 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKun Sun
Attention-aware semantic relevance predicting Chinese sentence reading
Mar 27, 2024
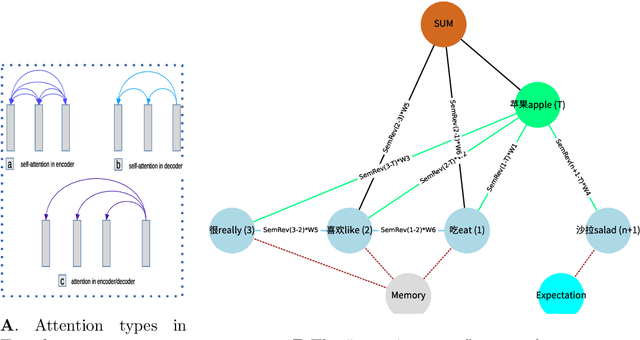

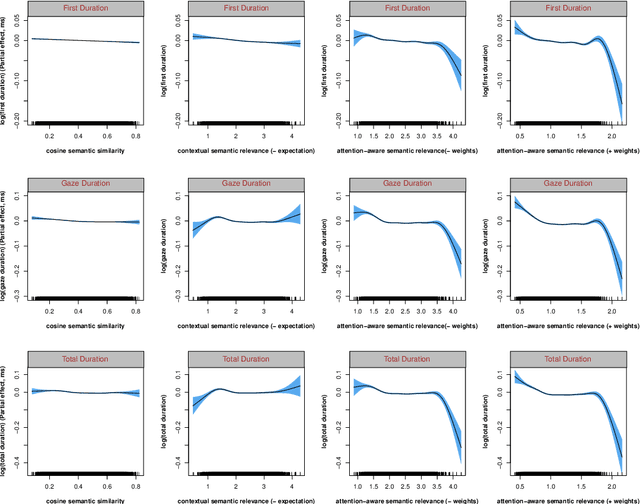

In recent years, several influential computational models and metrics have been proposed to predict how humans comprehend and process sentence. One particularly promising approach is contextual semantic similarity. Inspired by the attention algorithm in Transformer and human memory mechanisms, this study proposes an ``attention-aware'' approach for computing contextual semantic relevance. This new approach takes into account the different contributions of contextual parts and the expectation effect, allowing it to incorporate contextual information fully. The attention-aware approach also facilitates the simulation of existing reading models and evaluate them. The resulting ``attention-aware'' metrics of semantic relevance can more accurately predict fixation durations in Chinese reading tasks recorded in an eye-tracking corpus than those calculated by existing approaches. The study's findings further provide strong support for the presence of semantic preview benefits in Chinese naturalistic reading. Furthermore, the attention-aware metrics of semantic relevance, being memory-based, possess high interpretability from both linguistic and cognitive standpoints, making them a valuable computational tool for modeling eye-movements in reading and further gaining insight into the process of language comprehension. Our approach underscores the potential of these metrics to advance our comprehension of how humans understand and process language, ultimately leading to a better understanding of language comprehension and processing.
Computational Sentence-level Metrics Predicting Human Sentence Comprehension
Mar 23, 2024The majority of research in computational psycholinguistics has concentrated on the processing of words. This study introduces innovative methods for computing sentence-level metrics using multilingual large language models. The metrics developed sentence surprisal and sentence relevance and then are tested and compared to validate whether they can predict how humans comprehend sentences as a whole across languages. These metrics offer significant interpretability and achieve high accuracy in predicting human sentence reading speeds. Our results indicate that these computational sentence-level metrics are exceptionally effective at predicting and elucidating the processing difficulties encountered by readers in comprehending sentences as a whole across a variety of languages. Their impressive performance and generalization capabilities provide a promising avenue for future research in integrating LLMs and cognitive science.
Comprehensive Reassessment of Large-Scale Evaluation Outcomes in LLMs: A Multifaceted Statistical Approach
Mar 22, 2024Amidst the rapid evolution of LLMs, the significance of evaluation in comprehending and propelling these models forward is increasingly paramount. Evaluations have revealed that factors such as scaling, training types, architectures and other factors profoundly impact the performance of LLMs. However, the extent and nature of these impacts continue to be subjects of debate because most assessments have been restricted to a limited number of models and data points. Clarifying the effects of these factors on performance scores can be more effectively achieved through a statistical lens. Our study embarks on a thorough re-examination of these LLMs, targeting the inadequacies in current evaluation methods. With the advent of a uniform evaluation framework, our research leverages an expansive dataset of evaluation results, introducing a comprehensive statistical methodology. This includes the application of ANOVA, Tukey HSD tests, GAMM, and clustering technique, offering a robust and transparent approach to deciphering LLM performance data. Contrary to prevailing findings, our results challenge assumptions about emergent abilities and the influence of given training types and architectures in LLMs. These findings furnish new perspectives on the characteristics, intrinsic nature, and developmental trajectories of LLMs. By providing straightforward and reliable methods to scrutinize and reassess LLM performance data, this study contributes a nuanced perspective on LLM efficiency and potentials.
Compensating Removed Frequency Components: Thwarting Voice Spectrum Reduction Attacks
Aug 18, 2023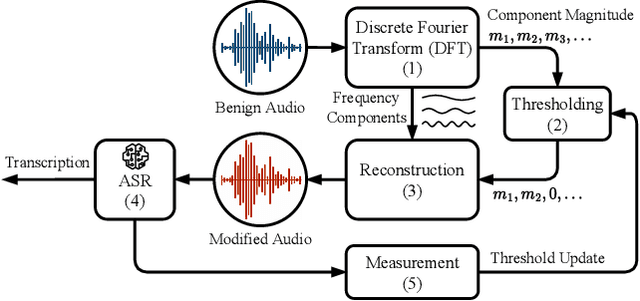

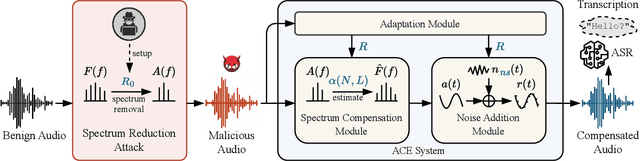
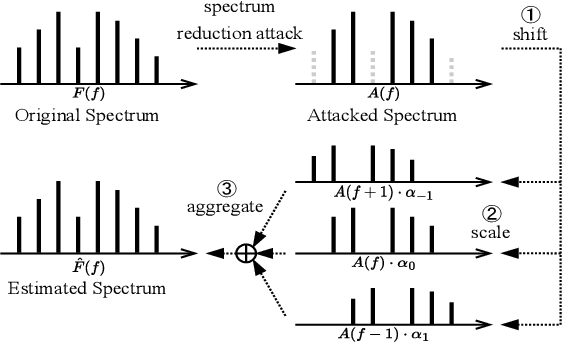
Automatic speech recognition (ASR) provides diverse audio-to-text services for humans to communicate with machines. However, recent research reveals ASR systems are vulnerable to various malicious audio attacks. In particular, by removing the non-essential frequency components, a new spectrum reduction attack can generate adversarial audios that can be perceived by humans but cannot be correctly interpreted by ASR systems. It raises a new challenge for content moderation solutions to detect harmful content in audio and video available on social media platforms. In this paper, we propose an acoustic compensation system named ACE to counter the spectrum reduction attacks over ASR systems. Our system design is based on two observations, namely, frequency component dependencies and perturbation sensitivity. First, since the Discrete Fourier Transform computation inevitably introduces spectral leakage and aliasing effects to the audio frequency spectrum, the frequency components with similar frequencies will have a high correlation. Thus, considering the intrinsic dependencies between neighboring frequency components, it is possible to recover more of the original audio by compensating for the removed components based on the remaining ones. Second, since the removed components in the spectrum reduction attacks can be regarded as an inverse of adversarial noise, the attack success rate will decrease when the adversarial audio is replayed in an over-the-air scenario. Hence, we can model the acoustic propagation process to add over-the-air perturbations into the attacked audio. We implement a prototype of ACE and the experiments show ACE can effectively reduce up to 87.9% of ASR inference errors caused by spectrum reduction attacks. Also, by analyzing residual errors, we summarize six general types of ASR inference errors and investigate the error causes and potential mitigation solutions.
Object Detection in Hyperspectral Image via Unified Spectral-Spatial Feature Aggregation
Jun 14, 2023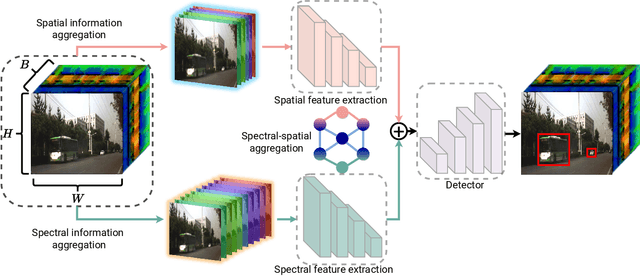

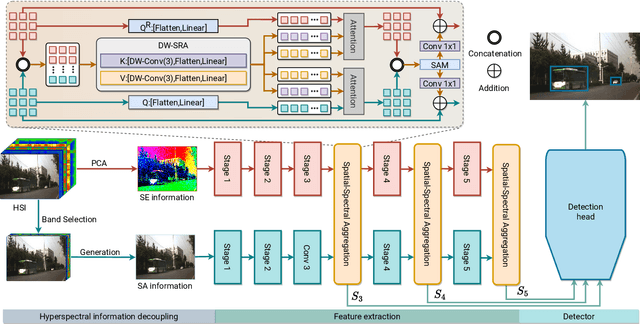
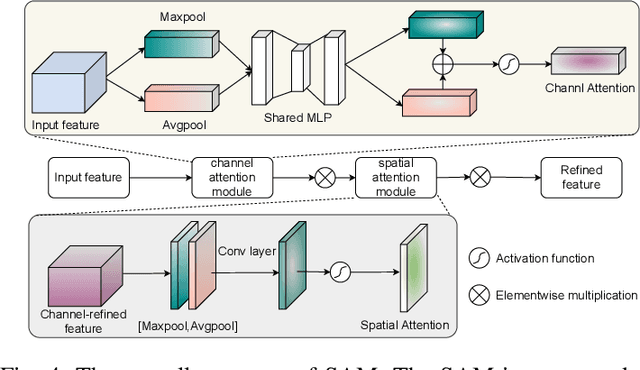
Deep learning-based hyperspectral image (HSI) classification and object detection techniques have gained significant attention due to their vital role in image content analysis, interpretation, and wider HSI applications. However, current hyperspectral object detection approaches predominantly emphasize either spectral or spatial information, overlooking the valuable complementary relationship between these two aspects. In this study, we present a novel \textbf{S}pectral-\textbf{S}patial \textbf{A}ggregation (S2ADet) object detector that effectively harnesses the rich spectral and spatial complementary information inherent in hyperspectral images. S2ADet comprises a hyperspectral information decoupling (HID) module, a two-stream feature extraction network, and a one-stage detection head. The HID module processes hyperspectral images by aggregating spectral and spatial information via band selection and principal components analysis, consequently reducing redundancy. Based on the acquired spatial and spectral aggregation information, we propose a feature aggregation two-stream network for interacting spectral-spatial features. Furthermore, to address the limitations of existing databases, we annotate an extensive dataset, designated as HOD3K, containing 3,242 hyperspectral images captured across diverse real-world scenes and encompassing three object classes. These images possess a resolution of 512x256 pixels and cover 16 bands ranging from 470 nm to 620 nm. Comprehensive experiments on two datasets demonstrate that S2ADet surpasses existing state-of-the-art methods, achieving robust and reliable results. The demo code and dataset of this work are publicly available at \url{https://github.com/hexiao-cs/S2ADet}.
Towards Accurate and Reliable Change Detection of Remote Sensing Images via Knowledge Review and Online Uncertainty Estimation
May 31, 2023
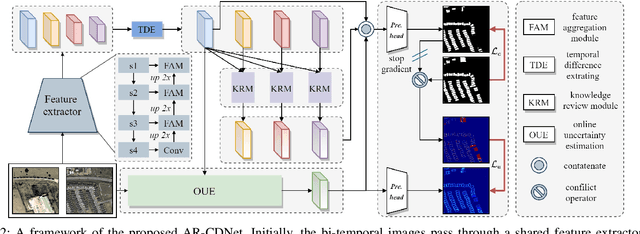
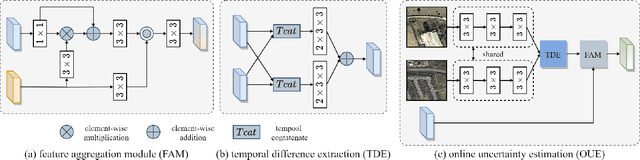
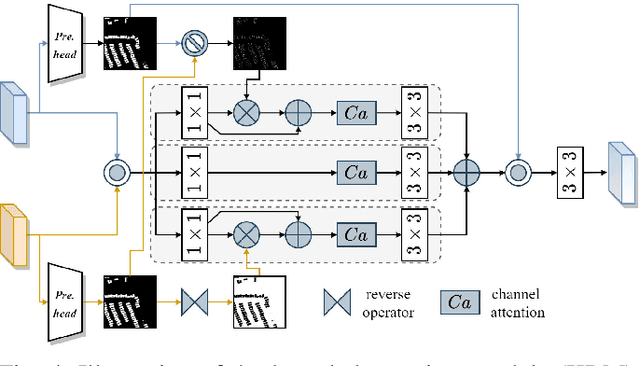
Change detection (CD) is an essential task for various real-world applications, such as urban management and disaster assessment. However, previous methods primarily focus on improving the accuracy of CD, while neglecting the reliability of detection results. In this paper, we propose a novel change detection network, called AR-CDNet, which is able to provide accurate change maps and generate pixel-wise uncertainty. Specifically, an online uncertainty estimation branch is constructed to model the pixel-wise uncertainty, which is supervised by the difference between predicted change maps and corresponding ground truth during the training process. Furthermore, we introduce a knowledge review strategy to distill temporal change knowledge from low-level features to high-level ones, thereby enhancing the discriminability of temporal difference features. Finally, we aggregate the uncertainty-aware features extracted from the online uncertainty estimation branch with multi-level temporal difference features to improve the accuracy of CD. Once trained, our AR-CDNet can provide accurate change maps and evaluate pixel-wise uncertainty without ground truth. Experimental results on two benchmark datasets demonstrate the superior performance of AR-CDNet in the CD task. The demo code for our work will be publicly available at \url{https://github.com/guanyuezhen/AR-CDNet}.
MixCycle: Mixup Assisted Semi-Supervised 3D Single Object Tracking with Cycle Consistency
Mar 16, 2023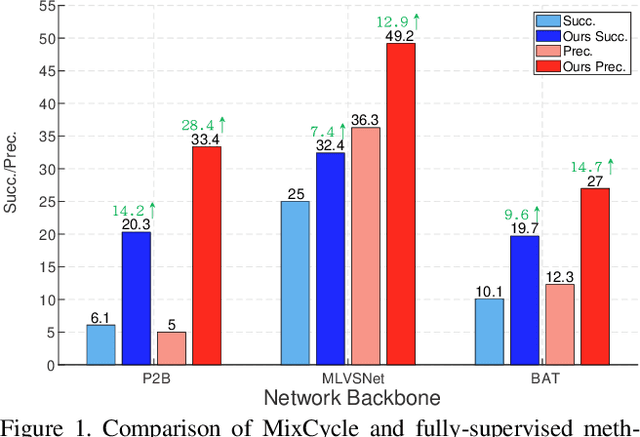
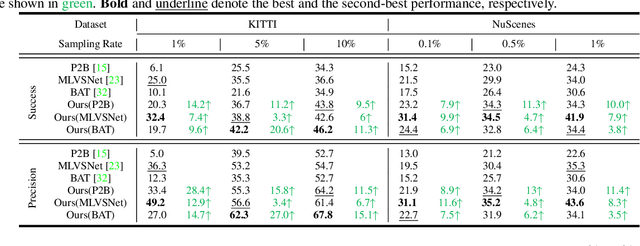

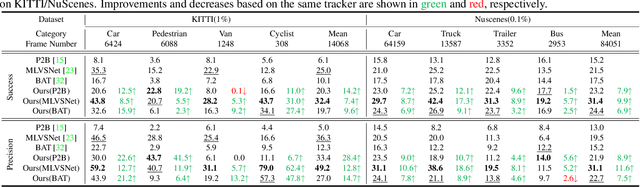
3D single object tracking (SOT) is an indispensable part of automated driving. Existing approaches rely heavily on large, densely labeled datasets. However, annotating point clouds is both costly and time-consuming. Inspired by the great success of cycle tracking in unsupervised 2D SOT, we introduce the first semi-supervised approach to 3D SOT. Specifically, we introduce two cycle-consistency strategies for supervision: 1) Self tracking cycles, which leverage labels to help the model converge better in the early stages of training; 2) forward-backward cycles, which strengthen the tracker's robustness to motion variations and the template noise caused by the template update strategy. Furthermore, we propose a data augmentation strategy named SOTMixup to improve the tracker's robustness to point cloud diversity. SOTMixup generates training samples by sampling points in two point clouds with a mixing rate and assigns a reasonable loss weight for training according to the mixing rate. The resulting MixCycle approach generalizes to appearance matching-based trackers. On the KITTI benchmark, based on the P2B tracker, MixCycle trained with $\textbf{10%}$ labels outperforms P2B trained with $\textbf{100%}$ labels, and achieves a $\textbf{28.4%}$ precision improvement when using $\textbf{1%}$ labels. Our code will be publicly released.
SC^2-PCR: A Second Order Spatial Compatibility for Efficient and Robust Point Cloud Registration
Mar 28, 2022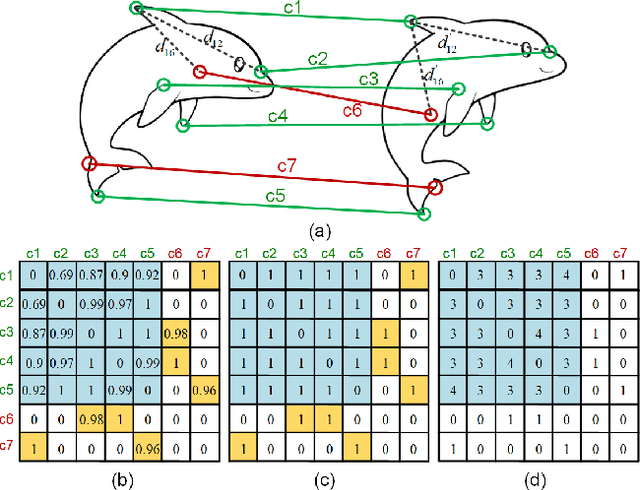
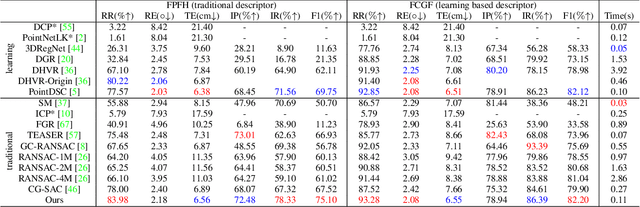

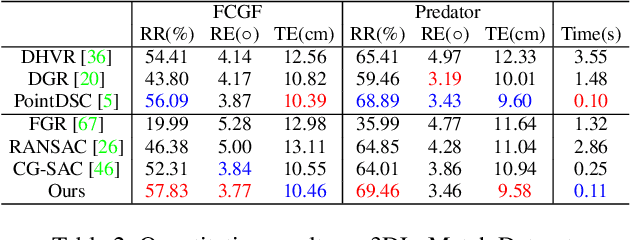
In this paper, we present a second order spatial compatibility (SC^2) measure based method for efficient and robust point cloud registration (PCR), called SC^2-PCR. Firstly, we propose a second order spatial compatibility (SC^2) measure to compute the similarity between correspondences. It considers the global compatibility instead of local consistency, allowing for more distinctive clustering between inliers and outliers at early stage. Based on this measure, our registration pipeline employs a global spectral technique to find some reliable seeds from the initial correspondences. Then we design a two-stage strategy to expand each seed to a consensus set based on the SC^2 measure matrix. Finally, we feed each consensus set to a weighted SVD algorithm to generate a candidate rigid transformation and select the best model as the final result. Our method can guarantee to find a certain number of outlier-free consensus sets using fewer samplings, making the model estimation more efficient and robust. In addition, the proposed SC^2 measure is general and can be easily plugged into deep learning based frameworks. Extensive experiments are carried out to investigate the performance of our method. Code will be available at \url{https://github.com/ZhiChen902/SC2-PCR}.
SGUIE-Net: Semantic Attention Guided Underwater Image Enhancement with Multi-Scale Perception
Jan 08, 2022



Due to the wavelength-dependent light attenuation, refraction and scattering, underwater images usually suffer from color distortion and blurred details. However, due to the limited number of paired underwater images with undistorted images as reference, training deep enhancement models for diverse degradation types is quite difficult. To boost the performance of data-driven approaches, it is essential to establish more effective learning mechanisms that mine richer supervised information from limited training sample resources. In this paper, we propose a novel underwater image enhancement network, called SGUIE-Net, in which we introduce semantic information as high-level guidance across different images that share common semantic regions. Accordingly, we propose semantic region-wise enhancement module to perceive the degradation of different semantic regions from multiple scales and feed it back to the global attention features extracted from its original scale. This strategy helps to achieve robust and visually pleasant enhancements to different semantic objects, which should thanks to the guidance of semantic information for differentiated enhancement. More importantly, for those degradation types that are not common in the training sample distribution, the guidance connects them with the already well-learned types according to their semantic relevance. Extensive experiments on the publicly available datasets and our proposed dataset demonstrated the impressive performance of SGUIE-Net. The code and proposed dataset are available at: https://trentqq.github.io/SGUIE-Net.html
A Hard Label Black-box Adversarial Attack Against Graph Neural Networks
Aug 21, 2021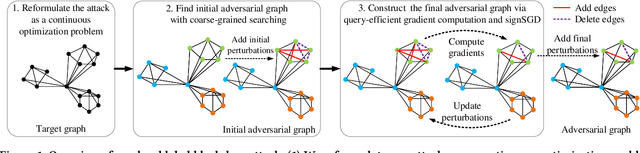
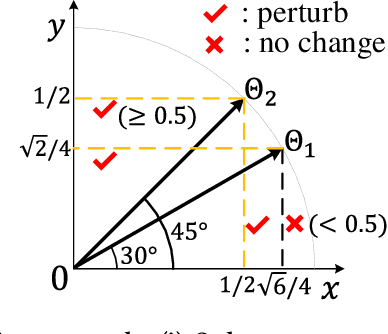
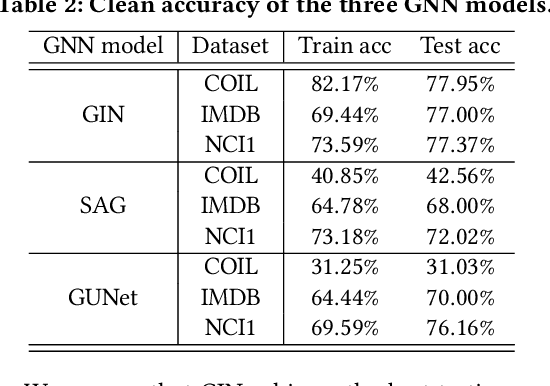
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in various graph structure related tasks such as node classification and graph classification. However, GNNs are vulnerable to adversarial attacks. Existing works mainly focus on attacking GNNs for node classification; nevertheless, the attacks against GNNs for graph classification have not been well explored. In this work, we conduct a systematic study on adversarial attacks against GNNs for graph classification via perturbing the graph structure. In particular, we focus on the most challenging attack, i.e., hard label black-box attack, where an attacker has no knowledge about the target GNN model and can only obtain predicted labels through querying the target model.To achieve this goal, we formulate our attack as an optimization problem, whose objective is to minimize the number of edges to be perturbed in a graph while maintaining the high attack success rate. The original optimization problem is intractable to solve, and we relax the optimization problem to be a tractable one, which is solved with theoretical convergence guarantee. We also design a coarse-grained searching algorithm and a query-efficient gradient computation algorithm to decrease the number of queries to the target GNN model. Our experimental results on three real-world datasets demonstrate that our attack can effectively attack representative GNNs for graph classification with less queries and perturbations. We also evaluate the effectiveness of our attack under two defenses: one is well-designed adversarial graph detector and the other is that the target GNN model itself is equipped with a defense to prevent adversarial graph generation. Our experimental results show that such defenses are not effective enough, which highlights more advanced defenses.