 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaiyong Zheng
Quantum Recurrent Neural Networks for Sequential Learning
Feb 07, 2023
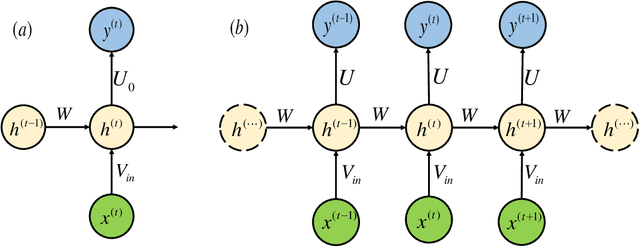
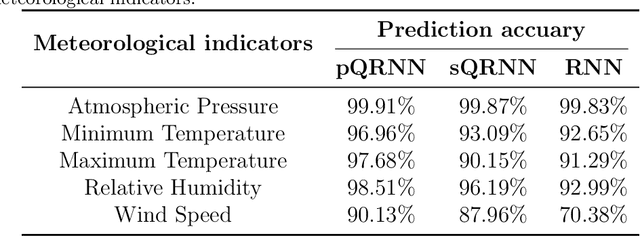
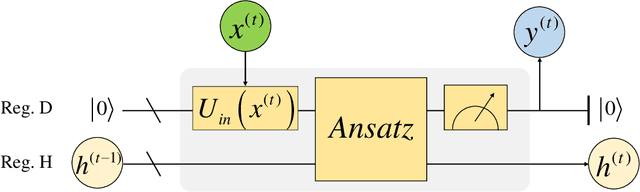
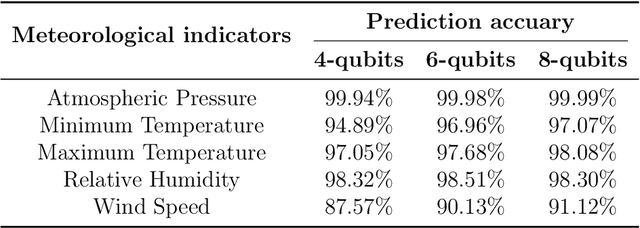
Quantum neural network (QNN) is one of the promising directions where the near-term noisy intermediate-scale quantum (NISQ) devices could find advantageous applications against classical resources. Recurrent neural networks are the most fundamental networks for sequential learning, but up to now there is still a lack of canonical model of quantum recurrent neural network (QRNN), which certainly restricts the research in the field of quantum deep learning. In the present work, we propose a new kind of QRNN which would be a good candidate as the canonical QRNN model, where, the quantum recurrent blocks (QRBs) are constructed in the hardware-efficient way, and the QRNN is built by stacking the QRBs in a staggered way that can greatly reduce the algorithm's requirement with regard to the coherent time of quantum devices. That is, our QRNN is much more accessible on NISQ devices. Furthermore, the performance of the present QRNN model is verified concretely using three different kinds of classical sequential data, i.e., meteorological indicators, stock price, and text categorization. The numerical experiments show that our QRNN achieves much better performance in prediction (classification) accuracy against the classical RNN and state-of-the-art QNN models for sequential learning, and can predict the changing details of temporal sequence data. The practical circuit structure and superior performance indicate that the present QRNN is a promising learning model to find quantum advantageous applications in the near term.
SinTra: Learning an inspiration model from a single multi-track music segment
Apr 21, 2022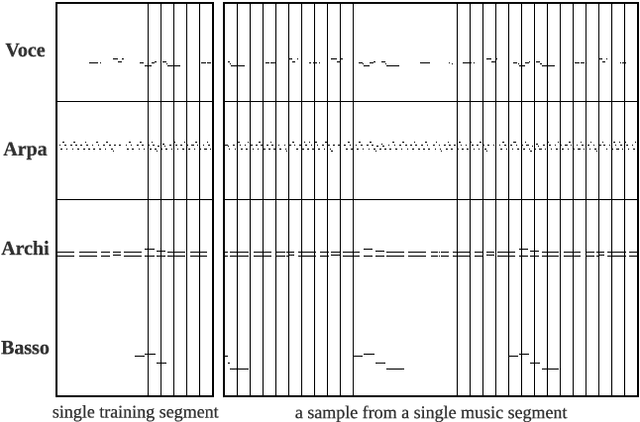

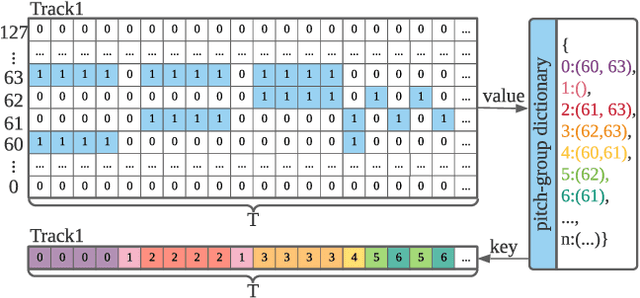
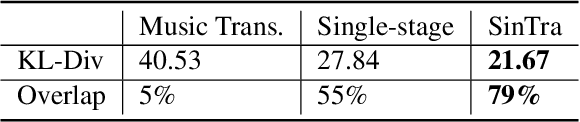
In this paper, we propose SinTra, an auto-regressive sequential generative model that can learn from a single multi-track music segment, to generate coherent, aesthetic, and variable polyphonic music of multi-instruments with an arbitrary length of bar. For this task, to ensure the relevance of generated samples and training music, we present a novel pitch-group representation. SinTra, consisting of a pyramid of Transformer-XL with a multi-scale training strategy, can learn both the musical structure and the relative positional relationship between notes of the single training music segment. Additionally, for maintaining the inter-track correlation, we use the convolution operation to process multi-track music, and when decoding, the tracks are independent to each other to prevent interference. We evaluate SinTra with both subjective study and objective metrics. The comparison results show that our framework can learn information from a single music segment more sufficiently than Music Transformer. Also the comparison between SinTra and its variant, i.e., the single-stage SinTra with the first stage only, shows that the pyramid structure can effectively suppress overly-fragmented notes.
SGUIE-Net: Semantic Attention Guided Underwater Image Enhancement with Multi-Scale Perception
Jan 08, 2022



Due to the wavelength-dependent light attenuation, refraction and scattering, underwater images usually suffer from color distortion and blurred details. However, due to the limited number of paired underwater images with undistorted images as reference, training deep enhancement models for diverse degradation types is quite difficult. To boost the performance of data-driven approaches, it is essential to establish more effective learning mechanisms that mine richer supervised information from limited training sample resources. In this paper, we propose a novel underwater image enhancement network, called SGUIE-Net, in which we introduce semantic information as high-level guidance across different images that share common semantic regions. Accordingly, we propose semantic region-wise enhancement module to perceive the degradation of different semantic regions from multiple scales and feed it back to the global attention features extracted from its original scale. This strategy helps to achieve robust and visually pleasant enhancements to different semantic objects, which should thanks to the guidance of semantic information for differentiated enhancement. More importantly, for those degradation types that are not common in the training sample distribution, the guidance connects them with the already well-learned types according to their semantic relevance. Extensive experiments on the publicly available datasets and our proposed dataset demonstrated the impressive performance of SGUIE-Net. The code and proposed dataset are available at: https://trentqq.github.io/SGUIE-Net.html
ReshapeGAN: Object Reshaping by Providing A Single Reference Image
May 16, 2019

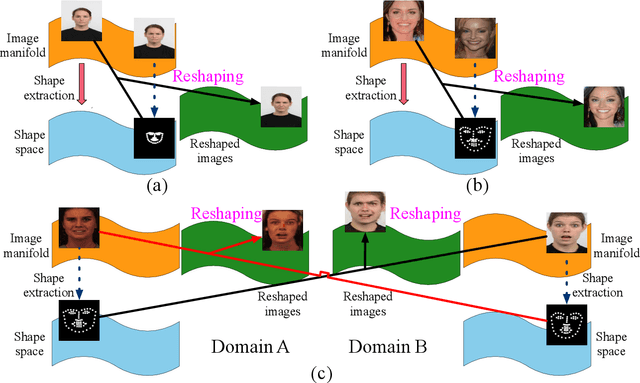
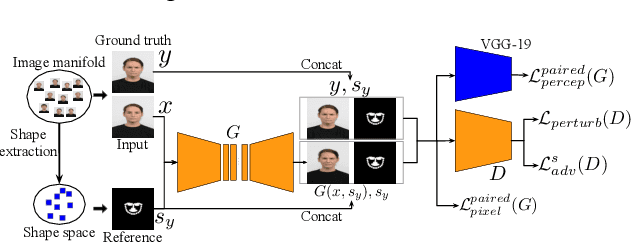
The aim of this work is learning to reshape the object in an input image to an arbitrary new shape, by just simply providing a single reference image with an object instance in the desired shape. We propose a new Generative Adversarial Network (GAN) architecture for such an object reshaping problem, named ReshapeGAN. The network can be tailored for handling all kinds of problem settings, including both within-domain (or single-dataset) reshaping and cross-domain (typically across mutiple datasets) reshaping, with paired or unpaired training data. The appearance of the input object is preserved in all cases, and thus it is still identifiable after reshaping, which has never been achieved as far as we are aware. We present the tailored models of the proposed ReshapeGAN for all the problem settings, and have them tested on 8 kinds of reshaping tasks with 13 different datasets, demonstrating the ability of ReshapeGAN on generating convincing and superior results for object reshaping. To the best of our knowledge, we are the first to be able to make one GAN framework work on all such object reshaping tasks, especially the cross-domain tasks on handling multiple diverse datasets. We present here both ablation studies on our proposed ReshapeGAN models and comparisons with the state-of-the-art models when they are made comparable, using all kinds of applicable metrics that we are aware of.
One-Shot Image-to-Image Translation via Part-Global Learning with a Multi-adversarial Framework
May 12, 2019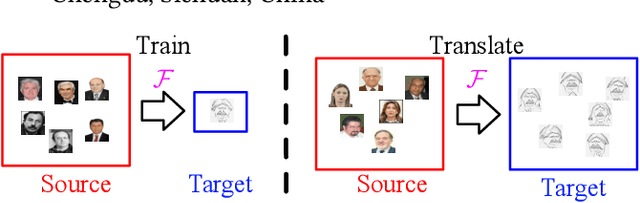
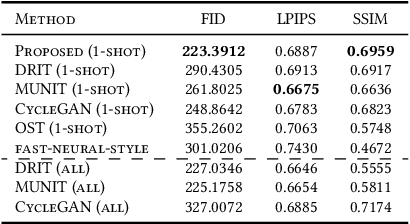
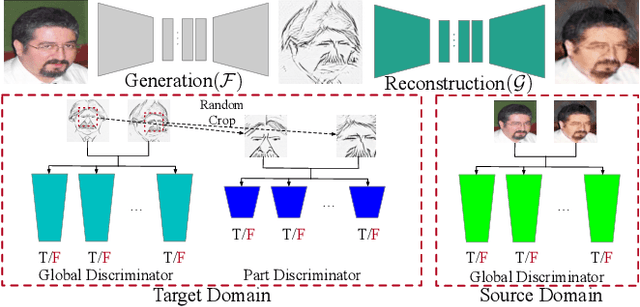
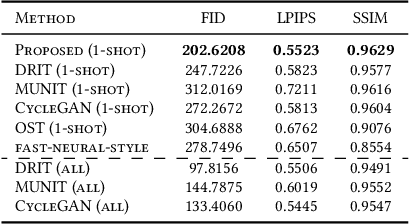
It is well known that humans can learn and recognize objects effectively from several limited image samples. However, learning from just a few images is still a tremendous challenge for existing main-stream deep neural networks. Inspired by analogical reasoning in the human mind, a feasible strategy is to translate the abundant images of a rich source domain to enrich the relevant yet different target domain with insufficient image data. To achieve this goal, we propose a novel, effective multi-adversarial framework (MA) based on part-global learning, which accomplishes one-shot cross-domain image-to-image translation. In specific, we first devise a part-global adversarial training scheme to provide an efficient way for feature extraction and prevent discriminators being over-fitted. Then, a multi-adversarial mechanism is employed to enhance the image-to-image translation ability to unearth the high-level semantic representation. Moreover, a balanced adversarial loss function is presented, which aims to balance the training data and stabilize the training process. Extensive experiments demonstrate that the proposed approach can obtain impressive results on various datasets between two extremely imbalanced image domains and outperform state-of-the-art methods on one-shot image-to-image translation.
Generative Adversarial Network with Multi-Branch Discriminator for Cross-Species Image-to-Image Translation
Jan 24, 2019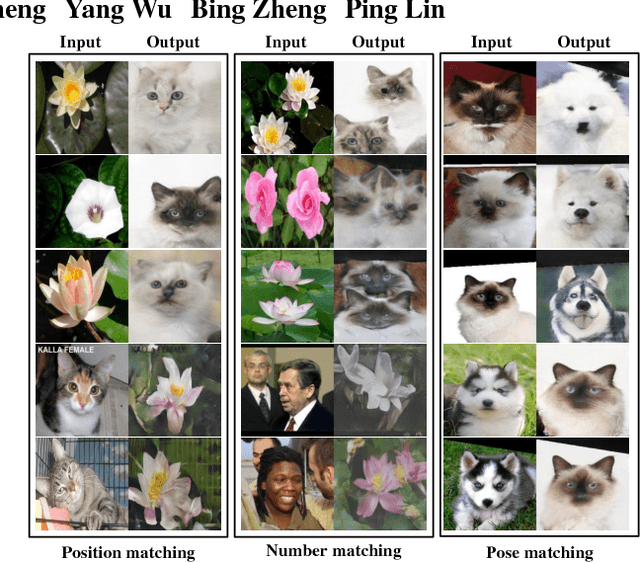
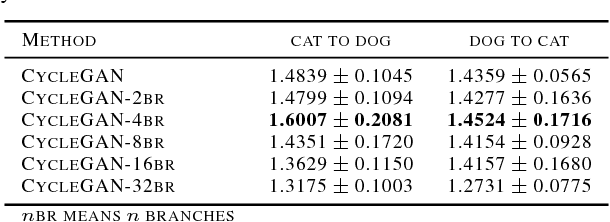
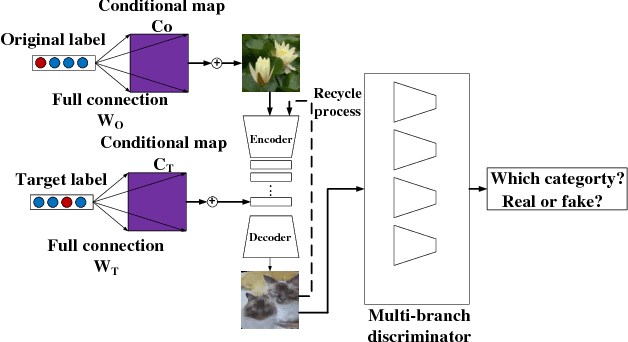

Current approaches have made great progress on image-to-image translation tasks benefiting from the success of image synthesis methods especially generative adversarial networks (GANs). However, existing methods are limited to handling translation tasks between two species while keeping the content matching on the semantic level. A more challenging task would be the translation among more than two species. To explore this new area, we propose a simple yet effective structure of a multi-branch discriminator for enhancing an arbitrary generative adversarial architecture (GAN), named GAN-MBD. It takes advantage of the boosting strategy to break a common discriminator into several smaller ones with fewer parameters, which can enhance the generation and synthesis abilities of GANs efficiently and effectively. Comprehensive experiments show that the proposed multi-branch discriminator can dramatically improve the performance of popular GANs on cross-species image-to-image translation tasks while reducing the number of parameters for computation. The code and some datasets are attached as supplementary materials for reference.
Discriminative Region Proposal Adversarial Networks for High-Quality Image-to-Image Translation
Aug 06, 2018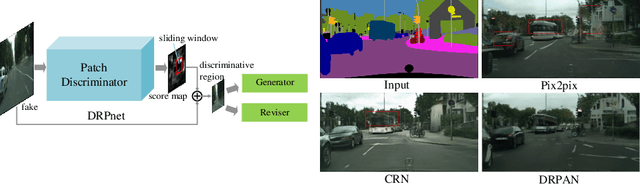
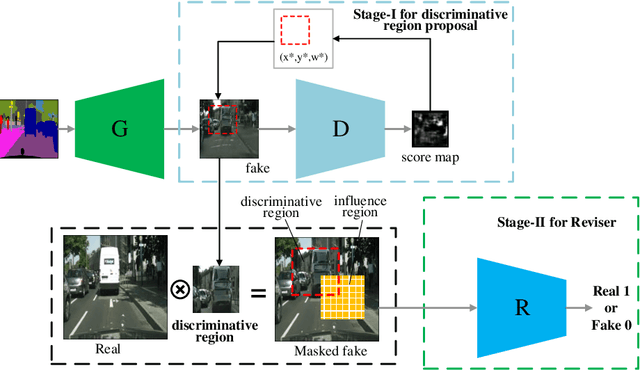
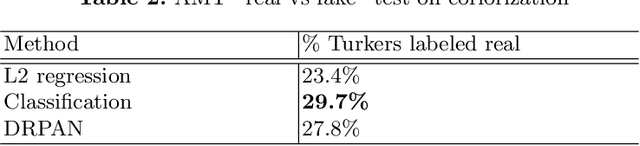
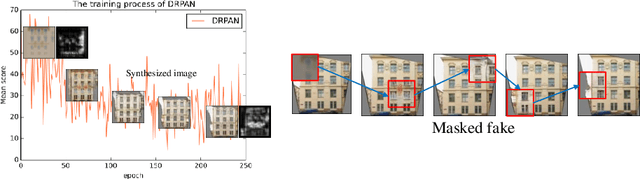
Image-to-image translation has been made much progress with embracing Generative Adversarial Networks (GANs). However, it's still very challenging for translation tasks that require high quality, especially at high-resolution and photorealism. In this paper, we present Discriminative Region Proposal Adversarial Networks (DRPAN) for high-quality image-to-image translation. We decompose the procedure of image-to-image translation task into three iterated steps, first is to generate an image with global structure but some local artifacts (via GAN), second is using our DRPnet to propose the most fake region from the generated image, and third is to implement "image inpainting" on the most fake region for more realistic result through a reviser, so that the system (DRPAN) can be gradually optimized to synthesize images with more attention on the most artifact local part. Experiments on a variety of image-to-image translation tasks and datasets validate that our method outperforms state-of-the-arts for producing high-quality translation results in terms of both human perceptual studies and automatic quantitative measures.
Unpaired Photo-to-Caricature Translation on Faces in the Wild
Jul 25, 2018
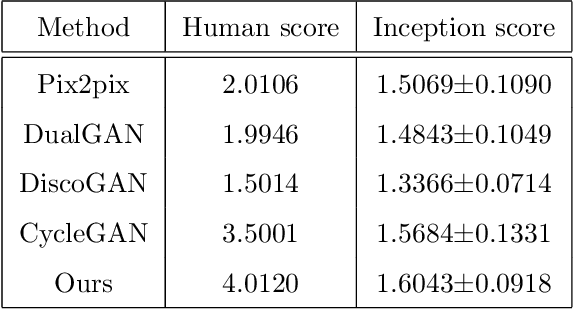
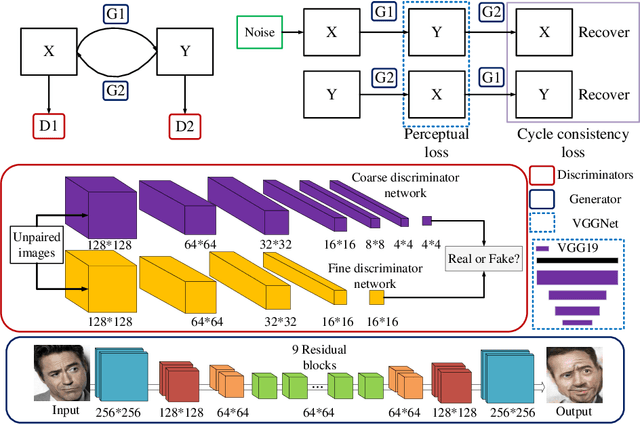
Recently, image-to-image translation has been made much progress owing to the success of conditional Generative Adversarial Networks (cGANs). And some unpaired methods based on cycle consistency loss such as DualGAN, CycleGAN and DiscoGAN are really popular. However, it's still very challenging for translation tasks with the requirement of high-level visual information conversion, such as photo-to-caricature translation that requires satire, exaggeration, lifelikeness and artistry. We present an approach for learning to translate faces in the wild from the source photo domain to the target caricature domain with different styles, which can also be used for other high-level image-to-image translation tasks. In order to capture global structure with local statistics while translation, we design a dual pathway model with one coarse discriminator and one fine discriminator. For generator, we provide one extra perceptual loss in association with adversarial loss and cycle consistency loss to achieve representation learning for two different domains. Also the style can be learned by the auxiliary noise input. Experiments on photo-to-caricature translation of faces in the wild show considerable performance gain of our proposed method over state-of-the-art translation methods as well as its potential real applications.
Instance Map based Image Synthesis with a Denoising Generative Adversarial Network
Jan 10, 2018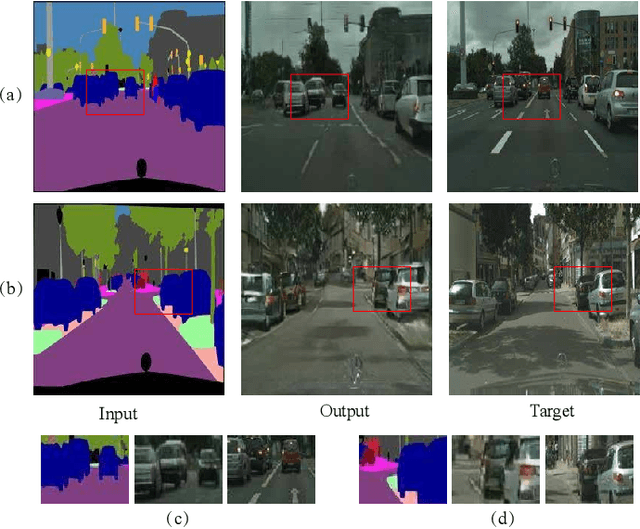



Semantic layouts based Image synthesizing, which has benefited from the success of Generative Adversarial Network (GAN), has drawn much attention in these days. How to enhance the synthesis image equality while keeping the stochasticity of the GAN is still a challenge. We propose a novel denoising framework to handle this problem. The overlapped objects generation is another challenging task when synthesizing images from a semantic layout to a realistic RGB photo. To overcome this deficiency, we include a one-hot semantic label map to force the generator paying more attention on the overlapped objects generation. Furthermore, we improve the loss function of the discriminator by considering perturb loss and cascade layer loss to guide the generation process. We applied our methods on the Cityscapes, Facades and NYU datasets and demonstrate the image generation ability of our model.
Pipeline Generative Adversarial Networks for Facial Images Generation with Multiple Attributes
Nov 29, 2017
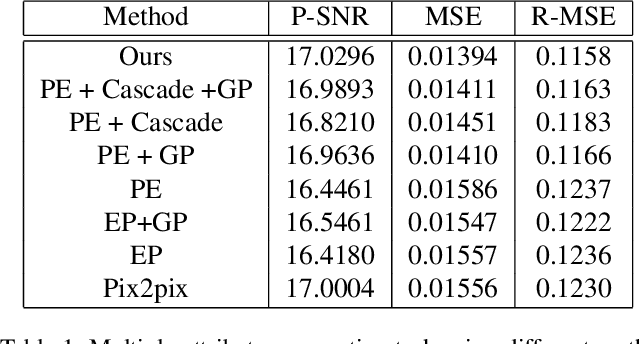
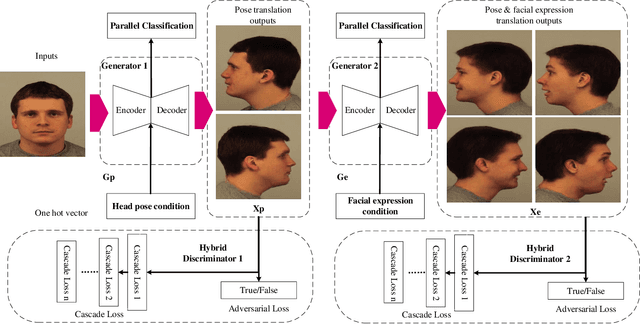
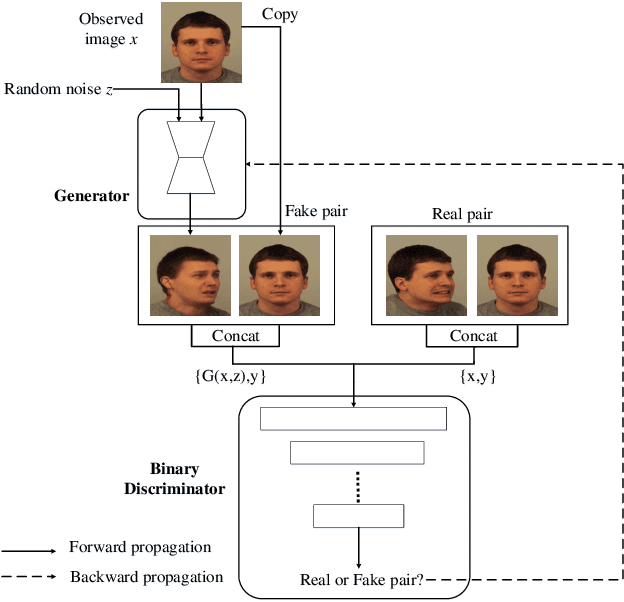
Generative Adversarial Networks are proved to be efficient on various kinds of image generation tasks. However, it is still a challenge if we want to generate images precisely. Many researchers focus on how to generate images with one attribute. But image generation under multiple attributes is still a tough work. In this paper, we try to generate a variety of face images under multiple constraints using a pipeline process. The Pip-GAN (Pipeline Generative Adversarial Network) we present employs a pipeline network structure which can generate a complex facial image step by step using a neutral face image. We applied our method on two face image databases and demonstrate its ability to generate convincing novel images of unseen identities under multiple conditions previously.