 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi Shen
Continuous Spiking Graph Neural Networks
Apr 02, 2024
Continuous graph neural networks (CGNNs) have garnered significant attention due to their ability to generalize existing discrete graph neural networks (GNNs) by introducing continuous dynamics. They typically draw inspiration from diffusion-based methods to introduce a novel propagation scheme, which is analyzed using ordinary differential equations (ODE). However, the implementation of CGNNs requires significant computational power, making them challenging to deploy on battery-powered devices. Inspired by recent spiking neural networks (SNNs), which emulate a biological inference process and provide an energy-efficient neural architecture, we incorporate the SNNs with CGNNs in a unified framework, named Continuous Spiking Graph Neural Networks (COS-GNN). We employ SNNs for graph node representation at each time step, which are further integrated into the ODE process along with time. To enhance information preservation and mitigate information loss in SNNs, we introduce the high-order structure of COS-GNN, which utilizes the second-order ODE for spiking representation and continuous propagation. Moreover, we provide the theoretical proof that COS-GNN effectively mitigates the issues of exploding and vanishing gradients, enabling us to capture long-range dependencies between nodes. Experimental results on graph-based learning tasks demonstrate the effectiveness of the proposed COS-GNN over competitive baselines.
A General and Efficient Federated Split Learning with Pre-trained Image Transformers for Heterogeneous Data
Mar 24, 2024Federated Split Learning (FSL) is a promising distributed learning paradigm in practice, which gathers the strengths of both Federated Learning (FL) and Split Learning (SL) paradigms, to ensure model privacy while diminishing the resource overhead of each client, especially on large transformer models in a resource-constrained environment, e.g., Internet of Things (IoT). However, almost all works merely investigate the performance with simple neural network models in FSL. Despite the minor efforts focusing on incorporating Vision Transformers (ViT) as model architectures, they train ViT from scratch, thereby leading to enormous training overhead in each device with limited resources. Therefore, in this paper, we harness Pre-trained Image Transformers (PITs) as the initial model, coined FES-PIT, to accelerate the training process and improve model robustness. Furthermore, we propose FES-PTZO to hinder the gradient inversion attack, especially having the capability compatible with black-box scenarios, where the gradient information is unavailable. Concretely, FES-PTZO approximates the server gradient by utilizing a zeroth-order (ZO) optimization, which replaces the backward propagation with just one forward process. Empirically, we are the first to provide a systematic evaluation of FSL methods with PITs in real-world datasets, different partial device participations, and heterogeneous data splits. Our experiments verify the effectiveness of our algorithms.
Building Accurate Translation-Tailored LLMs with Language Aware Instruction Tuning
Mar 21, 2024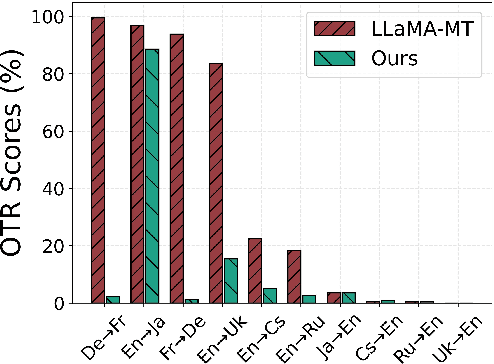
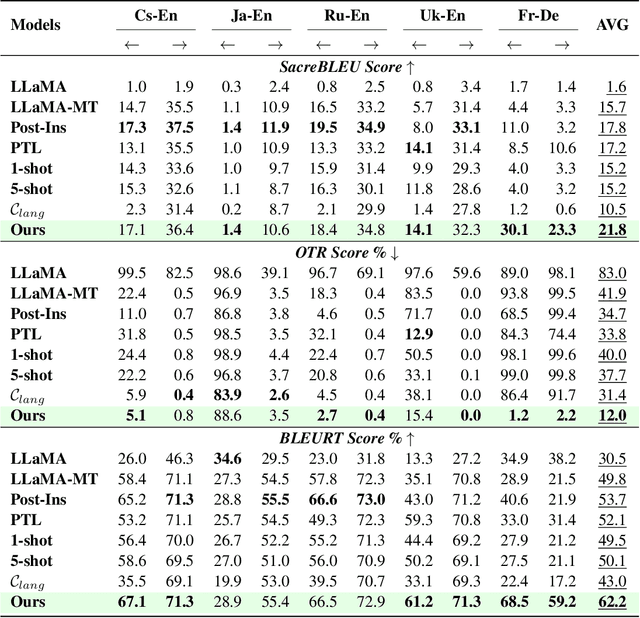
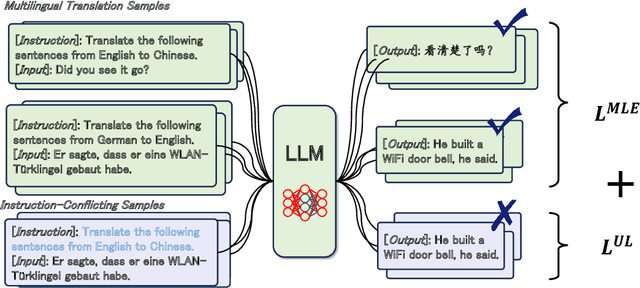
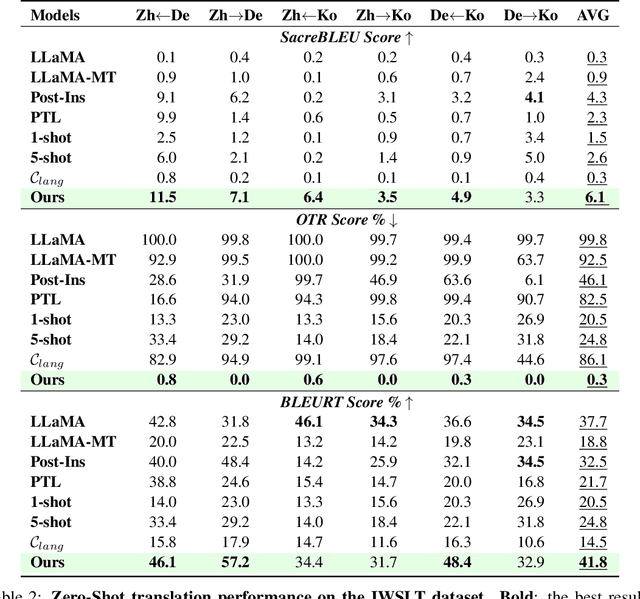
Translation-tailored Large language models (LLMs) exhibit remarkable translation capabilities, even competing with supervised-trained commercial translation systems. However, off-target translation remains an unsolved problem, especially for low-resource languages, hindering us from developing accurate LLMs-based translation models. To mitigate the off-target translation problem and enhance the performance of LLMs on translation, recent works have either designed advanced prompting strategies to highlight the functionality of translation instructions or exploited the in-context learning ability of LLMs by feeding few-shot demonstrations. However, these methods essentially do not improve LLM's ability to follow translation instructions, especially the language direction information. In this work, we design a two-stage fine-tuning algorithm to improve the instruction-following ability (especially the translation direction) of LLMs. Specifically, we first tune LLMs with the maximum likelihood estimation loss on the translation dataset to elicit the basic translation capabilities. In the second stage, we construct instruction-conflicting samples by randomly replacing the translation directions with a wrong one within the instruction, and then introduce an extra unlikelihood loss to learn those samples. Experiments on IWSLT and WMT benchmarks upon the LLaMA model spanning 16 zero-shot directions show that, compared to the competitive baseline -- translation-finetuned LLama, our method could effectively reduce the off-target translation ratio (averagely -53.3\%), thus improving translation quality with average +5.7 SacreBLEU and +16.4 BLEURT. Analysis shows that our method could preserve the model's general task performance on AlpacaEval. Code and models will be released at \url{https://github.com/alphadl/LanguageAware_Tuning}.
A Unified and General Framework for Continual Learning
Mar 20, 2024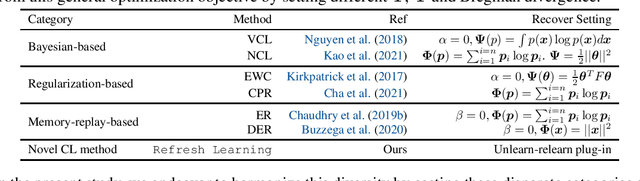
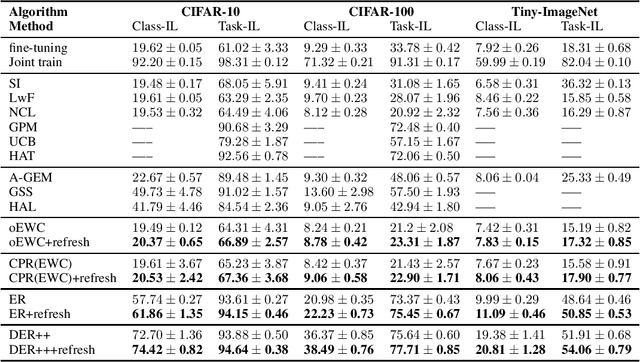
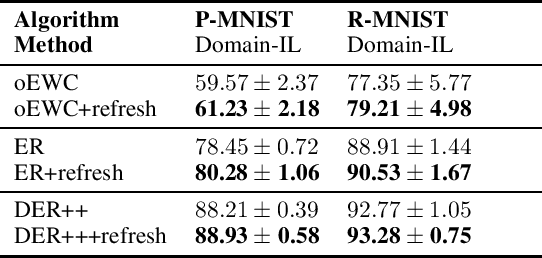

Continual Learning (CL) focuses on learning from dynamic and changing data distributions while retaining previously acquired knowledge. Various methods have been developed to address the challenge of catastrophic forgetting, including regularization-based, Bayesian-based, and memory-replay-based techniques. However, these methods lack a unified framework and common terminology for describing their approaches. This research aims to bridge this gap by introducing a comprehensive and overarching framework that encompasses and reconciles these existing methodologies. Notably, this new framework is capable of encompassing established CL approaches as special instances within a unified and general optimization objective. An intriguing finding is that despite their diverse origins, these methods share common mathematical structures. This observation highlights the compatibility of these seemingly distinct techniques, revealing their interconnectedness through a shared underlying optimization objective. Moreover, the proposed general framework introduces an innovative concept called refresh learning, specifically designed to enhance the CL performance. This novel approach draws inspiration from neuroscience, where the human brain often sheds outdated information to improve the retention of crucial knowledge and facilitate the acquisition of new information. In essence, refresh learning operates by initially unlearning current data and subsequently relearning it. It serves as a versatile plug-in that seamlessly integrates with existing CL methods, offering an adaptable and effective enhancement to the learning process. Extensive experiments on CL benchmarks and theoretical analysis demonstrate the effectiveness of the proposed refresh learning. Code is available at \url{https://github.com/joey-wang123/CL-refresh-learning}.
Step-On-Feet Tuning: Scaling Self-Alignment of LLMs via Bootstrapping
Feb 22, 2024Self-alignment is an effective way to reduce the cost of human annotation while ensuring promising model capability. However, most current methods complete the data collection and training steps in a single round, which may overlook the continuously improving ability of self-aligned models. This gives rise to a key query: What if we do multi-time bootstrapping self-alignment? Does this strategy enhance model performance or lead to rapid degradation? In this paper, our pioneering exploration delves into the impact of bootstrapping self-alignment on large language models. Our findings reveal that bootstrapping self-alignment markedly surpasses the single-round approach, by guaranteeing data diversity from in-context learning. To further exploit the capabilities of bootstrapping, we investigate and adjust the training order of data, which yields improved performance of the model. Drawing on these findings, we propose Step-On-Feet Tuning (SOFT) which leverages model's continuously enhanced few-shot ability to boost zero or one-shot performance. Based on easy-to-hard training recipe, we propose SOFT+ which further boost self-alignment's performance. Our experiments demonstrate the efficiency of SOFT (SOFT+) across various classification and generation tasks, highlighting the potential of bootstrapping self-alignment on continually enhancing model alignment performance.
Revisiting Knowledge Distillation for Autoregressive Language Models
Feb 19, 2024Knowledge distillation (KD) is a common approach to compress a teacher model to reduce its inference cost and memory footprint, by training a smaller student model. However, in the context of autoregressive language models (LMs), we empirically find that larger teacher LMs might dramatically result in a poorer student. In response to this problem, we conduct a series of analyses and reveal that different tokens have different teaching modes, neglecting which will lead to performance degradation. Motivated by this, we propose a simple yet effective adaptive teaching approach (ATKD) to improve the KD. The core of ATKD is to reduce rote learning and make teaching more diverse and flexible. Extensive experiments on 8 LM tasks show that, with the help of ATKD, various baseline KD methods can achieve consistent and significant performance gains (up to +3.04% average score) across all model types and sizes. More encouragingly, ATKD can improve the student model generalization effectively.
Communication-Efficient Distributed Learning with Local Immediate Error Compensation
Feb 19, 2024Gradient compression with error compensation has attracted significant attention with the target of reducing the heavy communication overhead in distributed learning. However, existing compression methods either perform only unidirectional compression in one iteration with higher communication cost, or bidirectional compression with slower convergence rate. In this work, we propose the Local Immediate Error Compensated SGD (LIEC-SGD) optimization algorithm to break the above bottlenecks based on bidirectional compression and carefully designed compensation approaches. Specifically, the bidirectional compression technique is to reduce the communication cost, and the compensation technique compensates the local compression error to the model update immediately while only maintaining the global error variable on the server throughout the iterations to boost its efficacy. Theoretically, we prove that LIEC-SGD is superior to previous works in either the convergence rate or the communication cost, which indicates that LIEC-SGD could inherit the dual advantages from unidirectional compression and bidirectional compression. Finally, experiments of training deep neural networks validate the effectiveness of the proposed LIEC-SGD algorithm.
Representation Surgery for Multi-Task Model Merging
Feb 05, 2024Multi-task learning (MTL) compresses the information from multiple tasks into a unified backbone to improve computational efficiency and generalization. Recent work directly merges multiple independently trained models to perform MTL instead of collecting their raw data for joint training, greatly expanding the application scenarios of MTL. However, by visualizing the representation distribution of existing model merging schemes, we find that the merged model often suffers from the dilemma of representation bias. That is, there is a significant discrepancy in the representation distribution between the merged and individual models, resulting in poor performance of merged MTL. In this paper, we propose a representation surgery solution called "Surgery" to reduce representation bias in the merged model. Specifically, Surgery is a lightweight task-specific module that takes the representation of the merged model as input and attempts to output the biases contained in the representation from the merged model. We then designed an unsupervised optimization objective that updates the Surgery module by minimizing the distance between the merged model's representation and the individual model's representation. Extensive experiments demonstrate significant MTL performance improvements when our Surgery module is applied to state-of-the-art (SOTA) model merging schemes.
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Feb 01, 2024Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://anonymous.4open.science/r/weight-ensembling_MoE-67C9/