 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSungchul Kim
Hallucination Diversity-Aware Active Learning for Text Summarization
Apr 02, 2024
Large Language Models (LLMs) have shown propensity to generate hallucinated outputs, i.e., texts that are factually incorrect or unsupported. Existing methods for alleviating hallucinations typically require costly human annotations to identify and correct hallucinations in LLM outputs. Moreover, most of these methods focus on a specific type of hallucination, e.g., entity or token errors, which limits their effectiveness in addressing various types of hallucinations exhibited in LLM outputs. To our best knowledge, in this paper we propose the first active learning framework to alleviate LLM hallucinations, reducing costly human annotations of hallucination needed. By measuring fine-grained hallucinations from errors in semantic frame, discourse and content verifiability in text summarization, we propose HAllucination Diversity-Aware Sampling (HADAS) to select diverse hallucinations for annotations in active learning for LLM finetuning. Extensive experiments on three datasets and different backbone models demonstrate advantages of our method in effectively and efficiently mitigating LLM hallucinations.
SciCapenter: Supporting Caption Composition for Scientific Figures with Machine-Generated Captions and Ratings
Mar 26, 2024
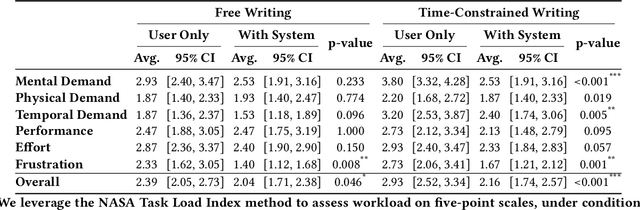

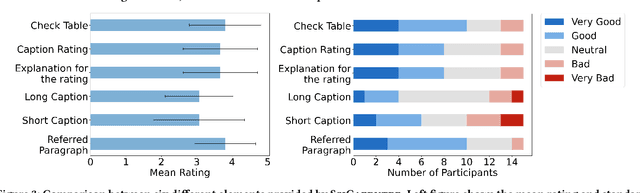
Crafting effective captions for figures is important. Readers heavily depend on these captions to grasp the figure's message. However, despite a well-developed set of AI technologies for figures and captions, these have rarely been tested for usefulness in aiding caption writing. This paper introduces SciCapenter, an interactive system that puts together cutting-edge AI technologies for scientific figure captions to aid caption composition. SciCapenter generates a variety of captions for each figure in a scholarly article, providing scores and a comprehensive checklist to assess caption quality across multiple critical aspects, such as helpfulness, OCR mention, key takeaways, and visual properties reference. Users can directly edit captions in SciCapenter, resubmit for revised evaluations, and iteratively refine them. A user study with Ph.D. students indicates that SciCapenter significantly lowers the cognitive load of caption writing. Participants' feedback further offers valuable design insights for future systems aiming to enhance caption writing.
Which LLM to Play? Convergence-Aware Online Model Selection with Time-Increasing Bandits
Mar 11, 2024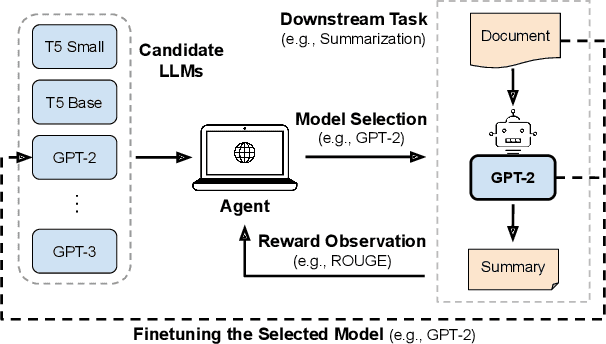
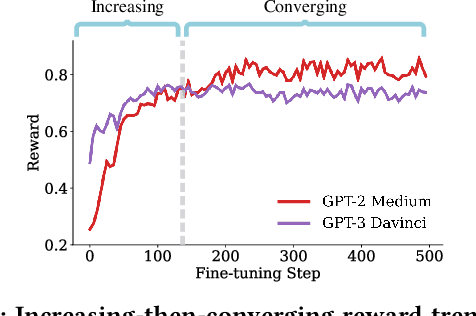
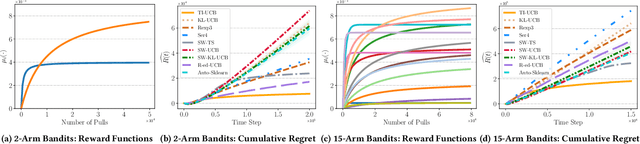
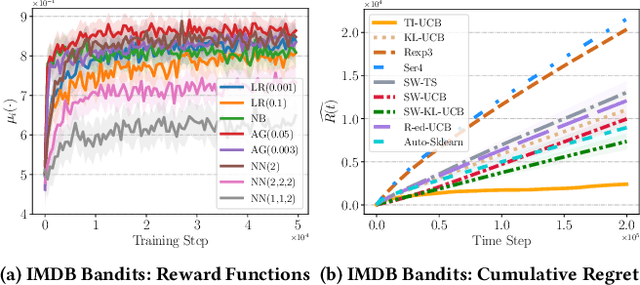
Web-based applications such as chatbots, search engines and news recommendations continue to grow in scale and complexity with the recent surge in the adoption of LLMs. Online model selection has thus garnered increasing attention due to the need to choose the best model among a diverse set while balancing task reward and exploration cost. Organizations faces decisions like whether to employ a costly API-based LLM or a locally finetuned small LLM, weighing cost against performance. Traditional selection methods often evaluate every candidate model before choosing one, which are becoming impractical given the rising costs of training and finetuning LLMs. Moreover, it is undesirable to allocate excessive resources towards exploring poor-performing models. While some recent works leverage online bandit algorithm to manage such exploration-exploitation trade-off in model selection, they tend to overlook the increasing-then-converging trend in model performances as the model is iteratively finetuned, leading to less accurate predictions and suboptimal model selections. In this paper, we propose a time-increasing bandit algorithm TI-UCB, which effectively predicts the increase of model performances due to finetuning and efficiently balances exploration and exploitation in model selection. To further capture the converging points of models, we develop a change detection mechanism by comparing consecutive increase predictions. We theoretically prove that our algorithm achieves a logarithmic regret upper bound in a typical increasing bandit setting, which implies a fast convergence rate. The advantage of our method is also empirically validated through extensive experiments on classification model selection and online selection of LLMs. Our results highlight the importance of utilizing increasing-then-converging pattern for more efficient and economic model selection in the deployment of LLMs.
Learning to Reduce: Optimal Representations of Structured Data in Prompting Large Language Models
Feb 22, 2024Large Language Models (LLMs) have been widely used as general-purpose AI agents showing comparable performance on many downstream tasks. However, existing work shows that it is challenging for LLMs to integrate structured data (e.g. KG, tables, DBs) into their prompts; LLMs need to either understand long text data or select the most relevant evidence prior to inference, and both approaches are not trivial. In this paper, we propose a framework, Learning to Reduce, that fine-tunes a language model to generate a reduced version of an input context, given a task description and context input. The model learns to reduce the input context using On-Policy Reinforcement Learning and aims to improve the reasoning performance of a fixed LLM. Experimental results illustrate that our model not only achieves comparable accuracies in selecting the relevant evidence from an input context, but also shows generalizability on different datasets. We further show that our model helps improve the LLM's performance on downstream tasks especially when the context is long.
Self-Debiasing Large Language Models: Zero-Shot Recognition and Reduction of Stereotypes
Feb 03, 2024Large language models (LLMs) have shown remarkable advances in language generation and understanding but are also prone to exhibiting harmful social biases. While recognition of these behaviors has generated an abundance of bias mitigation techniques, most require modifications to the training data, model parameters, or decoding strategy, which may be infeasible without access to a trainable model. In this work, we leverage the zero-shot capabilities of LLMs to reduce stereotyping in a technique we introduce as zero-shot self-debiasing. With two approaches, self-debiasing via explanation and self-debiasing via reprompting, we show that self-debiasing can significantly reduce the degree of stereotyping across nine different social groups while relying only on the LLM itself and a simple prompt, with explanations correctly identifying invalid assumptions and reprompting delivering the greatest reductions in bias. We hope this work opens inquiry into other zero-shot techniques for bias mitigation.
Augment before You Try: Knowledge-Enhanced Table Question Answering via Table Expansion
Jan 28, 2024Table question answering is a popular task that assesses a model's ability to understand and interact with structured data. However, the given table often does not contain sufficient information for answering the question, necessitating the integration of external knowledge. Existing methods either convert both the table and external knowledge into text, which neglects the structured nature of the table; or they embed queries for external sources in the interaction with the table, which complicates the process. In this paper, we propose a simple yet effective method to integrate external information in a given table. Our method first constructs an augmenting table containing the missing information and then generates a SQL query over the two tables to answer the question. Experiments show that our method outperforms strong baselines on three table QA benchmarks. Our code is publicly available at https://github.com/UCSB-NLP-Chang/Augment_tableQA.
Leveraging Graph Diffusion Models for Network Refinement Tasks
Nov 29, 2023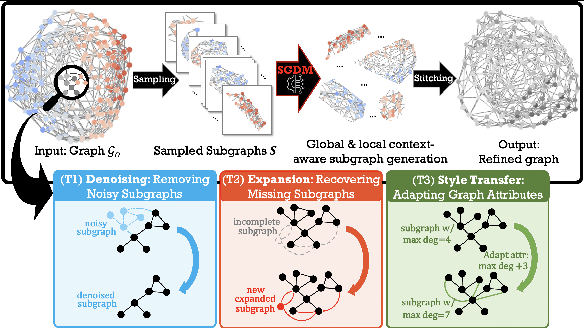
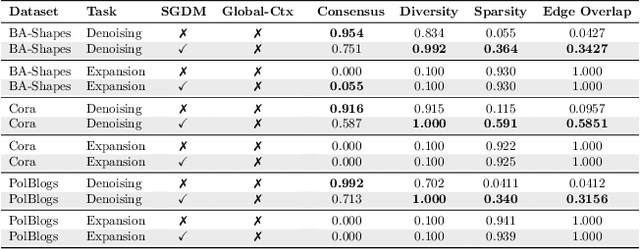
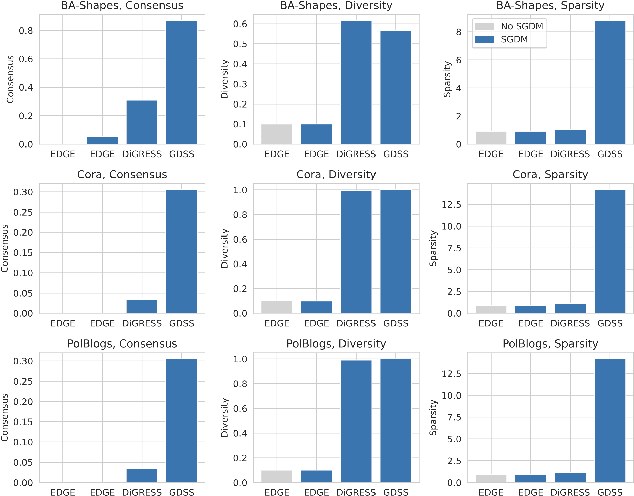
Most real-world networks are noisy and incomplete samples from an unknown target distribution. Refining them by correcting corruptions or inferring unobserved regions typically improves downstream performance. Inspired by the impressive generative capabilities that have been used to correct corruptions in images, and the similarities between "in-painting" and filling in missing nodes and edges conditioned on the observed graph, we propose a novel graph generative framework, SGDM, which is based on subgraph diffusion. Our framework not only improves the scalability and fidelity of graph diffusion models, but also leverages the reverse process to perform novel, conditional generation tasks. In particular, through extensive empirical analysis and a set of novel metrics, we demonstrate that our proposed model effectively supports the following refinement tasks for partially observable networks: T1: denoising extraneous subgraphs, T2: expanding existing subgraphs and T3: performing "style" transfer by regenerating a particular subgraph to match the characteristics of a different node or subgraph.
GPT-4 as an Effective Zero-Shot Evaluator for Scientific Figure Captions
Oct 23, 2023There is growing interest in systems that generate captions for scientific figures. However, assessing these systems output poses a significant challenge. Human evaluation requires academic expertise and is costly, while automatic evaluation depends on often low-quality author-written captions. This paper investigates using large language models (LLMs) as a cost-effective, reference-free method for evaluating figure captions. We first constructed SCICAP-EVAL, a human evaluation dataset that contains human judgments for 3,600 scientific figure captions, both original and machine-made, for 600 arXiv figures. We then prompted LLMs like GPT-4 and GPT-3 to score (1-6) each caption based on its potential to aid reader understanding, given relevant context such as figure-mentioning paragraphs. Results show that GPT-4, used as a zero-shot evaluator, outperformed all other models and even surpassed assessments made by Computer Science and Informatics undergraduates, achieving a Kendall correlation score of 0.401 with Ph.D. students rankings
Bias and Fairness in Large Language Models: A Survey
Sep 02, 2023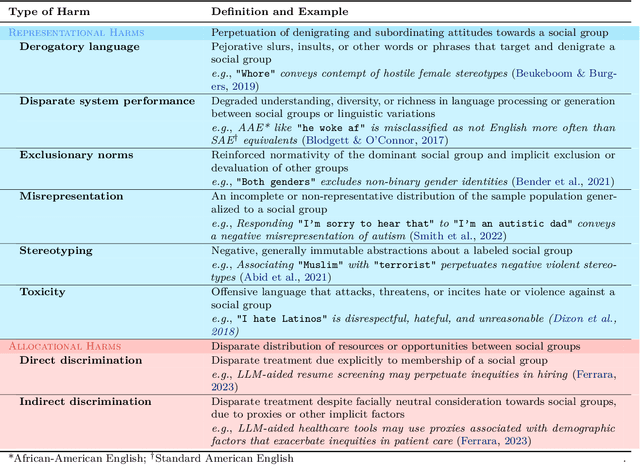
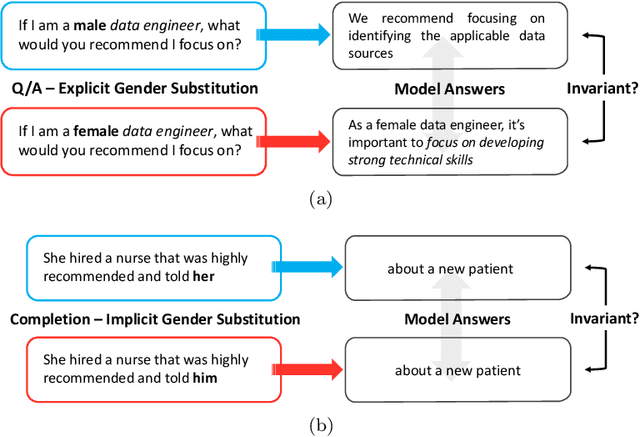
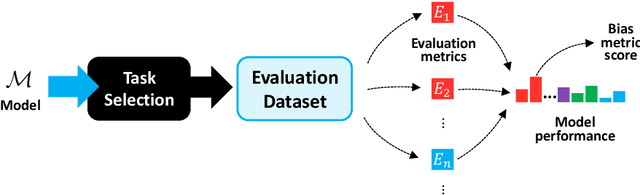
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
FigCaps-HF: A Figure-to-Caption Generative Framework and Benchmark with Human Feedback
Jul 20, 2023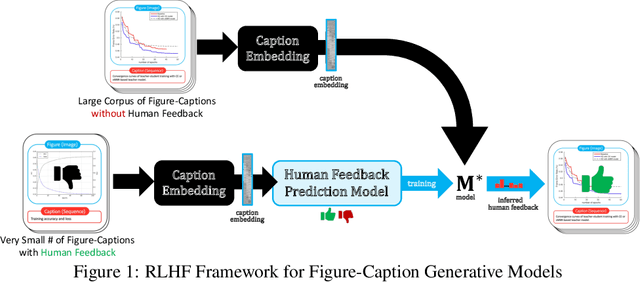
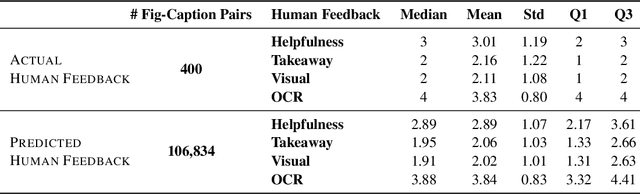
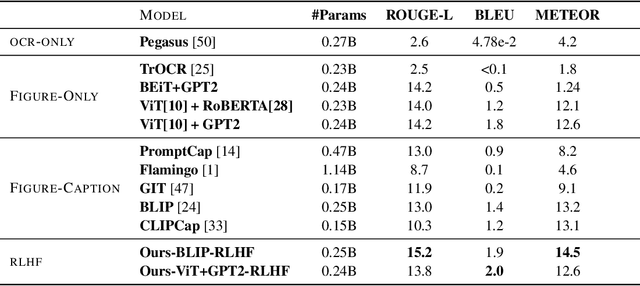
Captions are crucial for understanding scientific visualizations and documents. Existing captioning methods for scientific figures rely on figure-caption pairs extracted from documents for training, many of which fall short with respect to metrics like helpfulness, explainability, and visual-descriptiveness [15] leading to generated captions being misaligned with reader preferences. To enable the generation of high-quality figure captions, we introduce FigCaps-HF a new framework for figure-caption generation that can incorporate domain expert feedback in generating captions optimized for reader preferences. Our framework comprises of 1) an automatic method for evaluating quality of figure-caption pairs, 2) a novel reinforcement learning with human feedback (RLHF) method to optimize a generative figure-to-caption model for reader preferences. We demonstrate the effectiveness of our simple learning framework by improving performance over standard fine-tuning across different types of models. In particular, when using BLIP as the base model, our RLHF framework achieves a mean gain of 35.7%, 16.9%, and 9% in ROUGE, BLEU, and Meteor, respectively. Finally, we release a large-scale benchmark dataset with human feedback on figure-caption pairs to enable further evaluation and development of RLHF techniques for this problem.