 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYingwei Ma
Online Differentiable Clustering for Intent Learning in Recommendation
Jan 24, 2024
Mining users' intents plays a crucial role in sequential recommendation. The recent approach, ICLRec, was introduced to extract underlying users' intents using contrastive learning and clustering. While it has shown effectiveness, the existing method suffers from complex and cumbersome alternating optimization, leading to two main issues. Firstly, the separation of representation learning and clustering optimization within a generalized expectation maximization (EM) framework often results in sub-optimal performance. Secondly, performing clustering on the entire dataset hampers scalability for large-scale industry data. To address these challenges, we propose a novel intent learning method called \underline{ODCRec}, which integrates representation learning into an \underline{O}nline \underline{D}ifferentiable \underline{C}lustering framework for \underline{Rec}ommendation. Specifically, we encode users' behavior sequences and initialize the cluster centers as differentiable network parameters. Additionally, we design a clustering loss that guides the networks to differentiate between different cluster centers and pull similar samples towards their respective cluster centers. This allows simultaneous optimization of recommendation and clustering using mini-batch data. Moreover, we leverage the learned cluster centers as self-supervision signals for representation learning, resulting in further enhancement of recommendation performance. Extensive experiments conducted on open benchmarks and industry data validate the superiority, effectiveness, and efficiency of our proposed ODCRec method. Code is available at: https://github.com/yueliu1999/ELCRec.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 22, 2023Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
At Which Training Stage Does Code Data Help LLMs Reasoning?
Sep 30, 2023Large Language Models (LLMs) have exhibited remarkable reasoning capabilities and become the foundation of language technologies. Inspired by the great success of code data in training LLMs, we naturally wonder at which training stage introducing code data can really help LLMs reasoning. To this end, this paper systematically explores the impact of code data on LLMs at different stages. Concretely, we introduce the code data at the pre-training stage, instruction-tuning stage, and both of them, respectively. Then, the reasoning capability of LLMs is comprehensively and fairly evaluated via six reasoning tasks in five domains. We critically analyze the experimental results and provide conclusions with insights. First, pre-training LLMs with the mixture of code and text can significantly enhance LLMs' general reasoning capability almost without negative transfer on other tasks. Besides, at the instruction-tuning stage, code data endows LLMs the task-specific reasoning capability. Moreover, the dynamic mixing strategy of code and text data assists LLMs to learn reasoning capability step-by-step during training. These insights deepen the understanding of LLMs regarding reasoning ability for their application, such as scientific question answering, legal support, etc. The source code and model parameters are released at the link:~\url{https://github.com/yingweima2022/CodeLLM}.
Language-Enhanced Session-Based Recommendation with Decoupled Contrastive Learning
Jul 20, 2023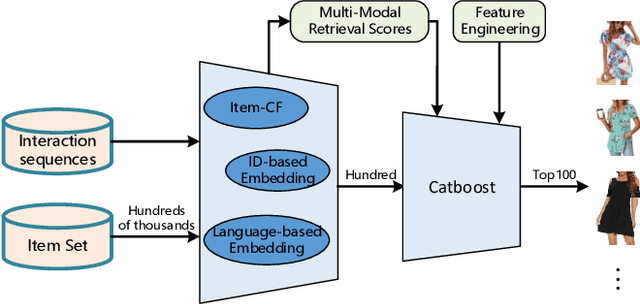

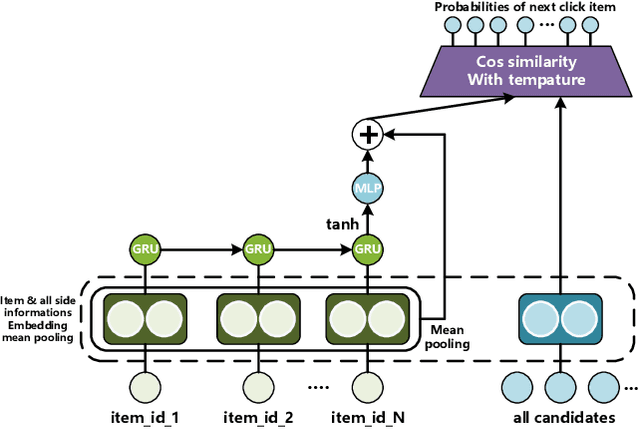
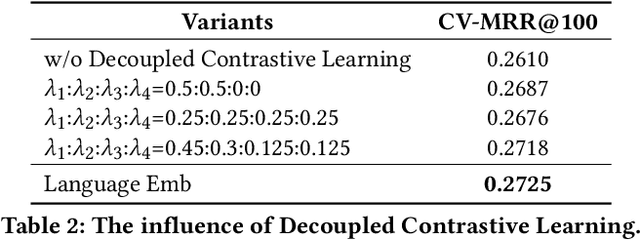
Session-based recommendation techniques aim to capture dynamic user behavior by analyzing past interactions. However, existing methods heavily rely on historical item ID sequences to extract user preferences, leading to challenges such as popular bias and cold-start problems. In this paper, we propose a hybrid multimodal approach for session-based recommendation to address these challenges. Our approach combines different modalities, including textual content and item IDs, leveraging the complementary nature of these modalities using CatBoost. To learn universal item representations, we design a language representation-based item retrieval architecture that extracts features from the textual content utilizing pre-trained language models. Furthermore, we introduce a novel Decoupled Contrastive Learning method to enhance the effectiveness of the language representation. This technique decouples the sequence representation and item representation space, facilitating bidirectional alignment through dual-queue contrastive learning. Simultaneously, the momentum queue provides a large number of negative samples, effectively enhancing the effectiveness of contrastive learning. Our approach yielded competitive results, securing a 5th place ranking in KDD CUP 2023 Task 1. We have released the source code and pre-trained models associated with this work.