-frequency indirect illumination, including glossy reflection, for relighting with changing view. Specifically, we seek to represent the light transport function in the Haar wavelet basis. For global illumination, we learn the wavelet transport using a small multi-layer perceptron (MLP) applied to a feature field as a function of spatial location and wavelet index, with reflected direction and material parameters being other MLP inputs. We optimize/learn the feature field (compactly represented by a tensor decomposition) and MLP parameters from multiple images of the scene under different lighting and viewing conditions. We demonstrate real-time (512 x 512 at 24 FPS, 800 x 600 at 13 FPS) precomputed rendering of challenging scenes involving view-dependent reflections and even caustics.
One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
Jun 29, 2023
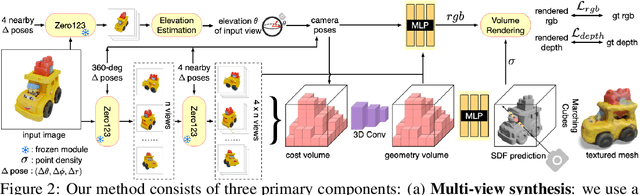
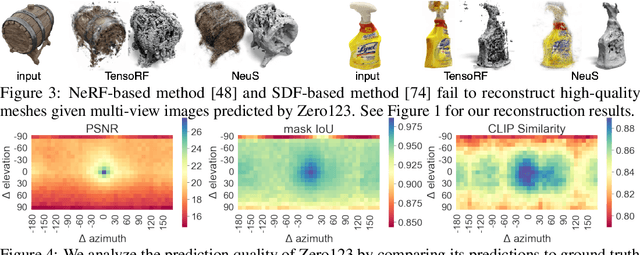

Single image 3D reconstruction is an important but challenging task that requires extensive knowledge of our natural world. Many existing methods solve this problem by optimizing a neural radiance field under the guidance of 2D diffusion models but suffer from lengthy optimization time, 3D inconsistency results, and poor geometry. In this work, we propose a novel method that takes a single image of any object as input and generates a full 360-degree 3D textured mesh in a single feed-forward pass. Given a single image, we first use a view-conditioned 2D diffusion model, Zero123, to generate multi-view images for the input view, and then aim to lift them up to 3D space. Since traditional reconstruction methods struggle with inconsistent multi-view predictions, we build our 3D reconstruction module upon an SDF-based generalizable neural surface reconstruction method and propose several critical training strategies to enable the reconstruction of 360-degree meshes. Without costly optimizations, our method reconstructs 3D shapes in significantly less time than existing methods. Moreover, our method favors better geometry, generates more 3D consistent results, and adheres more closely to the input image. We evaluate our approach on both synthetic data and in-the-wild images and demonstrate its superiority in terms of both mesh quality and runtime. In addition, our approach can seamlessly support the text-to-3D task by integrating with off-the-shelf text-to-image diffusion models.
NeuManifold: Neural Watertight Manifold Reconstruction with Efficient and High-Quality Rendering Support
May 26, 2023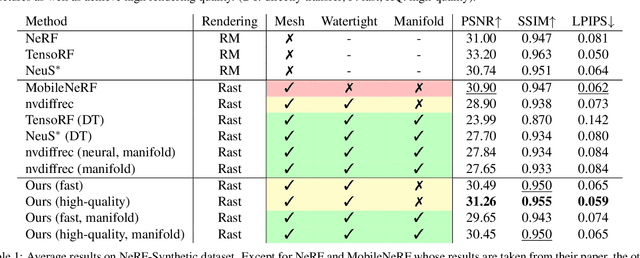
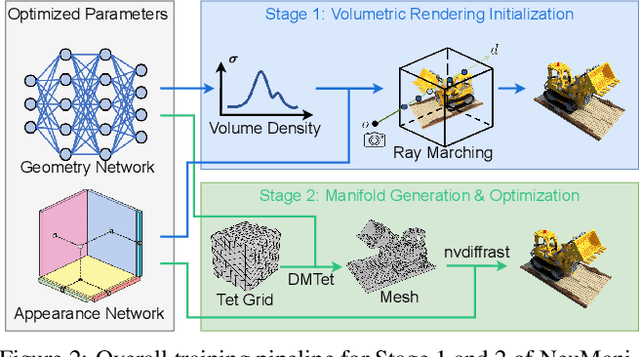
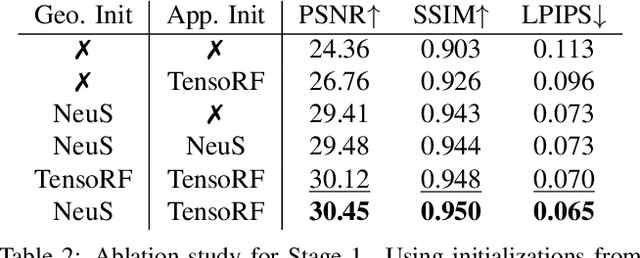

We present a method for generating high-quality watertight manifold meshes from multi-view input images. Existing volumetric rendering methods are robust in optimization but tend to generate noisy meshes with poor topology. Differentiable rasterization-based methods can generate high-quality meshes but are sensitive to initialization. Our method combines the benefits of both worlds; we take the geometry initialization obtained from neural volumetric fields, and further optimize the geometry as well as a compact neural texture representation with differentiable rasterizers. Through extensive experiments, we demonstrate that our method can generate accurate mesh reconstructions with faithful appearance that are comparable to previous volume rendering methods while being an order of magnitude faster in rendering. We also show that our generated mesh and neural texture reconstruction is compatible with existing graphics pipelines and enables downstream 3D applications such as simulation. Project page: https://sarahweiii.github.io/neumanifold/