 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhong Zhang
RepoAgent: An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation
Feb 26, 2024
Generative models have demonstrated considerable potential in software engineering, particularly in tasks such as code generation and debugging. However, their utilization in the domain of code documentation generation remains underexplored. To this end, we introduce RepoAgent, a large language model powered open-source framework aimed at proactively generating, maintaining, and updating code documentation. Through both qualitative and quantitative evaluations, we have validated the effectiveness of our approach, showing that RepoAgent excels in generating high-quality repository-level documentation. The code and results are publicly accessible at https://github.com/OpenBMB/RepoAgent.
Step-On-Feet Tuning: Scaling Self-Alignment of LLMs via Bootstrapping
Feb 22, 2024Self-alignment is an effective way to reduce the cost of human annotation while ensuring promising model capability. However, most current methods complete the data collection and training steps in a single round, which may overlook the continuously improving ability of self-aligned models. This gives rise to a key query: What if we do multi-time bootstrapping self-alignment? Does this strategy enhance model performance or lead to rapid degradation? In this paper, our pioneering exploration delves into the impact of bootstrapping self-alignment on large language models. Our findings reveal that bootstrapping self-alignment markedly surpasses the single-round approach, by guaranteeing data diversity from in-context learning. To further exploit the capabilities of bootstrapping, we investigate and adjust the training order of data, which yields improved performance of the model. Drawing on these findings, we propose Step-On-Feet Tuning (SOFT) which leverages model's continuously enhanced few-shot ability to boost zero or one-shot performance. Based on easy-to-hard training recipe, we propose SOFT+ which further boost self-alignment's performance. Our experiments demonstrate the efficiency of SOFT (SOFT+) across various classification and generation tasks, highlighting the potential of bootstrapping self-alignment on continually enhancing model alignment performance.
Tell Me More! Towards Implicit User Intention Understanding of Language Model Driven Agents
Feb 15, 2024Current language model-driven agents often lack mechanisms for effective user participation, which is crucial given the vagueness commonly found in user instructions. Although adept at devising strategies and performing tasks, these agents struggle with seeking clarification and grasping precise user intentions. To bridge this gap, we introduce Intention-in-Interaction (IN3), a novel benchmark designed to inspect users' implicit intentions through explicit queries. Next, we propose the incorporation of model experts as the upstream in agent designs to enhance user-agent interaction. Employing IN3, we empirically train Mistral-Interact, a powerful model that proactively assesses task vagueness, inquires user intentions, and refines them into actionable goals before starting downstream agent task execution. Integrating it into the XAgent framework, we comprehensively evaluate the enhanced agent system regarding user instruction understanding and execution, revealing that our approach notably excels at identifying vague user tasks, recovering and summarizing critical missing information, setting precise and necessary agent execution goals, and minimizing redundant tool usage, thus boosting overall efficiency. All the data and codes are released.
GitAgent: Facilitating Autonomous Agent with GitHub by Tool Extension
Dec 28, 2023While Large Language Models (LLMs) like ChatGPT and GPT-4 have demonstrated exceptional proficiency in natural language processing, their efficacy in addressing complex, multifaceted tasks remains limited. A growing area of research focuses on LLM-based agents equipped with external tools capable of performing diverse tasks. However, existing LLM-based agents only support a limited set of tools which is unable to cover a diverse range of user queries, especially for those involving expertise domains. It remains a challenge for LLM-based agents to extend their tools autonomously when confronted with various user queries. As GitHub has hosted a multitude of repositories which can be seen as a good resource for tools, a promising solution is that LLM-based agents can autonomously integrate the repositories in GitHub according to the user queries to extend their tool set. In this paper, we introduce GitAgent, an agent capable of achieving the autonomous tool extension from GitHub. GitAgent follows a four-phase procedure to incorporate repositories and it can learn human experience by resorting to GitHub Issues/PRs to solve problems encountered during the procedure. Experimental evaluation involving 30 user queries demonstrates GitAgent's effectiveness, achieving a 69.4% success rate on average.
Seeing Is Not Always Believing: Invisible Collision Attack and Defence on Pre-Trained Models
Sep 24, 2023Large-scale pre-trained models (PTMs) such as BERT and GPT have achieved great success in diverse fields. The typical paradigm is to pre-train a big deep learning model on large-scale data sets, and then fine-tune the model on small task-specific data sets for downstream tasks. Although PTMs have rapidly progressed with wide real-world applications, they also pose significant risks of potential attacks. Existing backdoor attacks or data poisoning methods often build up the assumption that the attacker invades the computers of victims or accesses the target data, which is challenging in real-world scenarios. In this paper, we propose a novel framework for an invisible attack on PTMs with enhanced MD5 collision. The key idea is to generate two equal-size models with the same MD5 checksum by leveraging the MD5 chosen-prefix collision. Afterwards, the two ``same" models will be deployed on public websites to induce victims to download the poisoned model. Unlike conventional attacks on deep learning models, this new attack is flexible, covert, and model-independent. Additionally, we propose a simple defensive strategy for recognizing the MD5 chosen-prefix collision and provide a theoretical justification for its feasibility. We extensively validate the effectiveness and stealthiness of our proposed attack and defensive method on different models and data sets.
Alleviating Matthew Effect of Offline Reinforcement Learning in Interactive Recommendation
Jul 10, 2023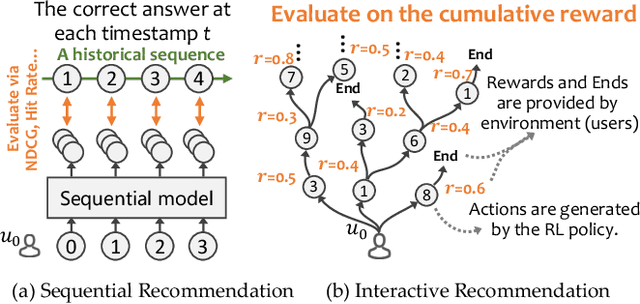
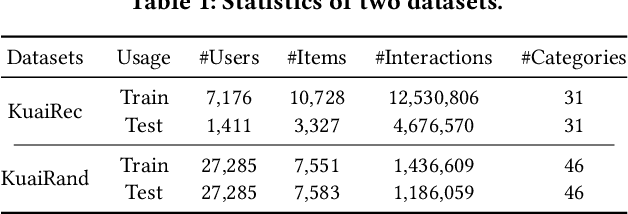
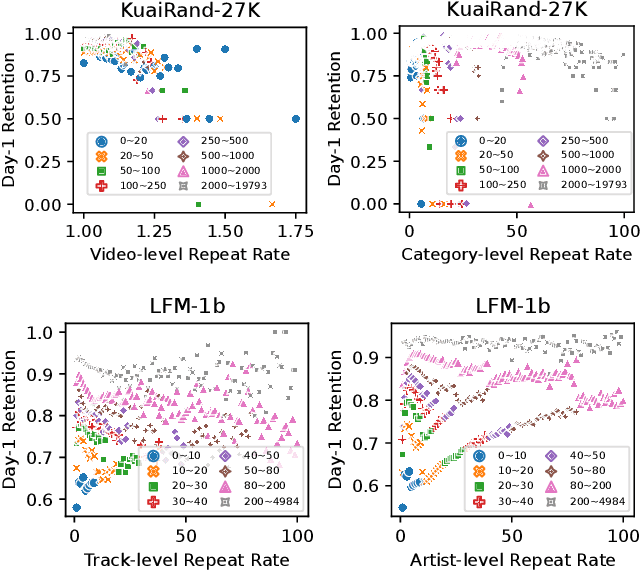

Offline reinforcement learning (RL), a technology that offline learns a policy from logged data without the need to interact with online environments, has become a favorable choice in decision-making processes like interactive recommendation. Offline RL faces the value overestimation problem. To address it, existing methods employ conservatism, e.g., by constraining the learned policy to be close to behavior policies or punishing the rarely visited state-action pairs. However, when applying such offline RL to recommendation, it will cause a severe Matthew effect, i.e., the rich get richer and the poor get poorer, by promoting popular items or categories while suppressing the less popular ones. It is a notorious issue that needs to be addressed in practical recommender systems. In this paper, we aim to alleviate the Matthew effect in offline RL-based recommendation. Through theoretical analyses, we find that the conservatism of existing methods fails in pursuing users' long-term satisfaction. It inspires us to add a penalty term to relax the pessimism on states with high entropy of the logging policy and indirectly penalizes actions leading to less diverse states. This leads to the main technical contribution of the work: Debiased model-based Offline RL (DORL) method. Experiments show that DORL not only captures user interests well but also alleviates the Matthew effect. The implementation is available via https://github.com/chongminggao/DORL-codes.
Fine-tuning Happens in Tiny Subspaces: Exploring Intrinsic Task-specific Subspaces of Pre-trained Language Models
May 27, 2023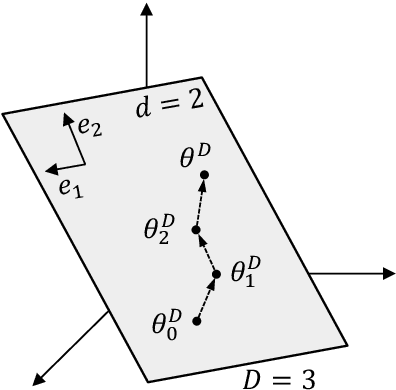
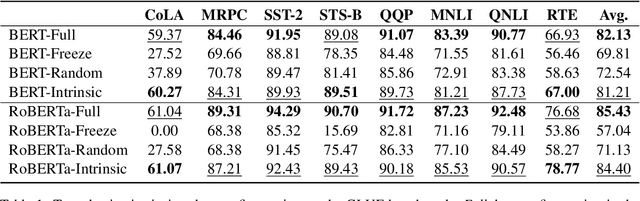
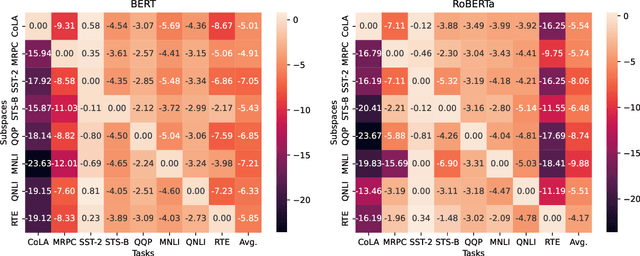
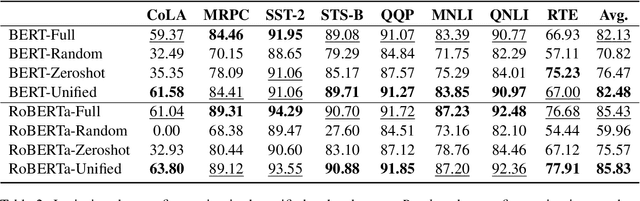
Pre-trained language models (PLMs) are known to be overly parameterized and have significant redundancy, indicating a small degree of freedom of the PLMs. Motivated by the observation, in this paper, we study the problem of re-parameterizing and fine-tuning PLMs from a new perspective: Discovery of intrinsic task-specific subspace. Specifically, by exploiting the dynamics of the fine-tuning process for a given task, the parameter optimization trajectory is learned to uncover its intrinsic task-specific subspace. A key finding is that PLMs can be effectively fine-tuned in the subspace with a small number of free parameters. Beyond, we observe some outlier dimensions emerging during fine-tuning in the subspace. Disabling these dimensions degrades the model performance significantly. This suggests that these dimensions are crucial to induce task-specific knowledge to downstream tasks.
Zero-shot stance detection based on cross-domain feature enhancement by contrastive learning
Oct 07, 2022
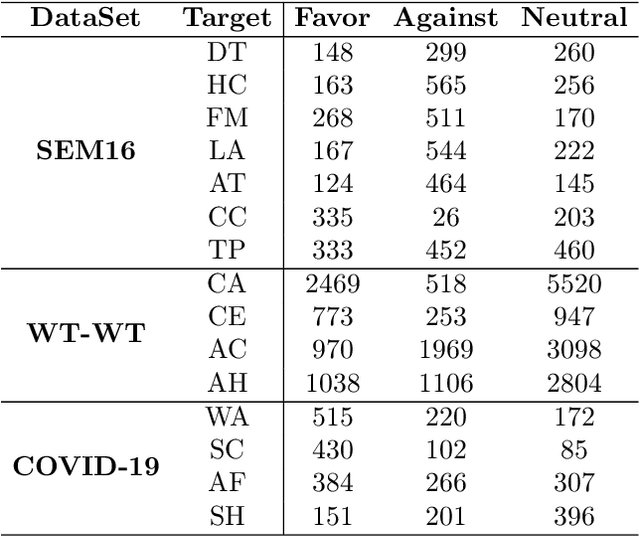
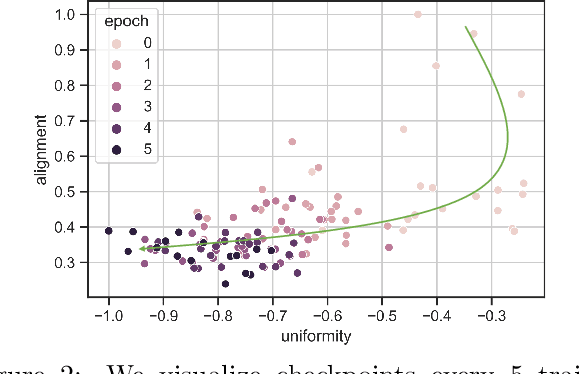
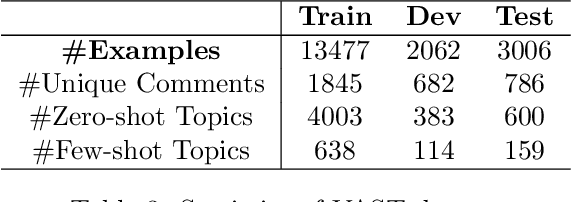
Zero-shot stance detection is challenging because it requires detecting the stance of previously unseen targets in the inference phase. The ability to learn transferable target-invariant features is critical for zero-shot stance detection. In this work, we propose a stance detection approach that can efficiently adapt to unseen targets, the core of which is to capture target-invariant syntactic expression patterns as transferable knowledge. Specifically, we first augment the data by masking the topic words of sentences, and then feed the augmented data to an unsupervised contrastive learning module to capture transferable features. Then, to fit a specific target, we encode the raw texts as target-specific features. Finally, we adopt an attention mechanism, which combines syntactic expression patterns with target-specific features to obtain enhanced features for predicting previously unseen targets. Experiments demonstrate that our model outperforms competitive baselines on four benchmark datasets.
Adversarial Learning-based Stance Classifier for COVID-19-related Health Policies
Sep 13, 2022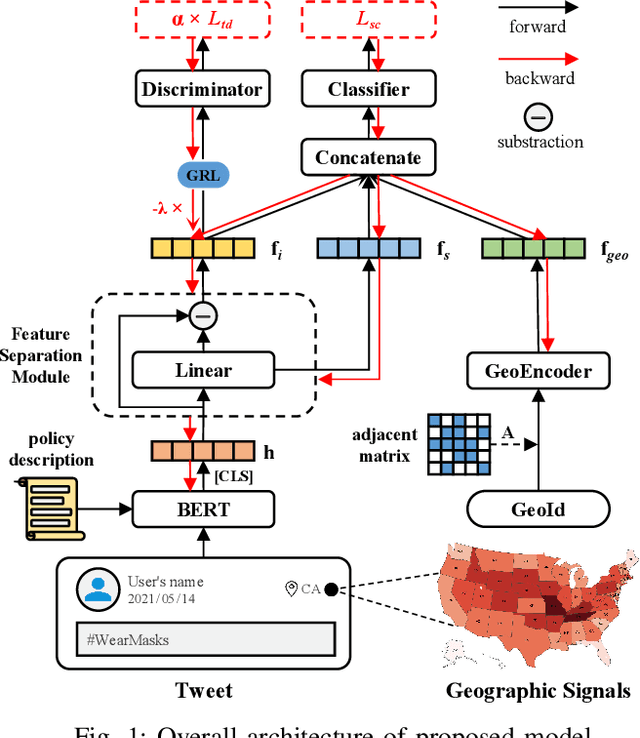
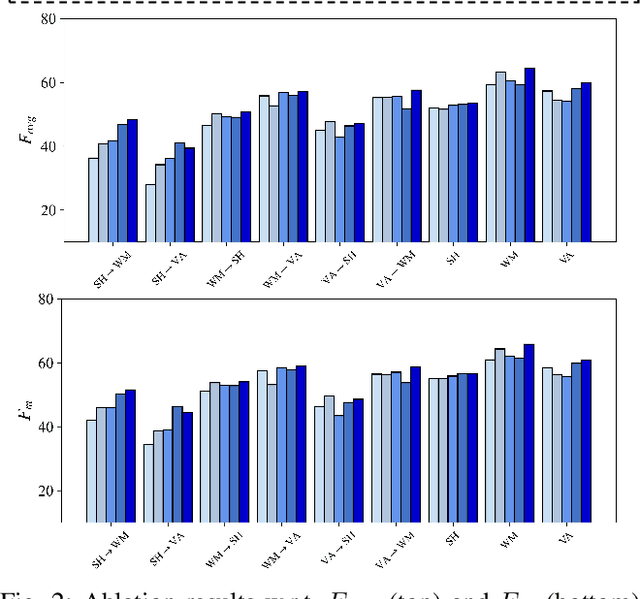
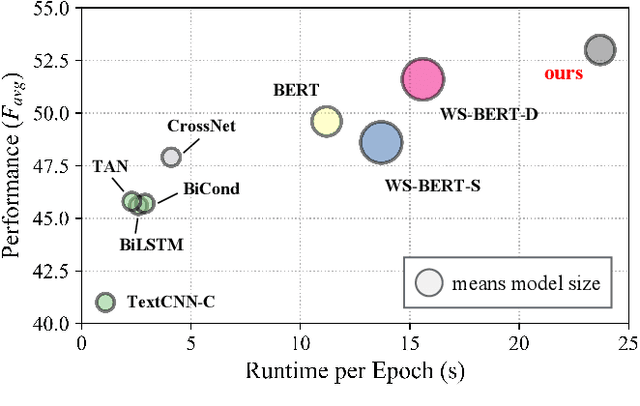

The ongoing COVID-19 pandemic has caused immeasurable losses for people worldwide. To contain the spread of virus and further alleviate the crisis, various health policies (e.g., stay-at-home orders) have been issued which spark heat discussion as users turn to share their attitudes on social media. In this paper, we consider a more realistic scenario on stance detection (i.e., cross-target and zero-shot settings) for the pandemic and propose an adversarial learning-based stance classifier to automatically identify the public attitudes toward COVID-19-related health policies. Specifically, we adopt adversarial learning which allows the model to train on a large amount of labeled data and capture transferable knowledge from source topics, so as to enable generalize to the emerging health policy with sparse labeled data. Meanwhile, a GeoEncoder is designed which encourages model to learn unobserved contextual factors specified by each region and represents them as non-text information to enhance model's deeper understanding. We evaluate the performance of a broad range of baselines in stance detection task for COVID-19-related policies, and experimental results show that our proposed method achieves state-of-the-art performance in both cross-target and zero-shot settings.
EpiGNN: Exploring Spatial Transmission with Graph Neural Network for Regional Epidemic Forecasting
Aug 23, 2022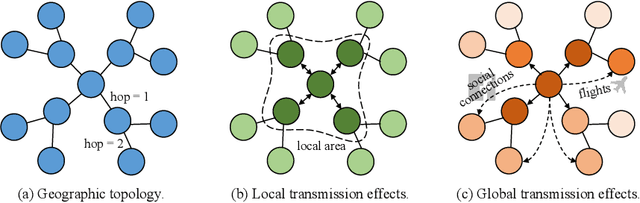
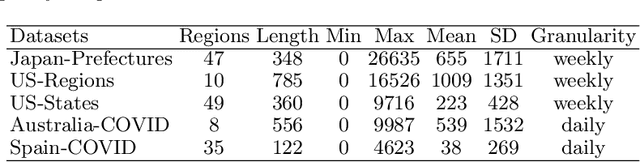
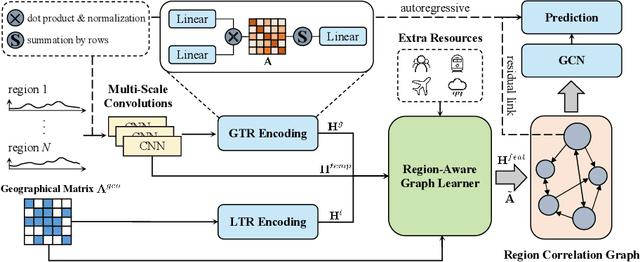
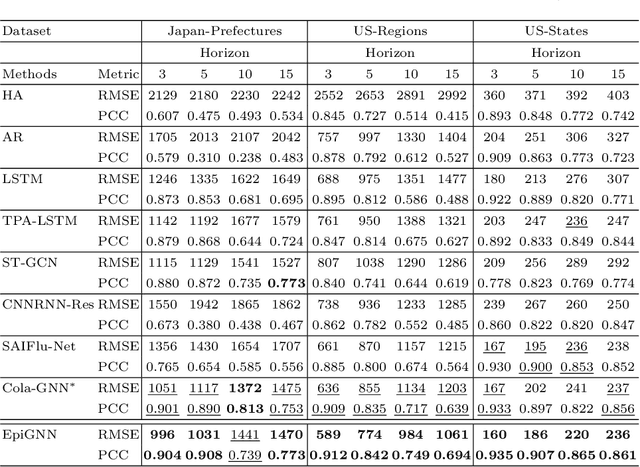
Epidemic forecasting is the key to effective control of epidemic transmission and helps the world mitigate the crisis that threatens public health. To better understand the transmission and evolution of epidemics, we propose EpiGNN, a graph neural network-based model for epidemic forecasting. Specifically, we design a transmission risk encoding module to characterize local and global spatial effects of regions in epidemic processes and incorporate them into the model. Meanwhile, we develop a Region-Aware Graph Learner (RAGL) that takes transmission risk, geographical dependencies, and temporal information into account to better explore spatial-temporal dependencies and makes regions aware of related regions' epidemic situations. The RAGL can also combine with external resources, such as human mobility, to further improve prediction performance. Comprehensive experiments on five real-world epidemic-related datasets (including influenza and COVID-19) demonstrate the effectiveness of our proposed method and show that EpiGNN outperforms state-of-the-art baselines by 9.48% in RMSE.