 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuyuan Yang
Heterogeneous Network Based Contrastive Learning Method for PolSAR Land Cover Classification
Mar 29, 2024

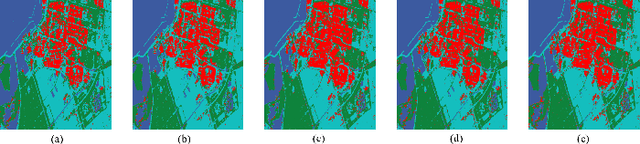
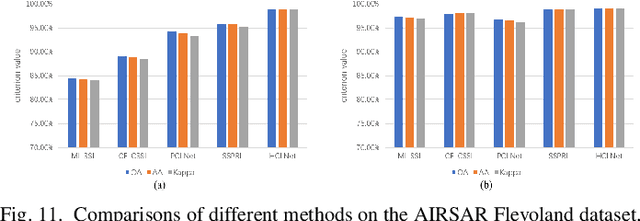

Polarimetric synthetic aperture radar (PolSAR) image interpretation is widely used in various fields. Recently, deep learning has made significant progress in PolSAR image classification. Supervised learning (SL) requires a large amount of labeled PolSAR data with high quality to achieve better performance, however, manually labeled data is insufficient. This causes the SL to fail into overfitting and degrades its generalization performance. Furthermore, the scattering confusion problem is also a significant challenge that attracts more attention. To solve these problems, this article proposes a Heterogeneous Network based Contrastive Learning method(HCLNet). It aims to learn high-level representation from unlabeled PolSAR data for few-shot classification according to multi-features and superpixels. Beyond the conventional CL, HCLNet introduces the heterogeneous architecture for the first time to utilize heterogeneous PolSAR features better. And it develops two easy-to-use plugins to narrow the domain gap between optics and PolSAR, including feature filter and superpixel-based instance discrimination, which the former is used to enhance the complementarity of multi-features, and the latter is used to increase the diversity of negative samples. Experiments demonstrate the superiority of HCLNet on three widely used PolSAR benchmark datasets compared with state-of-the-art methods. Ablation studies also verify the importance of each component. Besides, this work has implications for how to efficiently utilize the multi-features of PolSAR data to learn better high-level representation in CL and how to construct networks suitable for PolSAR data better.
Vision-Based Force Estimation for Minimally Invasive Telesurgery Through Contact Detection and Local Stiffness Models
Mar 27, 2024In minimally invasive telesurgery, obtaining accurate force information is difficult due to the complexities of in-vivo end effector force sensing. This constrains development and implementation of haptic feedback and force-based automated performance metrics, respectively. Vision-based force sensing approaches using deep learning are a promising alternative to intrinsic end effector force sensing. However, they have limited ability to generalize to novel scenarios, and require learning on high-quality force sensor training data that can be difficult to obtain. To address these challenges, this paper presents a novel vision-based contact-conditional approach for force estimation in telesurgical environments. Our method leverages supervised learning with human labels and end effector position data to train deep neural networks. Predictions from these trained models are optionally combined with robot joint torque information to estimate forces indirectly from visual data. We benchmark our method against ground truth force sensor data and demonstrate generality by fine-tuning to novel surgical scenarios in a data-efficient manner. Our methods demonstrated greater than 90% accuracy on contact detection and less than 10% force prediction error. These results suggest potential usefulness of contact-conditional force estimation for sensory substitution haptic feedback and tissue handling skill evaluation in clinical settings.
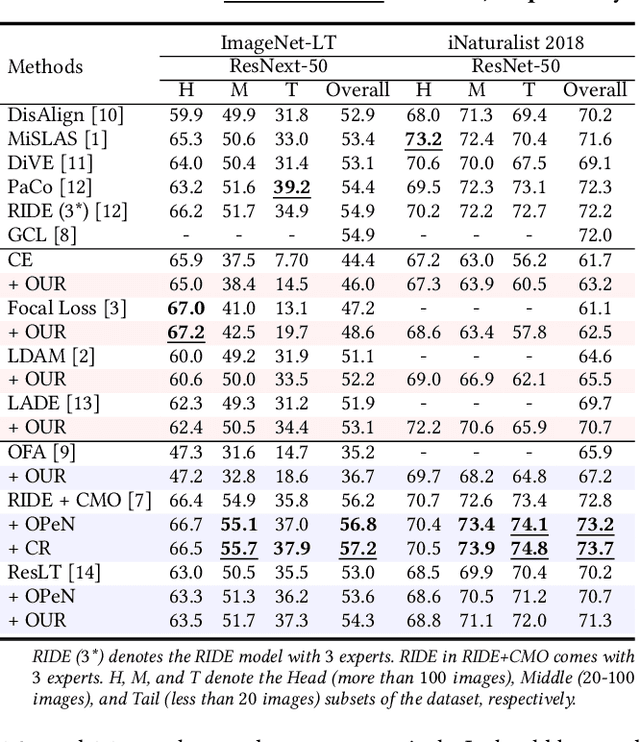
Geometric Prior Guided Feature Representation Learning for Long-Tailed Classification
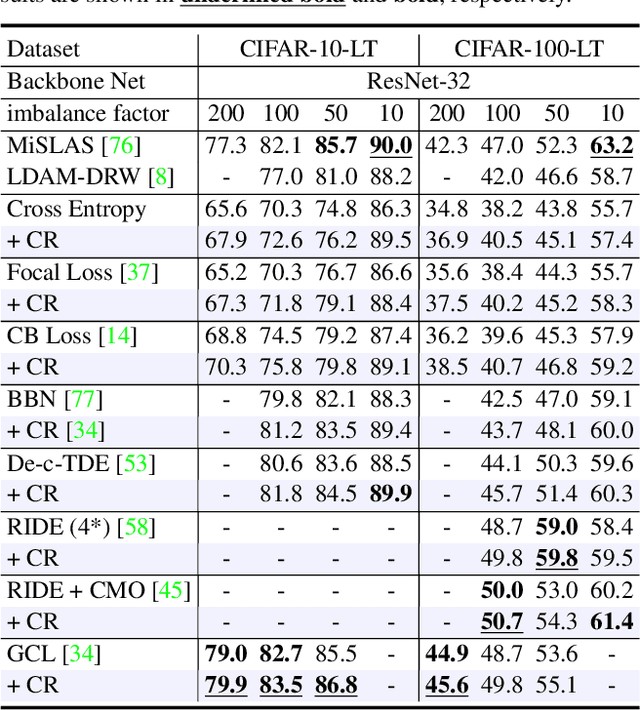
Jan 21, 2024Real-world data are long-tailed, the lack of tail samples leads to a significant limitation in the generalization ability of the model. Although numerous approaches of class re-balancing perform well for moderate class imbalance problems, additional knowledge needs to be introduced to help the tail class recover the underlying true distribution when the observed distribution from a few tail samples does not represent its true distribution properly, thus allowing the model to learn valuable information outside the observed domain. In this work, we propose to leverage the geometric information of the feature distribution of the well-represented head class to guide the model to learn the underlying distribution of the tail class. Specifically, we first systematically define the geometry of the feature distribution and the similarity measures between the geometries, and discover four phenomena regarding the relationship between the geometries of different feature distributions. Then, based on four phenomena, feature uncertainty representation is proposed to perturb the tail features by utilizing the geometry of the head class feature distribution. It aims to make the perturbed features cover the underlying distribution of the tail class as much as possible, thus improving the model's generalization performance in the test domain. Finally, we design a three-stage training scheme enabling feature uncertainty modeling to be successfully applied. Experiments on CIFAR-10/100-LT, ImageNet-LT, and iNaturalist2018 show that our proposed approach outperforms other similar methods on most metrics. In addition, the experimental phenomena we discovered are able to provide new perspectives and theoretical foundations for subsequent studies.
A match made in consistency heaven: when large language models meet evolutionary algorithms
Jan 19, 2024Pre-trained large language models (LLMs) have powerful capabilities for generating creative natural text. Evolutionary algorithms (EAs) can discover diverse solutions to complex real-world problems. Motivated by the common collective and directionality of text sequence generation and evolution, this paper illustrates the strong consistency of LLMs and EAs, which includes multiple one-to-one key characteristics: token embedding and genotype-phenotype mapping, position encoding and fitness shaping, position embedding and selection, attention and crossover, feed-forward neural network and mutation, model training and parameter update, and multi-task learning and multi-objective optimization. Based on this consistency perspective, existing coupling studies are analyzed, including evolutionary fine-tuning and LLM-enhanced EAs. Leveraging these insights, we outline a fundamental roadmap for future research in coupling LLMs and EAs, while highlighting key challenges along the way. The consistency not only reveals the evolution mechanism behind LLMs but also facilitates the development of evolved artificial agents that approach or surpass biological organisms.
Data-Centric Long-Tailed Image Recognition
Nov 03, 2023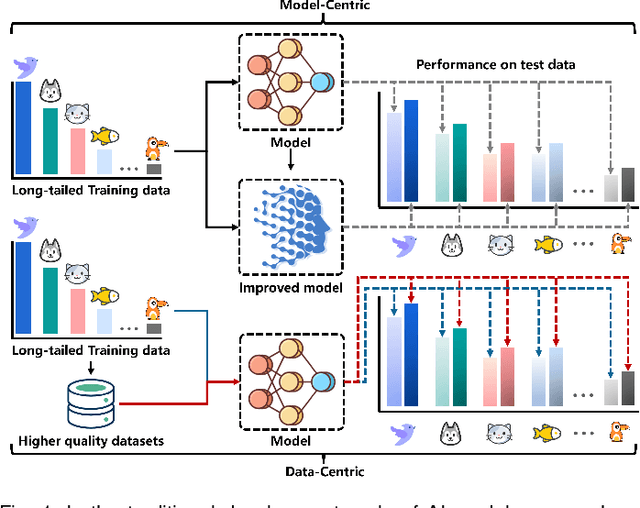
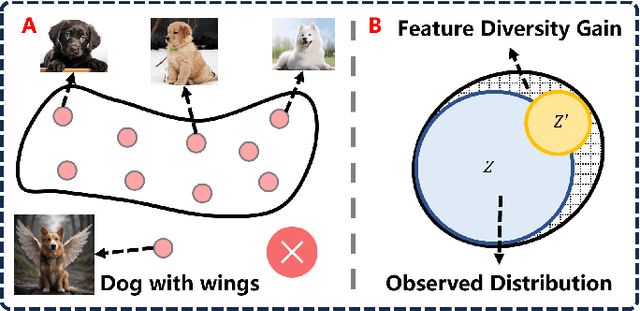
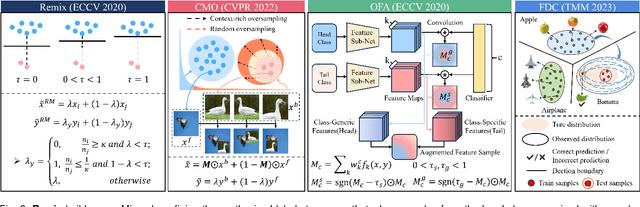
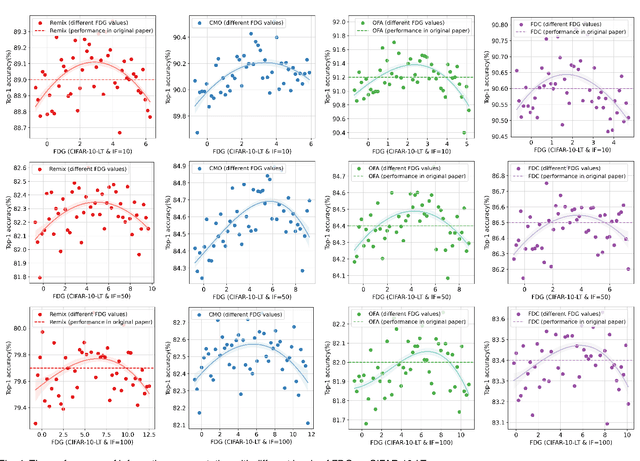
In the context of the long-tail scenario, models exhibit a strong demand for high-quality data. Data-centric approaches aim to enhance both the quantity and quality of data to improve model performance. Among these approaches, information augmentation has been progressively introduced as a crucial category. It achieves a balance in model performance by augmenting the richness and quantity of samples in the tail classes. However, there is currently a lack of research into the underlying mechanisms explaining the effectiveness of information augmentation methods. Consequently, the utilization of information augmentation in long-tail recognition tasks relies heavily on empirical and intricate fine-tuning. This work makes two primary contributions. Firstly, we approach the problem from the perspectives of feature diversity and distribution shift, introducing the concept of Feature Diversity Gain (FDG) to elucidate why information augmentation is effective. We find that the performance of information augmentation can be explained by FDG, and its performance peaks when FDG achieves an appropriate balance. Experimental results demonstrate that by using FDG to select augmented data, we can further enhance model performance without the need for any modifications to the model's architecture. Thus, data-centric approaches hold significant potential in the field of long-tail recognition, beyond the development of new model structures. Furthermore, we systematically introduce the core components and fundamental tasks of a data-centric long-tail learning framework for the first time. These core components guide the implementation and deployment of the system, while the corresponding fundamental tasks refine and expand the research area.
Orthogonal Uncertainty Representation of Data Manifold for Robust Long-Tailed Learning
Oct 16, 2023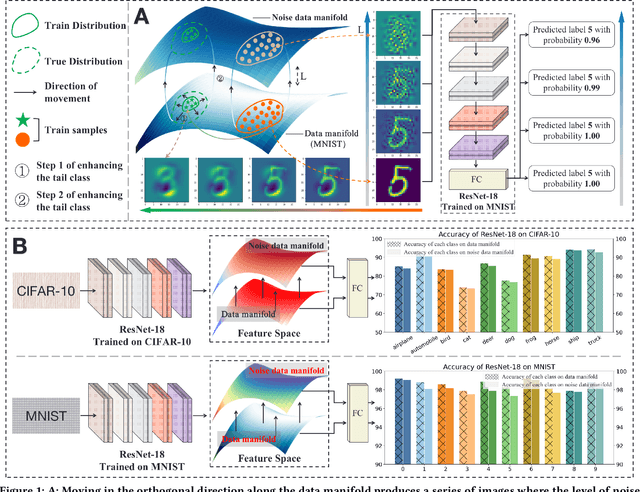
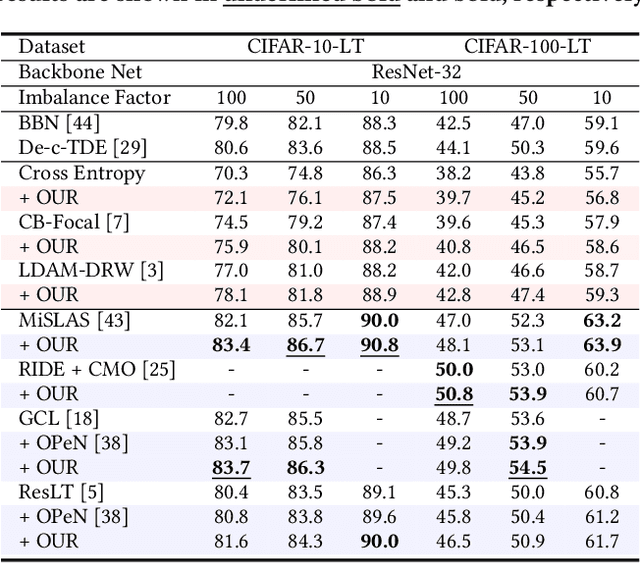
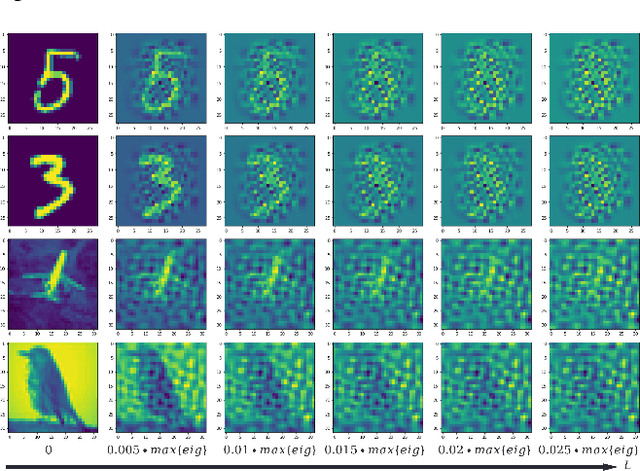
In scenarios with long-tailed distributions, the model's ability to identify tail classes is limited due to the under-representation of tail samples. Class rebalancing, information augmentation, and other techniques have been proposed to facilitate models to learn the potential distribution of tail classes. The disadvantage is that these methods generally pursue models with balanced class accuracy on the data manifold, while ignoring the ability of the model to resist interference. By constructing noisy data manifold, we found that the robustness of models trained on unbalanced data has a long-tail phenomenon. That is, even if the class accuracy is balanced on the data domain, it still has bias on the noisy data manifold. However, existing methods cannot effectively mitigate the above phenomenon, which makes the model vulnerable in long-tailed scenarios. In this work, we propose an Orthogonal Uncertainty Representation (OUR) of feature embedding and an end-to-end training strategy to improve the long-tail phenomenon of model robustness. As a general enhancement tool, OUR has excellent compatibility with other methods and does not require additional data generation, ensuring fast and efficient training. Comprehensive evaluations on long-tailed datasets show that our method significantly improves the long-tail phenomenon of robustness, bringing consistent performance gains to other long-tailed learning methods.
Changes-Aware Transformer: Learning Generalized Changes Representation
Sep 24, 2023
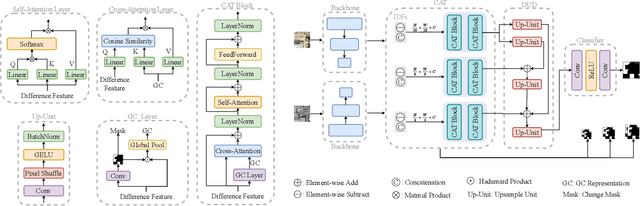


Difference features obtained by comparing the images of two periods play an indispensable role in the change detection (CD) task. However, a pair of bi-temporal images can exhibit diverse changes, which may cause various difference features. Identifying changed pixels with differ difference features to be the same category is thus a challenge for CD. Most nowadays' methods acquire distinctive difference features in implicit ways like enhancing image representation or supervision information. Nevertheless, informative image features only guarantee object semantics are modeled and can not guarantee that changed pixels have similar semantics in the difference feature space and are distinct from those unchanged ones. In this work, the generalized representation of various changes is learned straightforwardly in the difference feature space, and a novel Changes-Aware Transformer (CAT) for refining difference features is proposed. This generalized representation can perceive which pixels are changed and which are unchanged and further guide the update of pixels' difference features. CAT effectively accomplishes this refinement process through the stacked cosine cross-attention layer and self-attention layer. After refinement, the changed pixels in the difference feature space are closer to each other, which facilitates change detection. In addition, CAT is compatible with various backbone networks and existing CD methods. Experiments on remote sensing CD data set and street scene CD data set show that our method achieves state-of-the-art performance and has excellent generalization.
AMC-Net: An Effective Network for Automatic Modulation Classification
Apr 02, 2023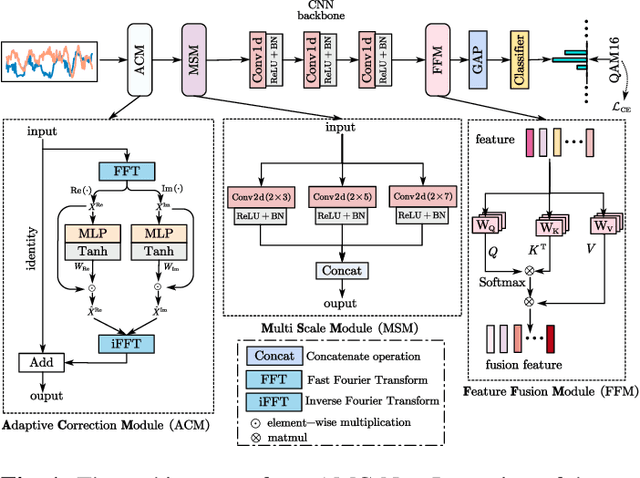
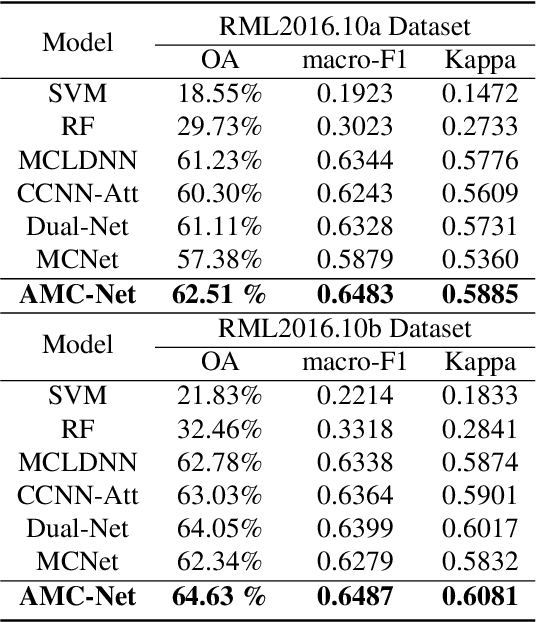
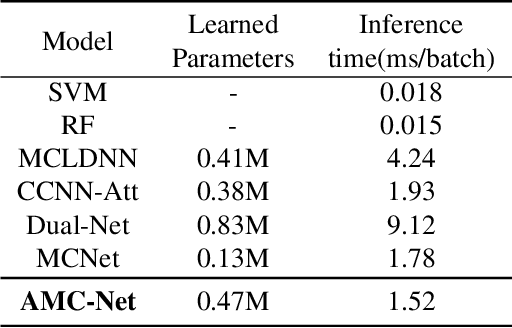
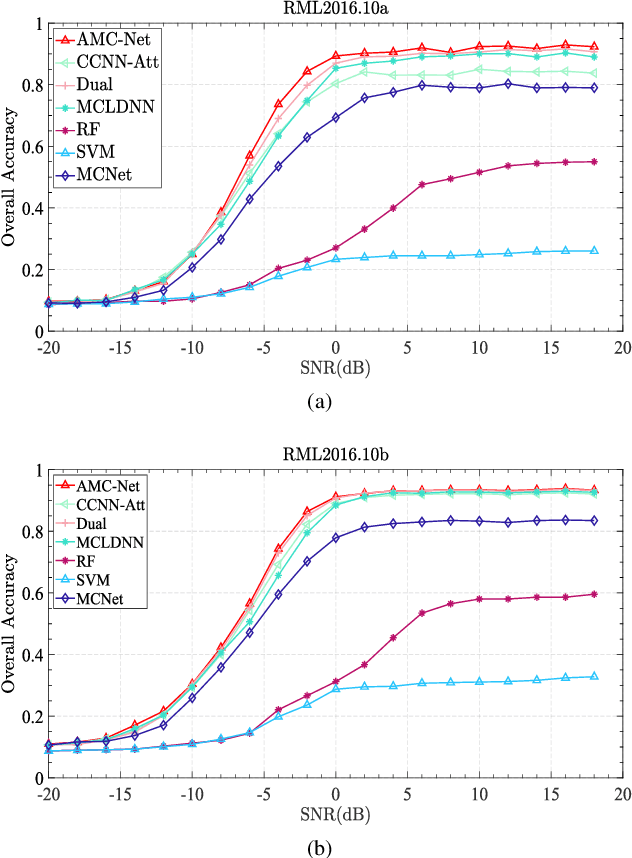
Automatic modulation classification (AMC) is a crucial stage in the spectrum management, signal monitoring, and control of wireless communication systems. The accurate classification of the modulation format plays a vital role in the subsequent decoding of the transmitted data. End-to-end deep learning methods have been recently applied to AMC, outperforming traditional feature engineering techniques. However, AMC still has limitations in low signal-to-noise ratio (SNR) environments. To address the drawback, we propose a novel AMC-Net that improves recognition by denoising the input signal in the frequency domain while performing multi-scale and effective feature extraction. Experiments on two representative datasets demonstrate that our model performs better in efficiency and effectiveness than the most current methods.
Curvature-Balanced Feature Manifold Learning for Long-Tailed Classification
Mar 22, 2023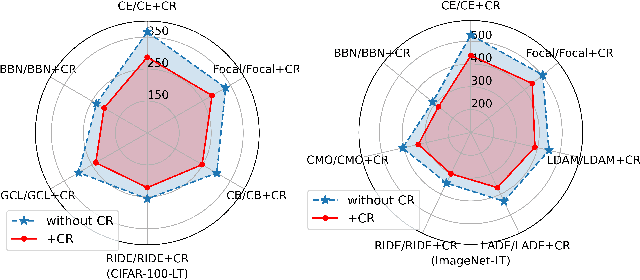
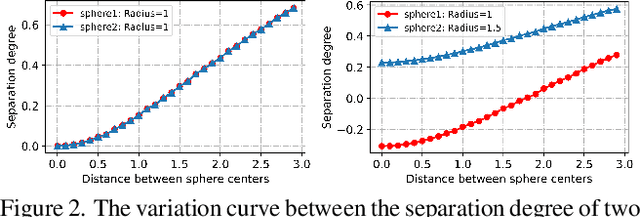
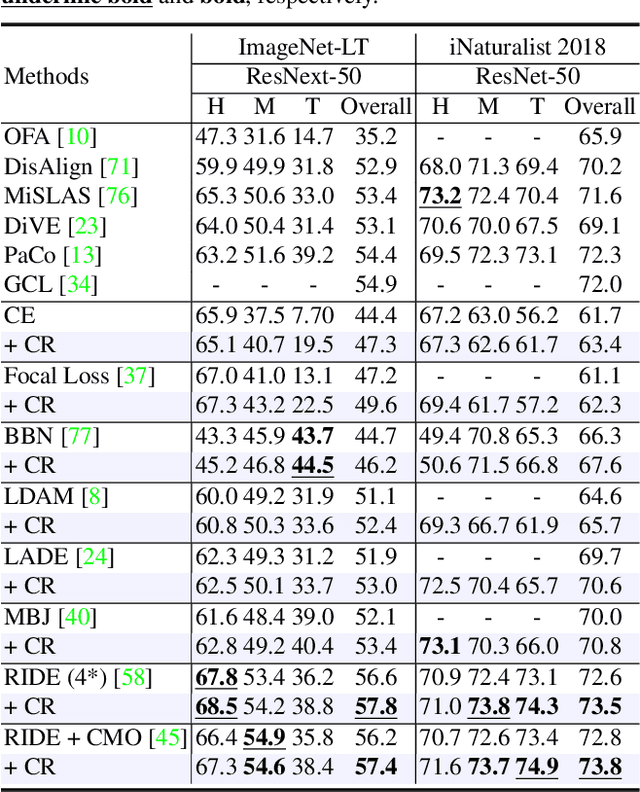
To address the challenges of long-tailed classification, researchers have proposed several approaches to reduce model bias, most of which assume that classes with few samples are weak classes. However, recent studies have shown that tail classes are not always hard to learn, and model bias has been observed on sample-balanced datasets, suggesting the existence of other factors that affect model bias. In this work, we systematically propose a series of geometric measurements for perceptual manifolds in deep neural networks, and then explore the effect of the geometric characteristics of perceptual manifolds on classification difficulty and how learning shapes the geometric characteristics of perceptual manifolds. An unanticipated finding is that the correlation between the class accuracy and the separation degree of perceptual manifolds gradually decreases during training, while the negative correlation with the curvature gradually increases, implying that curvature imbalance leads to model bias. Therefore, we propose curvature regularization to facilitate the model to learn curvature-balanced and flatter perceptual manifolds. Evaluations on multiple long-tailed and non-long-tailed datasets show the excellent performance and exciting generality of our approach, especially in achieving significant performance improvements based on current state-of-the-art techniques. Our work opens up a geometric analysis perspective on model bias and reminds researchers to pay attention to model bias on non-long-tailed and even sample-balanced datasets. The code and model will be made public.
Bi-level Multi-objective Evolutionary Learning: A Case Study on Multi-task Graph Neural Topology Search
Feb 06, 2023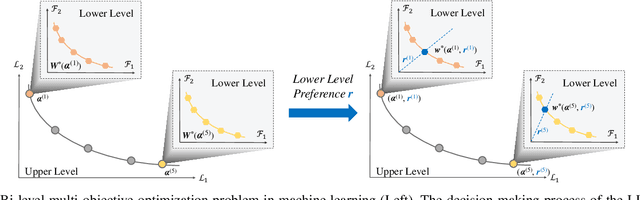
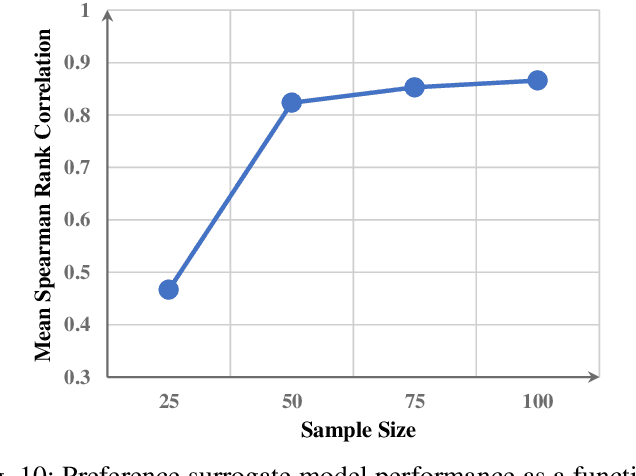
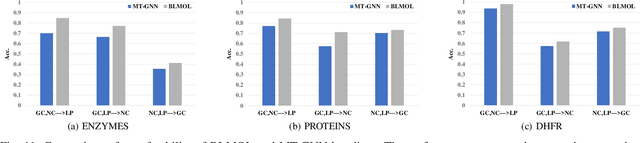
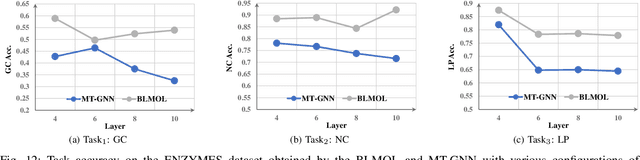
The construction of machine learning models involves many bi-level multi-objective optimization problems (BL-MOPs), where upper level (UL) candidate solutions must be evaluated via training weights of a model in the lower level (LL). Due to the Pareto optimality of sub-problems and the complex dependency across UL solutions and LL weights, an UL solution is feasible if and only if the LL weight is Pareto optimal. It is computationally expensive to determine which LL Pareto weight in the LL Pareto weight set is the most appropriate for each UL solution. This paper proposes a bi-level multi-objective learning framework (BLMOL), coupling the above decision-making process with the optimization process of the UL-MOP by introducing LL preference $r$. Specifically, the UL variable and $r$ are simultaneously searched to minimize multiple UL objectives by evolutionary multi-objective algorithms. The LL weight with respect to $r$ is trained to minimize multiple LL objectives via gradient-based preference multi-objective algorithms. In addition, the preference surrogate model is constructed to replace the expensive evaluation process of the UL-MOP. We consider a novel case study on multi-task graph neural topology search. It aims to find a set of Pareto topologies and their Pareto weights, representing different trade-offs across tasks at UL and LL, respectively. The found graph neural network is employed to solve multiple tasks simultaneously, including graph classification, node classification, and link prediction. Experimental results demonstrate that BLMOL can outperform some state-of-the-art algorithms and generate well-representative UL solutions and LL weights.