 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi Wen
TransLandSeg: A Transfer Learning Approach for Landslide Semantic Segmentation Based on Vision Foundation Model
Mar 15, 2024
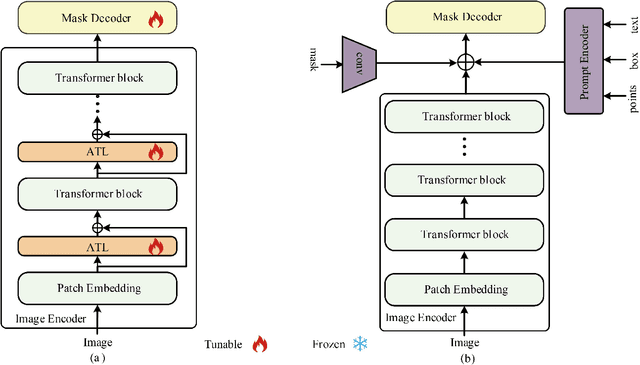
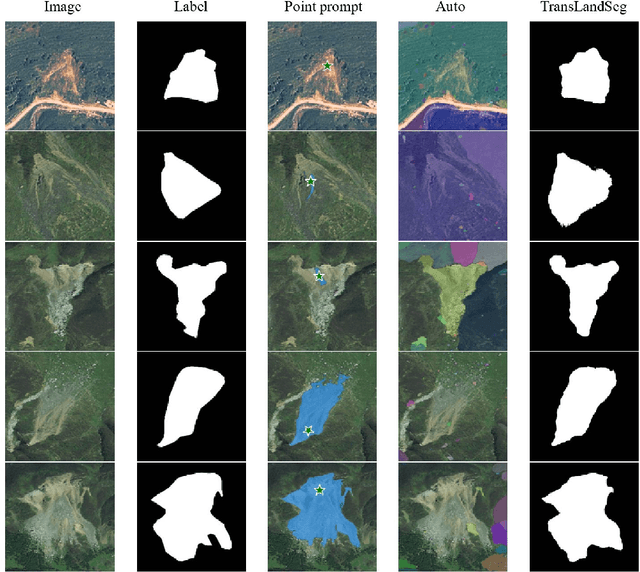
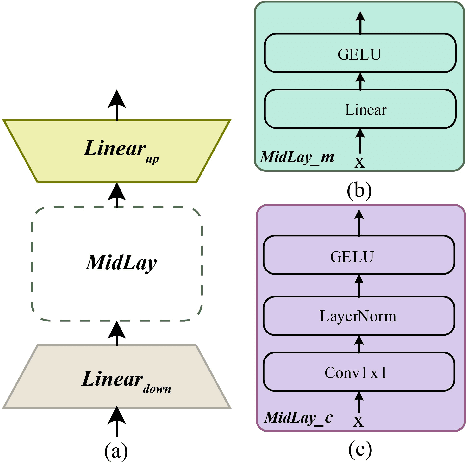
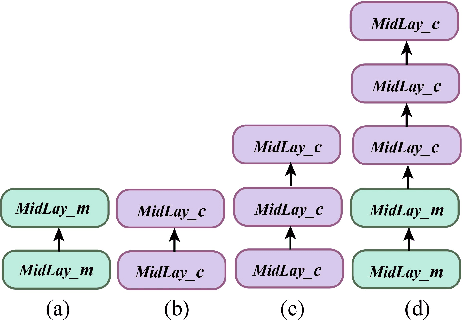
Landslides are one of the most destructive natural disasters in the world, posing a serious threat to human life and safety. The development of foundation models has provided a new research paradigm for large-scale landslide detection. The Segment Anything Model (SAM) has garnered widespread attention in the field of image segmentation. However, our experiment found that SAM performed poorly in the task of landslide segmentation. We propose TransLandSeg, which is a transfer learning approach for landslide semantic segmentation based on a vision foundation model (VFM). TransLandSeg outperforms traditional semantic segmentation models on both the Landslide4Sense dataset and the Bijie landslide dataset. Our proposed adaptive transfer learning (ATL) architecture enables the powerful segmentation capability of SAM to be transferred to landslide detection by training only 1.3% of the number of the parameters of SAM, which greatly improves the training efficiency of the model. Finally we also conducted ablation experiments on models with different ATL structures, concluded that the deployment location and residual connection of ATL play an important role in TransLandSeg accuracy improvement.
CartoMark: a benchmark dataset for map pattern recognition and 1 map content retrieval with machine intelligence
Dec 14, 2023Maps are fundamental medium to visualize and represent the real word in a simple and 16 philosophical way. The emergence of the 3rd wave information has made a proportion of maps are available to be generated ubiquitously, which would significantly enrich the dimensions and perspectives to understand the characteristics of the real world. However, a majority of map dataset have never been discovered, acquired and effectively used, and the map data used in many applications might not be completely fitted for the authentic demands of these applications. This challenge is emerged due to the lack of numerous well-labelled benchmark datasets for implementing the deep learning approaches into identifying complicated map content. Thus, we develop a large-scale benchmark dataset that includes well-labelled dataset for map text annotation recognition, map scene classification, map super-resolution reconstruction, and map style transferring. Furthermore, these well-labelled datasets would facilitate the state-of-the-art machine intelligence technologies to conduct map feature detection, map pattern recognition and map content retrieval. We hope our efforts would be useful for AI-enhanced cartographical applications.
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Sep 27, 2023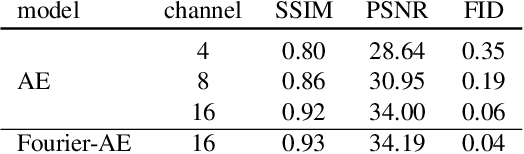

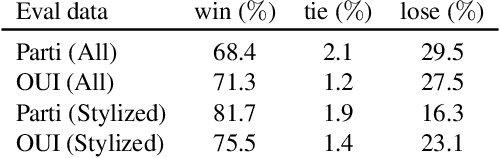

Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on $1.1$ billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of $82.9\%$ compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred $68.4\%$ and $71.3\%$ of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
DealMVC: Dual Contrastive Calibration for Multi-view Clustering
Sep 02, 2023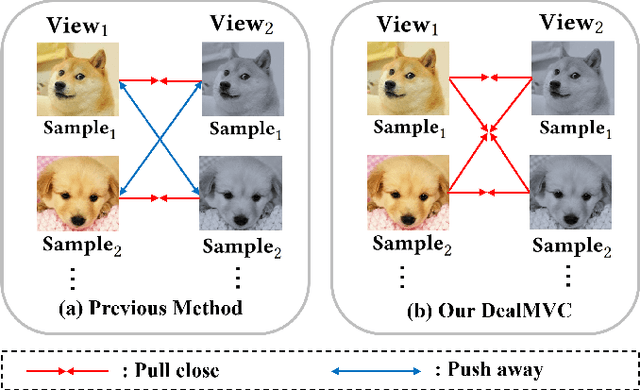

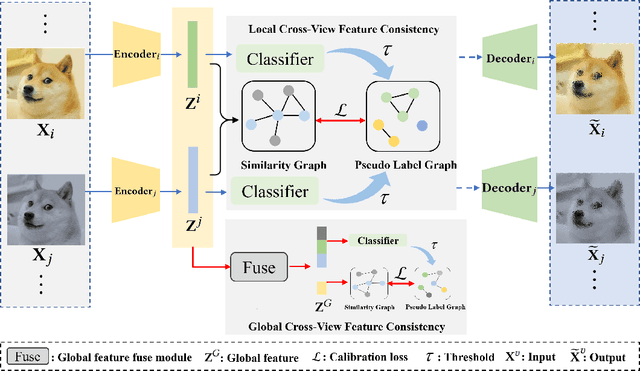
Benefiting from the strong view-consistent information mining capacity, multi-view contrastive clustering has attracted plenty of attention in recent years. However, we observe the following drawback, which limits the clustering performance from further improvement. The existing multi-view models mainly focus on the consistency of the same samples in different views while ignoring the circumstance of similar but different samples in cross-view scenarios. To solve this problem, we propose a novel Dual contrastive calibration network for Multi-View Clustering (DealMVC). Specifically, we first design a fusion mechanism to obtain a global cross-view feature. Then, a global contrastive calibration loss is proposed by aligning the view feature similarity graph and the high-confidence pseudo-label graph. Moreover, to utilize the diversity of multi-view information, we propose a local contrastive calibration loss to constrain the consistency of pair-wise view features. The feature structure is regularized by reliable class information, thus guaranteeing similar samples have similar features in different views. During the training procedure, the interacted cross-view feature is jointly optimized at both local and global levels. In comparison with other state-of-the-art approaches, the comprehensive experimental results obtained from eight benchmark datasets provide substantial validation of the effectiveness and superiority of our algorithm. We release the code of DealMVC at https://github.com/xihongyang1999/DealMVC on GitHub.
Scalable Incomplete Multi-View Clustering with Structure Alignment
Aug 31, 2023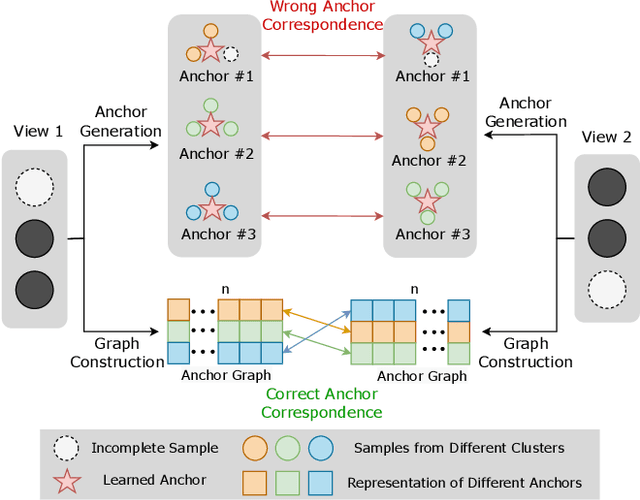
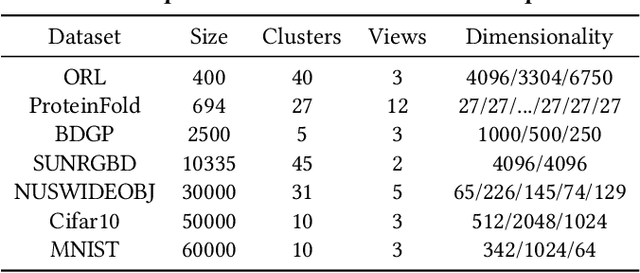
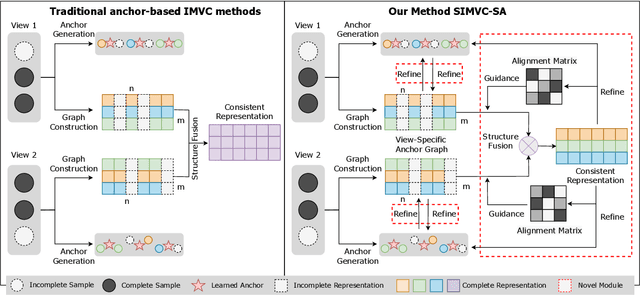
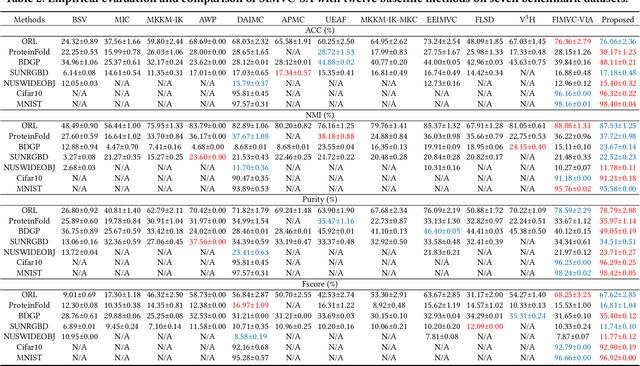
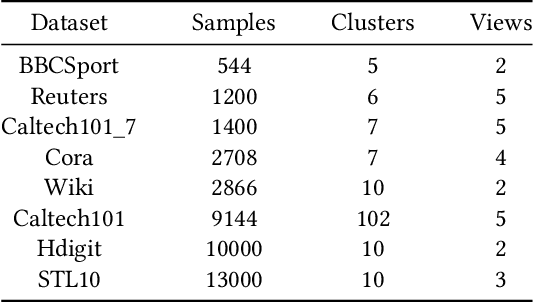
The success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.
Efficient Multi-View Graph Clustering with Local and Global Structure Preservation
Aug 31, 2023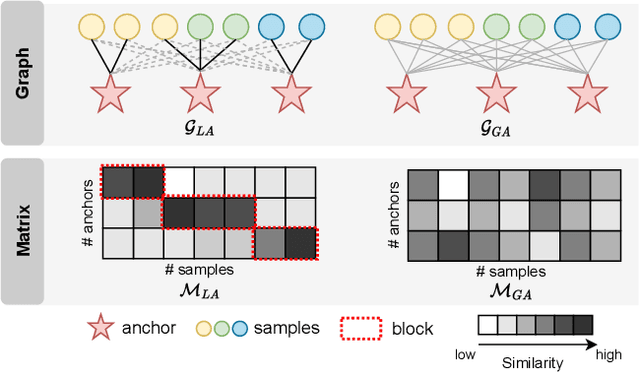
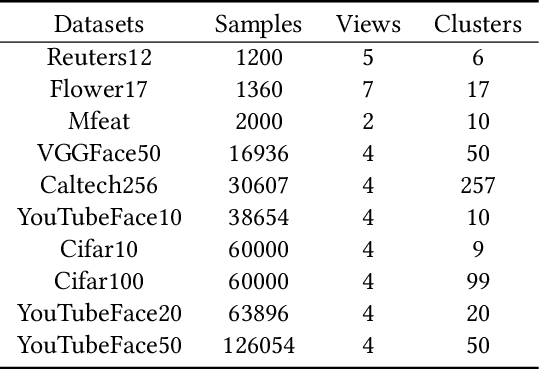
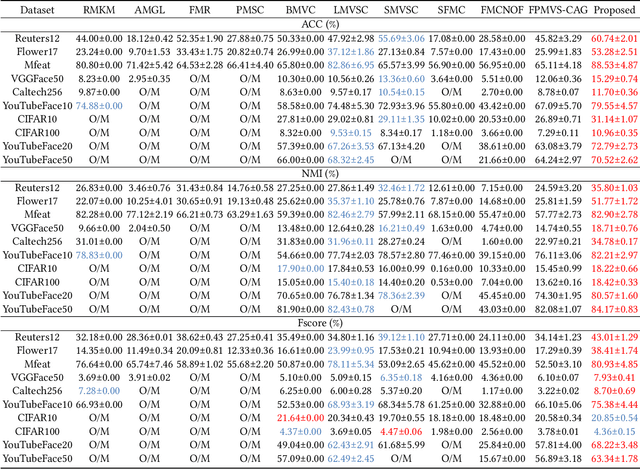
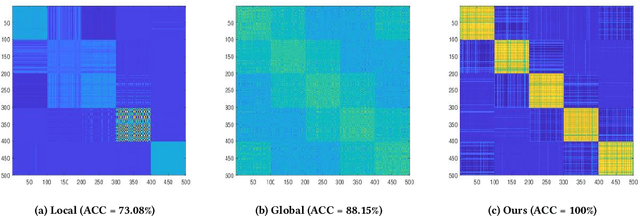
Anchor-based multi-view graph clustering (AMVGC) has received abundant attention owing to its high efficiency and the capability to capture complementary structural information across multiple views. Intuitively, a high-quality anchor graph plays an essential role in the success of AMVGC. However, the existing AMVGC methods only consider single-structure information, i.e., local or global structure, which provides insufficient information for the learning task. To be specific, the over-scattered global structure leads to learned anchors failing to depict the cluster partition well. In contrast, the local structure with an improper similarity measure results in potentially inaccurate anchor assignment, ultimately leading to sub-optimal clustering performance. To tackle the issue, we propose a novel anchor-based multi-view graph clustering framework termed Efficient Multi-View Graph Clustering with Local and Global Structure Preservation (EMVGC-LG). Specifically, a unified framework with a theoretical guarantee is designed to capture local and global information. Besides, EMVGC-LG jointly optimizes anchor construction and graph learning to enhance the clustering quality. In addition, EMVGC-LG inherits the linear complexity of existing AMVGC methods respecting the sample number, which is time-economical and scales well with the data size. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method.
Unpaired Multi-View Graph Clustering with Cross-View Structure Matching
Jul 07, 2023Multi-view clustering (MVC), which effectively fuses information from multiple views for better performance, has received increasing attention. Most existing MVC methods assume that multi-view data are fully paired, which means that the mappings of all corresponding samples between views are pre-defined or given in advance. However, the data correspondence is often incomplete in real-world applications due to data corruption or sensor differences, referred as the data-unpaired problem (DUP) in multi-view literature. Although several attempts have been made to address the DUP issue, they suffer from the following drawbacks: 1) Most methods focus on the feature representation while ignoring the structural information of multi-view data, which is essential for clustering tasks; 2) Existing methods for partially unpaired problems rely on pre-given cross-view alignment information, resulting in their inability to handle fully unpaired problems; 3) Their inevitable parameters degrade the efficiency and applicability of the models. To tackle these issues, we propose a novel parameter-free graph clustering framework termed Unpaired Multi-view Graph Clustering framework with Cross-View Structure Matching (UPMGC-SM). Specifically, unlike the existing methods, UPMGC-SM effectively utilizes the structural information from each view to refine cross-view correspondences. Besides, our UPMGC-SM is a unified framework for both the fully and partially unpaired multi-view graph clustering. Moreover, existing graph clustering methods can adopt our UPMGC-SM to enhance their ability for unpaired scenarios. Extensive experiments demonstrate the effectiveness and generalization of our proposed framework for both paired and unpaired datasets.
One-step Multi-view Clustering with Diverse Representation
Jun 27, 2023
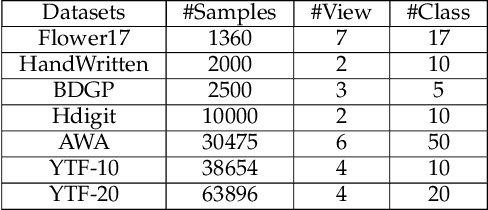
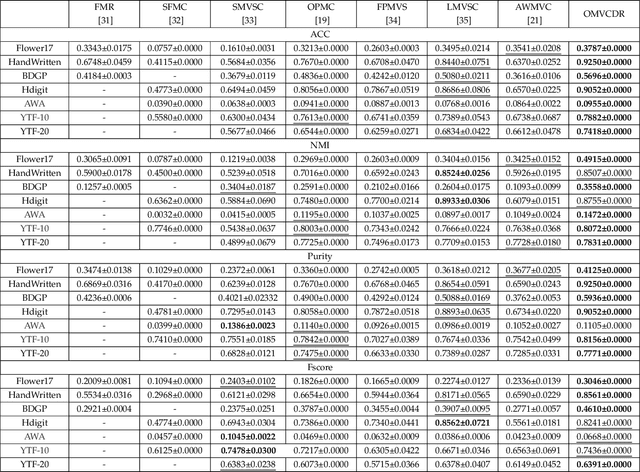

Multi-view clustering has attracted broad attention due to its capacity to utilize consistent and complementary information among views. Although tremendous progress has been made recently, most existing methods undergo high complexity, preventing them from being applied to large-scale tasks. Multi-view clustering via matrix factorization is a representative to address this issue. However, most of them map the data matrices into a fixed dimension, limiting the model's expressiveness. Moreover, a range of methods suffers from a two-step process, i.e., multimodal learning and the subsequent $k$-means, inevitably causing a sub-optimal clustering result. In light of this, we propose a one-step multi-view clustering with diverse representation method, which incorporates multi-view learning and $k$-means into a unified framework. Specifically, we first project original data matrices into various latent spaces to attain comprehensive information and auto-weight them in a self-supervised manner. Then we directly use the information matrices under diverse dimensions to obtain consensus discrete clustering labels. The unified work of representation learning and clustering boosts the quality of the final results. Furthermore, we develop an efficient optimization algorithm with proven convergence to solve the resultant problem. Comprehensive experiments on various datasets demonstrate the promising clustering performance of our proposed method.
Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training
Jan 05, 2023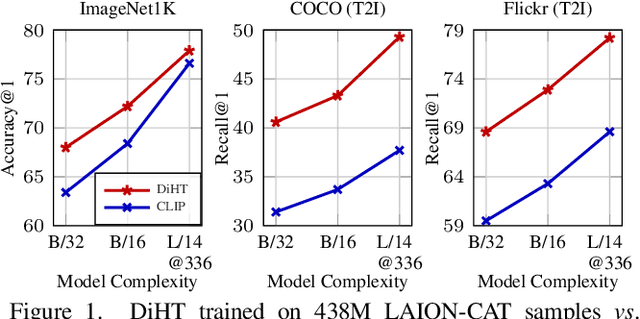
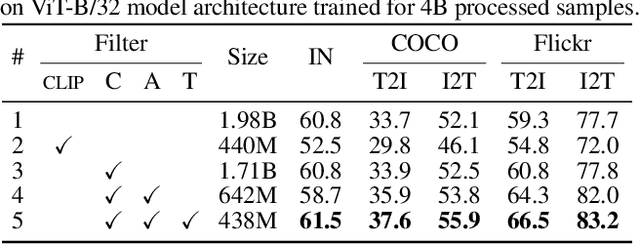
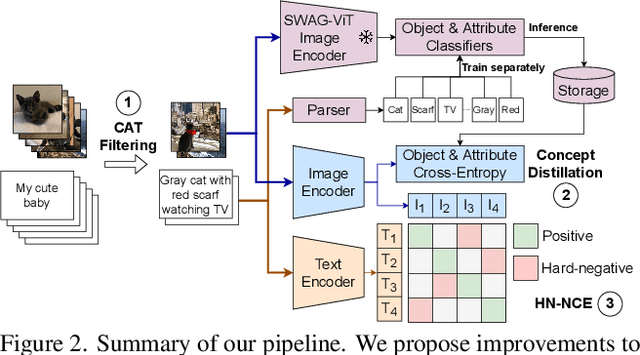
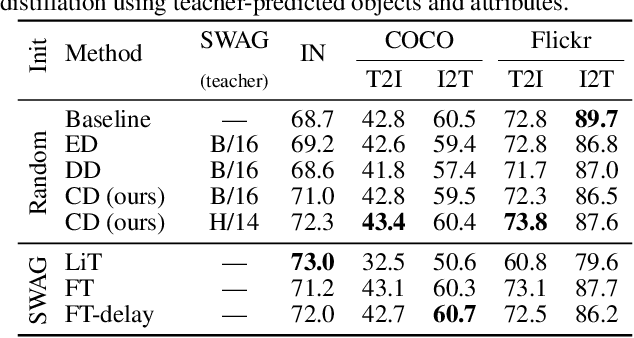
Vision-language models trained with contrastive learning on large-scale noisy data are becoming increasingly popular for zero-shot recognition problems. In this paper we improve the following three aspects of the contrastive pre-training pipeline: dataset noise, model initialization and the training objective. First, we propose a straightforward filtering strategy titled Complexity, Action, and Text-spotting (CAT) that significantly reduces dataset size, while achieving improved performance across zero-shot vision-language tasks. Next, we propose an approach titled Concept Distillation to leverage strong unimodal representations for contrastive training that does not increase training complexity while outperforming prior work. Finally, we modify the traditional contrastive alignment objective, and propose an importance-sampling approach to up-sample the importance of hard-negatives without adding additional complexity. On an extensive zero-shot benchmark of 29 tasks, our Distilled and Hard-negative Training (DiHT) approach improves on 20 tasks compared to the baseline. Furthermore, for few-shot linear probing, we propose a novel approach that bridges the gap between zero-shot and few-shot performance, substantially improving over prior work. Models are available at https://github.com/facebookresearch/diht.
PACO: Parts and Attributes of Common Objects
Jan 04, 2023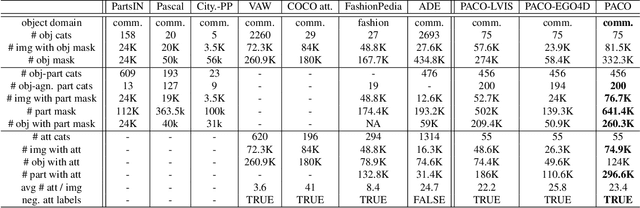
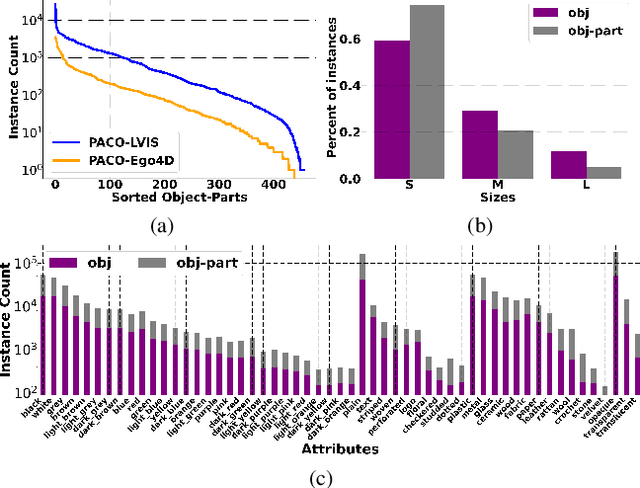
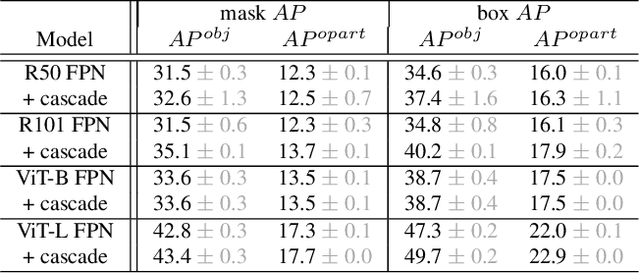

Object models are gradually progressing from predicting just category labels to providing detailed descriptions of object instances. This motivates the need for large datasets which go beyond traditional object masks and provide richer annotations such as part masks and attributes. Hence, we introduce PACO: Parts and Attributes of Common Objects. It spans 75 object categories, 456 object-part categories and 55 attributes across image (LVIS) and video (Ego4D) datasets. We provide 641K part masks annotated across 260K object boxes, with roughly half of them exhaustively annotated with attributes as well. We design evaluation metrics and provide benchmark results for three tasks on the dataset: part mask segmentation, object and part attribute prediction and zero-shot instance detection. Dataset, models, and code are open-sourced at https://github.com/facebookresearch/paco.