 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXu Liu
Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing
May 07, 2024
Existing diffusion-based video editing methods have achieved impressive results in motion editing. Most of the existing methods focus on the motion alignment between the edited video and the reference video. However, these methods do not constrain the background and object content of the video to remain unchanged, which makes it possible for users to generate unexpected videos. In this paper, we propose a one-shot video motion editing method called Edit-Your-Motion that requires only a single text-video pair for training. Specifically, we design the Detailed Prompt-Guided Learning Strategy (DPL) to decouple spatio-temporal features in space-time diffusion models. DPL separates learning object content and motion into two training stages. In the first training stage, we focus on learning the spatial features (the features of object content) and breaking down the temporal relationships in the video frames by shuffling them. We further propose Recurrent-Causal Attention (RC-Attn) to learn the consistent content features of the object from unordered video frames. In the second training stage, we restore the temporal relationship in video frames to learn the temporal feature (the features of the background and object's motion). We also adopt the Noise Constraint Loss to smooth out inter-frame differences. Finally, in the inference stage, we inject the content features of the source object into the editing branch through a two-branch structure (editing branch and reconstruction branch). With Edit-Your-Motion, users can edit the motion of objects in the source video to generate more exciting and diverse videos. Comprehensive qualitative experiments, quantitative experiments and user preference studies demonstrate that Edit-Your-Motion performs better than other methods.
Exploring Beyond Logits: Hierarchical Dynamic Labeling Based on Embeddings for Semi-Supervised Classification
Apr 26, 2024In semi-supervised learning, methods that rely on confidence learning to generate pseudo-labels have been widely proposed. However, increasing research finds that when faced with noisy and biased data, the model's representation network is more reliable than the classification network. Additionally, label generation methods based on model predictions often show poor adaptability across different datasets, necessitating customization of the classification network. Therefore, we propose a Hierarchical Dynamic Labeling (HDL) algorithm that does not depend on model predictions and utilizes image embeddings to generate sample labels. We also introduce an adaptive method for selecting hyperparameters in HDL, enhancing its versatility. Moreover, HDL can be combined with general image encoders (e.g., CLIP) to serve as a fundamental data processing module. We extract embeddings from datasets with class-balanced and long-tailed distributions using pre-trained semi-supervised models. Subsequently, samples are re-labeled using HDL, and the re-labeled samples are used to further train the semi-supervised models. Experiments demonstrate improved model performance, validating the motivation that representation networks are more reliable than classifiers or predictors. Our approach has the potential to change the paradigm of pseudo-label generation in semi-supervised learning.
Beyond Chain-of-Thought: A Survey of Chain-of-X Paradigms for LLMs
Apr 24, 2024Chain-of-Thought (CoT) has been a widely adopted prompting method, eliciting impressive reasoning abilities of Large Language Models (LLMs). Inspired by the sequential thought structure of CoT, a number of Chain-of-X (CoX) methods have been developed to address various challenges across diverse domains and tasks involving LLMs. In this paper, we provide a comprehensive survey of Chain-of-X methods for LLMs in different contexts. Specifically, we categorize them by taxonomies of nodes, i.e., the X in CoX, and application tasks. We also discuss the findings and implications of existing CoX methods, as well as potential future directions. Our survey aims to serve as a detailed and up-to-date resource for researchers seeking to apply the idea of CoT to broader scenarios.
Unveiling and Mitigating Generalized Biases of DNNs through the Intrinsic Dimensions of Perceptual Manifolds
Apr 22, 2024Building fair deep neural networks (DNNs) is a crucial step towards achieving trustworthy artificial intelligence. Delving into deeper factors that affect the fairness of DNNs is paramount and serves as the foundation for mitigating model biases. However, current methods are limited in accurately predicting DNN biases, relying solely on the number of training samples and lacking more precise measurement tools. Here, we establish a geometric perspective for analyzing the fairness of DNNs, comprehensively exploring how DNNs internally shape the intrinsic geometric characteristics of datasets-the intrinsic dimensions (IDs) of perceptual manifolds, and the impact of IDs on the fairness of DNNs. Based on multiple findings, we propose Intrinsic Dimension Regularization (IDR), which enhances the fairness and performance of models by promoting the learning of concise and ID-balanced class perceptual manifolds. In various image recognition benchmark tests, IDR significantly mitigates model bias while improving its performance.
Low-rank Adaptation for Spatio-Temporal Forecasting
Apr 11, 2024Spatio-temporal forecasting is crucial in real-world dynamic systems, predicting future changes using historical data from diverse locations. Existing methods often prioritize the development of intricate neural networks to capture the complex dependencies of the data, yet their accuracy fails to show sustained improvement. Besides, these methods also overlook node heterogeneity, hindering customized prediction modules from handling diverse regional nodes effectively. In this paper, our goal is not to propose a new model but to present a novel low-rank adaptation framework as an off-the-shelf plugin for existing spatial-temporal prediction models, termed ST-LoRA, which alleviates the aforementioned problems through node-level adjustments. Specifically, we first tailor a node adaptive low-rank layer comprising multiple trainable low-rank matrices. Additionally, we devise a multi-layer residual fusion stacking module, injecting the low-rank adapters into predictor modules of various models. Across six real-world traffic datasets and six different types of spatio-temporal prediction models, our approach minimally increases the parameters and training time of the original models by less than 4%, still achieving consistent and sustained performance enhancement.
Hallucination Diversity-Aware Active Learning for Text Summarization
Apr 02, 2024Large Language Models (LLMs) have shown propensity to generate hallucinated outputs, i.e., texts that are factually incorrect or unsupported. Existing methods for alleviating hallucinations typically require costly human annotations to identify and correct hallucinations in LLM outputs. Moreover, most of these methods focus on a specific type of hallucination, e.g., entity or token errors, which limits their effectiveness in addressing various types of hallucinations exhibited in LLM outputs. To our best knowledge, in this paper we propose the first active learning framework to alleviate LLM hallucinations, reducing costly human annotations of hallucination needed. By measuring fine-grained hallucinations from errors in semantic frame, discourse and content verifiability in text summarization, we propose HAllucination Diversity-Aware Sampling (HADAS) to select diverse hallucinations for annotations in active learning for LLM finetuning. Extensive experiments on three datasets and different backbone models demonstrate advantages of our method in effectively and efficiently mitigating LLM hallucinations.
CACA Agent: Capability Collaboration based AI Agent
Mar 22, 2024As AI Agents based on Large Language Models (LLMs) have shown potential in practical applications across various fields, how to quickly deploy an AI agent and how to conveniently expand the application scenario of AI agents has become a challenge. Previous studies mainly focused on implementing all the reasoning capabilities of AI agents within a single LLM, which often makes the model more complex and also reduces the extensibility of AI agent functionality. In this paper, we propose CACA Agent (Capability Collaboration based AI Agent), using an open architecture inspired by service computing. CACA Agent integrates a set of collaborative capabilities to implement AI Agents, not only reducing the dependence on a single LLM, but also enhancing the extensibility of both the planning abilities and the tools available to AI agents. Utilizing the proposed system, we present a demo to illustrate the operation and the application scenario extension of CACA Agent.
Diffeomorphism Neural Operator for various domains and parameters of partial differential equations
Feb 19, 2024Many science and engineering applications demand partial differential equations (PDE) evaluations that are traditionally computed with resource-intensive numerical solvers. Neural operator models provide an efficient alternative by learning the governing physical laws directly from data in a class of PDEs with different parameters, but constrained in a fixed boundary (domain). Many applications, such as design and manufacturing, would benefit from neural operators with flexible domains when studied at scale. Here we present a diffeomorphism neural operator learning framework towards developing domain-flexible models for physical systems with various and complex domains. Specifically, a neural operator trained in a shared domain mapped from various domains of fields by diffeomorphism is proposed, which transformed the problem of learning function mappings in varying domains (spaces) into the problem of learning operators on a shared diffeomorphic domain. Meanwhile, an index is provided to evaluate the generalization of diffeomorphism neural operators in different domains by the domain diffeomorphism similarity. Experiments on statics scenarios (Darcy flow, mechanics) and dynamic scenarios (pipe flow, airfoil flow) demonstrate the advantages of our approach for neural operator learning under various domains, where harmonic and volume parameterization are used as the diffeomorphism for 2D and 3D domains. Our diffeomorphism neural operator approach enables strong learning capability and robust generalization across varying domains and parameters.
QAGait: Revisit Gait Recognition from a Quality Perspective
Jan 24, 2024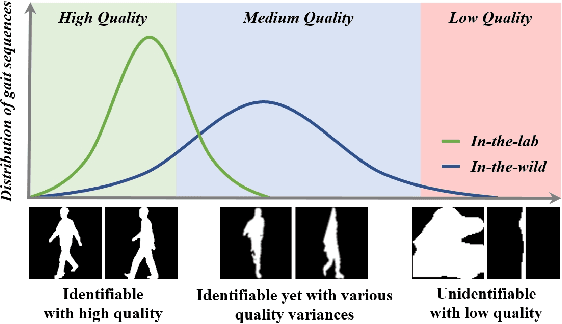
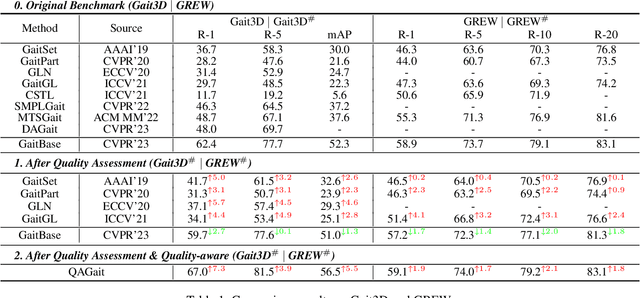
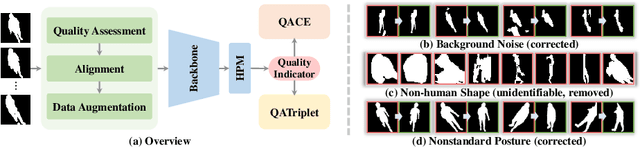
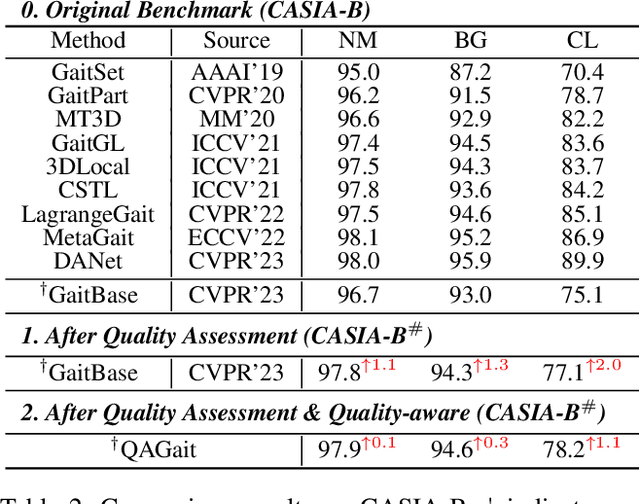
Gait recognition is a promising biometric method that aims to identify pedestrians from their unique walking patterns. Silhouette modality, renowned for its easy acquisition, simple structure, sparse representation, and convenient modeling, has been widely employed in controlled in-the-lab research. However, as gait recognition rapidly advances from in-the-lab to in-the-wild scenarios, various conditions raise significant challenges for silhouette modality, including 1) unidentifiable low-quality silhouettes (abnormal segmentation, severe occlusion, or even non-human shape), and 2) identifiable but challenging silhouettes (background noise, non-standard posture, slight occlusion). To address these challenges, we revisit gait recognition pipeline and approach gait recognition from a quality perspective, namely QAGait. Specifically, we propose a series of cost-effective quality assessment strategies, including Maxmial Connect Area and Template Match to eliminate background noises and unidentifiable silhouettes, Alignment strategy to handle non-standard postures. We also propose two quality-aware loss functions to integrate silhouette quality into optimization within the embedding space. Extensive experiments demonstrate our QAGait can guarantee both gait reliability and performance enhancement. Furthermore, our quality assessment strategies can seamlessly integrate with existing gait datasets, showcasing our superiority. Code is available at https://github.com/wzb-bupt/QAGait.
TNANet: A Temporal-Noise-Aware Neural Network for Suicidal Ideation Prediction with Noisy Physiological Data
Jan 23, 2024The robust generalization of deep learning models in the presence of inherent noise remains a significant challenge, especially when labels are subjective and noise is indiscernible in natural settings. This problem is particularly pronounced in many practical applications. In this paper, we address a special and important scenario of monitoring suicidal ideation, where time-series data, such as photoplethysmography (PPG), is susceptible to such noise. Current methods predominantly focus on image and text data or address artificially introduced noise, neglecting the complexities of natural noise in time-series analysis. To tackle this, we introduce a novel neural network model tailored for analyzing noisy physiological time-series data, named TNANet, which merges advanced encoding techniques with confidence learning, enhancing prediction accuracy. Another contribution of our work is the collection of a specialized dataset of PPG signals derived from real-world environments for suicidal ideation prediction. Employing this dataset, our TNANet achieves the prediction accuracy of 63.33% in a binary classification task, outperforming state-of-the-art models. Furthermore, comprehensive evaluations were conducted on three other well-known public datasets with artificially introduced noise to rigorously test the TNANet's capabilities. These tests consistently demonstrated TNANet's superior performance by achieving an accuracy improvement of more than 10% compared to baseline methods.