 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRong Wang
Robust Capped lp-Norm Support Vector Ordinal Regression
Apr 25, 2024
Ordinal regression is a specialized supervised problem where the labels show an inherent order. The order distinguishes it from normal multi-class problem. Support Vector Ordinal Regression, as an outstanding ordinal regression model, is widely used in many ordinal regression tasks. However, like most supervised learning algorithms, the design of SVOR is based on the assumption that the training data are real and reliable, which is difficult to satisfy in real-world data. In many practical applications, outliers are frequently present in the training set, potentially leading to misguide the learning process, such that the performance is non-optimal. In this paper, we propose a novel capped $\ell_{p}$-norm loss function that is theoretically robust to both light and heavy outliers. The capped $\ell_{p}$-norm loss can help the model detect and eliminate outliers during training process. Adhering to this concept, we introduce a new model, Capped $\ell_{p}$-Norm Support Vector Ordinal Regression(CSVOR), that is robust to outliers. CSVOR uses a weight matrix to detect and eliminate outliers during the training process to improve the robustness to outliers. Moreover, a Re-Weighted algorithm algorithm which is illustrated convergence by our theoretical results is proposed to effectively minimize the corresponding problem. Extensive experimental results demonstrate that our model outperforms state-of-the-art(SOTA) methods, particularly in the presence of outliers.
Dual Model Replacement:invisible Multi-target Backdoor Attack based on Federal Learning
Apr 22, 2024In recent years, the neural network backdoor hidden in the parameters of the federated learning model has been proved to have great security risks. Considering the characteristics of trigger generation, data poisoning and model training in backdoor attack, this paper designs a backdoor attack method based on federated learning. Firstly, aiming at the concealment of the backdoor trigger, a TrojanGan steganography model with encoder-decoder structure is designed. The model can encode specific attack information as invisible noise and attach it to the image as a backdoor trigger, which improves the concealment and data transformations of the backdoor trigger.Secondly, aiming at the problem of single backdoor trigger mode, an image poisoning attack method called combination trigger attack is proposed. This method realizes multi-backdoor triggering by multiplexing combined triggers and improves the robustness of backdoor attacks. Finally, aiming at the problem that the local training mechanism leads to the decrease of the success rate of backdoor attack, a dual model replacement backdoor attack algorithm based on federated learning is designed. This method can improve the success rate of backdoor attack while maintaining the performance of the federated learning aggregation model. Experiments show that the attack strategy in this paper can not only achieve high backdoor concealment and diversification of trigger forms under federated learning, but also achieve good attack success rate in multi-target attacks.door concealment and diversification of trigger forms but also achieve good results in multi-target attacks.
Differential contributions of machine learning and statistical analysis to language and cognitive sciences
Apr 22, 2024Data-driven approaches have revolutionized scientific research. Machine learning and statistical analysis are commonly utilized in this type of research. Despite their widespread use, these methodologies differ significantly in their techniques and objectives. Few studies have utilized a consistent dataset to demonstrate these differences within the social sciences, particularly in language and cognitive sciences. This study leverages the Buckeye Speech Corpus to illustrate how both machine learning and statistical analysis are applied in data-driven research to obtain distinct insights. This study significantly enhances our understanding of the diverse approaches employed in data-driven strategies.
TIMIT Speaker Profiling: A Comparison of Multi-task learning and Single-task learning Approaches
Apr 18, 2024This study employs deep learning techniques to explore four speaker profiling tasks on the TIMIT dataset, namely gender classification, accent classification, age estimation, and speaker identification, highlighting the potential and challenges of multi-task learning versus single-task models. The motivation for this research is twofold: firstly, to empirically assess the advantages and drawbacks of multi-task learning over single-task models in the context of speaker profiling; secondly, to emphasize the undiminished significance of skillful feature engineering for speaker recognition tasks. The findings reveal challenges in accent classification, and multi-task learning is found advantageous for tasks of similar complexity. Non-sequential features are favored for speaker recognition, but sequential ones can serve as starting points for complex models. The study underscores the necessity of meticulous experimentation and parameter tuning for deep learning models.
Computational Sentence-level Metrics Predicting Human Sentence Comprehension
Mar 23, 2024The majority of research in computational psycholinguistics has concentrated on the processing of words. This study introduces innovative methods for computing sentence-level metrics using multilingual large language models. The metrics developed sentence surprisal and sentence relevance and then are tested and compared to validate whether they can predict how humans comprehend sentences as a whole across languages. These metrics offer significant interpretability and achieve high accuracy in predicting human sentence reading speeds. Our results indicate that these computational sentence-level metrics are exceptionally effective at predicting and elucidating the processing difficulties encountered by readers in comprehending sentences as a whole across a variety of languages. Their impressive performance and generalization capabilities provide a promising avenue for future research in integrating LLMs and cognitive science.
Comprehensive Reassessment of Large-Scale Evaluation Outcomes in LLMs: A Multifaceted Statistical Approach
Mar 22, 2024Amidst the rapid evolution of LLMs, the significance of evaluation in comprehending and propelling these models forward is increasingly paramount. Evaluations have revealed that factors such as scaling, training types, architectures and other factors profoundly impact the performance of LLMs. However, the extent and nature of these impacts continue to be subjects of debate because most assessments have been restricted to a limited number of models and data points. Clarifying the effects of these factors on performance scores can be more effectively achieved through a statistical lens. Our study embarks on a thorough re-examination of these LLMs, targeting the inadequacies in current evaluation methods. With the advent of a uniform evaluation framework, our research leverages an expansive dataset of evaluation results, introducing a comprehensive statistical methodology. This includes the application of ANOVA, Tukey HSD tests, GAMM, and clustering technique, offering a robust and transparent approach to deciphering LLM performance data. Contrary to prevailing findings, our results challenge assumptions about emergent abilities and the influence of given training types and architectures in LLMs. These findings furnish new perspectives on the characteristics, intrinsic nature, and developmental trajectories of LLMs. By providing straightforward and reliable methods to scrutinize and reassess LLM performance data, this study contributes a nuanced perspective on LLM efficiency and potentials.
Multi-class Support Vector Machine with Maximizing Minimum Margin
Dec 15, 2023Support Vector Machine (SVM) stands out as a prominent machine learning technique widely applied in practical pattern recognition tasks. It achieves binary classification by maximizing the "margin", which represents the minimum distance between instances and the decision boundary. Although many efforts have been dedicated to expanding SVM for multi-class case through strategies such as one versus one and one versus the rest, satisfactory solutions remain to be developed. In this paper, we propose a novel method for multi-class SVM that incorporates pairwise class loss considerations and maximizes the minimum margin. Adhering to this concept, we embrace a new formulation that imparts heightened flexibility to multi-class SVM. Furthermore, the correlations between the proposed method and multiple forms of multi-class SVM are analyzed. The proposed regularizer, akin to the concept of "margin", can serve as a seamless enhancement over the softmax in deep learning, providing guidance for network parameter learning. Empirical evaluations demonstrate the effectiveness and superiority of our proposed method over existing multi-classification methods.Code is available at https://github.com/zz-haooo/M3SVM.
A Novel Normalized-Cut Solver with Nearest Neighbor Hierarchical Initialization
Nov 26, 2023Normalized-Cut (N-Cut) is a famous model of spectral clustering. The traditional N-Cut solvers are two-stage: 1) calculating the continuous spectral embedding of normalized Laplacian matrix; 2) discretization via $K$-means or spectral rotation. However, this paradigm brings two vital problems: 1) two-stage methods solve a relaxed version of the original problem, so they cannot obtain good solutions for the original N-Cut problem; 2) solving the relaxed problem requires eigenvalue decomposition, which has $\mathcal{O}(n^3)$ time complexity ($n$ is the number of nodes). To address the problems, we propose a novel N-Cut solver designed based on the famous coordinate descent method. Since the vanilla coordinate descent method also has $\mathcal{O}(n^3)$ time complexity, we design various accelerating strategies to reduce the time complexity to $\mathcal{O}(|E|)$ ($|E|$ is the number of edges). To avoid reliance on random initialization which brings uncertainties to clustering, we propose an efficient initialization method that gives deterministic outputs. Extensive experiments on several benchmark datasets demonstrate that the proposed solver can obtain larger objective values of N-Cut, meanwhile achieving better clustering performance compared to traditional solvers.
DeepSimHO: Stable Pose Estimation for Hand-Object Interaction via Physics Simulation
Oct 11, 2023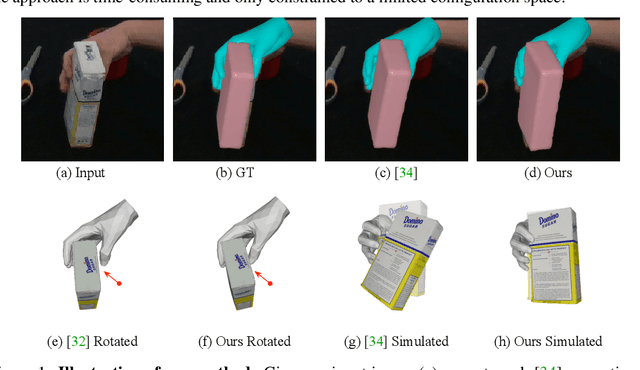
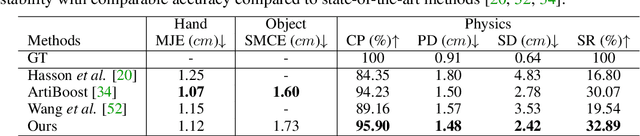

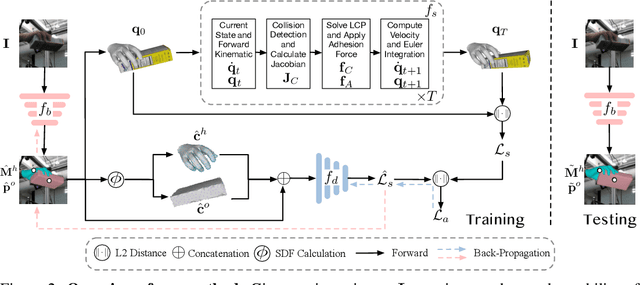
This paper addresses the task of 3D pose estimation for a hand interacting with an object from a single image observation. When modeling hand-object interaction, previous works mainly exploit proximity cues, while overlooking the dynamical nature that the hand must stably grasp the object to counteract gravity and thus preventing the object from slipping or falling. These works fail to leverage dynamical constraints in the estimation and consequently often produce unstable results. Meanwhile, refining unstable configurations with physics-based reasoning remains challenging, both by the complexity of contact dynamics and by the lack of effective and efficient physics inference in the data-driven learning framework. To address both issues, we present DeepSimHO: a novel deep-learning pipeline that combines forward physics simulation and backward gradient approximation with a neural network. Specifically, for an initial hand-object pose estimated by a base network, we forward it to a physics simulator to evaluate its stability. However, due to non-smooth contact geometry and penetration, existing differentiable simulators can not provide reliable state gradient. To remedy this, we further introduce a deep network to learn the stability evaluation process from the simulator, while smoothly approximating its gradient and thus enabling effective back-propagation. Extensive experiments show that our method noticeably improves the stability of the estimation and achieves superior efficiency over test-time optimization. The code is available at https://github.com/rongakowang/DeepSimHO.
OCU-Net: A Novel U-Net Architecture for Enhanced Oral Cancer Segmentation
Oct 03, 2023Accurate detection of oral cancer is crucial for improving patient outcomes. However, the field faces two key challenges: the scarcity of deep learning-based image segmentation research specifically targeting oral cancer and the lack of annotated data. Our study proposes OCU-Net, a pioneering U-Net image segmentation architecture exclusively designed to detect oral cancer in hematoxylin and eosin (H&E) stained image datasets. OCU-Net incorporates advanced deep learning modules, such as the Channel and Spatial Attention Fusion (CSAF) module, a novel and innovative feature that emphasizes important channel and spatial areas in H&E images while exploring contextual information. In addition, OCU-Net integrates other innovative components such as Squeeze-and-Excite (SE) attention module, Atrous Spatial Pyramid Pooling (ASPP) module, residual blocks, and multi-scale fusion. The incorporation of these modules showed superior performance for oral cancer segmentation for two datasets used in this research. Furthermore, we effectively utilized the efficient ImageNet pre-trained MobileNet-V2 model as a backbone of our OCU-Net to create OCU-Netm, an enhanced version achieving state-of-the-art results. Comprehensive evaluation demonstrates that OCU-Net and OCU-Netm outperformed existing segmentation methods, highlighting their precision in identifying cancer cells in H&E images from OCDC and ORCA datasets.