 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWang Chao
A match made in consistency heaven: when large language models meet evolutionary algorithms
Jan 19, 2024
Pre-trained large language models (LLMs) have powerful capabilities for generating creative natural text. Evolutionary algorithms (EAs) can discover diverse solutions to complex real-world problems. Motivated by the common collective and directionality of text sequence generation and evolution, this paper illustrates the strong consistency of LLMs and EAs, which includes multiple one-to-one key characteristics: token embedding and genotype-phenotype mapping, position encoding and fitness shaping, position embedding and selection, attention and crossover, feed-forward neural network and mutation, model training and parameter update, and multi-task learning and multi-objective optimization. Based on this consistency perspective, existing coupling studies are analyzed, including evolutionary fine-tuning and LLM-enhanced EAs. Leveraging these insights, we outline a fundamental roadmap for future research in coupling LLMs and EAs, while highlighting key challenges along the way. The consistency not only reveals the evolution mechanism behind LLMs but also facilitates the development of evolved artificial agents that approach or surpass biological organisms.
Automatic detection of aerial survey ground control points based on Yolov5-OBB
Mar 06, 2023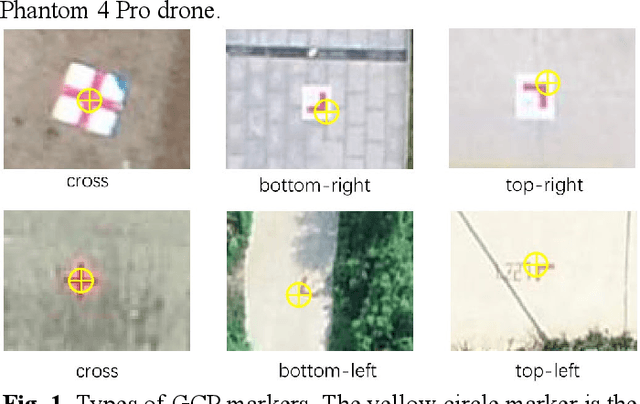
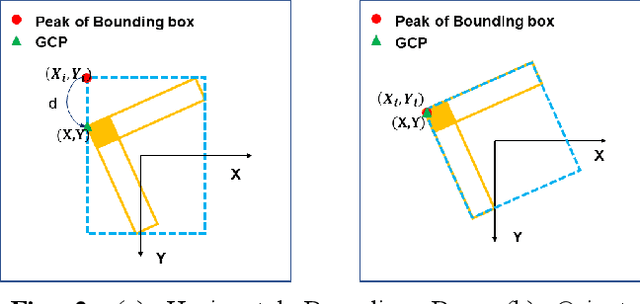
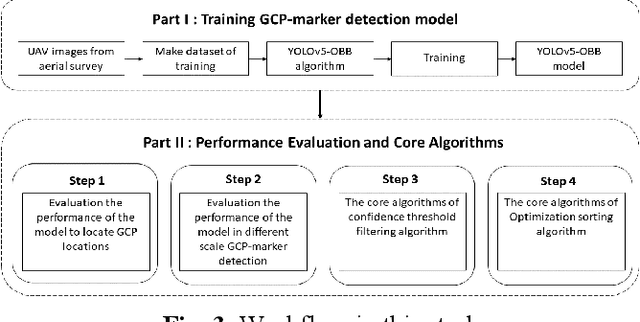

The use of ground control points (GCPs) for georeferencing is the most common strategy in unmanned aerial vehicle (UAV) photogrammetry, but at the same time their collection represents the most time-consuming and expensive part of UAV campaigns. Recently, deep learning has been rapidly developed in the field of small object detection. In this letter, to automatically extract coordinates information of ground control points (GCPs) by detecting GCP-markers in UAV images, we propose a solution that uses a deep learning-based architecture, YOLOv5-OBB, combined with a confidence threshold filtering algorithm and an optimal ranking algorithm. We applied our proposed method to a dataset collected by DJI Phantom 4 Pro drone and obtained good detection performance with the mean Average Precision (AP) of 0.832 and the highest AP of 0.982 for the cross-type GCP-markers. The proposed method can be a promising tool for future implementation of the end-to-end aerial triangulation process.
A New Radar Signal Multiparameter-Based Deinterleaving Method
Aug 21, 2022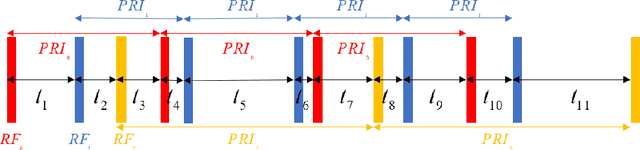
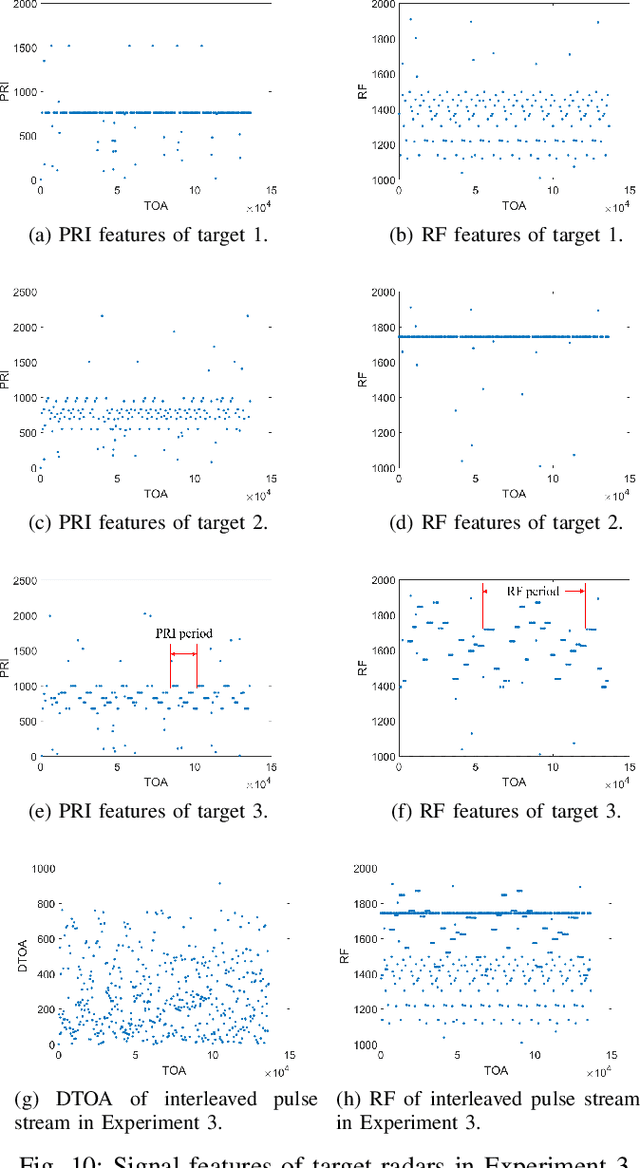
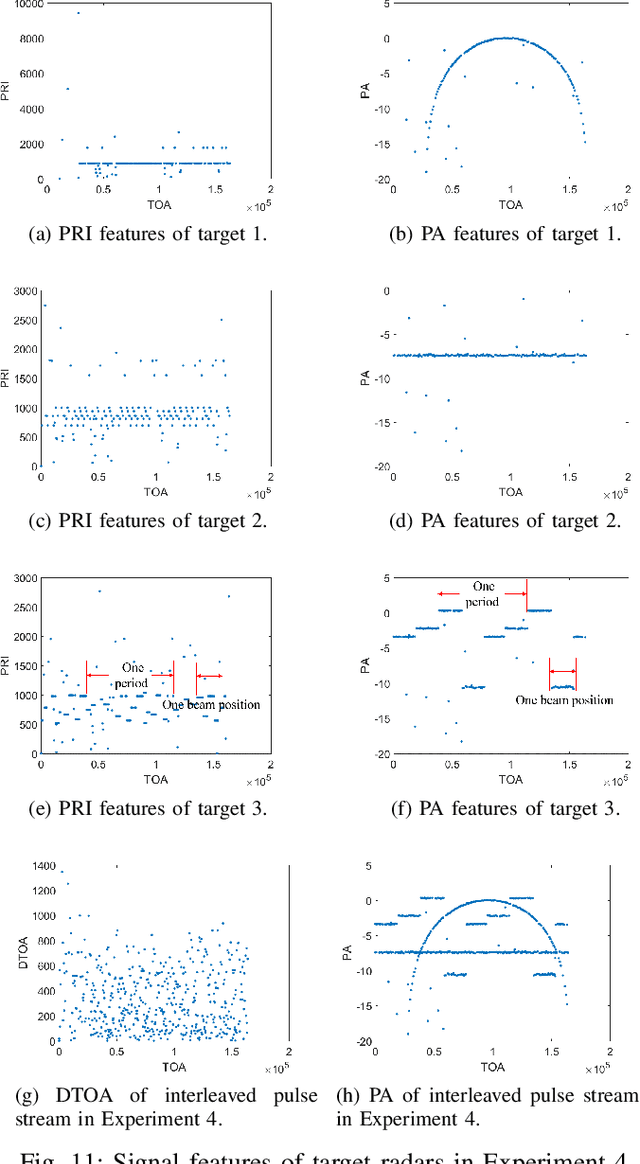
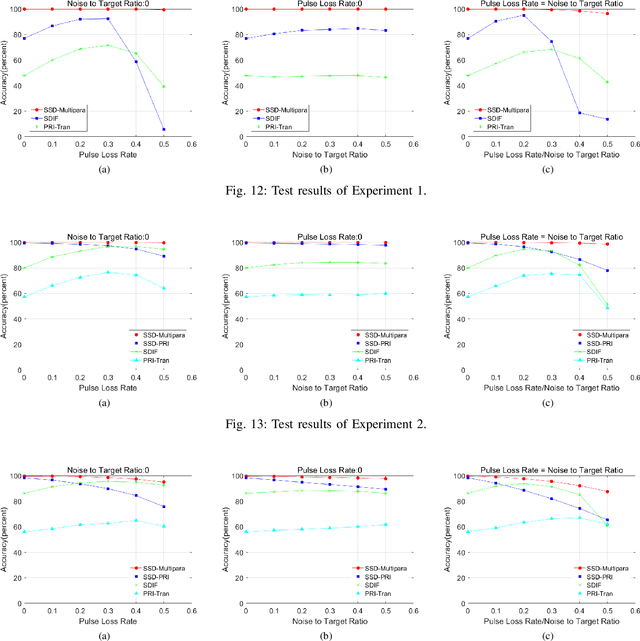
Radar signal deinterleaving has been extensively and thoroughly investigated in the electronic reconnaissance field. In this work, a new radar signal multiparameter-based deinterleaving method is proposed. In this method, semantic information composed of the pulse repetition interval (PRI), pulse width (PW), radio frequency (RF), and pulse amplitude (PA) of a radar signal is used to deinterleave radar signals. A bidirectional gated recurrent unit (BGRU) is employed, and the difference of time of arrival (DTOA)/RF, DTOA/PW, and DTOA/PA of the pulse stream are input into the BGRU. Based on the semantic information contained in different radar signal types, each pulse in the obtained pulse stream is classified according to the semantic information category, and the radar signals are deinterleaved. Compared to the PRI-based deinterleaving methods, the proposed method utilizes the multidimensional information of radar signals. As a result, higher deinterleaving accuracy is achieved. Compared to other existing radar signal multiparameter-based deinterleaving methods, the proposed method can adapt to radar signals with complex parameter features as well as to complex signal environments, and can complete the use of multiparameter in one step.
Unpaired Photo-to-Caricature Translation on Faces in the Wild
Jul 25, 2018
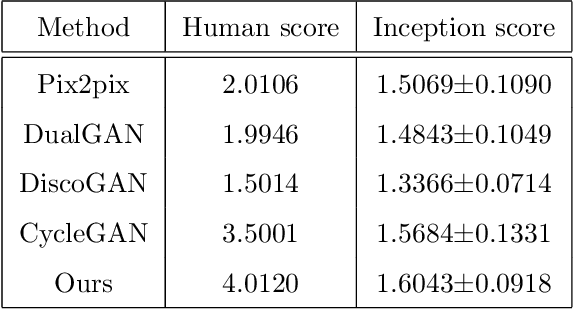
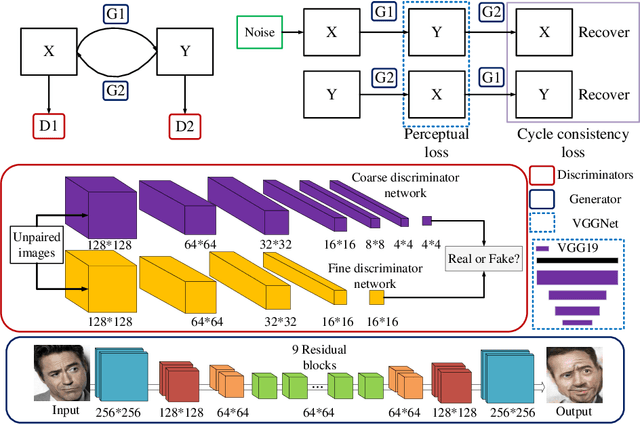
Recently, image-to-image translation has been made much progress owing to the success of conditional Generative Adversarial Networks (cGANs). And some unpaired methods based on cycle consistency loss such as DualGAN, CycleGAN and DiscoGAN are really popular. However, it's still very challenging for translation tasks with the requirement of high-level visual information conversion, such as photo-to-caricature translation that requires satire, exaggeration, lifelikeness and artistry. We present an approach for learning to translate faces in the wild from the source photo domain to the target caricature domain with different styles, which can also be used for other high-level image-to-image translation tasks. In order to capture global structure with local statistics while translation, we design a dual pathway model with one coarse discriminator and one fine discriminator. For generator, we provide one extra perceptual loss in association with adversarial loss and cycle consistency loss to achieve representation learning for two different domains. Also the style can be learned by the auxiliary noise input. Experiments on photo-to-caricature translation of faces in the wild show considerable performance gain of our proposed method over state-of-the-art translation methods as well as its potential real applications.