 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiang Gao
SPUQ: Perturbation-Based Uncertainty Quantification for Large Language Models
Mar 04, 2024
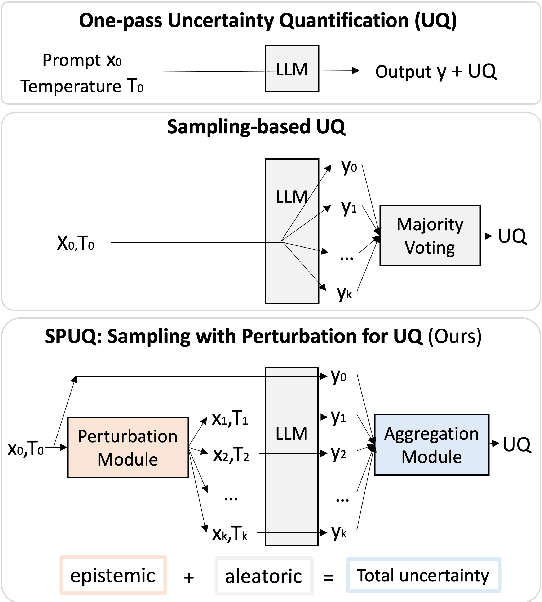

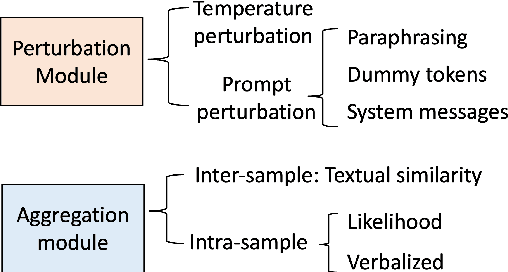

In recent years, large language models (LLMs) have become increasingly prevalent, offering remarkable text generation capabilities. However, a pressing challenge is their tendency to make confidently wrong predictions, highlighting the critical need for uncertainty quantification (UQ) in LLMs. While previous works have mainly focused on addressing aleatoric uncertainty, the full spectrum of uncertainties, including epistemic, remains inadequately explored. Motivated by this gap, we introduce a novel UQ method, sampling with perturbation for UQ (SPUQ), designed to tackle both aleatoric and epistemic uncertainties. The method entails generating a set of perturbations for LLM inputs, sampling outputs for each perturbation, and incorporating an aggregation module that generalizes the sampling uncertainty approach for text generation tasks. Through extensive experiments on various datasets, we investigated different perturbation and aggregation techniques. Our findings show a substantial improvement in model uncertainty calibration, with a reduction in Expected Calibration Error (ECE) by 50\% on average. Our findings suggest that our proposed UQ method offers promising steps toward enhancing the reliability and trustworthiness of LLMs.
RKHS-BA: A Semantic Correspondence-Free Multi-View Registration Framework with Global Tracking
Mar 02, 2024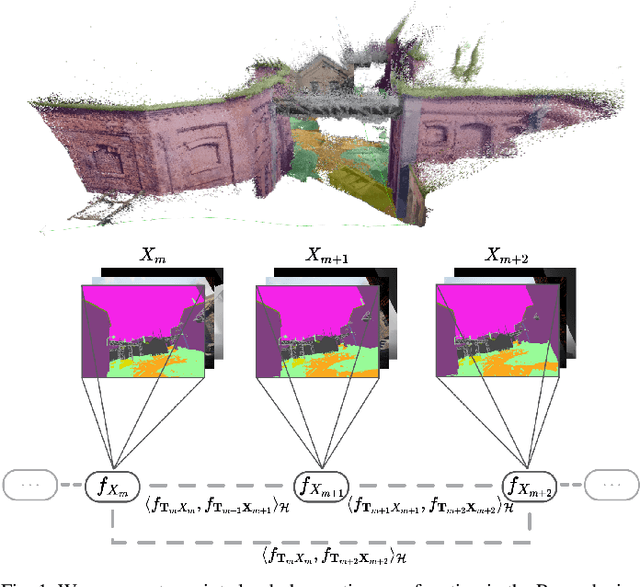
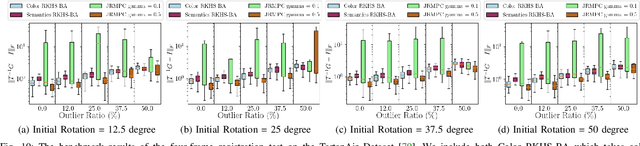
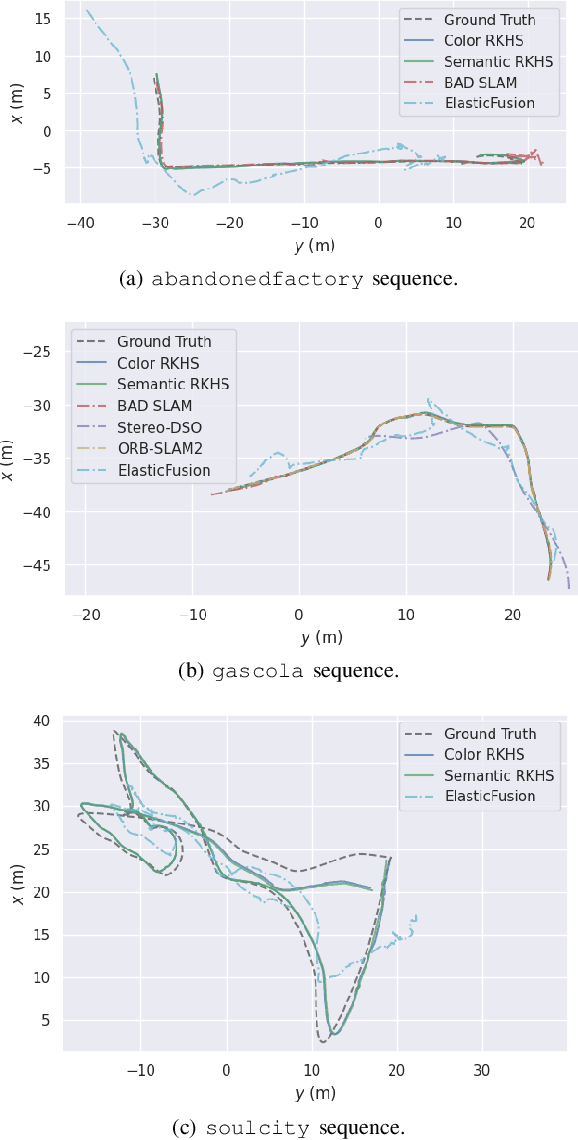

This work reports a novel Bundle Adjustment (BA) formulation using a Reproducing Kernel Hilbert Space (RKHS) representation called RKHS-BA. The proposed formulation is correspondence-free, enables the BA to use RGB-D/LiDAR and semantic labels in the optimization directly, and provides a generalization for the photometric loss function commonly used in direct methods. RKHS-BA can incorporate appearance and semantic labels within a continuous spatial-semantic functional representation that does not require optimization via image pyramids. We demonstrate its applications in sliding-window odometry and global LiDAR mapping, which show highly robust performance in extremely challenging scenes and the best trade-off of generalization and accuracy.
Generative 3D Part Assembly via Part-Whole-Hierarchy Message Passing
Feb 27, 2024Generative 3D part assembly involves understanding part relationships and predicting their 6-DoF poses for assembling a realistic 3D shape. Prior work often focus on the geometry of individual parts, neglecting part-whole hierarchies of objects. Leveraging two key observations: 1) super-part poses provide strong hints about part poses, and 2) predicting super-part poses is easier due to fewer superparts, we propose a part-whole-hierarchy message passing network for efficient 3D part assembly. We first introduce super-parts by grouping geometrically similar parts without any semantic labels. Then we employ a part-whole hierarchical encoder, wherein a super-part encoder predicts latent super-part poses based on input parts. Subsequently, we transform the point cloud using the latent poses, feeding it to the part encoder for aggregating super-part information and reasoning about part relationships to predict all part poses. In training, only ground-truth part poses are required. During inference, the predicted latent poses of super-parts enhance interpretability. Experimental results on the PartNet dataset show that our method achieves state-of-the-art performance in part and connectivity accuracy and enables an interpretable hierarchical part assembly.
Investigating White-Box Attacks for On-Device Models
Feb 26, 2024Numerous mobile apps have leveraged deep learning capabilities. However, on-device models are vulnerable to attacks as they can be easily extracted from their corresponding mobile apps. Existing on-device attacking approaches only generate black-box attacks, which are far less effective and efficient than white-box strategies. This is because mobile deep learning frameworks like TFLite do not support gradient computing, which is necessary for white-box attacking algorithms. Thus, we argue that existing findings may underestimate the harmfulness of on-device attacks. To this end, we conduct a study to answer this research question: Can on-device models be directly attacked via white-box strategies? We first systematically analyze the difficulties of transforming the on-device model to its debuggable version, and propose a Reverse Engineering framework for On-device Models (REOM), which automatically reverses the compiled on-device TFLite model to the debuggable model. Specifically, REOM first transforms compiled on-device models into Open Neural Network Exchange format, then removes the non-debuggable parts, and converts them to the debuggable DL models format that allows attackers to exploit in a white-box setting. Our experimental results show that our approach is effective in achieving automated transformation among 244 TFLite models. Compared with previous attacks using surrogate models, REOM enables attackers to achieve higher attack success rates with a hundred times smaller attack perturbations. In addition, because the ONNX platform has plenty of tools for model format exchanging, the proposed method based on the ONNX platform can be adapted to other model formats. Our findings emphasize the need for developers to carefully consider their model deployment strategies, and use white-box methods to evaluate the vulnerability of on-device models.
Customizing Language Model Responses with Contrastive In-Context Learning
Jan 30, 2024Large language models (LLMs) are becoming increasingly important for machine learning applications. However, it can be challenging to align LLMs with our intent, particularly when we want to generate content that is preferable over others or when we want the LLM to respond in a certain style or tone that is hard to describe. To address this challenge, we propose an approach that uses contrastive examples to better describe our intent. This involves providing positive examples that illustrate the true intent, along with negative examples that show what characteristics we want LLMs to avoid. The negative examples can be retrieved from labeled data, written by a human, or generated by the LLM itself. Before generating an answer, we ask the model to analyze the examples to teach itself what to avoid. This reasoning step provides the model with the appropriate articulation of the user's need and guides it towards generting a better answer. We tested our approach on both synthesized and real-world datasets, including StackExchange and Reddit, and found that it significantly improves performance compared to standard few-shot prompting
InvariantOODG: Learning Invariant Features of Point Clouds for Out-of-Distribution Generalization
Jan 08, 2024The convenience of 3D sensors has led to an increase in the use of 3D point clouds in various applications. However, the differences in acquisition devices or scenarios lead to divergence in the data distribution of point clouds, which requires good generalization of point cloud representation learning methods. While most previous methods rely on domain adaptation, which involves fine-tuning pre-trained models on target domain data, this may not always be feasible in real-world scenarios where target domain data may be unavailable. To address this issue, we propose InvariantOODG, which learns invariability between point clouds with different distributions using a two-branch network to extract local-to-global features from original and augmented point clouds. Specifically, to enhance local feature learning of point clouds, we define a set of learnable anchor points that locate the most useful local regions and two types of transformations to augment the input point clouds. The experimental results demonstrate the effectiveness of the proposed model on 3D domain generalization benchmarks.
Machine Learning Driven Sensitivity Analysis of E3SM Land Model Parameters for Wetland Methane Emissions
Dec 05, 2023Methane (CH4) is the second most critical greenhouse gas after carbon dioxide, contributing to 16-25% of the observed atmospheric warming. Wetlands are the primary natural source of methane emissions globally. However, wetland methane emission estimates from biogeochemistry models contain considerable uncertainty. One of the main sources of this uncertainty arises from the numerous uncertain model parameters within various physical, biological, and chemical processes that influence methane production, oxidation, and transport. Sensitivity Analysis (SA) can help identify critical parameters for methane emission and achieve reduced biases and uncertainties in future projections. This study performs SA for 19 selected parameters responsible for critical biogeochemical processes in the methane module of the Energy Exascale Earth System Model (E3SM) land model (ELM). The impact of these parameters on various CH4 fluxes is examined at 14 FLUXNET- CH4 sites with diverse vegetation types. Given the extensive number of model simulations needed for global variance-based SA, we employ a machine learning (ML) algorithm to emulate the complex behavior of ELM methane biogeochemistry. ML enables the computational time to be shortened significantly from 6 CPU hours to 0.72 milliseconds, achieving reduced computational costs. We found that parameters linked to CH4 production and diffusion generally present the highest sensitivities despite apparent seasonal variation. Comparing simulated emissions from perturbed parameter sets against FLUXNET-CH4 observations revealed that better performances can be achieved at each site compared to the default parameter values. This presents a scope for further improving simulated emissions using parameter calibration with advanced optimization techniques like Bayesian optimization.
Structured Neural Networks for Density Estimation and Causal Inference
Nov 03, 2023Injecting structure into neural networks enables learning functions that satisfy invariances with respect to subsets of inputs. For instance, when learning generative models using neural networks, it is advantageous to encode the conditional independence structure of observed variables, often in the form of Bayesian networks. We propose the Structured Neural Network (StrNN), which injects structure through masking pathways in a neural network. The masks are designed via a novel relationship we explore between neural network architectures and binary matrix factorization, to ensure that the desired independencies are respected. We devise and study practical algorithms for this otherwise NP-hard design problem based on novel objectives that control the model architecture. We demonstrate the utility of StrNN in three applications: (1) binary and Gaussian density estimation with StrNN, (2) real-valued density estimation with Structured Autoregressive Flows (StrAFs) and Structured Continuous Normalizing Flows (StrCNF), and (3) interventional and counterfactual analysis with StrAFs for causal inference. Our work opens up new avenues for learning neural networks that enable data-efficient generative modeling and the use of normalizing flows for causal effect estimation.
Colmap-PCD: An Open-source Tool for Fine Image-to-point cloud Registration
Oct 09, 2023State-of-the-art techniques for monocular camera reconstruction predominantly rely on the Structure from Motion (SfM) pipeline. However, such methods often yield reconstruction outcomes that lack crucial scale information, and over time, accumulation of images leads to inevitable drift issues. In contrast, mapping methods based on LiDAR scans are popular in large-scale urban scene reconstruction due to their precise distance measurements, a capability fundamentally absent in visual-based approaches. Researchers have made attempts to utilize concurrent LiDAR and camera measurements in pursuit of precise scaling and color details within mapping outcomes. However, the outcomes are subject to extrinsic calibration and time synchronization precision. In this paper, we propose a novel cost-effective reconstruction pipeline that utilizes a pre-established LiDAR map as a fixed constraint to effectively address the inherent scale challenges present in monocular camera reconstruction. To our knowledge, our method is the first to register images onto the point cloud map without requiring synchronous capture of camera and LiDAR data, granting us the flexibility to manage reconstruction detail levels across various areas of interest. To facilitate further research in this domain, we have released Colmap-PCD${^{3}}$, an open-source tool leveraging the Colmap algorithm, that enables precise fine-scale registration of images to the point cloud map.
Incremental Rotation Averaging Revisited and More: A New Rotation Averaging Benchmark
Sep 29, 2023In order to further advance the accuracy and robustness of the incremental parameter estimation-based rotation averaging methods, in this paper, a new member of the Incremental Rotation Averaging (IRA) family is introduced, which is termed as IRAv4. As the most significant feature of the IRAv4, a task-specific connected dominating set is extracted to serve as a more reliable and accurate reference for rotation global alignment. In addition, to further address the limitations of the existing rotation averaging benchmark of relying on the slightly outdated Bundler camera calibration results as ground truths and focusing solely on rotation estimation accuracy, this paper presents a new COLMAP-based rotation averaging benchmark that incorporates a cross check between COLMAP and Bundler, and employ the accuracy of both rotation and downstream location estimation as evaluation metrics, which is desired to provide a more reliable and comprehensive evaluation tool for the rotation averaging research. Comprehensive comparisons between the proposed IRAv4 and other mainstream rotation averaging methods on this new benchmark demonstrate the effectiveness of our proposed approach.