 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaxin Zhang
VRSO: Visual-Centric Reconstruction for Static Object Annotation
Mar 22, 2024
As a part of the perception results of intelligent driving systems, static object detection (SOD) in 3D space provides crucial cues for driving environment understanding. With the rapid deployment of deep neural networks for SOD tasks, the demand for high-quality training samples soars. The traditional, also reliable, way is manual labeling over the dense LiDAR point clouds and reference images. Though most public driving datasets adopt this strategy to provide SOD ground truth (GT), it is still expensive (requires LiDAR scanners) and low-efficient (time-consuming and unscalable) in practice. This paper introduces VRSO, a visual-centric approach for static object annotation. VRSO is distinguished in low cost, high efficiency, and high quality: (1) It recovers static objects in 3D space with only camera images as input, and (2) manual labeling is barely involved since GT for SOD tasks is generated based on an automatic reconstruction and annotation pipeline. (3) Experiments on the Waymo Open Dataset show that the mean reprojection error from VRSO annotation is only 2.6 pixels, around four times lower than the Waymo labeling (10.6 pixels). Source code is available at: https://github.com/CaiYingFeng/VRSO.
SPUQ: Perturbation-Based Uncertainty Quantification for Large Language Models
Mar 04, 2024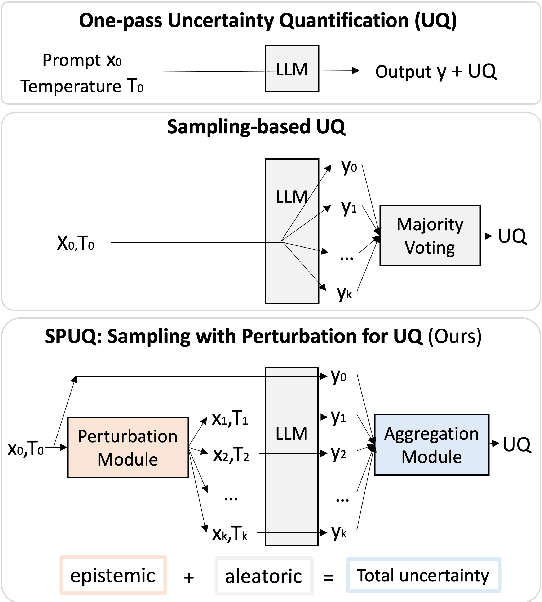

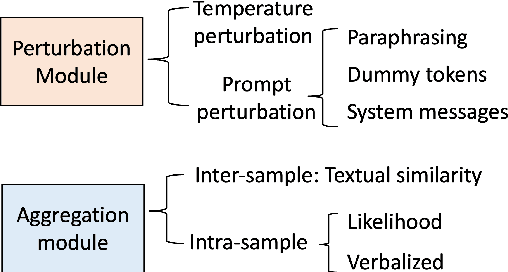

In recent years, large language models (LLMs) have become increasingly prevalent, offering remarkable text generation capabilities. However, a pressing challenge is their tendency to make confidently wrong predictions, highlighting the critical need for uncertainty quantification (UQ) in LLMs. While previous works have mainly focused on addressing aleatoric uncertainty, the full spectrum of uncertainties, including epistemic, remains inadequately explored. Motivated by this gap, we introduce a novel UQ method, sampling with perturbation for UQ (SPUQ), designed to tackle both aleatoric and epistemic uncertainties. The method entails generating a set of perturbations for LLM inputs, sampling outputs for each perturbation, and incorporating an aggregation module that generalizes the sampling uncertainty approach for text generation tasks. Through extensive experiments on various datasets, we investigated different perturbation and aggregation techniques. Our findings show a substantial improvement in model uncertainty calibration, with a reduction in Expected Calibration Error (ECE) by 50\% on average. Our findings suggest that our proposed UQ method offers promising steps toward enhancing the reliability and trustworthiness of LLMs.
Discriminant Distance-Aware Representation on Deterministic Uncertainty Quantification Methods
Feb 20, 2024Uncertainty estimation is a crucial aspect of deploying dependable deep learning models in safety-critical systems. In this study, we introduce a novel and efficient method for deterministic uncertainty estimation called Discriminant Distance-Awareness Representation (DDAR). Our approach involves constructing a DNN model that incorporates a set of prototypes in its latent representations, enabling us to analyze valuable feature information from the input data. By leveraging a distinction maximization layer over optimal trainable prototypes, DDAR can learn a discriminant distance-awareness representation. We demonstrate that DDAR overcomes feature collapse by relaxing the Lipschitz constraint that hinders the practicality of deterministic uncertainty methods (DUMs) architectures. Our experiments show that DDAR is a flexible and architecture-agnostic method that can be easily integrated as a pluggable layer with distance-sensitive metrics, outperforming state-of-the-art uncertainty estimation methods on multiple benchmark problems.
PhaseEvo: Towards Unified In-Context Prompt Optimization for Large Language Models
Feb 17, 2024Crafting an ideal prompt for Large Language Models (LLMs) is a challenging task that demands significant resources and expert human input. Existing work treats the optimization of prompt instruction and in-context learning examples as distinct problems, leading to sub-optimal prompt performance. This research addresses this limitation by establishing a unified in-context prompt optimization framework, which aims to achieve joint optimization of the prompt instruction and examples. However, formulating such optimization in the discrete and high-dimensional natural language space introduces challenges in terms of convergence and computational efficiency. To overcome these issues, we present PhaseEvo, an efficient automatic prompt optimization framework that combines the generative capability of LLMs with the global search proficiency of evolution algorithms. Our framework features a multi-phase design incorporating innovative LLM-based mutation operators to enhance search efficiency and accelerate convergence. We conduct an extensive evaluation of our approach across 35 benchmark tasks. The results demonstrate that PhaseEvo significantly outperforms the state-of-the-art baseline methods by a large margin whilst maintaining good efficiency.
GeoEval: Benchmark for Evaluating LLMs and Multi-Modal Models on Geometry Problem-Solving
Feb 15, 2024Recent advancements in Large Language Models (LLMs) and Multi-Modal Models (MMs) have demonstrated their remarkable capabilities in problem-solving. Yet, their proficiency in tackling geometry math problems, which necessitates an integrated understanding of both textual and visual information, has not been thoroughly evaluated. To address this gap, we introduce the GeoEval benchmark, a comprehensive collection that includes a main subset of 2000 problems, a 750 problem subset focusing on backward reasoning, an augmented subset of 2000 problems, and a hard subset of 300 problems. This benchmark facilitates a deeper investigation into the performance of LLMs and MMs on solving geometry math problems. Our evaluation of ten LLMs and MMs across these varied subsets reveals that the WizardMath model excels, achieving a 55.67\% accuracy rate on the main subset but only a 6.00\% accuracy on the challenging subset. This highlights the critical need for testing models against datasets on which they have not been pre-trained. Additionally, our findings indicate that GPT-series models perform more effectively on problems they have rephrased, suggesting a promising method for enhancing model capabilities.
GAPS: Geometry-Aware Problem Solver
Jan 29, 2024Geometry problem solving presents a formidable challenge within the NLP community. Existing approaches often rely on models designed for solving math word problems, neglecting the unique characteristics of geometry math problems. Additionally, the current research predominantly focuses on geometry calculation problems, while overlooking other essential aspects like proving. In this study, we address these limitations by proposing the Geometry-Aware Problem Solver (GAPS) model. GAPS is specifically designed to generate solution programs for geometry math problems of various types with the help of its unique problem-type classifier. To achieve this, GAPS treats the solution program as a composition of operators and operands, segregating their generation processes. Furthermore, we introduce the geometry elements enhancement method, which enhances the ability of GAPS to recognize geometry elements accurately. By leveraging these improvements, GAPS showcases remarkable performance in resolving geometry math problems. Our experiments conducted on the UniGeo dataset demonstrate the superiority of GAPS over the state-of-the-art model, Geoformer. Specifically, GAPS achieves an accuracy improvement of more than 5.3% for calculation tasks and an impressive 41.1% for proving tasks. Notably, GAPS achieves an impressive accuracy of 97.5% on proving problems, representing a significant advancement in solving geometry proving tasks.
GLOCALFAIR: Jointly Improving Global and Local Group Fairness in Federated Learning
Jan 07, 2024Federated learning (FL) has emerged as a prospective solution for collaboratively learning a shared model across clients without sacrificing their data privacy. However, the federated learned model tends to be biased against certain demographic groups (e.g., racial and gender groups) due to the inherent FL properties, such as data heterogeneity and party selection. Unlike centralized learning, mitigating bias in FL is particularly challenging as private training datasets and their sensitive attributes are typically not directly accessible. Most prior research in this field only focuses on global fairness while overlooking the local fairness of individual clients. Moreover, existing methods often require sensitive information about the client's local datasets to be shared, which is not desirable. To address these issues, we propose GLOCALFAIR, a client-server co-design fairness framework that can jointly improve global and local group fairness in FL without the need for sensitive statistics about the client's private datasets. Specifically, we utilize constrained optimization to enforce local fairness on the client side and adopt a fairness-aware clustering-based aggregation on the server to further ensure the global model fairness across different sensitive groups while maintaining high utility. Experiments on two image datasets and one tabular dataset with various state-of-the-art fairness baselines show that GLOCALFAIR can achieve enhanced fairness under both global and local data distributions while maintaining a good level of utility and client fairness.
DCR-Consistency: Divide-Conquer-Reasoning for Consistency Evaluation and Improvement of Large Language Models
Jan 04, 2024Evaluating the quality and variability of text generated by Large Language Models (LLMs) poses a significant, yet unresolved research challenge. Traditional evaluation methods, such as ROUGE and BERTScore, which measure token similarity, often fail to capture the holistic semantic equivalence. This results in a low correlation with human judgments and intuition, which is especially problematic in high-stakes applications like healthcare and finance where reliability, safety, and robust decision-making are highly critical. This work proposes DCR, an automated framework for evaluating and improving the consistency of LLM-generated texts using a divide-conquer-reasoning approach. Unlike existing LLM-based evaluators that operate at the paragraph level, our method employs a divide-and-conquer evaluator (DCE) that breaks down the paragraph-to-paragraph comparison between two generated responses into individual sentence-to-paragraph comparisons, each evaluated based on predefined criteria. To facilitate this approach, we introduce an automatic metric converter (AMC) that translates the output from DCE into an interpretable numeric score. Beyond the consistency evaluation, we further present a reason-assisted improver (RAI) that leverages the analytical reasons with explanations identified by DCE to generate new responses aimed at reducing these inconsistencies. Through comprehensive and systematic empirical analysis, we show that our approach outperforms state-of-the-art methods by a large margin (e.g., +19.3% and +24.3% on the SummEval dataset) in evaluating the consistency of LLM generation across multiple benchmarks in semantic, factual, and summarization consistency tasks. Our approach also substantially reduces nearly 90% of output inconsistencies, showing promise for effective hallucination mitigation.
UPOCR: Towards Unified Pixel-Level OCR Interface
Dec 05, 2023In recent years, the optical character recognition (OCR) field has been proliferating with plentiful cutting-edge approaches for a wide spectrum of tasks. However, these approaches are task-specifically designed with divergent paradigms, architectures, and training strategies, which significantly increases the complexity of research and maintenance and hinders the fast deployment in applications. To this end, we propose UPOCR, a simple-yet-effective generalist model for Unified Pixel-level OCR interface. Specifically, the UPOCR unifies the paradigm of diverse OCR tasks as image-to-image transformation and the architecture as a vision Transformer (ViT)-based encoder-decoder. Learnable task prompts are introduced to push the general feature representations extracted by the encoder toward task-specific spaces, endowing the decoder with task awareness. Moreover, the model training is uniformly aimed at minimizing the discrepancy between the generated and ground-truth images regardless of the inhomogeneity among tasks. Experiments are conducted on three pixel-level OCR tasks including text removal, text segmentation, and tampered text detection. Without bells and whistles, the experimental results showcase that the proposed method can simultaneously achieve state-of-the-art performance on three tasks with a unified single model, which provides valuable strategies and insights for future research on generalist OCR models. Code will be publicly available.
Advancing Urban Renewal: An Automated Approach to Generating Historical Arcade Facades with Stable Diffusion Models
Nov 20, 2023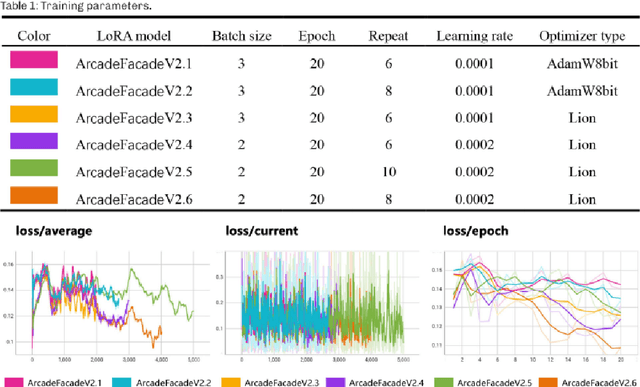

Urban renewal and transformation processes necessitate the preservation of the historical urban fabric, particularly in districts known for their architectural and historical significance. These regions, with their diverse architectural styles, have traditionally required extensive preliminary research, often leading to subjective results. However, the advent of machine learning models has opened up new avenues for generating building facade images. Despite this, creating high-quality images for historical district renovations remains challenging, due to the complexity and diversity inherent in such districts. In response to these challenges, our study introduces a new methodology for automatically generating images of historical arcade facades, utilizing Stable Diffusion models conditioned on textual descriptions. By classifying and tagging a variety of arcade styles, we have constructed several realistic arcade facade image datasets. We trained multiple low-rank adaptation (LoRA) models to control the stylistic aspects of the generated images, supplemented by ControlNet models for improved precision and authenticity. Our approach has demonstrated high levels of precision, authenticity, and diversity in the generated images, showing promising potential for real-world urban renewal projects. This new methodology offers a more efficient and accurate alternative to conventional design processes in urban renewal, bypassing issues of unconvincing image details, lack of precision, and limited stylistic variety. Future research could focus on integrating this two-dimensional image generation with three-dimensional modeling techniques, providing a more comprehensive solution for renovating architectural facades in historical districts.