 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJuhua Liu
Achieving >97% on GSM8K: Deeply Understanding the Problems Makes LLMs Better Reasoners
Apr 28, 2024
Chain of Thought prompting strategy has enhanced the performance of Large Language Models (LLMs) across various NLP tasks. However, it still has shortcomings when dealing with complex reasoning tasks, including understanding errors, calculation errors and process errors (e.g., missing-step and hallucinations). Subsequently, our in-depth analyses among various error types show that deeply understanding the whole problem is critical in addressing complicated reasoning tasks. Motivated by this, we propose a simple-yet-effective method, namely Deeply Understanding the Problems (DUP), to enhance the LLMs' reasoning abilities. The core of our method is to encourage the LLMs to deeply understand the problems and leverage the key problem-solving information for better reasoning. Extensive experiments on 10 diverse reasoning benchmarks show that our DUP method consistently outperforms the other counterparts by a large margin. More encouragingly, DUP achieves a new SOTA result on the GSM8K benchmark, with an accuracy of 97.1% in a zero-shot setting.
RFL-CDNet: Towards Accurate Change Detection via Richer Feature Learning
Apr 27, 2024Change Detection is a crucial but extremely challenging task of remote sensing image analysis, and much progress has been made with the rapid development of deep learning. However, most existing deep learning-based change detection methods mainly focus on intricate feature extraction and multi-scale feature fusion, while ignoring the insufficient utilization of features in the intermediate stages, thus resulting in sub-optimal results. To this end, we propose a novel framework, named RFL-CDNet, that utilizes richer feature learning to boost change detection performance. Specifically, we first introduce deep multiple supervision to enhance intermediate representations, thus unleashing the potential of backbone feature extractor at each stage. Furthermore, we design the Coarse-To-Fine Guiding (C2FG) module and the Learnable Fusion (LF) module to further improve feature learning and obtain more discriminative feature representations. The C2FG module aims to seamlessly integrate the side prediction from the previous coarse-scale into the current fine-scale prediction in a coarse-to-fine manner, while LF module assumes that the contribution of each stage and each spatial location is independent, thus designing a learnable module to fuse multiple predictions. Experiments on several benchmark datasets show that our proposed RFL-CDNet achieves state-of-the-art performance on WHU cultivated land dataset and CDD dataset, and the second-best performance on WHU building dataset. The source code and models are publicly available at https://github.com/Hhaizee/RFL-CDNet.
When ControlNet Meets Inexplicit Masks: A Case Study of ControlNet on its Contour-following Ability
Mar 01, 2024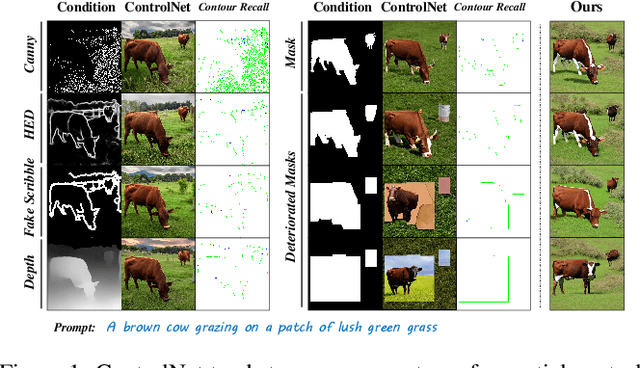
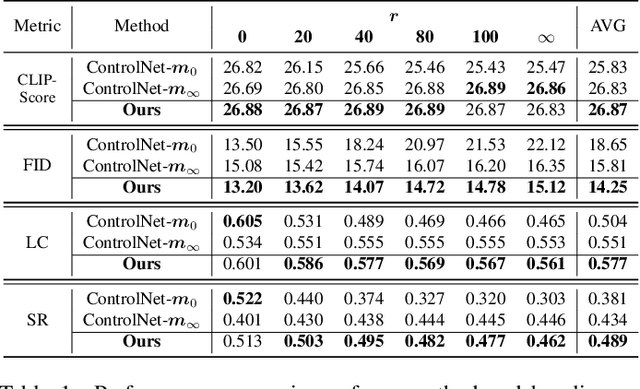


ControlNet excels at creating content that closely matches precise contours in user-provided masks. However, when these masks contain noise, as a frequent occurrence with non-expert users, the output would include unwanted artifacts. This paper first highlights the crucial role of controlling the impact of these inexplicit masks with diverse deterioration levels through in-depth analysis. Subsequently, to enhance controllability with inexplicit masks, an advanced Shape-aware ControlNet consisting of a deterioration estimator and a shape-prior modulation block is devised. The deterioration estimator assesses the deterioration factor of the provided masks. Then this factor is utilized in the modulation block to adaptively modulate the model's contour-following ability, which helps it dismiss the noise part in the inexplicit masks. Extensive experiments prove its effectiveness in encouraging ControlNet to interpret inaccurate spatial conditions robustly rather than blindly following the given contours. We showcase application scenarios like modifying shape priors and composable shape-controllable generation. Codes are soon available.
ROSE Doesn't Do That: Boosting the Safety of Instruction-Tuned Large Language Models with Reverse Prompt Contrastive Decoding
Feb 19, 2024With the development of instruction-tuned large language models (LLMs), improving the safety of LLMs has become more critical. However, the current approaches for aligning the LLMs output with expected safety usually require substantial training efforts, e.g., high-quality safety data and expensive computational resources, which are costly and inefficient. To this end, we present reverse prompt contrastive decoding (ROSE), a simple-yet-effective method to directly boost the safety of existing instruction-tuned LLMs without any additional training. The principle of ROSE is to improve the probability of desired safe output via suppressing the undesired output induced by the carefully-designed reverse prompts. Experiments on 6 safety and 2 general-purpose tasks show that, our ROSE not only brings consistent and significant safety improvements (up to +13.8% safety score) upon 5 types of instruction-tuned LLMs, but also benefits the general-purpose ability of LLMs. In-depth analyses explore the underlying mechanism of ROSE, and reveal when and where to use it.
Revisiting Knowledge Distillation for Autoregressive Language Models
Feb 19, 2024Knowledge distillation (KD) is a common approach to compress a teacher model to reduce its inference cost and memory footprint, by training a smaller student model. However, in the context of autoregressive language models (LMs), we empirically find that larger teacher LMs might dramatically result in a poorer student. In response to this problem, we conduct a series of analyses and reveal that different tokens have different teaching modes, neglecting which will lead to performance degradation. Motivated by this, we propose a simple yet effective adaptive teaching approach (ATKD) to improve the KD. The core of ATKD is to reduce rote learning and make teaching more diverse and flexible. Extensive experiments on 8 LM tasks show that, with the help of ATKD, various baseline KD methods can achieve consistent and significant performance gains (up to +3.04% average score) across all model types and sizes. More encouragingly, ATKD can improve the student model generalization effectively.
Hi-SAM: Marrying Segment Anything Model for Hierarchical Text Segmentation
Jan 31, 2024The Segment Anything Model (SAM), a profound vision foundation model pre-trained on a large-scale dataset, breaks the boundaries of general segmentation and sparks various downstream applications. This paper introduces Hi-SAM, a unified model leveraging SAM for hierarchical text segmentation. Hi-SAM excels in text segmentation across four hierarchies, including stroke, word, text-line, and paragraph, while realizing layout analysis as well. Specifically, we first turn SAM into a high-quality text stroke segmentation (TSS) model through a parameter-efficient fine-tuning approach. We use this TSS model to iteratively generate the text stroke labels in a semi-automatical manner, unifying labels across the four text hierarchies in the HierText dataset. Subsequently, with these complete labels, we launch the end-to-end trainable Hi-SAM based on the TSS architecture with a customized hierarchical mask decoder. During inference, Hi-SAM offers both automatic mask generation (AMG) mode and promptable segmentation mode. In terms of the AMG mode, Hi-SAM segments text stroke foreground masks initially, then samples foreground points for hierarchical text mask generation and achieves layout analysis in passing. As for the promptable mode, Hi-SAM provides word, text-line, and paragraph masks with a single point click. Experimental results show the state-of-the-art performance of our TSS model: 84.86% fgIOU on Total-Text and 88.96% fgIOU on TextSeg for text stroke segmentation. Moreover, compared to the previous specialist for joint hierarchical detection and layout analysis on HierText, Hi-SAM achieves significant improvements: 4.73% PQ and 5.39% F1 on the text-line level, 5.49% PQ and 7.39% F1 on the paragraph level layout analysis, requiring 20x fewer training epochs. The code is available at https://github.com/ymy-k/Hi-SAM.
GoMatching: A Simple Baseline for Video Text Spotting via Long and Short Term Matching
Jan 13, 2024Beyond the text detection and recognition tasks in image text spotting, video text spotting presents an augmented challenge with the inclusion of tracking. While advanced end-to-end trainable methods have shown commendable performance, the pursuit of multi-task optimization may pose the risk of producing sub-optimal outcomes for individual tasks. In this paper, we highlight a main bottleneck in the state-of-the-art video text spotter: the limited recognition capability. In response to this issue, we propose to efficiently turn an off-the-shelf query-based image text spotter into a specialist on video and present a simple baseline termed GoMatching, which focuses the training efforts on tracking while maintaining strong recognition performance. To adapt the image text spotter to video datasets, we add a rescoring head to rescore each detected instance's confidence via efficient tuning, leading to a better tracking candidate pool. Additionally, we design a long-short term matching module, termed LST-Matcher, to enhance the spotter's tracking capability by integrating both long- and short-term matching results via Transformer. Based on the above simple designs, GoMatching achieves impressive performance on two public benchmarks, e.g., setting a new record on the ICDAR15-video dataset, and one novel test set with arbitrary-shaped text, while saving considerable training budgets. The code will be released at https://github.com/Hxyz-123/GoMatching.
Zero-Shot Sharpness-Aware Quantization for Pre-trained Language Models
Oct 20, 2023Quantization is a promising approach for reducing memory overhead and accelerating inference, especially in large pre-trained language model (PLM) scenarios. While having no access to original training data due to security and privacy concerns has emerged the demand for zero-shot quantization. Most of the cutting-edge zero-shot quantization methods primarily 1) apply to computer vision tasks, and 2) neglect of overfitting problem in the generative adversarial learning process, leading to sub-optimal performance. Motivated by this, we propose a novel zero-shot sharpness-aware quantization (ZSAQ) framework for the zero-shot quantization of various PLMs. The key algorithm in solving ZSAQ is the SAM-SGA optimization, which aims to improve the quantization accuracy and model generalization via optimizing a minimax problem. We theoretically prove the convergence rate for the minimax optimization problem and this result can be applied to other nonconvex-PL minimax optimization frameworks. Extensive experiments on 11 tasks demonstrate that our method brings consistent and significant performance gains on both discriminative and generative PLMs, i.e., up to +6.98 average score. Furthermore, we empirically validate that our method can effectively improve the model generalization.
PNT-Edge: Towards Robust Edge Detection with Noisy Labels by Learning Pixel-level Noise Transitions
Jul 26, 2023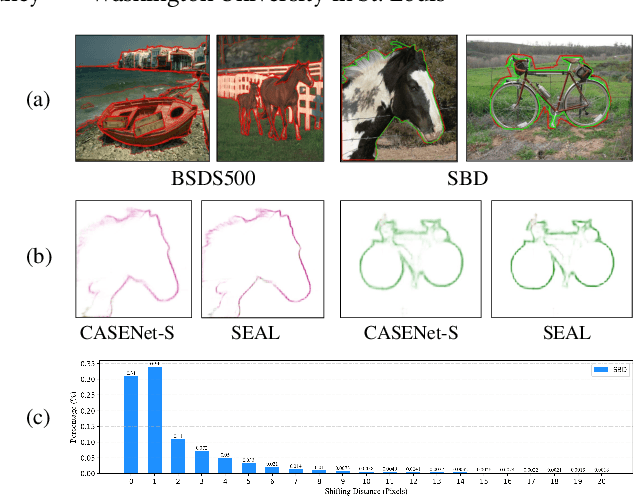
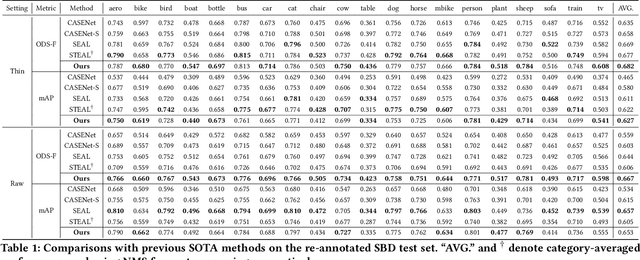
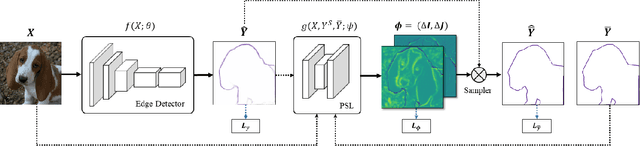
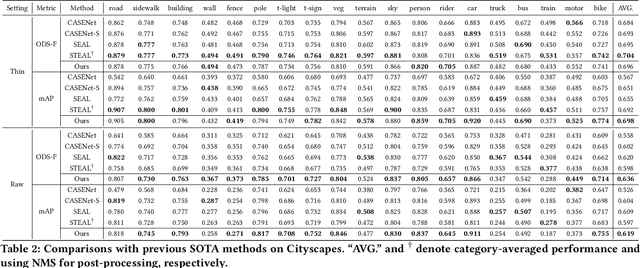
Relying on large-scale training data with pixel-level labels, previous edge detection methods have achieved high performance. However, it is hard to manually label edges accurately, especially for large datasets, and thus the datasets inevitably contain noisy labels. This label-noise issue has been studied extensively for classification, while still remaining under-explored for edge detection. To address the label-noise issue for edge detection, this paper proposes to learn Pixel-level NoiseTransitions to model the label-corruption process. To achieve it, we develop a novel Pixel-wise Shift Learning (PSL) module to estimate the transition from clean to noisy labels as a displacement field. Exploiting the estimated noise transitions, our model, named PNT-Edge, is able to fit the prediction to clean labels. In addition, a local edge density regularization term is devised to exploit local structure information for better transition learning. This term encourages learning large shifts for the edges with complex local structures. Experiments on SBD and Cityscapes demonstrate the effectiveness of our method in relieving the impact of label noise. Codes will be available at github.
DeepSolo++: Let Transformer Decoder with Explicit Points Solo for Text Spotting
May 31, 2023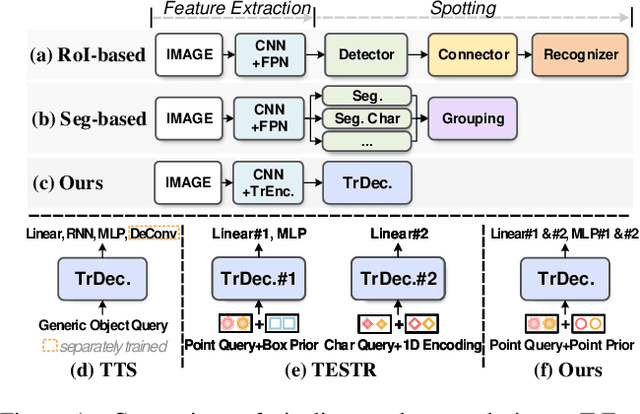
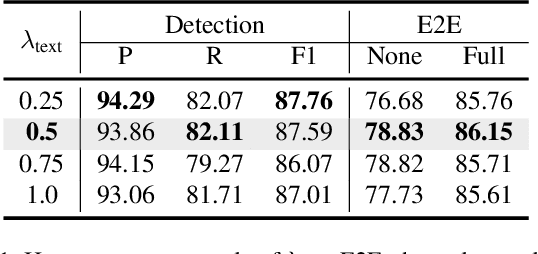
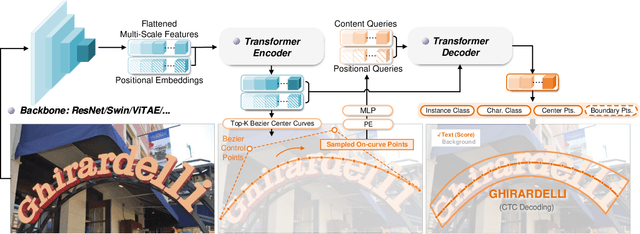
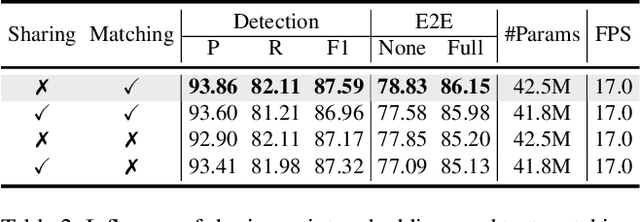
End-to-end text spotting aims to integrate scene text detection and recognition into a unified framework. Dealing with the relationship between the two sub-tasks plays a pivotal role in designing effective spotters. Although Transformer-based methods eliminate the heuristic post-processing, they still suffer from the synergy issue between the sub-tasks and low training efficiency. In this paper, we present DeepSolo, a simple DETR-like baseline that lets a single decoder with explicit points solo for text detection and recognition simultaneously and efficiently. Technically, for each text instance, we represent the character sequence as ordered points and model them with learnable explicit point queries. After passing a single decoder, the point queries have encoded requisite text semantics and locations. Furthermore, we show the surprisingly good extensibility of our method, in terms of character class, language type, and task. On the one hand, DeepSolo not only performs well in English scenes but also masters the Chinese transcription with complex font structure and a thousand-level character classes. On the other hand, based on the extensibility of DeepSolo, we launch DeepSolo++ for multilingual text spotting, making a further step to let Transformer decoder with explicit points solo for multilingual text detection, recognition, and script identification all at once. Extensive experiments on public benchmarks demonstrate that our simple approach achieves better training efficiency compared with Transformer-based models and outperforms the previous state-of-the-art. In addition, DeepSolo and DeepSolo++ are also compatible with line annotations, which require much less annotation cost than polygons. The code is available at \url{https://github.com/ViTAE-Transformer/DeepSolo}.