 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinwang Liu
Part-aware Shape Generation with Latent 3D Diffusion of Neural Voxel Fields
May 02, 2024
This paper presents a novel latent 3D diffusion model for the generation of neural voxel fields, aiming to achieve accurate part-aware structures. Compared to existing methods, there are two key designs to ensure high-quality and accurate part-aware generation. On one hand, we introduce a latent 3D diffusion process for neural voxel fields, enabling generation at significantly higher resolutions that can accurately capture rich textural and geometric details. On the other hand, a part-aware shape decoder is introduced to integrate the part codes into the neural voxel fields, guiding the accurate part decomposition and producing high-quality rendering results. Through extensive experimentation and comparisons with state-of-the-art methods, we evaluate our approach across four different classes of data. The results demonstrate the superior generative capabilities of our proposed method in part-aware shape generation, outperforming existing state-of-the-art methods.
Test-Time Training on Graphs with Large Language Models (LLMs)
Apr 21, 2024Graph Neural Networks have demonstrated great success in various fields of multimedia. However, the distribution shift between the training and test data challenges the effectiveness of GNNs. To mitigate this challenge, Test-Time Training (TTT) has been proposed as a promising approach. Traditional TTT methods require a demanding unsupervised training strategy to capture the information from test to benefit the main task. Inspired by the great annotation ability of Large Language Models (LLMs) on Text-Attributed Graphs (TAGs), we propose to enhance the test-time training on graphs with LLMs as annotators. In this paper, we design a novel Test-Time Training pipeline, LLMTTT, which conducts the test-time adaptation under the annotations by LLMs on a carefully-selected node set. Specifically, LLMTTT introduces a hybrid active node selection strategy that considers not only node diversity and representativeness, but also prediction signals from the pre-trained model. Given annotations from LLMs, a two-stage training strategy is designed to tailor the test-time model with the limited and noisy labels. A theoretical analysis ensures the validity of our method and extensive experiments demonstrate that the proposed LLMTTT can achieve a significant performance improvement compared to existing Out-of-Distribution (OOD) generalization methods.
AdvLoRA: Adversarial Low-Rank Adaptation of Vision-Language Models
Apr 20, 2024Vision-Language Models (VLMs) are a significant technique for Artificial General Intelligence (AGI). With the fast growth of AGI, the security problem become one of the most important challenges for VLMs. In this paper, through extensive experiments, we demonstrate the vulnerability of the conventional adaptation methods for VLMs, which may bring significant security risks. In addition, as the size of the VLMs increases, performing conventional adversarial adaptation techniques on VLMs results in high computational costs. To solve these problems, we propose a parameter-efficient \underline{Adv}ersarial adaptation method named \underline{AdvLoRA} by \underline{Lo}w-\underline{R}ank \underline{A}daptation. At first, we investigate and reveal the intrinsic low-rank property during the adversarial adaptation for VLMs. Different from LoRA, we improve the efficiency and robustness of adversarial adaptation by designing a novel reparameterizing method based on parameter clustering and parameter alignment. In addition, an adaptive parameter update strategy is proposed to further improve the robustness. By these settings, our proposed AdvLoRA alleviates the model security and high resource waste problems. Extensive experiments demonstrate the effectiveness and efficiency of the AdvLoRA.
Post-Semantic-Thinking: A Robust Strategy to Distill Reasoning Capacity from Large Language Models
Apr 14, 2024Chain of thought finetuning aims to endow small student models with reasoning capacity to improve their performance towards a specific task by allowing them to imitate the reasoning procedure of large language models (LLMs) beyond simply predicting the answer to the question. However, the existing methods 1) generate rationale before the answer, making their answer correctness sensitive to the hallucination in the rationale;2) force the student model to repeat the exact LLMs rationale expression word-after-word, which could have the model biased towards learning the expression in rationale but count against the model from understanding the core logic behind it. Therefore, we propose a robust Post-Semantic-Thinking (PST) strategy to generate answers before rationale. Thanks to this answer-first setting, 1) the answering procedure can escape from the adverse effects caused by hallucinations in the rationale; 2) the complex reasoning procedure is tightly bound with the relatively concise answer, making the reasoning for questions easier with the prior information in the answer; 3) the efficiency of the method can also benefit from the setting since users can stop the generation right after answers are outputted when inference is conducted. Furthermore, the PST strategy loose the constraint against the generated rationale to be close to the LLMs gold standard in the hidden semantic space instead of the vocabulary space, thus making the small student model better comprehend the semantic reasoning logic in rationale. Extensive experiments conducted across 12 reasoning tasks demonstrate the effectiveness of PST.
Efficient Prompt Tuning of Large Vision-Language Model for Fine-Grained Ship Classification
Mar 13, 2024

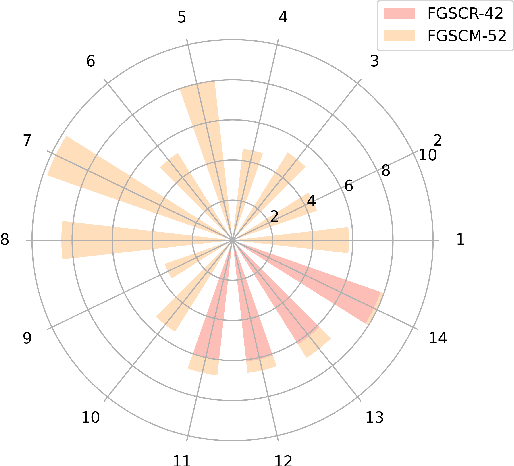

Fine-grained ship classification in remote sensing (RS-FGSC) poses a significant challenge due to the high similarity between classes and the limited availability of labeled data, limiting the effectiveness of traditional supervised classification methods. Recent advancements in large pre-trained Vision-Language Models (VLMs) have demonstrated impressive capabilities in few-shot or zero-shot learning, particularly in understanding image content. This study delves into harnessing the potential of VLMs to enhance classification accuracy for unseen ship categories, which holds considerable significance in scenarios with restricted data due to cost or privacy constraints. Directly fine-tuning VLMs for RS-FGSC often encounters the challenge of overfitting the seen classes, resulting in suboptimal generalization to unseen classes, which highlights the difficulty in differentiating complex backgrounds and capturing distinct ship features. To address these issues, we introduce a novel prompt tuning technique that employs a hierarchical, multi-granularity prompt design. Our approach integrates remote sensing ship priors through bias terms, learned from a small trainable network. This strategy enhances the model's generalization capabilities while improving its ability to discern intricate backgrounds and learn discriminative ship features. Furthermore, we contribute to the field by introducing a comprehensive dataset, FGSCM-52, significantly expanding existing datasets with more extensive data and detailed annotations for less common ship classes. Extensive experimental evaluations demonstrate the superiority of our proposed method over current state-of-the-art techniques. The source code will be made publicly available.
A Survey of Graph Neural Networks in Real world: Imbalance, Noise, Privacy and OOD Challenges
Mar 07, 2024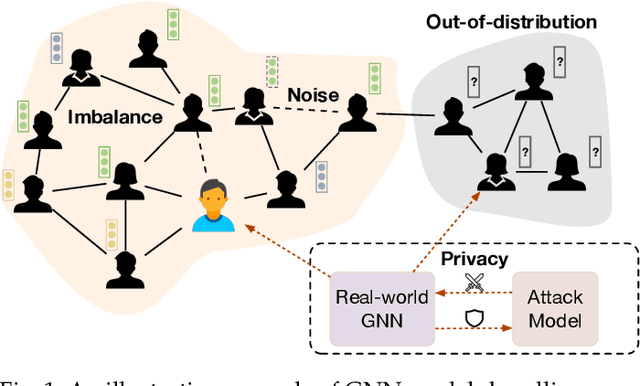
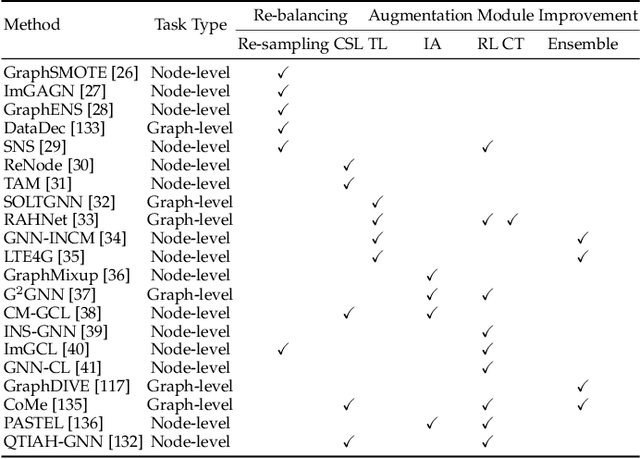
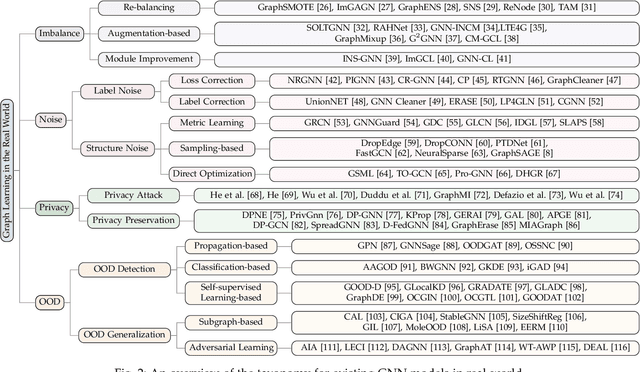
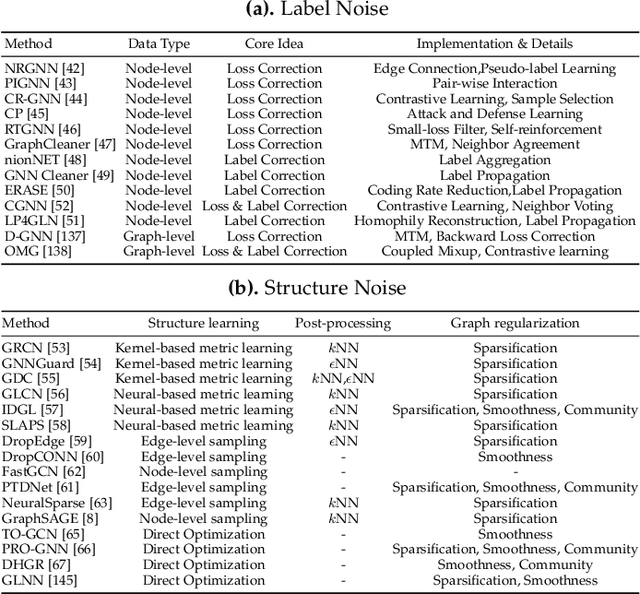
Graph-structured data exhibits universality and widespread applicability across diverse domains, such as social network analysis, biochemistry, financial fraud detection, and network security. Significant strides have been made in leveraging Graph Neural Networks (GNNs) to achieve remarkable success in these areas. However, in real-world scenarios, the training environment for models is often far from ideal, leading to substantial performance degradation of GNN models due to various unfavorable factors, including imbalance in data distribution, the presence of noise in erroneous data, privacy protection of sensitive information, and generalization capability for out-of-distribution (OOD) scenarios. To tackle these issues, substantial efforts have been devoted to improving the performance of GNN models in practical real-world scenarios, as well as enhancing their reliability and robustness. In this paper, we present a comprehensive survey that systematically reviews existing GNN models, focusing on solutions to the four mentioned real-world challenges including imbalance, noise, privacy, and OOD in practical scenarios that many existing reviews have not considered. Specifically, we first highlight the four key challenges faced by existing GNNs, paving the way for our exploration of real-world GNN models. Subsequently, we provide detailed discussions on these four aspects, dissecting how these solutions contribute to enhancing the reliability and robustness of GNN models. Last but not least, we outline promising directions and offer future perspectives in the field.
Phrase Grounding-based Style Transfer for Single-Domain Generalized Object Detection
Feb 05, 2024Single-domain generalized object detection aims to enhance a model's generalizability to multiple unseen target domains using only data from a single source domain during training. This is a practical yet challenging task as it requires the model to address domain shift without incorporating target domain data into training. In this paper, we propose a novel phrase grounding-based style transfer (PGST) approach for the task. Specifically, we first define textual prompts to describe potential objects for each unseen target domain. Then, we leverage the grounded language-image pre-training (GLIP) model to learn the style of these target domains and achieve style transfer from the source to the target domain. The style-transferred source visual features are semantically rich and could be close to imaginary counterparts in the target domain. Finally, we employ these style-transferred visual features to fine-tune GLIP. By introducing imaginary counterparts, the detector could be effectively generalized to unseen target domains using only a single source domain for training. Extensive experimental results on five diverse weather driving benchmarks demonstrate our proposed approach achieves state-of-the-art performance, even surpassing some domain adaptive methods that incorporate target domain images into the training process.The source codes and pre-trained models will be made available.
Online Differentiable Clustering for Intent Learning in Recommendation
Jan 24, 2024Mining users' intents plays a crucial role in sequential recommendation. The recent approach, ICLRec, was introduced to extract underlying users' intents using contrastive learning and clustering. While it has shown effectiveness, the existing method suffers from complex and cumbersome alternating optimization, leading to two main issues. Firstly, the separation of representation learning and clustering optimization within a generalized expectation maximization (EM) framework often results in sub-optimal performance. Secondly, performing clustering on the entire dataset hampers scalability for large-scale industry data. To address these challenges, we propose a novel intent learning method called \underline{ODCRec}, which integrates representation learning into an \underline{O}nline \underline{D}ifferentiable \underline{C}lustering framework for \underline{Rec}ommendation. Specifically, we encode users' behavior sequences and initialize the cluster centers as differentiable network parameters. Additionally, we design a clustering loss that guides the networks to differentiate between different cluster centers and pull similar samples towards their respective cluster centers. This allows simultaneous optimization of recommendation and clustering using mini-batch data. Moreover, we leverage the learned cluster centers as self-supervision signals for representation learning, resulting in further enhancement of recommendation performance. Extensive experiments conducted on open benchmarks and industry data validate the superiority, effectiveness, and efficiency of our proposed ODCRec method. Code is available at: https://github.com/yueliu1999/ELCRec.
Single-cell Multi-view Clustering via Community Detection with Unknown Number of Clusters
Nov 28, 2023Single-cell multi-view clustering enables the exploration of cellular heterogeneity within the same cell from different views. Despite the development of several multi-view clustering methods, two primary challenges persist. Firstly, most existing methods treat the information from both single-cell RNA (scRNA) and single-cell Assay of Transposase Accessible Chromatin (scATAC) views as equally significant, overlooking the substantial disparity in data richness between the two views. This oversight frequently leads to a degradation in overall performance. Additionally, the majority of clustering methods necessitate manual specification of the number of clusters by users. However, for biologists dealing with cell data, precisely determining the number of distinct cell types poses a formidable challenge. To this end, we introduce scUNC, an innovative multi-view clustering approach tailored for single-cell data, which seamlessly integrates information from different views without the need for a predefined number of clusters. The scUNC method comprises several steps: initially, it employs a cross-view fusion network to create an effective embedding, which is then utilized to generate initial clusters via community detection. Subsequently, the clusters are automatically merged and optimized until no further clusters can be merged. We conducted a comprehensive evaluation of scUNC using three distinct single-cell datasets. The results underscored that scUNC outperforms the other baseline methods.
Single-Cell Clustering via Dual-Graph Alignment
Nov 28, 2023In recent years, the field of single-cell RNA sequencing has seen a surge in the development of clustering methods. These methods enable the identification of cell subpopulations, thereby facilitating the understanding of tumor microenvironments. Despite their utility, most existing clustering algorithms primarily focus on the attribute information provided by the cell matrix or the network structure between cells, often neglecting the network between genes. This oversight could lead to loss of information and clustering results that lack clinical significance. To address this limitation, we develop an advanced single-cell clustering model incorporating dual-graph alignment, which integrates gene network information into the clustering process based on self-supervised and unsupervised optimization. Specifically, we designed a graph-based autoencoder enhanced by an attention mechanism to effectively capture relationships between cells. Moreover, we performed the node2vec method on Protein-Protein Interaction (PPI) networks to derive the gene network structure and maintained this structure throughout the clustering process. Our proposed method has been demonstrated to be effective through experimental results, showcasing its ability to optimize clustering outcomes while preserving the original associations between cells and genes. This research contributes to obtaining accurate cell subpopulations and generates clustering results that more closely resemble real-world biological scenarios. It provides better insights into the characteristics and distribution of diseased cells, ultimately building a foundation for early disease diagnosis and treatment.