 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiuxiang Gu
SOHES: Self-supervised Open-world Hierarchical Entity Segmentation
Apr 18, 2024
Open-world entity segmentation, as an emerging computer vision task, aims at segmenting entities in images without being restricted by pre-defined classes, offering impressive generalization capabilities on unseen images and concepts. Despite its promise, existing entity segmentation methods like Segment Anything Model (SAM) rely heavily on costly expert annotators. This work presents Self-supervised Open-world Hierarchical Entity Segmentation (SOHES), a novel approach that eliminates the need for human annotations. SOHES operates in three phases: self-exploration, self-instruction, and self-correction. Given a pre-trained self-supervised representation, we produce abundant high-quality pseudo-labels through visual feature clustering. Then, we train a segmentation model on the pseudo-labels, and rectify the noises in pseudo-labels via a teacher-student mutual-learning procedure. Beyond segmenting entities, SOHES also captures their constituent parts, providing a hierarchical understanding of visual entities. Using raw images as the sole training data, our method achieves unprecedented performance in self-supervised open-world segmentation, marking a significant milestone towards high-quality open-world entity segmentation in the absence of human-annotated masks. Project page: https://SOHES.github.io.
Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning
Feb 15, 2024Instruction tuning is critical to large language models (LLMs) for achieving better instruction following and task adaptation capabilities but its success heavily relies on the training data quality. Many recent methods focus on improving the data quality but often overlook the compatibility of the data with the student model being finetuned. This paper introduces Selective Reflection-Tuning, a novel paradigm that synergizes a teacher LLM's reflection and introspection for improving existing data quality with the data selection capability of the student LLM, to automatically refine existing instruction-tuning data. This teacher-student collaboration produces high-quality and student-compatible instruction-response pairs, resulting in sample-efficient instruction tuning and LLMs of superior performance. Selective Reflection-Tuning is a data augmentation and synthesis that generally improves LLM finetuning and self-improvement without collecting brand-new data. We apply our method to Alpaca and WizardLM data and achieve much stronger and top-tier 7B and 13B LLMs. Our codes, models, and data will be released at https://github.com/tianyi-lab/Reflection_Tuning.
Fourier Circuits in Neural Networks: Unlocking the Potential of Large Language Models in Mathematical Reasoning and Modular Arithmetic
Feb 12, 2024In the evolving landscape of machine learning, a pivotal challenge lies in deciphering the internal representations harnessed by neural networks and Transformers. Building on recent progress toward comprehending how networks execute distinct target functions, our study embarks on an exploration of the underlying reasons behind networks adopting specific computational strategies. We direct our focus to the complex algebraic learning task of modular addition involving $k$ inputs. Our research presents a thorough analytical characterization of the features learned by stylized one-hidden layer neural networks and one-layer Transformers in addressing this task. A cornerstone of our theoretical framework is the elucidation of how the principle of margin maximization shapes the features adopted by one-hidden layer neural networks. Let $p$ denote the modulus, $D_p$ denote the dataset of modular arithmetic with $k$ inputs and $m$ denote the network width. We demonstrate that a neuron count of $ m \geq 2^{2k-2} \cdot (p-1) $, these networks attain a maximum $ L_{2,k+1} $-margin on the dataset $ D_p $. Furthermore, we establish that each hidden-layer neuron aligns with a specific Fourier spectrum, integral to solving modular addition problems. By correlating our findings with the empirical observations of similar studies, we contribute to a deeper comprehension of the intrinsic computational mechanisms of neural networks. Furthermore, we observe similar computational mechanisms in the attention matrix of the Transformer. This research stands as a significant stride in unraveling their operation complexities, particularly in the realm of complex algebraic tasks.
Customization Assistant for Text-to-image Generation
Dec 05, 2023
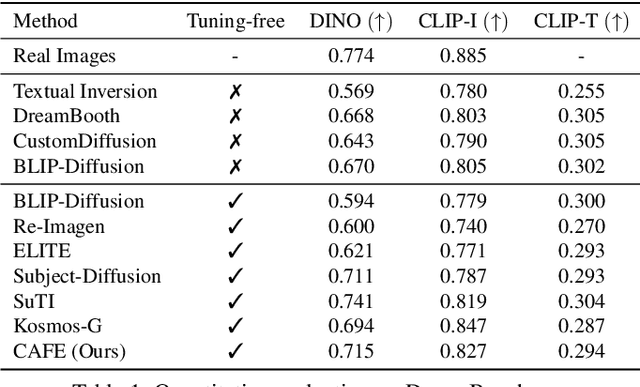
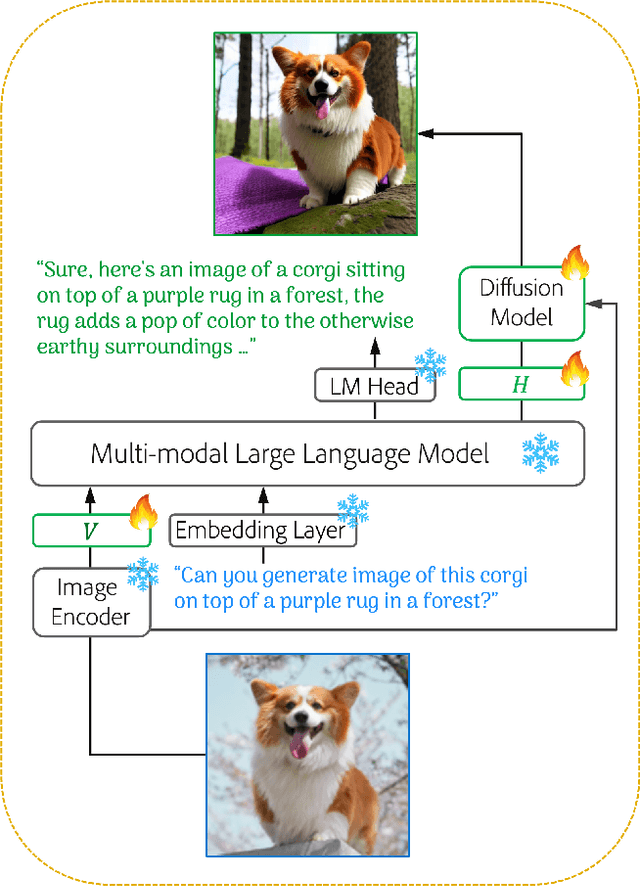
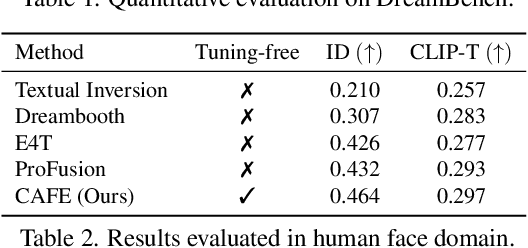
Customizing pre-trained text-to-image generation model has attracted massive research interest recently, due to its huge potential in real-world applications. Although existing methods are able to generate creative content for a novel concept contained in single user-input image, their capability are still far from perfection. Specifically, most existing methods require fine-tuning the generative model on testing images. Some existing methods do not require fine-tuning, while their performance are unsatisfactory. Furthermore, the interaction between users and models are still limited to directive and descriptive prompts such as instructions and captions. In this work, we build a customization assistant based on pre-trained large language model and diffusion model, which can not only perform customized generation in a tuning-free manner, but also enable more user-friendly interactions: users can chat with the assistant and input either ambiguous text or clear instruction. Specifically, we propose a new framework consists of a new model design and a novel training strategy. The resulting assistant can perform customized generation in 2-5 seconds without any test time fine-tuning. Extensive experiments are conducted, competitive results have been obtained across different domains, illustrating the effectiveness of the proposed method.
LRM: Large Reconstruction Model for Single Image to 3D
Nov 08, 2023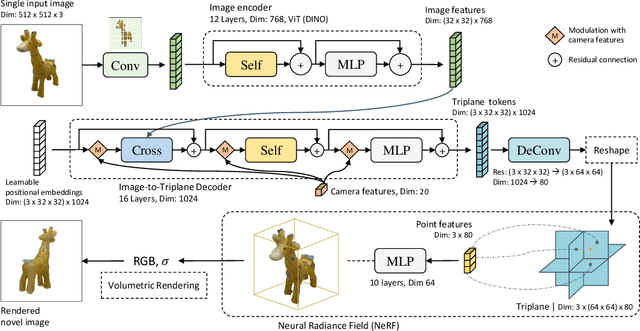
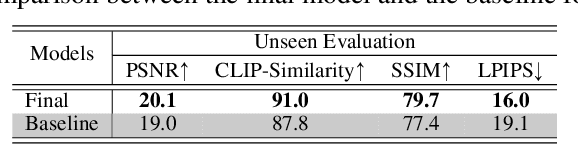

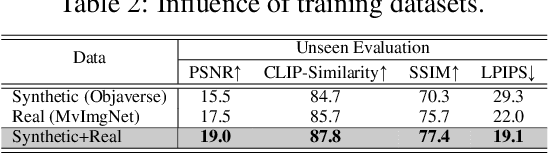
We propose the first Large Reconstruction Model (LRM) that predicts the 3D model of an object from a single input image within just 5 seconds. In contrast to many previous methods that are trained on small-scale datasets such as ShapeNet in a category-specific fashion, LRM adopts a highly scalable transformer-based architecture with 500 million learnable parameters to directly predict a neural radiance field (NeRF) from the input image. We train our model in an end-to-end manner on massive multi-view data containing around 1 million objects, including both synthetic renderings from Objaverse and real captures from MVImgNet. This combination of a high-capacity model and large-scale training data empowers our model to be highly generalizable and produce high-quality 3D reconstructions from various testing inputs including real-world in-the-wild captures and images from generative models. Video demos and interactable 3D meshes can be found on this website: https://yiconghong.me/LRM/.
Improving a Named Entity Recognizer Trained on Noisy Data with a Few Clean Instances
Oct 25, 2023
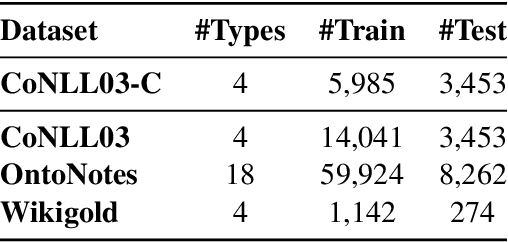
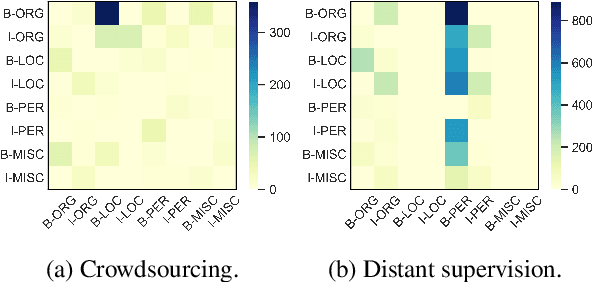
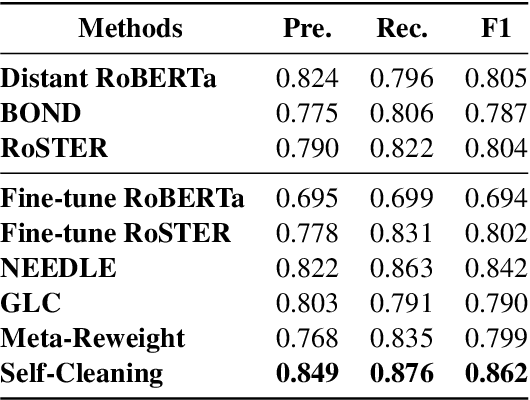
To achieve state-of-the-art performance, one still needs to train NER models on large-scale, high-quality annotated data, an asset that is both costly and time-intensive to accumulate. In contrast, real-world applications often resort to massive low-quality labeled data through non-expert annotators via crowdsourcing and external knowledge bases via distant supervision as a cost-effective alternative. However, these annotation methods result in noisy labels, which in turn lead to a notable decline in performance. Hence, we propose to denoise the noisy NER data with guidance from a small set of clean instances. Along with the main NER model we train a discriminator model and use its outputs to recalibrate the sample weights. The discriminator is capable of detecting both span and category errors with different discriminative prompts. Results on public crowdsourcing and distant supervision datasets show that the proposed method can consistently improve performance with a small guidance set.
Reflection-Tuning: Data Recycling Improves LLM Instruction-Tuning
Oct 18, 2023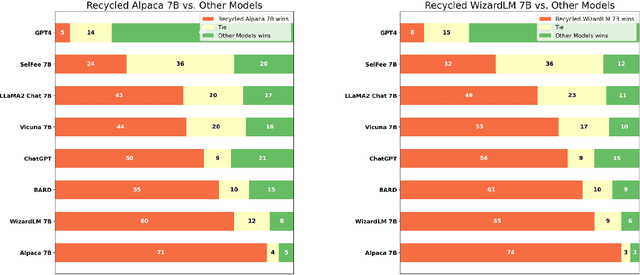
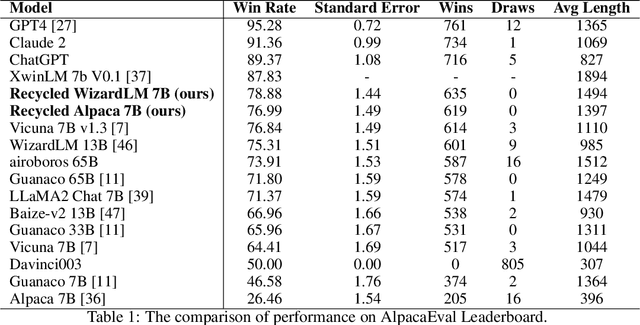
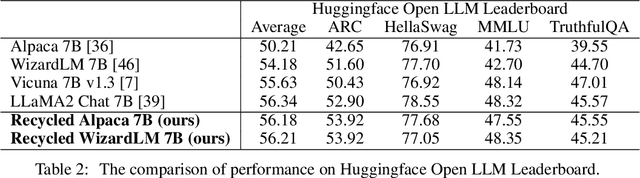

Recent advancements in Large Language Models (LLMs) have expanded the horizons of natural language understanding and generation. Notably, the output control and alignment with the input of LLMs can be refined through instruction tuning. However, as highlighted in several studies, low-quality data in the training set are usually detrimental to instruction tuning, resulting in inconsistent or even misleading LLM outputs. We propose a novel method, termed "reflection-tuning," which addresses the problem by self-improvement and judging capabilities of LLMs. This approach utilizes an oracle LLM to recycle the original training data by introspecting and enhancing the quality of instructions and responses in the data. Extensive experiments on widely used evaluation benchmarks show that LLMs trained with our recycled data outperform those trained with existing datasets in various benchmarks.
LLaVAR: Enhanced Visual Instruction Tuning for Text-Rich Image Understanding
Jun 29, 2023

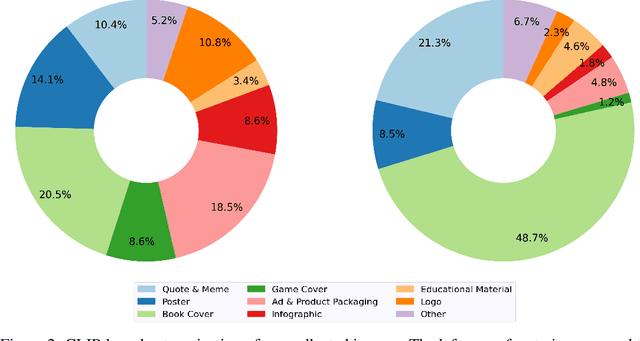
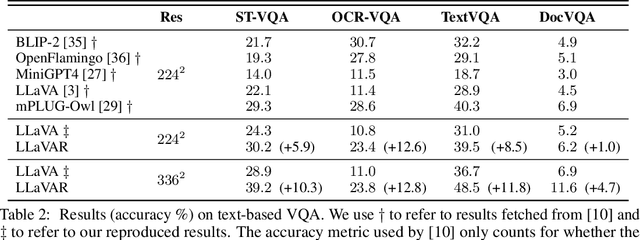
Instruction tuning unlocks the superior capability of Large Language Models (LLM) to interact with humans. Furthermore, recent instruction-following datasets include images as visual inputs, collecting responses for image-based instructions. However, visual instruction-tuned models cannot comprehend textual details within images well. This work enhances the current visual instruction tuning pipeline with text-rich images (e.g., movie posters, book covers, etc.). Specifically, we first use publicly available OCR tools to collect results on 422K text-rich images from the LAION dataset. Moreover, we prompt text-only GPT-4 with recognized texts and image captions to generate 16K conversations, each containing question-answer pairs for text-rich images. By combining our collected data with previous multi-modal instruction-following data, our model, LLaVAR, substantially improves the LLaVA model's capability on text-based VQA datasets (up to 20% accuracy improvement) while achieving an accuracy of 91.42% on ScienceQA. The GPT-4-based instruction-following evaluation also demonstrates the improvement of our model on both natural images and text-rich images. Through qualitative analysis, LLaVAR shows promising interaction (e.g., reasoning, writing, and elaboration) skills with humans based on the latest real-world online content that combines text and images. We make our code/data/models publicly available at https://llavar.github.io/.
AIMS: All-Inclusive Multi-Level Segmentation
May 28, 2023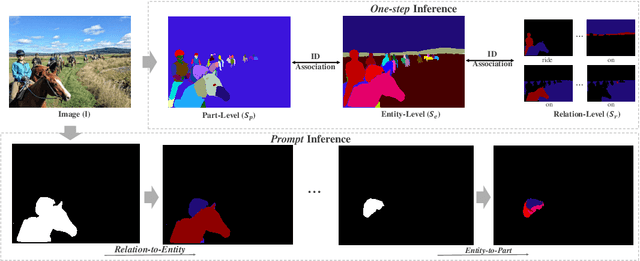

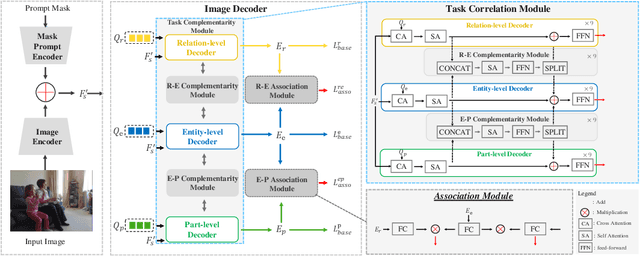

Despite the progress of image segmentation for accurate visual entity segmentation, completing the diverse requirements of image editing applications for different-level region-of-interest selections remains unsolved. In this paper, we propose a new task, All-Inclusive Multi-Level Segmentation (AIMS), which segments visual regions into three levels: part, entity, and relation (two entities with some semantic relationships). We also build a unified AIMS model through multi-dataset multi-task training to address the two major challenges of annotation inconsistency and task correlation. Specifically, we propose task complementarity, association, and prompt mask encoder for three-level predictions. Extensive experiments demonstrate the effectiveness and generalization capacity of our method compared to other state-of-the-art methods on a single dataset or the concurrent work on segmenting anything. We will make our code and training model publicly available.
Learning the Visualness of Text Using Large Vision-Language Models
May 11, 2023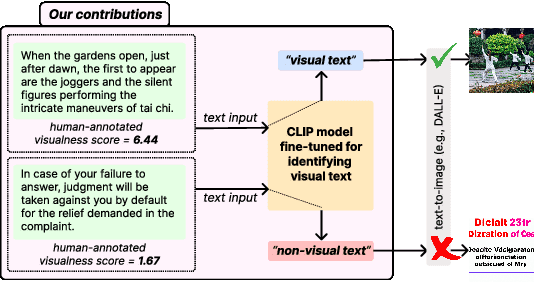

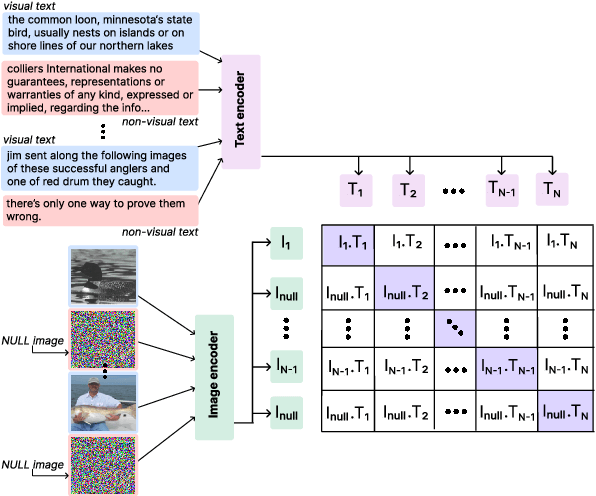
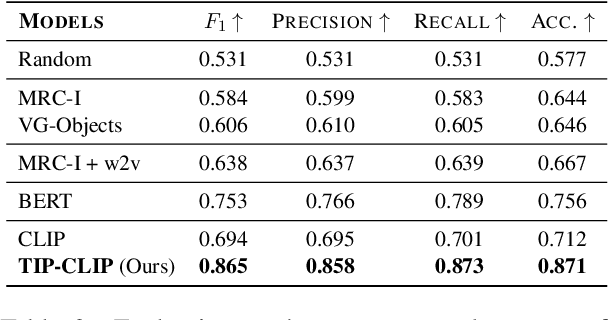
Visual text evokes an image in a person's mind, while non-visual text fails to do so. A method to automatically detect visualness in text will unlock the ability to augment text with relevant images, as neural text-to-image generation and retrieval models operate on the implicit assumption that the input text is visual in nature. We curate a dataset of 3,620 English sentences and their visualness scores provided by multiple human annotators. Additionally, we use documents that contain text and visual assets to create a distantly supervised corpus of document text and associated images. We also propose a fine-tuning strategy that adapts large vision-language models like CLIP that assume a one-to-one correspondence between text and image to the task of scoring text visualness from text input alone. Our strategy involves modifying the model's contrastive learning objective to map text identified as non-visual to a common NULL image while matching visual text to their corresponding images in the document. We evaluate the proposed approach on its ability to (i) classify visual and non-visual text accurately, and (ii) attend over words that are identified as visual in psycholinguistic studies. Empirical evaluation indicates that our approach performs better than several heuristics and baseline models for the proposed task. Furthermore, to highlight the importance of modeling the visualness of text, we conduct qualitative analyses of text-to-image generation systems like DALL-E.