 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEn Zhu
Test-Time Training on Graphs with Large Language Models (LLMs)
Apr 21, 2024
Graph Neural Networks have demonstrated great success in various fields of multimedia. However, the distribution shift between the training and test data challenges the effectiveness of GNNs. To mitigate this challenge, Test-Time Training (TTT) has been proposed as a promising approach. Traditional TTT methods require a demanding unsupervised training strategy to capture the information from test to benefit the main task. Inspired by the great annotation ability of Large Language Models (LLMs) on Text-Attributed Graphs (TAGs), we propose to enhance the test-time training on graphs with LLMs as annotators. In this paper, we design a novel Test-Time Training pipeline, LLMTTT, which conducts the test-time adaptation under the annotations by LLMs on a carefully-selected node set. Specifically, LLMTTT introduces a hybrid active node selection strategy that considers not only node diversity and representativeness, but also prediction signals from the pre-trained model. Given annotations from LLMs, a two-stage training strategy is designed to tailor the test-time model with the limited and noisy labels. A theoretical analysis ensures the validity of our method and extensive experiments demonstrate that the proposed LLMTTT can achieve a significant performance improvement compared to existing Out-of-Distribution (OOD) generalization methods.
One-Step Late Fusion Multi-view Clustering with Compressed Subspace
Jan 03, 2024Late fusion multi-view clustering (LFMVC) has become a rapidly growing class of methods in the multi-view clustering (MVC) field, owing to its excellent computational speed and clustering performance. One bottleneck faced by existing late fusion methods is that they are usually aligned to the average kernel function, which makes the clustering performance highly dependent on the quality of datasets. Another problem is that they require subsequent k-means clustering after obtaining the consensus partition matrix to get the final discrete labels, and the resulting separation of the label learning and cluster structure optimization processes limits the integrity of these models. To address the above issues, we propose an integrated framework named One-Step Late Fusion Multi-view Clustering with Compressed Subspace (OS-LFMVC-CS). Specifically, we use the consensus subspace to align the partition matrix while optimizing the partition fusion, and utilize the fused partition matrix to guide the learning of discrete labels. A six-step iterative optimization approach with verified convergence is proposed. Sufficient experiments on multiple datasets validate the effectiveness and efficiency of our proposed method.
Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent
Oct 11, 2023Multi-view clustering has attracted growing attention owing to its capabilities of aggregating information from various sources and its promising horizons in public affairs. Up till now, many advanced approaches have been proposed in recent literature. However, there are several ongoing difficulties to be tackled. One common dilemma occurs while attempting to align the features of different views. We dig out as well as deploy the dependency amongst views through hierarchical feature descent, which leads to a common latent space( STAGE 1). This latent space, for the first time of its kind, is regarded as a 'resemblance space', as it reveals certain correlations and dependencies of different views. To be exact, the one-hot encoding of a category can also be referred to as a resemblance space in its terminal phase. Moreover, due to the intrinsic fact that most of the existing multi-view clustering algorithms stem from k-means clustering and spectral clustering, this results in cubic time complexity w.r.t. the number of the objects. However, we propose Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent(MVSC-HFD) to further reduce the computing complexity to linear time cost through a unified sampling strategy in resemblance space( STAGE 2), followed by subspace clustering to learn the representation collectively( STAGE 3). Extensive experimental results on public benchmark datasets demonstrate that our proposed model consistently outperforms the state-of-the-art techniques.
Contrastive Continual Multi-view Clustering with Filtered Structural Fusion
Sep 26, 2023Multi-view clustering thrives in applications where views are collected in advance by extracting consistent and complementary information among views. However, it overlooks scenarios where data views are collected sequentially, i.e., real-time data. Due to privacy issues or memory burden, previous views are not available with time in these situations. Some methods are proposed to handle it but are trapped in a stability-plasticity dilemma. In specific, these methods undergo a catastrophic forgetting of prior knowledge when a new view is attained. Such a catastrophic forgetting problem (CFP) would cause the consistent and complementary information hard to get and affect the clustering performance. To tackle this, we propose a novel method termed Contrastive Continual Multi-view Clustering with Filtered Structural Fusion (CCMVC-FSF). Precisely, considering that data correlations play a vital role in clustering and prior knowledge ought to guide the clustering process of a new view, we develop a data buffer with fixed size to store filtered structural information and utilize it to guide the generation of a robust partition matrix via contrastive learning. Furthermore, we theoretically connect CCMVC-FSF with semi-supervised learning and knowledge distillation. Extensive experiments exhibit the excellence of the proposed method.
CONVERT:Contrastive Graph Clustering with Reliable Augmentation
Sep 02, 2023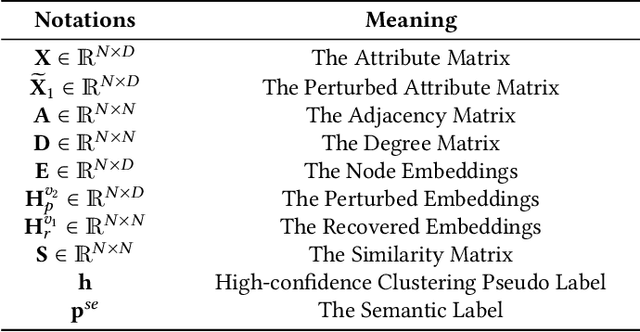
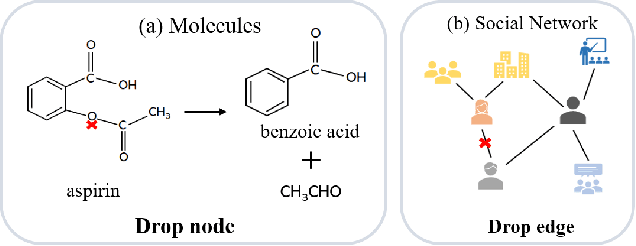
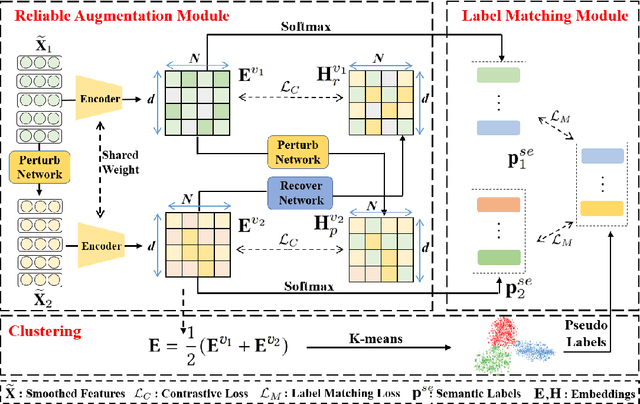
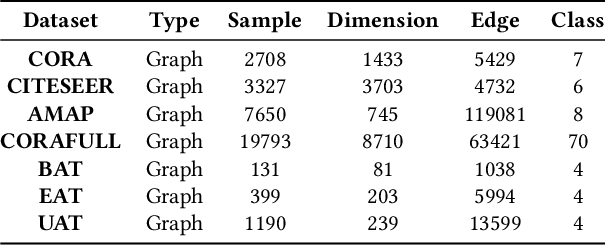
Contrastive graph node clustering via learnable data augmentation is a hot research spot in the field of unsupervised graph learning. The existing methods learn the sampling distribution of a pre-defined augmentation to generate data-driven augmentations automatically. Although promising clustering performance has been achieved, we observe that these strategies still rely on pre-defined augmentations, the semantics of the augmented graph can easily drift. The reliability of the augmented view semantics for contrastive learning can not be guaranteed, thus limiting the model performance. To address these problems, we propose a novel CONtrastiVe Graph ClustEring network with Reliable AugmenTation (COVERT). Specifically, in our method, the data augmentations are processed by the proposed reversible perturb-recover network. It distills reliable semantic information by recovering the perturbed latent embeddings. Moreover, to further guarantee the reliability of semantics, a novel semantic loss is presented to constrain the network via quantifying the perturbation and recovery. Lastly, a label-matching mechanism is designed to guide the model by clustering information through aligning the semantic labels and the selected high-confidence clustering pseudo labels. Extensive experimental results on seven datasets demonstrate the effectiveness of the proposed method. We release the code and appendix of CONVERT at https://github.com/xihongyang1999/CONVERT on GitHub.
DealMVC: Dual Contrastive Calibration for Multi-view Clustering
Sep 02, 2023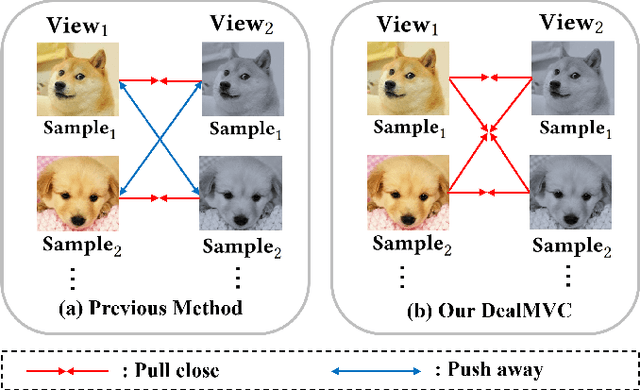

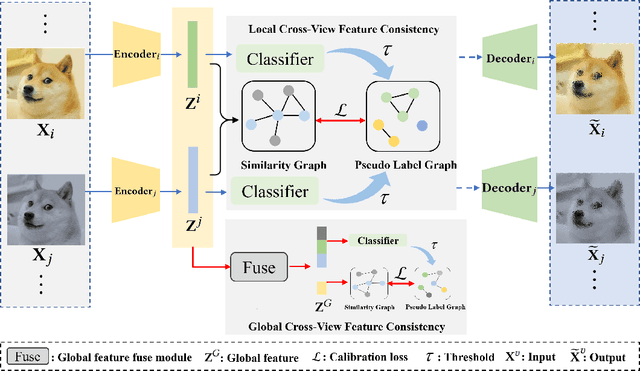
Benefiting from the strong view-consistent information mining capacity, multi-view contrastive clustering has attracted plenty of attention in recent years. However, we observe the following drawback, which limits the clustering performance from further improvement. The existing multi-view models mainly focus on the consistency of the same samples in different views while ignoring the circumstance of similar but different samples in cross-view scenarios. To solve this problem, we propose a novel Dual contrastive calibration network for Multi-View Clustering (DealMVC). Specifically, we first design a fusion mechanism to obtain a global cross-view feature. Then, a global contrastive calibration loss is proposed by aligning the view feature similarity graph and the high-confidence pseudo-label graph. Moreover, to utilize the diversity of multi-view information, we propose a local contrastive calibration loss to constrain the consistency of pair-wise view features. The feature structure is regularized by reliable class information, thus guaranteeing similar samples have similar features in different views. During the training procedure, the interacted cross-view feature is jointly optimized at both local and global levels. In comparison with other state-of-the-art approaches, the comprehensive experimental results obtained from eight benchmark datasets provide substantial validation of the effectiveness and superiority of our algorithm. We release the code of DealMVC at https://github.com/xihongyang1999/DealMVC on GitHub.
Scalable Incomplete Multi-View Clustering with Structure Alignment
Aug 31, 2023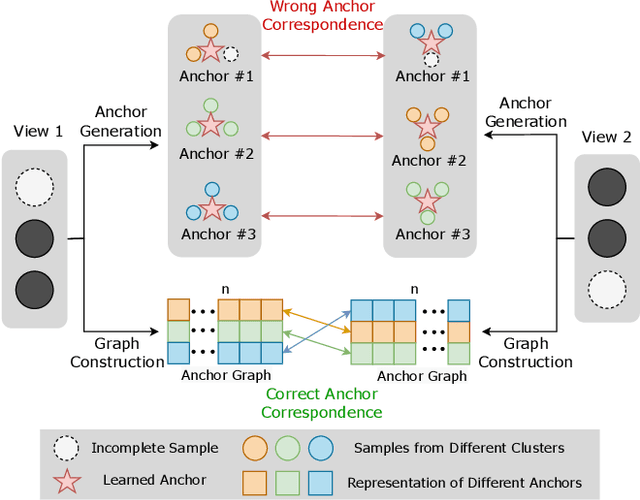
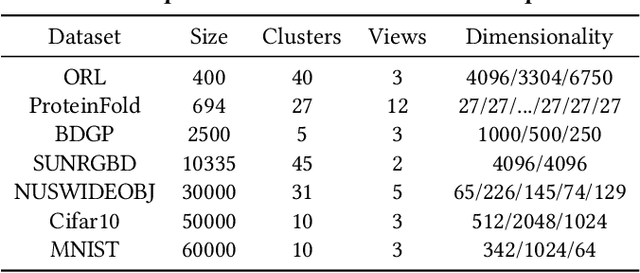
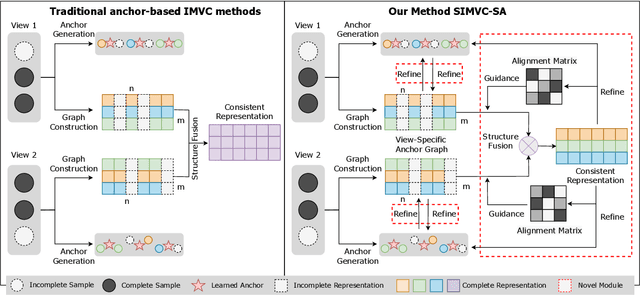
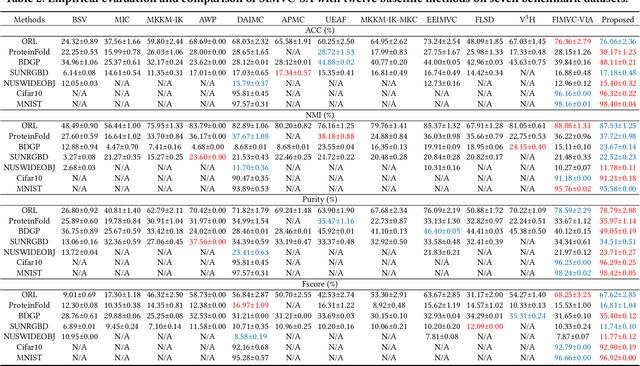
The success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.
One-step Multi-view Clustering with Diverse Representation
Jun 27, 2023
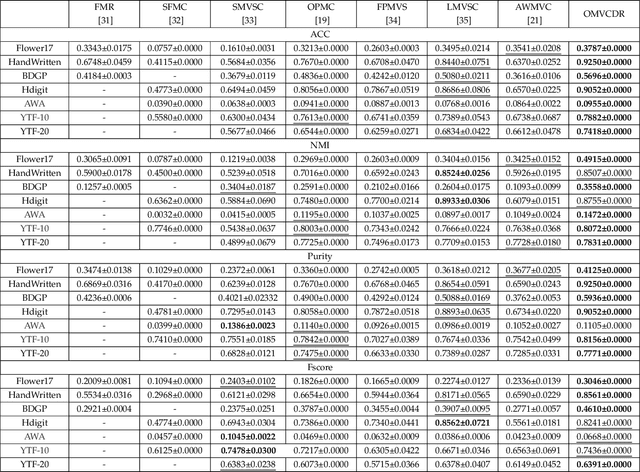

Multi-view clustering has attracted broad attention due to its capacity to utilize consistent and complementary information among views. Although tremendous progress has been made recently, most existing methods undergo high complexity, preventing them from being applied to large-scale tasks. Multi-view clustering via matrix factorization is a representative to address this issue. However, most of them map the data matrices into a fixed dimension, limiting the model's expressiveness. Moreover, a range of methods suffers from a two-step process, i.e., multimodal learning and the subsequent $k$-means, inevitably causing a sub-optimal clustering result. In light of this, we propose a one-step multi-view clustering with diverse representation method, which incorporates multi-view learning and $k$-means into a unified framework. Specifically, we first project original data matrices into various latent spaces to attain comprehensive information and auto-weight them in a self-supervised manner. Then we directly use the information matrices under diverse dimensions to obtain consensus discrete clustering labels. The unified work of representation learning and clustering boosts the quality of the final results. Furthermore, we develop an efficient optimization algorithm with proven convergence to solve the resultant problem. Comprehensive experiments on various datasets demonstrate the promising clustering performance of our proposed method.
Fast Continual Multi-View Clustering with Incomplete Views
Jun 04, 2023

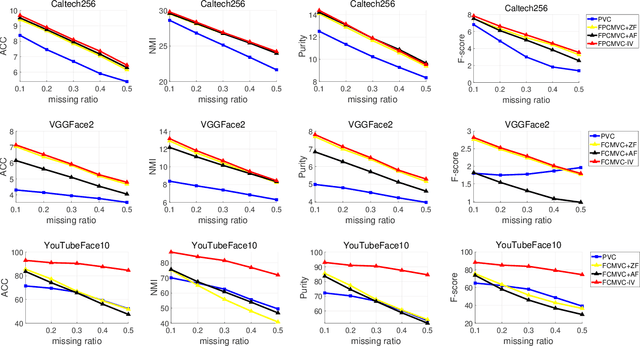

Multi-view clustering (MVC) has gained broad attention owing to its capacity to exploit consistent and complementary information across views. This paper focuses on a challenging issue in MVC called the incomplete continual data problem (ICDP). In specific, most existing algorithms assume that views are available in advance and overlook the scenarios where data observations of views are accumulated over time. Due to privacy considerations or memory limitations, previous views cannot be stored in these situations. Some works are proposed to handle it, but all fail to address incomplete views. Such an incomplete continual data problem (ICDP) in MVC is tough to solve since incomplete information with continual data increases the difficulty of extracting consistent and complementary knowledge among views. We propose Fast Continual Multi-View Clustering with Incomplete Views (FCMVC-IV) to address it. Specifically, it maintains a consensus coefficient matrix and updates knowledge with the incoming incomplete view rather than storing and recomputing all the data matrices. Considering that the views are incomplete, the newly collected view might contain samples that have yet to appear; two indicator matrices and a rotation matrix are developed to match matrices with different dimensions. Besides, we design a three-step iterative algorithm to solve the resultant problem in linear complexity with proven convergence. Comprehensive experiments on various datasets show the superiority of FCMVC-IV.
Deep Incomplete Multi-view Clustering with Cross-view Partial Sample and Prototype Alignment
Mar 30, 2023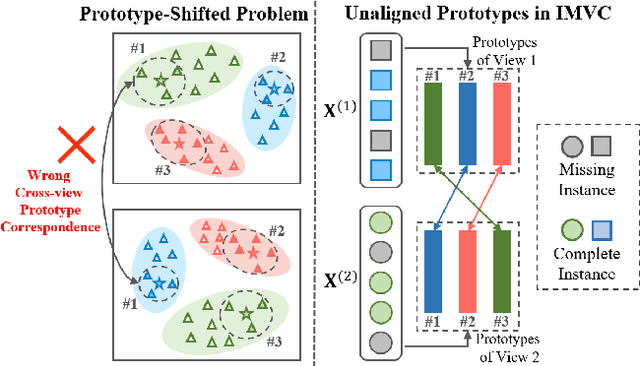



The success of existing multi-view clustering relies on the assumption of sample integrity across multiple views. However, in real-world scenarios, samples of multi-view are partially available due to data corruption or sensor failure, which leads to incomplete multi-view clustering study (IMVC). Although several attempts have been proposed to address IMVC, they suffer from the following drawbacks: i) Existing methods mainly adopt cross-view contrastive learning forcing the representations of each sample across views to be exactly the same, which might ignore view discrepancy and flexibility in representations; ii) Due to the absence of non-observed samples across multiple views, the obtained prototypes of clusters might be unaligned and biased, leading to incorrect fusion. To address the above issues, we propose a Cross-view Partial Sample and Prototype Alignment Network (CPSPAN) for Deep Incomplete Multi-view Clustering. Firstly, unlike existing contrastive-based methods, we adopt pair-observed data alignment as 'proxy supervised signals' to guide instance-to-instance correspondence construction among views. Then, regarding of the shifted prototypes in IMVC, we further propose a prototype alignment module to achieve incomplete distribution calibration across views. Extensive experimental results showcase the effectiveness of our proposed modules, attaining noteworthy performance improvements when compared to existing IMVC competitors on benchmark datasets.