 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYicong Hong
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Mar 01, 2024
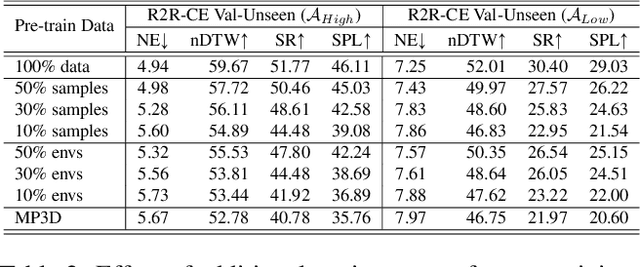
Vision-and-Language Navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavour to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometer and depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision-making and instruction following. We train NaVid with 550k navigation samples collected from VLN-CE trajectories, including action-planning and instruction-reasoning samples, along with 665k large-scale web data. Extensive experiments show that NaVid achieves SOTA performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
Nov 23, 2023

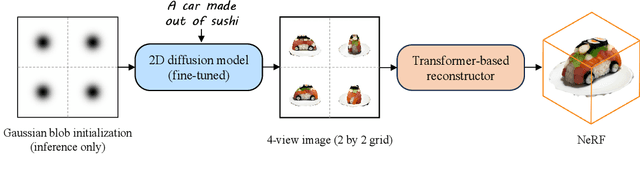
Text-to-3D with diffusion models has achieved remarkable progress in recent years. However, existing methods either rely on score distillation-based optimization which suffer from slow inference, low diversity and Janus problems, or are feed-forward methods that generate low-quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that generates high-quality and diverse 3D assets from text prompts in a feed-forward manner. We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a novel transformer-based sparse-view reconstructor. Through extensive experiments, we demonstrate that our method can generate diverse 3D assets of high visual quality within 20 seconds, which is two orders of magnitude faster than previous optimization-based methods that can take 1 to 10 hours. Our project webpage: https://jiahao.ai/instant3d/.
LRM: Large Reconstruction Model for Single Image to 3D
Nov 08, 2023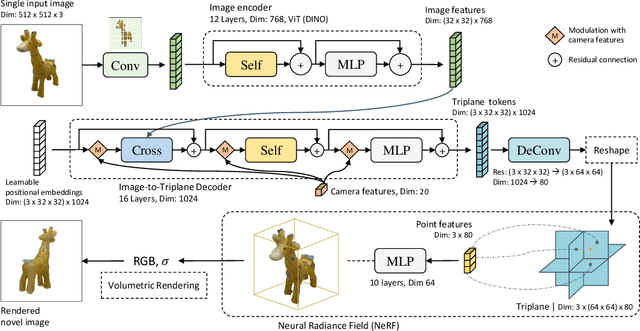
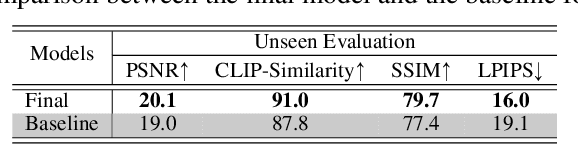

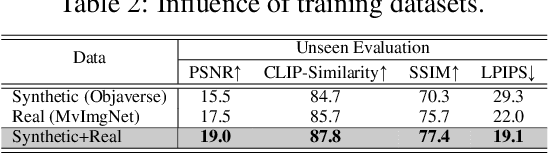
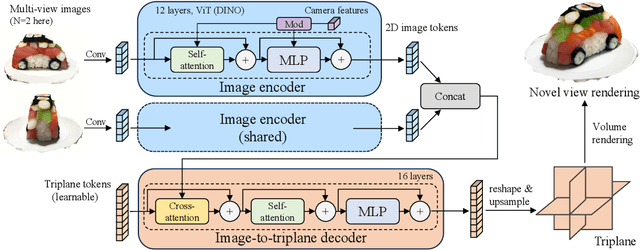
We propose the first Large Reconstruction Model (LRM) that predicts the 3D model of an object from a single input image within just 5 seconds. In contrast to many previous methods that are trained on small-scale datasets such as ShapeNet in a category-specific fashion, LRM adopts a highly scalable transformer-based architecture with 500 million learnable parameters to directly predict a neural radiance field (NeRF) from the input image. We train our model in an end-to-end manner on massive multi-view data containing around 1 million objects, including both synthetic renderings from Objaverse and real captures from MVImgNet. This combination of a high-capacity model and large-scale training data empowers our model to be highly generalizable and produce high-quality 3D reconstructions from various testing inputs including real-world in-the-wild captures and images from generative models. Video demos and interactable 3D meshes can be found on this website: https://yiconghong.me/LRM/.
Scaling Data Generation in Vision-and-Language Navigation
Aug 09, 2023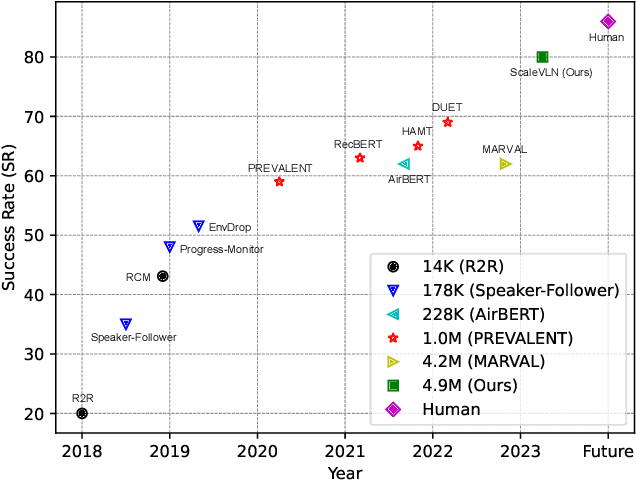
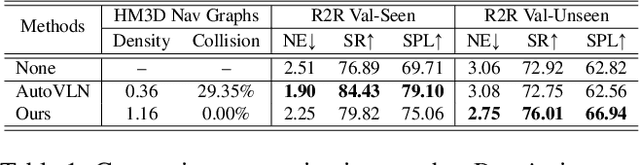
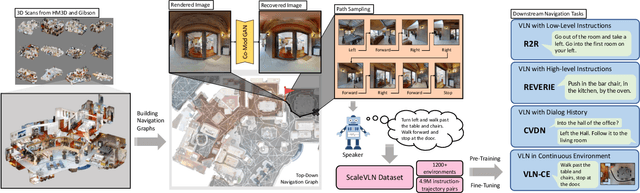
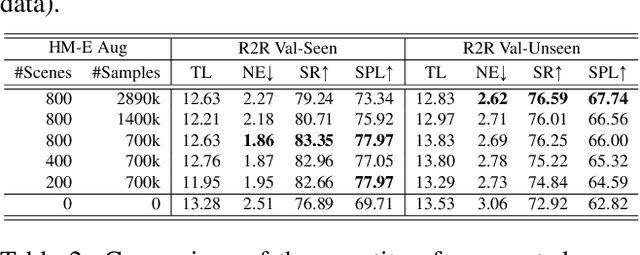
Recent research in language-guided visual navigation has demonstrated a significant demand for the diversity of traversable environments and the quantity of supervision for training generalizable agents. To tackle the common data scarcity issue in existing vision-and-language navigation datasets, we propose an effective paradigm for generating large-scale data for learning, which applies 1200+ photo-realistic environments from HM3D and Gibson datasets and synthesizes 4.9 million instruction trajectory pairs using fully-accessible resources on the web. Importantly, we investigate the influence of each component in this paradigm on the agent's performance and study how to adequately apply the augmented data to pre-train and fine-tune an agent. Thanks to our large-scale dataset, the performance of an existing agent can be pushed up (+11% absolute with regard to previous SoTA) to a significantly new best of 80% single-run success rate on the R2R test split by simple imitation learning. The long-lasting generalization gap between navigating in seen and unseen environments is also reduced to less than 1% (versus 8% in the previous best method). Moreover, our paradigm also facilitates different models to achieve new state-of-the-art navigation results on CVDN, REVERIE, and R2R in continuous environments.
Learning Navigational Visual Representations with Semantic Map Supervision
Jul 23, 2023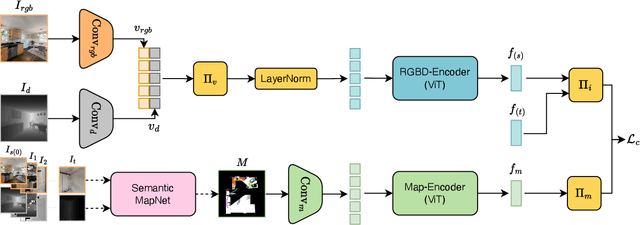
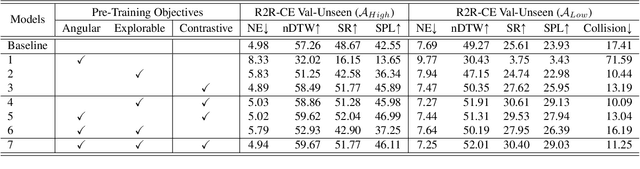
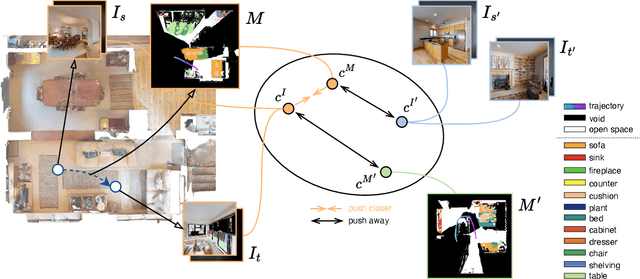
Being able to perceive the semantics and the spatial structure of the environment is essential for visual navigation of a household robot. However, most existing works only employ visual backbones pre-trained either with independent images for classification or with self-supervised learning methods to adapt to the indoor navigation domain, neglecting the spatial relationships that are essential to the learning of navigation. Inspired by the behavior that humans naturally build semantically and spatially meaningful cognitive maps in their brains during navigation, in this paper, we propose a novel navigational-specific visual representation learning method by contrasting the agent's egocentric views and semantic maps (Ego$^2$-Map). We apply the visual transformer as the backbone encoder and train the model with data collected from the large-scale Habitat-Matterport3D environments. Ego$^2$-Map learning transfers the compact and rich information from a map, such as objects, structure and transition, to the agent's egocentric representations for navigation. Experiments show that agents using our learned representations on object-goal navigation outperform recent visual pre-training methods. Moreover, our representations significantly improve vision-and-language navigation in continuous environments for both high-level and low-level action spaces, achieving new state-of-the-art results of 47% SR and 41% SPL on the test server.
NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models
May 29, 2023

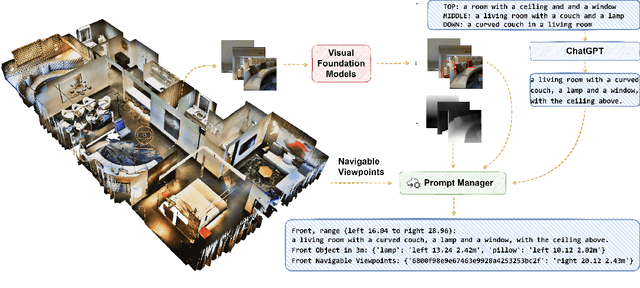
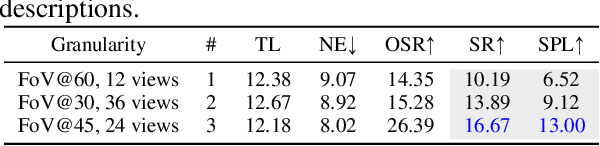
Trained with an unprecedented scale of data, large language models (LLMs) like ChatGPT and GPT-4 exhibit the emergence of significant reasoning abilities from model scaling. Such a trend underscored the potential of training LLMs with unlimited language data, advancing the development of a universal embodied agent. In this work, we introduce the NavGPT, a purely LLM-based instruction-following navigation agent, to reveal the reasoning capability of GPT models in complex embodied scenes by performing zero-shot sequential action prediction for vision-and-language navigation (VLN). At each step, NavGPT takes the textual descriptions of visual observations, navigation history, and future explorable directions as inputs to reason the agent's current status, and makes the decision to approach the target. Through comprehensive experiments, we demonstrate NavGPT can explicitly perform high-level planning for navigation, including decomposing instruction into sub-goal, integrating commonsense knowledge relevant to navigation task resolution, identifying landmarks from observed scenes, tracking navigation progress, and adapting to exceptions with plan adjustment. Furthermore, we show that LLMs is capable of generating high-quality navigational instructions from observations and actions along a path, as well as drawing accurate top-down metric trajectory given the agent's navigation history. Despite the performance of using NavGPT to zero-shot R2R tasks still falling short of trained models, we suggest adapting multi-modality inputs for LLMs to use as visual navigation agents and applying the explicit reasoning of LLMs to benefit learning-based models.
Bi-directional Training for Composed Image Retrieval via Text Prompt Learning
Mar 29, 2023
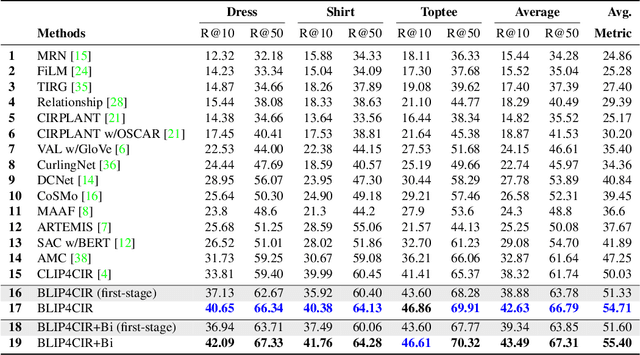

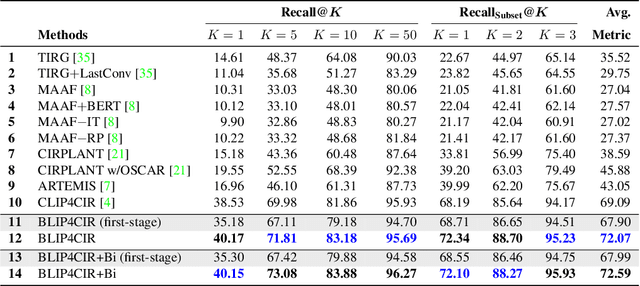
Composed image retrieval searches for a target image based on a multi-modal user query comprised of a reference image and modification text describing the desired changes. Existing approaches to solving this challenging task learn a mapping from the (reference image, modification text)-pair to an image embedding that is then matched against a large image corpus. One area that has not yet been explored is the reverse direction, which asks the question, what reference image when modified as describe by the text would produce the given target image? In this work we propose a bi-directional training scheme that leverages such reversed queries and can be applied to existing composed image retrieval architectures. To encode the bi-directional query we prepend a learnable token to the modification text that designates the direction of the query and then finetune the parameters of the text embedding module. We make no other changes to the network architecture. Experiments on two standard datasets show that our novel approach achieves improved performance over a baseline BLIP-based model that itself already achieves state-of-the-art performance.
1st Place Solutions for RxR-Habitat Vision-and-Language Navigation Competition (CVPR 2022)
Jun 26, 2022

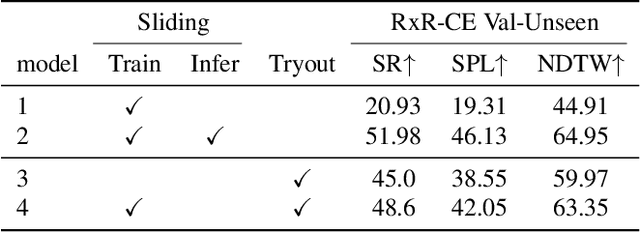

This report presents the methods of the winning entry of the RxR-Habitat Competition in CVPR 2022. The competition addresses the problem of Vision-and-Language Navigation in Continuous Environments (VLN-CE), which requires an agent to follow step-by-step natural language instructions to reach a target. We present a modular plan-and-control approach for the task. Our model consists of three modules: the candidate waypoints predictor (CWP), the history enhanced planner and the tryout controller. In each decision loop, CWP first predicts a set of candidate waypoints based on depth observations from multiple views. It can reduce the complexity of the action space and facilitate planning. Then, a history-enhanced planner is adopted to select one of the candidate waypoints as the subgoal. The planner additionally encodes historical memory to track the navigation progress, which is especially effective for long-horizon navigation. Finally, we propose a non-parametric heuristic controller named tryout to execute low-level actions to reach the planned subgoal. It is based on the trial-and-error mechanism which can help the agent to avoid obstacles and escape from getting stuck. All three modules work hierarchically until the agent stops. We further take several recent advances of Vision-and-Language Navigation (VLN) to improve the performance such as pretraining based on large-scale synthetic in-domain dataset, environment-level data augmentation and snapshot model ensemble. Our model won the RxR-Habitat Competition 2022, with 48% and 90% relative improvements over existing methods on NDTW and SR metrics respectively.
HOP: History-and-Order Aware Pre-training for Vision-and-Language Navigation
Mar 22, 2022



Pre-training has been adopted in a few of recent works for Vision-and-Language Navigation (VLN). However, previous pre-training methods for VLN either lack the ability to predict future actions or ignore the trajectory contexts, which are essential for a greedy navigation process. In this work, to promote the learning of spatio-temporal visual-textual correspondence as well as the agent's capability of decision making, we propose a novel history-and-order aware pre-training paradigm (HOP) with VLN-specific objectives that exploit the past observations and support future action prediction. Specifically, in addition to the commonly used Masked Language Modeling (MLM) and Trajectory-Instruction Matching (TIM), we design two proxy tasks to model temporal order information: Trajectory Order Modeling (TOM) and Group Order Modeling (GOM). Moreover, our navigation action prediction is also enhanced by introducing the task of Action Prediction with History (APH), which takes into account the history visual perceptions. Extensive experimental results on four downstream VLN tasks (R2R, REVERIE, NDH, RxR) demonstrate the effectiveness of our proposed method compared against several state-of-the-art agents.
Bridging the Gap Between Learning in Discrete and Continuous Environments for Vision-and-Language Navigation
Mar 05, 2022
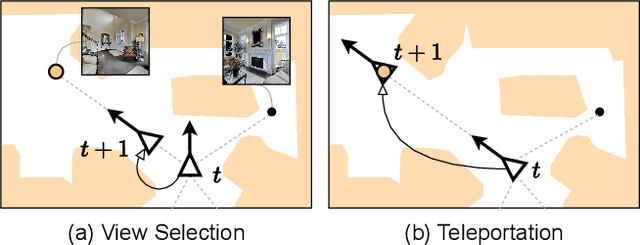
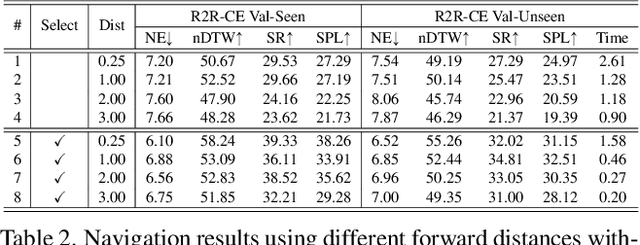
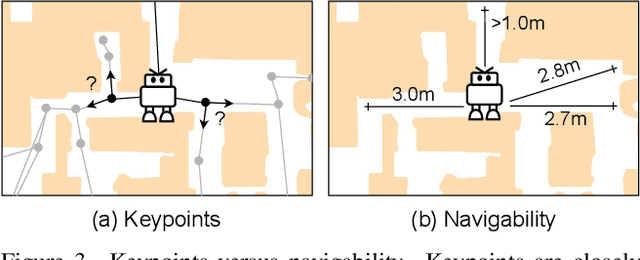
Most existing works in vision-and-language navigation (VLN) focus on either discrete or continuous environments, training agents that cannot generalize across the two. The fundamental difference between the two setups is that discrete navigation assumes prior knowledge of the connectivity graph of the environment, so that the agent can effectively transfer the problem of navigation with low-level controls to jumping from node to node with high-level actions by grounding to an image of a navigable direction. To bridge the discrete-to-continuous gap, we propose a predictor to generate a set of candidate waypoints during navigation, so that agents designed with high-level actions can be transferred to and trained in continuous environments. We refine the connectivity graph of Matterport3D to fit the continuous Habitat-Matterport3D, and train the waypoints predictor with the refined graphs to produce accessible waypoints at each time step. Moreover, we demonstrate that the predicted waypoints can be augmented during training to diversify the views and paths, and therefore enhance agent's generalization ability. Through extensive experiments we show that agents navigating in continuous environments with predicted waypoints perform significantly better than agents using low-level actions, which reduces the absolute discrete-to-continuous gap by 11.76% Success Weighted by Path Length (SPL) for the Cross-Modal Matching Agent and 18.24% SPL for the Recurrent VLN-BERT. Our agents, trained with a simple imitation learning objective, outperform previous methods by a large margin, achieving new state-of-the-art results on the testing environments of the R2R-CE and the RxR-CE datasets.