 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRyan A. Rossi
Hallucination Diversity-Aware Active Learning for Text Summarization
Apr 02, 2024
Large Language Models (LLMs) have shown propensity to generate hallucinated outputs, i.e., texts that are factually incorrect or unsupported. Existing methods for alleviating hallucinations typically require costly human annotations to identify and correct hallucinations in LLM outputs. Moreover, most of these methods focus on a specific type of hallucination, e.g., entity or token errors, which limits their effectiveness in addressing various types of hallucinations exhibited in LLM outputs. To our best knowledge, in this paper we propose the first active learning framework to alleviate LLM hallucinations, reducing costly human annotations of hallucination needed. By measuring fine-grained hallucinations from errors in semantic frame, discourse and content verifiability in text summarization, we propose HAllucination Diversity-Aware Sampling (HADAS) to select diverse hallucinations for annotations in active learning for LLM finetuning. Extensive experiments on three datasets and different backbone models demonstrate advantages of our method in effectively and efficiently mitigating LLM hallucinations.
Which LLM to Play? Convergence-Aware Online Model Selection with Time-Increasing Bandits
Mar 11, 2024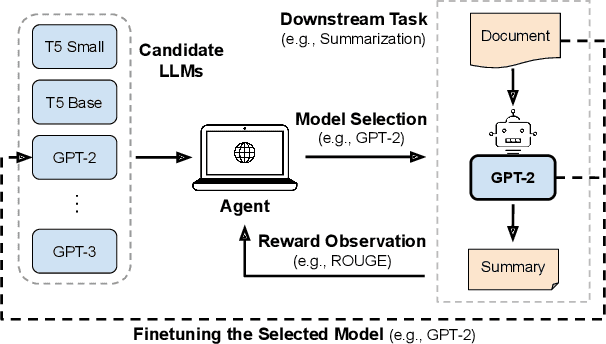
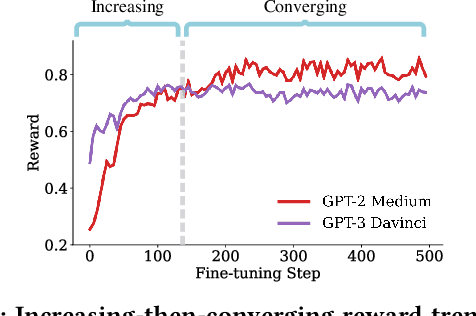
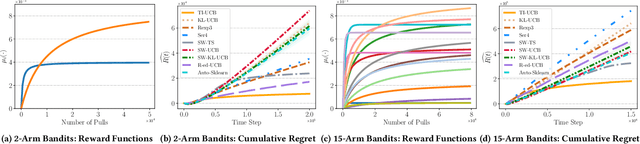
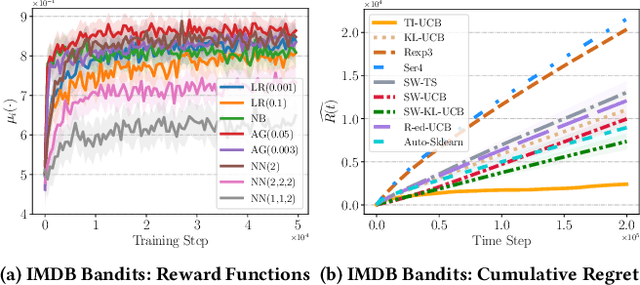
Web-based applications such as chatbots, search engines and news recommendations continue to grow in scale and complexity with the recent surge in the adoption of LLMs. Online model selection has thus garnered increasing attention due to the need to choose the best model among a diverse set while balancing task reward and exploration cost. Organizations faces decisions like whether to employ a costly API-based LLM or a locally finetuned small LLM, weighing cost against performance. Traditional selection methods often evaluate every candidate model before choosing one, which are becoming impractical given the rising costs of training and finetuning LLMs. Moreover, it is undesirable to allocate excessive resources towards exploring poor-performing models. While some recent works leverage online bandit algorithm to manage such exploration-exploitation trade-off in model selection, they tend to overlook the increasing-then-converging trend in model performances as the model is iteratively finetuned, leading to less accurate predictions and suboptimal model selections. In this paper, we propose a time-increasing bandit algorithm TI-UCB, which effectively predicts the increase of model performances due to finetuning and efficiently balances exploration and exploitation in model selection. To further capture the converging points of models, we develop a change detection mechanism by comparing consecutive increase predictions. We theoretically prove that our algorithm achieves a logarithmic regret upper bound in a typical increasing bandit setting, which implies a fast convergence rate. The advantage of our method is also empirically validated through extensive experiments on classification model selection and online selection of LLMs. Our results highlight the importance of utilizing increasing-then-converging pattern for more efficient and economic model selection in the deployment of LLMs.
Learning to Reduce: Optimal Representations of Structured Data in Prompting Large Language Models
Feb 22, 2024Large Language Models (LLMs) have been widely used as general-purpose AI agents showing comparable performance on many downstream tasks. However, existing work shows that it is challenging for LLMs to integrate structured data (e.g. KG, tables, DBs) into their prompts; LLMs need to either understand long text data or select the most relevant evidence prior to inference, and both approaches are not trivial. In this paper, we propose a framework, Learning to Reduce, that fine-tunes a language model to generate a reduced version of an input context, given a task description and context input. The model learns to reduce the input context using On-Policy Reinforcement Learning and aims to improve the reasoning performance of a fixed LLM. Experimental results illustrate that our model not only achieves comparable accuracies in selecting the relevant evidence from an input context, but also shows generalizability on different datasets. We further show that our model helps improve the LLM's performance on downstream tasks especially when the context is long.
Delivery Optimized Discovery in Behavioral User Segmentation under Budget Constrain
Feb 04, 2024Users' behavioral footprints online enable firms to discover behavior-based user segments (or, segments) and deliver segment specific messages to users. Following the discovery of segments, delivery of messages to users through preferred media channels like Facebook and Google can be challenging, as only a portion of users in a behavior segment find match in a medium, and only a fraction of those matched actually see the message (exposure). Even high quality discovery becomes futile when delivery fails. Many sophisticated algorithms exist for discovering behavioral segments; however, these ignore the delivery component. The problem is compounded because (i) the discovery is performed on the behavior data space in firms' data (e.g., user clicks), while the delivery is predicated on the static data space (e.g., geo, age) as defined by media; and (ii) firms work under budget constraint. We introduce a stochastic optimization based algorithm for delivery optimized discovery of behavioral user segmentation and offer new metrics to address the joint optimization. We leverage optimization under a budget constraint for delivery combined with a learning-based component for discovery. Extensive experiments on a public dataset from Google and a proprietary dataset show the effectiveness of our approach by simultaneously improving delivery metrics, reducing budget spend and achieving strong predictive performance in discovery.
Self-Debiasing Large Language Models: Zero-Shot Recognition and Reduction of Stereotypes
Feb 03, 2024Large language models (LLMs) have shown remarkable advances in language generation and understanding but are also prone to exhibiting harmful social biases. While recognition of these behaviors has generated an abundance of bias mitigation techniques, most require modifications to the training data, model parameters, or decoding strategy, which may be infeasible without access to a trainable model. In this work, we leverage the zero-shot capabilities of LLMs to reduce stereotyping in a technique we introduce as zero-shot self-debiasing. With two approaches, self-debiasing via explanation and self-debiasing via reprompting, we show that self-debiasing can significantly reduce the degree of stereotyping across nine different social groups while relying only on the LLM itself and a simple prompt, with explanations correctly identifying invalid assumptions and reprompting delivering the greatest reductions in bias. We hope this work opens inquiry into other zero-shot techniques for bias mitigation.
ToolChain*: Efficient Action Space Navigation in Large Language Models with A* Search
Oct 20, 2023

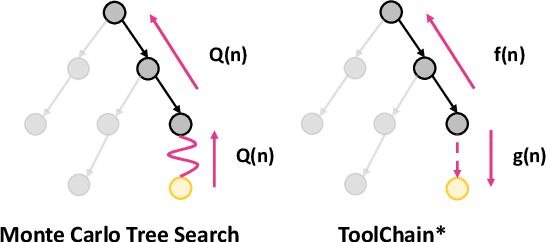
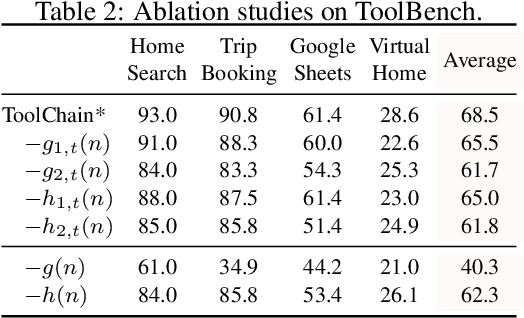
Large language models (LLMs) have demonstrated powerful decision-making and planning capabilities in solving complicated real-world problems. LLM-based autonomous agents can interact with diverse tools (e.g., functional APIs) and generate solution plans that execute a series of API function calls in a step-by-step manner. The multitude of candidate API function calls significantly expands the action space, amplifying the critical need for efficient action space navigation. However, existing methods either struggle with unidirectional exploration in expansive action spaces, trapped into a locally optimal solution, or suffer from exhaustively traversing all potential actions, causing inefficient navigation. To address these issues, we propose ToolChain*, an efficient tree search-based planning algorithm for LLM-based agents. It formulates the entire action space as a decision tree, where each node represents a possible API function call involved in a solution plan. By incorporating the A* search algorithm with task-specific cost function design, it efficiently prunes high-cost branches that may involve incorrect actions, identifying the most low-cost valid path as the solution. Extensive experiments on multiple tool-use and reasoning tasks demonstrate that ToolChain* efficiently balances exploration and exploitation within an expansive action space. It outperforms state-of-the-art baselines on planning and reasoning tasks by 3.1% and 3.5% on average while requiring 7.35x and 2.31x less time, respectively.
CulturaX: A Cleaned, Enormous, and Multilingual Dataset for Large Language Models in 167 Languages
Sep 17, 2023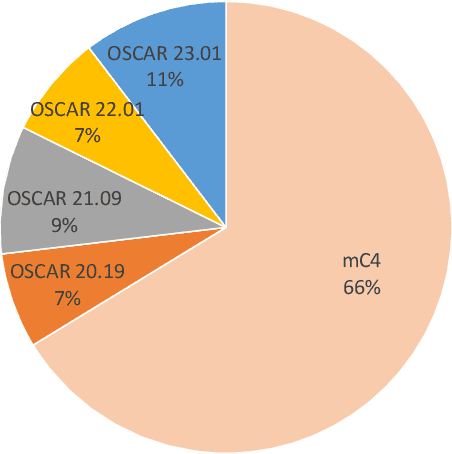

The driving factors behind the development of large language models (LLMs) with impressive learning capabilities are their colossal model sizes and extensive training datasets. Along with the progress in natural language processing, LLMs have been frequently made accessible to the public to foster deeper investigation and applications. However, when it comes to training datasets for these LLMs, especially the recent state-of-the-art models, they are often not fully disclosed. Creating training data for high-performing LLMs involves extensive cleaning and deduplication to ensure the necessary level of quality. The lack of transparency for training data has thus hampered research on attributing and addressing hallucination and bias issues in LLMs, hindering replication efforts and further advancements in the community. These challenges become even more pronounced in multilingual learning scenarios, where the available multilingual text datasets are often inadequately collected and cleaned. Consequently, there is a lack of open-source and readily usable dataset to effectively train LLMs in multiple languages. To overcome this issue, we present CulturaX, a substantial multilingual dataset with 6.3 trillion tokens in 167 languages, tailored for LLM development. Our dataset undergoes meticulous cleaning and deduplication through a rigorous pipeline of multiple stages to accomplish the best quality for model training, including language identification, URL-based filtering, metric-based cleaning, document refinement, and data deduplication. CulturaX is fully released to the public in HuggingFace to facilitate research and advancements in multilingual LLMs: https://huggingface.co/datasets/uonlp/CulturaX.
PDFTriage: Question Answering over Long, Structured Documents
Sep 16, 2023

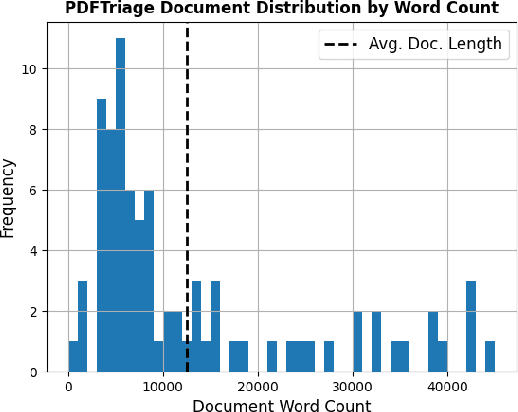

Large Language Models (LLMs) have issues with document question answering (QA) in situations where the document is unable to fit in the small context length of an LLM. To overcome this issue, most existing works focus on retrieving the relevant context from the document, representing them as plain text. However, documents such as PDFs, web pages, and presentations are naturally structured with different pages, tables, sections, and so on. Representing such structured documents as plain text is incongruous with the user's mental model of these documents with rich structure. When a system has to query the document for context, this incongruity is brought to the fore, and seemingly trivial questions can trip up the QA system. To bridge this fundamental gap in handling structured documents, we propose an approach called PDFTriage that enables models to retrieve the context based on either structure or content. Our experiments demonstrate the effectiveness of the proposed PDFTriage-augmented models across several classes of questions where existing retrieval-augmented LLMs fail. To facilitate further research on this fundamental problem, we release our benchmark dataset consisting of 900+ human-generated questions over 80 structured documents from 10 different categories of question types for document QA.
Bias and Fairness in Large Language Models: A Survey
Sep 02, 2023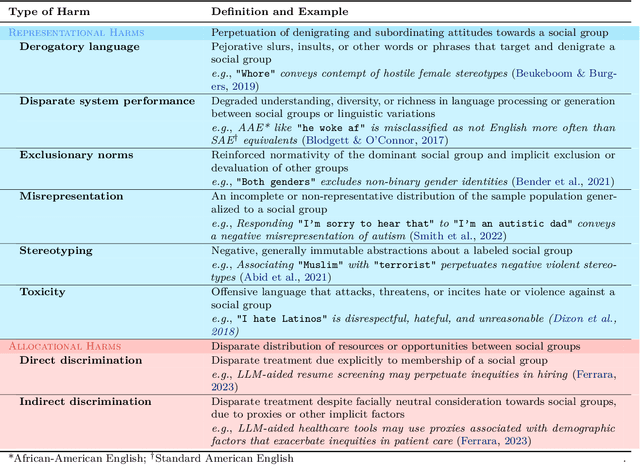
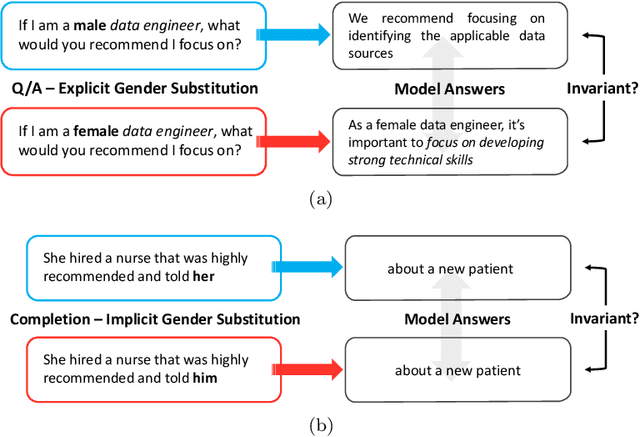
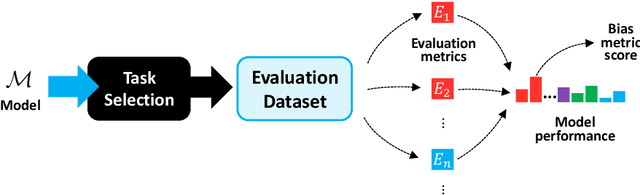
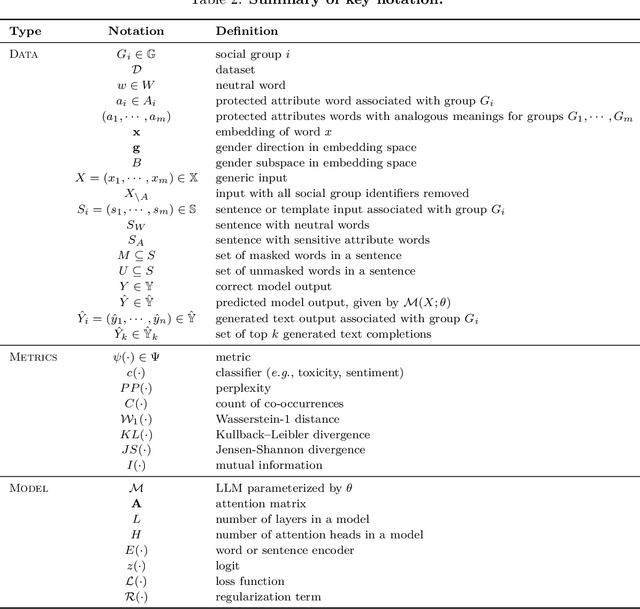
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Knowledge Graph Prompting for Multi-Document Question Answering
Aug 22, 2023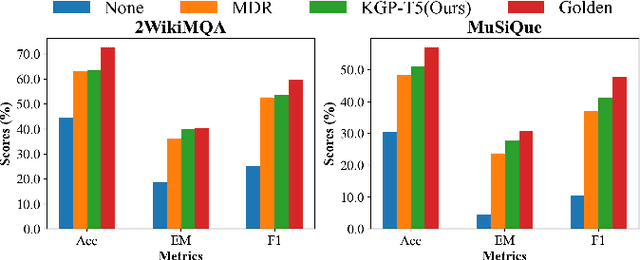
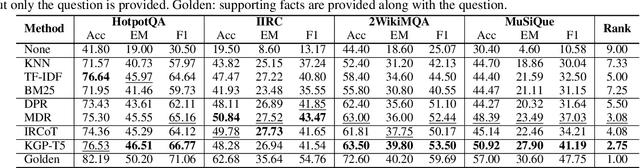
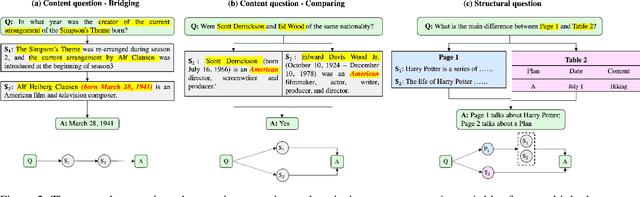
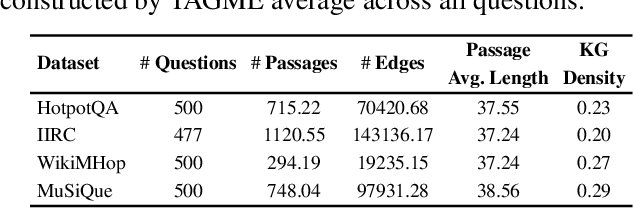
The 'pre-train, prompt, predict' paradigm of large language models (LLMs) has achieved remarkable success in open-domain question answering (OD-QA). However, few works explore this paradigm in the scenario of multi-document question answering (MD-QA), a task demanding a thorough understanding of the logical associations among the contents and structures of different documents. To fill this crucial gap, we propose a Knowledge Graph Prompting (KGP) method to formulate the right context in prompting LLMs for MD-QA, which consists of a graph construction module and a graph traversal module. For graph construction, we create a knowledge graph (KG) over multiple documents with nodes symbolizing passages or document structures (e.g., pages/tables), and edges denoting the semantic/lexical similarity between passages or intra-document structural relations. For graph traversal, we design an LM-guided graph traverser that navigates across nodes and gathers supporting passages assisting LLMs in MD-QA. The constructed graph serves as the global ruler that regulates the transitional space among passages and reduces retrieval latency. Concurrently, the LM-guided traverser acts as a local navigator that gathers pertinent context to progressively approach the question and guarantee retrieval quality. Extensive experiments underscore the efficacy of KGP for MD-QA, signifying the potential of leveraging graphs in enhancing the prompt design for LLMs. Our code is at https://github.com/YuWVandy/KG-LLM-MDQA.