 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhang Huang
Part-aware Shape Generation with Latent 3D Diffusion of Neural Voxel Fields
May 02, 2024
This paper presents a novel latent 3D diffusion model for the generation of neural voxel fields, aiming to achieve accurate part-aware structures. Compared to existing methods, there are two key designs to ensure high-quality and accurate part-aware generation. On one hand, we introduce a latent 3D diffusion process for neural voxel fields, enabling generation at significantly higher resolutions that can accurately capture rich textural and geometric details. On the other hand, a part-aware shape decoder is introduced to integrate the part codes into the neural voxel fields, guiding the accurate part decomposition and producing high-quality rendering results. Through extensive experimentation and comparisons with state-of-the-art methods, we evaluate our approach across four different classes of data. The results demonstrate the superior generative capabilities of our proposed method in part-aware shape generation, outperforming existing state-of-the-art methods.
Exploring the Distinctiveness and Fidelity of the Descriptions Generated by Large Vision-Language Models
Apr 26, 2024Large Vision-Language Models (LVLMs) are gaining traction for their remarkable ability to process and integrate visual and textual data. Despite their popularity, the capacity of LVLMs to generate precise, fine-grained textual descriptions has not been fully explored. This study addresses this gap by focusing on \textit{distinctiveness} and \textit{fidelity}, assessing how models like Open-Flamingo, IDEFICS, and MiniGPT-4 can distinguish between similar objects and accurately describe visual features. We proposed the Textual Retrieval-Augmented Classification (TRAC) framework, which, by leveraging its generative capabilities, allows us to delve deeper into analyzing fine-grained visual description generation. This research provides valuable insights into the generation quality of LVLMs, enhancing the understanding of multimodal language models. Notably, MiniGPT-4 stands out for its better ability to generate fine-grained descriptions, outperforming the other two models in this aspect. The code is provided at \url{https://anonymous.4open.science/r/Explore_FGVDs-E277}.
DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
Mar 04, 2024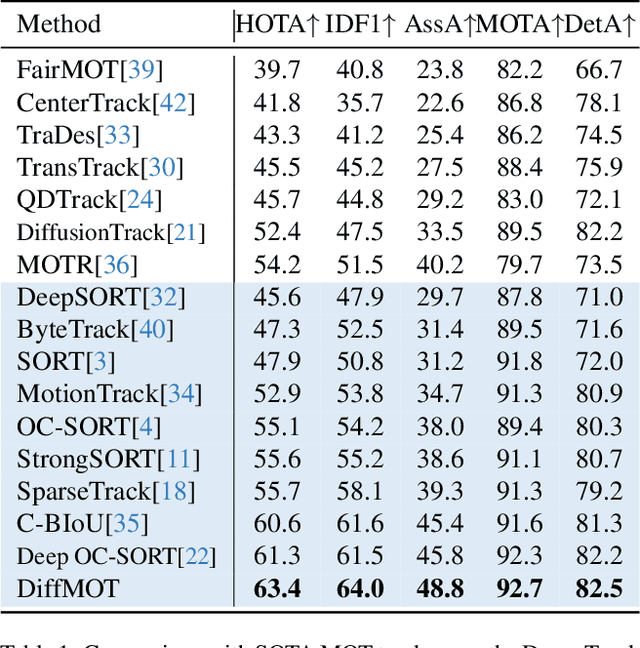
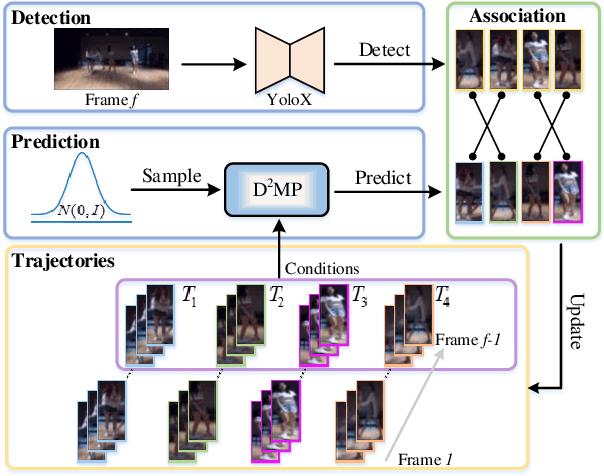
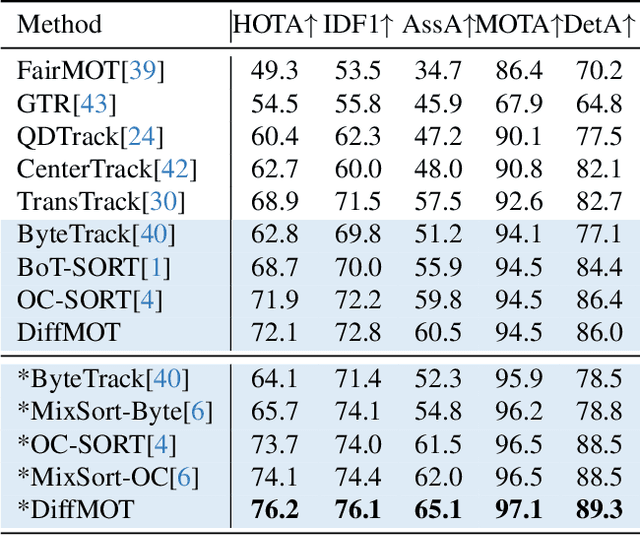
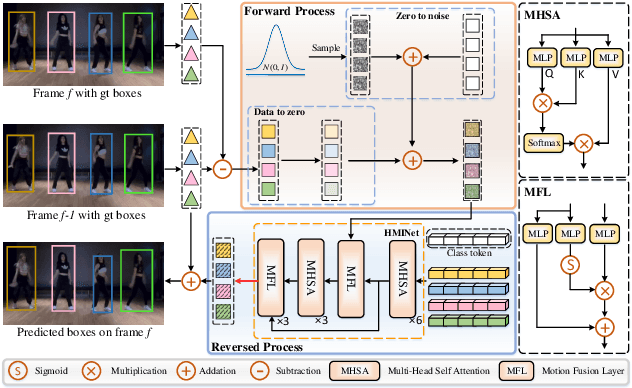
In Multiple Object Tracking, objects often exhibit non-linear motion of acceleration and deceleration, with irregular direction changes. Tacking-by-detection (TBD) with Kalman Filter motion prediction works well in pedestrian-dominant scenarios but falls short in complex situations when multiple objects perform non-linear and diverse motion simultaneously. To tackle the complex non-linear motion, we propose a real-time diffusion-based MOT approach named DiffMOT. Specifically, for the motion predictor component, we propose a novel Decoupled Diffusion-based Motion Predictor (D MP). It models the entire distribution of various motion presented by the data as a whole. It also predicts an individual object's motion conditioning on an individual's historical motion information. Furthermore, it optimizes the diffusion process with much less sampling steps. As a MOT tracker, the DiffMOT is real-time at 22.7FPS, and also outperforms the state-of-the-art on DanceTrack and SportsMOT datasets with 63.4 and 76.2 in HOTA metrics, respectively. To the best of our knowledge, DiffMOT is the first to introduce a diffusion probabilistic model into the MOT to tackle non-linear motion prediction.
DiffusionEdge: Diffusion Probabilistic Model for Crisp Edge Detection
Jan 09, 2024Limited by the encoder-decoder architecture, learning-based edge detectors usually have difficulty predicting edge maps that satisfy both correctness and crispness. With the recent success of the diffusion probabilistic model (DPM), we found it is especially suitable for accurate and crisp edge detection since the denoising process is directly applied to the original image size. Therefore, we propose the first diffusion model for the task of general edge detection, which we call DiffusionEdge. To avoid expensive computational resources while retaining the final performance, we apply DPM in the latent space and enable the classic cross-entropy loss which is uncertainty-aware in pixel level to directly optimize the parameters in latent space in a distillation manner. We also adopt a decoupled architecture to speed up the denoising process and propose a corresponding adaptive Fourier filter to adjust the latent features of specific frequencies. With all the technical designs, DiffusionEdge can be stably trained with limited resources, predicting crisp and accurate edge maps with much fewer augmentation strategies. Extensive experiments on four edge detection benchmarks demonstrate the superiority of DiffusionEdge both in correctness and crispness. On the NYUDv2 dataset, compared to the second best, we increase the ODS, OIS (without post-processing) and AC by 30.2%, 28.1% and 65.1%, respectively. Code: https://github.com/GuHuangAI/DiffusionEdge.
Manipulating the Label Space for In-Context Classification
Dec 06, 2023After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
DeepFracture: A Generative Approach for Predicting Brittle Fractures
Oct 20, 2023



In the realm of brittle fracture animation, generating realistic destruction animations with physics simulation techniques can be computationally expensive. Although methods using Voronoi diagrams or pre-fractured patterns work for real-time applications, they often lack realism in portraying brittle fractures. This paper introduces a novel learning-based approach for seamlessly merging realistic brittle fracture animations with rigid-body simulations. Our method utilizes BEM brittle fracture simulations to create fractured patterns and collision conditions for a given shape, which serve as training data for the learning process. To effectively integrate collision conditions and fractured shapes into a deep learning framework, we introduce the concept of latent impulse representation and geometrically-segmented signed distance function (GS-SDF). The latent impulse representation serves as input, capturing information about impact forces on the shape's surface. Simultaneously, a GS-SDF is used as the output representation of the fractured shape. To address the challenge of optimizing multiple fractured pattern targets with a single latent code, we propose an eight-dimensional latent space based on a normal distribution code within our latent impulse representation design. This adaptation effectively transforms our neural network into a generative one. Our experimental results demonstrate that our approach can generate significantly more detailed brittle fractures compared to existing techniques, all while maintaining commendable computational efficiency during run-time.
Decoupled Diffusion Models with Explicit Transition Probability
Jun 23, 2023



Recent diffusion probabilistic models (DPMs) have shown remarkable abilities of generated content, however, they often suffer from complex forward processes, resulting in inefficient solutions for the reversed process and prolonged sampling times. In this paper, we aim to address the aforementioned challenges by focusing on the diffusion process itself that we propose to decouple the intricate diffusion process into two comparatively simpler process to improve the generative efficacy and speed. In particular, we present a novel diffusion paradigm named DDM (\textbf{D}ecoupled \textbf{D}iffusion \textbf{M}odels) based on the It\^{o} diffusion process, in which the image distribution is approximated by an explicit transition probability while the noise path is controlled by the standard Wiener process. We find that decoupling the diffusion process reduces the learning difficulty and the explicit transition probability improves the generative speed significantly. We prove a new training objective for DPM, which enables the model to learn to predict the noise and image components separately. Moreover, given the novel forward diffusion equation, we derive the reverse denoising formula of DDM that naturally supports fewer steps of generation without ordinary differential equation (ODE) based accelerators. Our experiments demonstrate that DDM outperforms previous DPMs by a large margin in fewer function evaluations setting and gets comparable performances in long function evaluations setting. We also show that our framework can be applied to image-conditioned generation and high-resolution image synthesis, and that it can generate high-quality images with only 10 function evaluations.
DPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022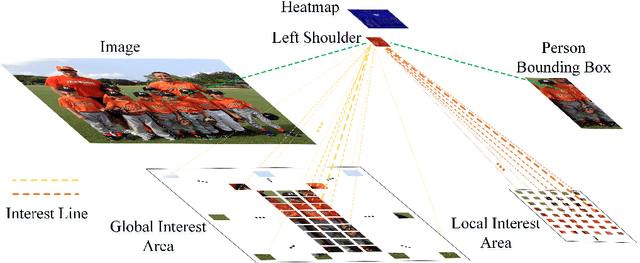
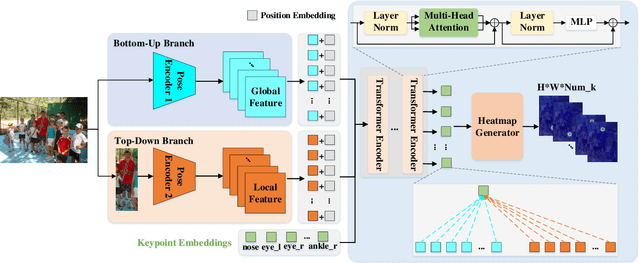
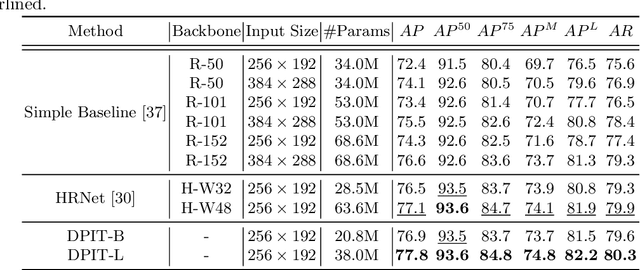
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.
Efficient VVC Intra Prediction Based on Deep Feature Fusion and Probability Estimation
May 07, 2022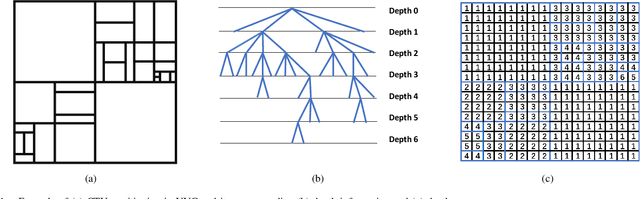
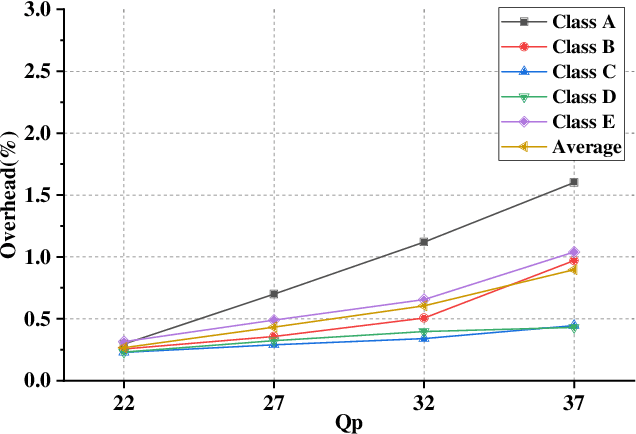
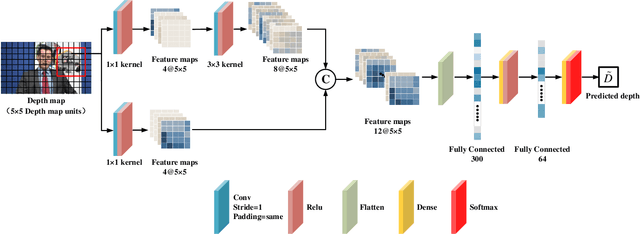
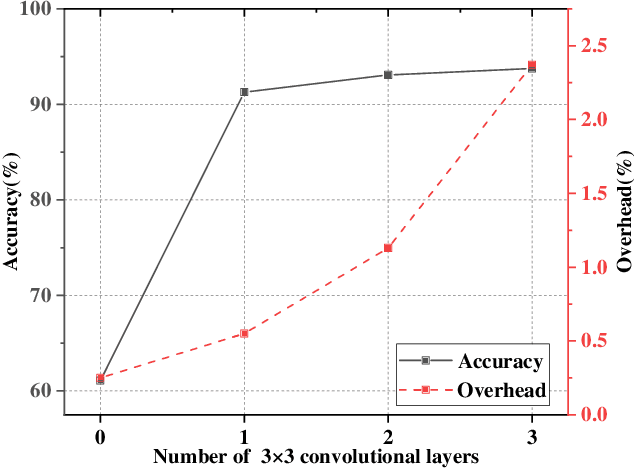
The ever-growing multimedia traffic has underscored the importance of effective multimedia codecs. Among them, the up-to-date lossy video coding standard, Versatile Video Coding (VVC), has been attracting attentions of video coding community. However, the gain of VVC is achieved at the cost of significant encoding complexity, which brings the need to realize fast encoder with comparable Rate Distortion (RD) performance. In this paper, we propose to optimize the VVC complexity at intra-frame prediction, with a two-stage framework of deep feature fusion and probability estimation. At the first stage, we employ the deep convolutional network to extract the spatialtemporal neighboring coding features. Then we fuse all reference features obtained by different convolutional kernels to determine an optimal intra coding depth. At the second stage, we employ a probability-based model and the spatial-temporal coherence to select the candidate partition modes within the optimal coding depth. Finally, these selected depths and partitions are executed whilst unnecessary computations are excluded. Experimental results on standard database demonstrate the superiority of proposed method, especially for High Definition (HD) and Ultra-HD (UHD) video sequences.
CaCo: Both Positive and Negative Samples are Directly Learnable via Cooperative-adversarial Contrastive Learning
Mar 27, 2022



As a representative self-supervised method, contrastive learning has achieved great successes in unsupervised training of representations. It trains an encoder by distinguishing positive samples from negative ones given query anchors. These positive and negative samples play critical roles in defining the objective to learn the discriminative encoder, avoiding it from learning trivial features. While existing methods heuristically choose these samples, we present a principled method where both positive and negative samples are directly learnable end-to-end with the encoder. We show that the positive and negative samples can be cooperatively and adversarially learned by minimizing and maximizing the contrastive loss, respectively. This yields cooperative positives and adversarial negatives with respect to the encoder, which are updated to continuously track the learned representation of the query anchors over mini-batches. The proposed method achieves 71.3% and 75.3% in top-1 accuracy respectively over 200 and 800 epochs of pre-training ResNet-50 backbone on ImageNet1K without tricks such as multi-crop or stronger augmentations. With Multi-Crop, it can be further boosted into 75.7%. The source code and pre-trained model are released in https://github.com/maple-research-lab/caco.