 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoliang Dai
Efficient Quantization Strategies for Latent Diffusion Models
Dec 09, 2023
Latent Diffusion Models (LDMs) capture the dynamic evolution of latent variables over time, blending patterns and multimodality in a generative system. Despite the proficiency of LDM in various applications, such as text-to-image generation, facilitated by robust text encoders and a variational autoencoder, the critical need to deploy large generative models on edge devices compels a search for more compact yet effective alternatives. Post Training Quantization (PTQ), a method to compress the operational size of deep learning models, encounters challenges when applied to LDM due to temporal and structural complexities. This study proposes a quantization strategy that efficiently quantize LDMs, leveraging Signal-to-Quantization-Noise Ratio (SQNR) as a pivotal metric for evaluation. By treating the quantization discrepancy as relative noise and identifying sensitive part(s) of a model, we propose an efficient quantization approach encompassing both global and local strategies. The global quantization process mitigates relative quantization noise by initiating higher-precision quantization on sensitive blocks, while local treatments address specific challenges in quantization-sensitive and time-sensitive modules. The outcomes of our experiments reveal that the implementation of both global and local treatments yields a highly efficient and effective Post Training Quantization (PTQ) of LDMs.
Cache Me if You Can: Accelerating Diffusion Models through Block Caching
Dec 06, 2023

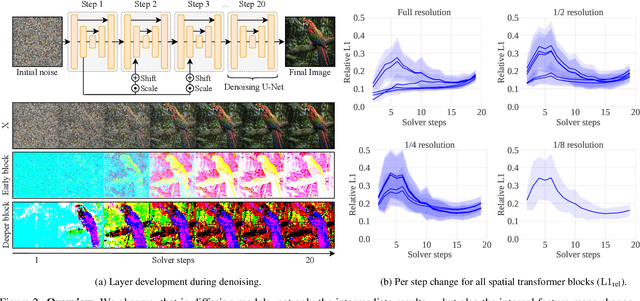
Diffusion models have recently revolutionized the field of image synthesis due to their ability to generate photorealistic images. However, one of the major drawbacks of diffusion models is that the image generation process is costly. A large image-to-image network has to be applied many times to iteratively refine an image from random noise. While many recent works propose techniques to reduce the number of required steps, they generally treat the underlying denoising network as a black box. In this work, we investigate the behavior of the layers within the network and find that 1) the layers' output changes smoothly over time, 2) the layers show distinct patterns of change, and 3) the change from step to step is often very small. We hypothesize that many layer computations in the denoising network are redundant. Leveraging this, we introduce block caching, in which we reuse outputs from layer blocks of previous steps to speed up inference. Furthermore, we propose a technique to automatically determine caching schedules based on each block's changes over timesteps. In our experiments, we show through FID, human evaluation and qualitative analysis that Block Caching allows to generate images with higher visual quality at the same computational cost. We demonstrate this for different state-of-the-art models (LDM and EMU) and solvers (DDIM and DPM).
LEGO: Learning EGOcentric Action Frame Generation via Visual Instruction Tuning
Dec 06, 2023Generating instructional images of human daily actions from an egocentric viewpoint serves a key step towards efficient skill transfer. In this paper, we introduce a novel problem -- egocentric action frame generation. The goal is to synthesize the action frame conditioning on the user prompt question and an input egocentric image that captures user's environment. Notably, existing egocentric datasets lack the detailed annotations that describe the execution of actions. Additionally, the diffusion-based image manipulation models fail to control the state change of an action within the corresponding egocentric image pixel space. To this end, we finetune a visual large language model (VLLM) via visual instruction tuning for curating the enriched action descriptions to address our proposed problem. Moreover, we propose to Learn EGOcentric (LEGO) action frame generation using image and text embeddings from VLLM as additional conditioning. We validate our proposed model on two egocentric datasets -- Ego4D and Epic-Kitchens. Our experiments show prominent improvement over prior image manipulation models in both quantitative and qualitative evaluation. We also conduct detailed ablation studies and analysis to provide insights on our method.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023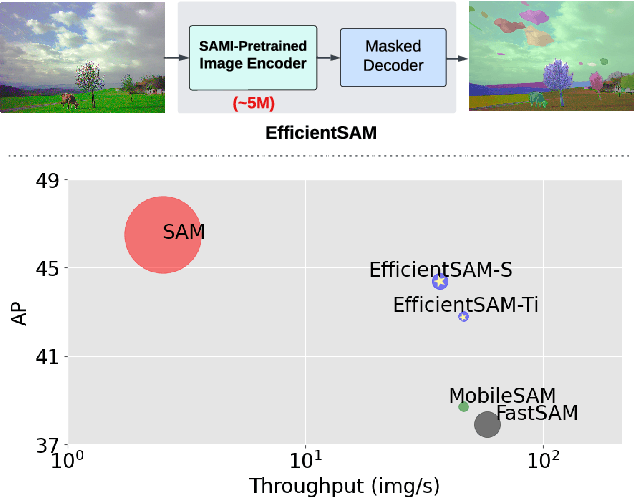
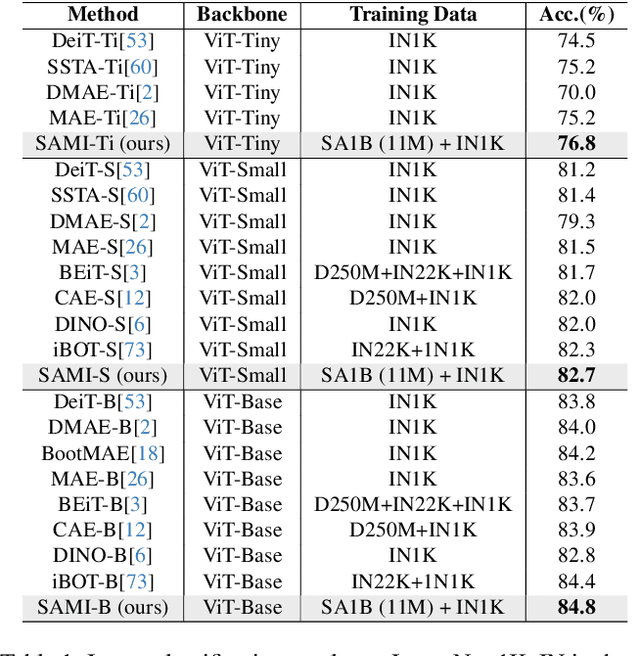
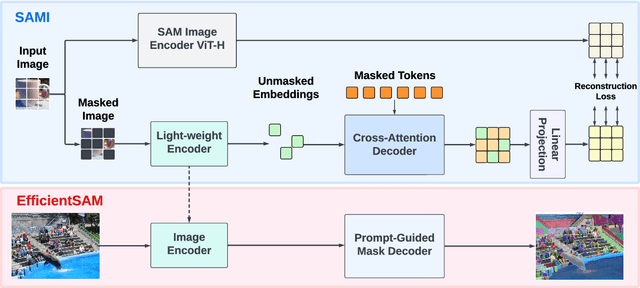
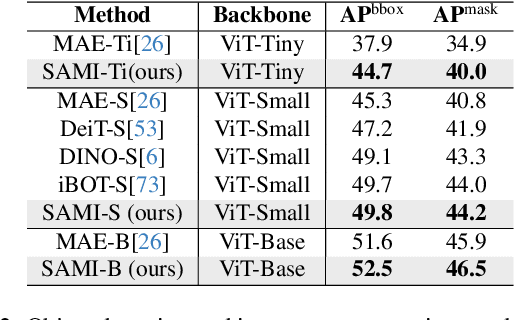
Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Sep 27, 2023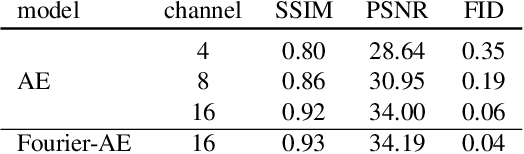

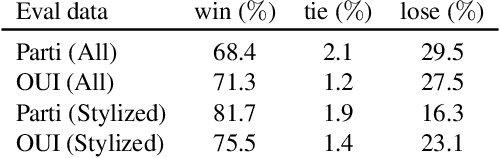

Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on $1.1$ billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of $82.9\%$ compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred $68.4\%$ and $71.3\%$ of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
Unveiling Optimal SDG Pathways: An Innovative Approach Leveraging Graph Pruning and Intent Graph for Effective Recommendations
Sep 21, 2023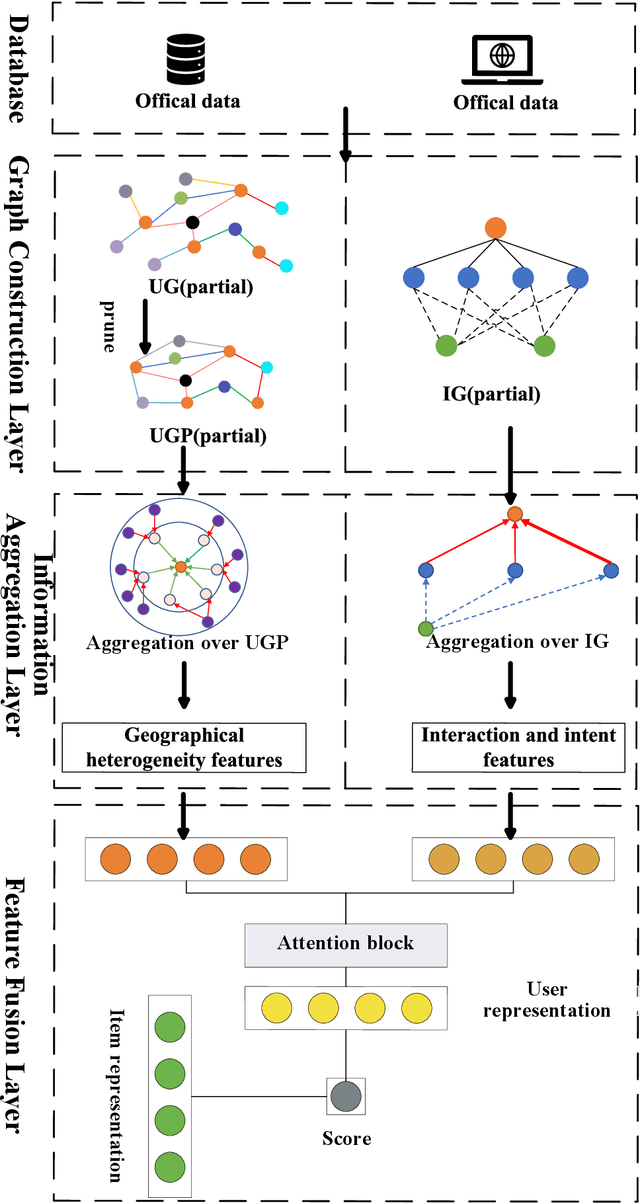
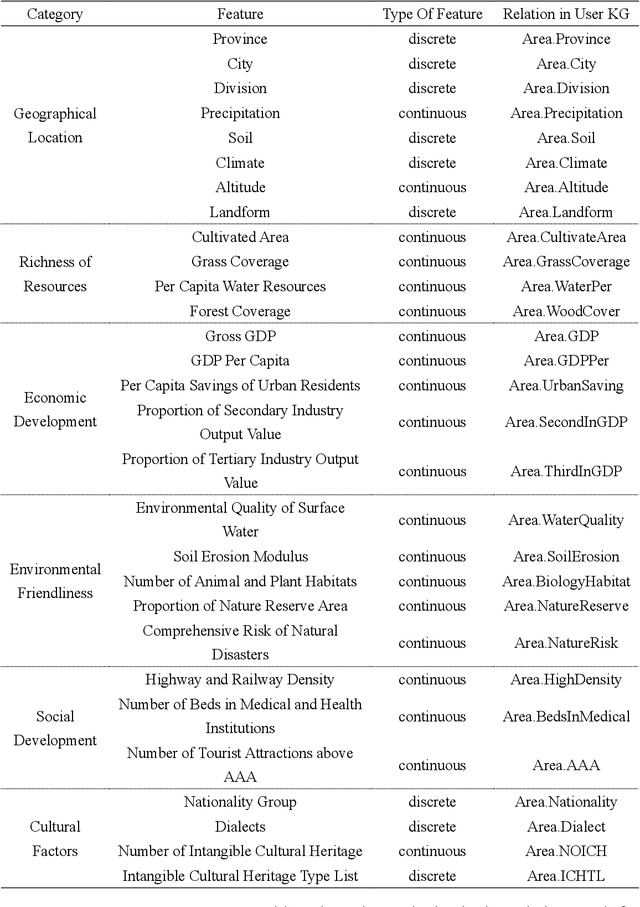
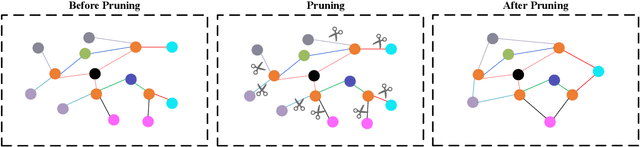

The recommendation of appropriate development pathways, also known as ecological civilization patterns for achieving Sustainable Development Goals (namely, sustainable development patterns), are of utmost importance for promoting ecological, economic, social, and resource sustainability in a specific region. To achieve this, the recommendation process must carefully consider the region's natural, environmental, resource, and economic characteristics. However, current recommendation algorithms in the field of computer science fall short in adequately addressing the spatial heterogeneity related to environment and sparsity of regional historical interaction data, which limits their effectiveness in recommending sustainable development patterns. To overcome these challenges, this paper proposes a method called User Graph after Pruning and Intent Graph (UGPIG). Firstly, we utilize the high-density linking capability of the pruned User Graph to address the issue of spatial heterogeneity neglect in recommendation algorithms. Secondly, we construct an Intent Graph by incorporating the intent network, which captures the preferences for attributes including environmental elements of target regions. This approach effectively alleviates the problem of sparse historical interaction data in the region. Through extensive experiments, we demonstrate that UGPIG outperforms state-of-the-art recommendation algorithms like KGCN, KGAT, and KGIN in sustainable development pattern recommendations, with a maximum improvement of 9.61% in Top-3 recommendation performance.
Auto-CARD: Efficient and Robust Codec Avatar Driving for Real-time Mobile Telepresence
Apr 24, 2023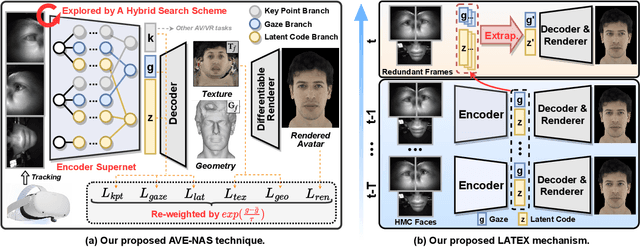
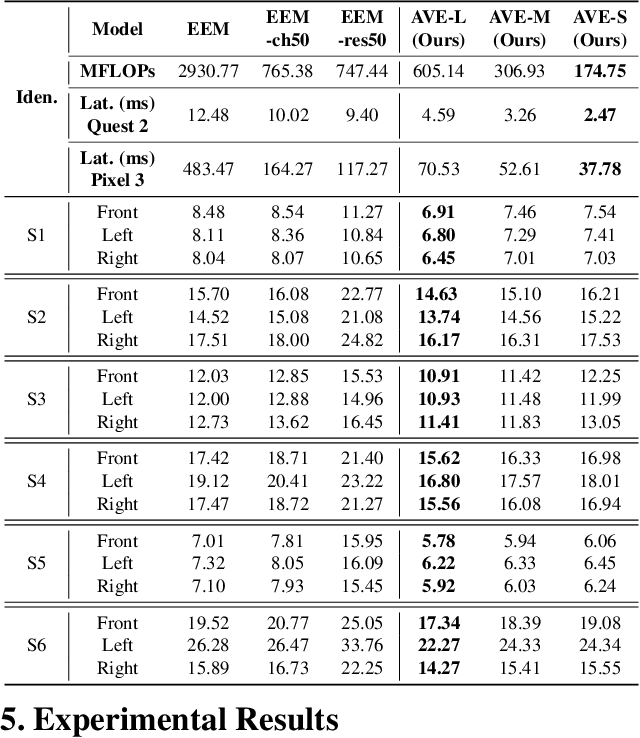

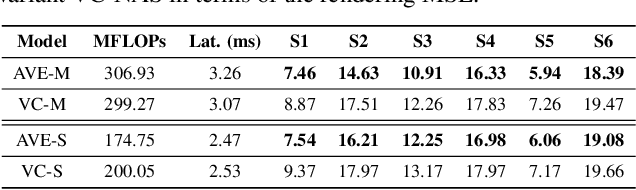
Real-time and robust photorealistic avatars for telepresence in AR/VR have been highly desired for enabling immersive photorealistic telepresence. However, there still exists one key bottleneck: the considerable computational expense needed to accurately infer facial expressions captured from headset-mounted cameras with a quality level that can match the realism of the avatar's human appearance. To this end, we propose a framework called Auto-CARD, which for the first time enables real-time and robust driving of Codec Avatars when exclusively using merely on-device computing resources. This is achieved by minimizing two sources of redundancy. First, we develop a dedicated neural architecture search technique called AVE-NAS for avatar encoding in AR/VR, which explicitly boosts both the searched architectures' robustness in the presence of extreme facial expressions and hardware friendliness on fast evolving AR/VR headsets. Second, we leverage the temporal redundancy in consecutively captured images during continuous rendering and develop a mechanism dubbed LATEX to skip the computation of redundant frames. Specifically, we first identify an opportunity from the linearity of the latent space derived by the avatar decoder and then propose to perform adaptive latent extrapolation for redundant frames. For evaluation, we demonstrate the efficacy of our Auto-CARD framework in real-time Codec Avatar driving settings, where we achieve a 5.05x speed-up on Meta Quest 2 while maintaining a comparable or even better animation quality than state-of-the-art avatar encoder designs.
Trainable Projected Gradient Method for Robust Fine-tuning
Mar 28, 2023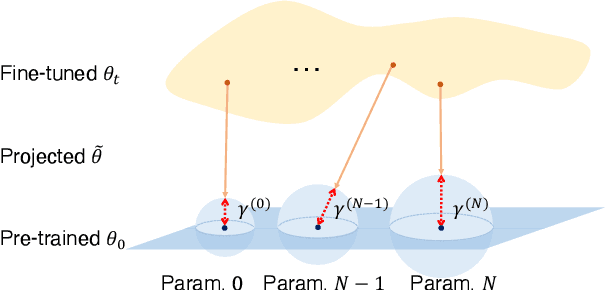
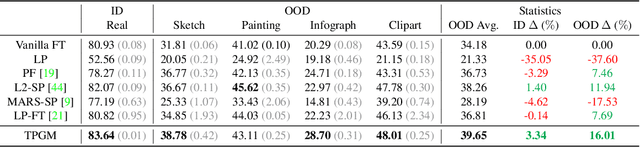
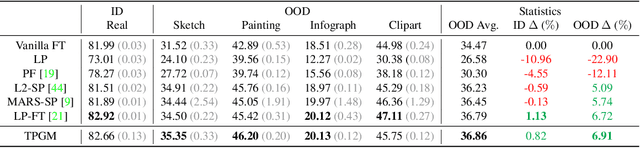
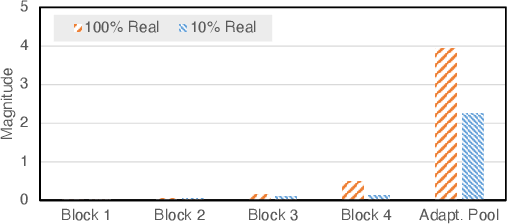
Recent studies on transfer learning have shown that selectively fine-tuning a subset of layers or customizing different learning rates for each layer can greatly improve robustness to out-of-distribution (OOD) data and retain generalization capability in the pre-trained models. However, most of these methods employ manually crafted heuristics or expensive hyper-parameter searches, which prevent them from scaling up to large datasets and neural networks. To solve this problem, we propose Trainable Projected Gradient Method (TPGM) to automatically learn the constraint imposed for each layer for a fine-grained fine-tuning regularization. This is motivated by formulating fine-tuning as a bi-level constrained optimization problem. Specifically, TPGM maintains a set of projection radii, i.e., distance constraints between the fine-tuned model and the pre-trained model, for each layer, and enforces them through weight projections. To learn the constraints, we propose a bi-level optimization to automatically learn the best set of projection radii in an end-to-end manner. Theoretically, we show that the bi-level optimization formulation could explain the regularization capability of TPGM. Empirically, with little hyper-parameter search cost, TPGM outperforms existing fine-tuning methods in OOD performance while matching the best in-distribution (ID) performance. For example, when fine-tuned on DomainNet-Real and ImageNet, compared to vanilla fine-tuning, TPGM shows $22\%$ and $10\%$ relative OOD improvement respectively on their sketch counterparts. Code is available at \url{https://github.com/PotatoTian/TPGM}.
* Accepted to CVPR2023
Mask3D: Pre-training 2D Vision Transformers by Learning Masked 3D Priors
Feb 28, 2023



Current popular backbones in computer vision, such as Vision Transformers (ViT) and ResNets are trained to perceive the world from 2D images. However, to more effectively understand 3D structural priors in 2D backbones, we propose Mask3D to leverage existing large-scale RGB-D data in a self-supervised pre-training to embed these 3D priors into 2D learned feature representations. In contrast to traditional 3D contrastive learning paradigms requiring 3D reconstructions or multi-view correspondences, our approach is simple: we formulate a pre-text reconstruction task by masking RGB and depth patches in individual RGB-D frames. We demonstrate the Mask3D is particularly effective in embedding 3D priors into the powerful 2D ViT backbone, enabling improved representation learning for various scene understanding tasks, such as semantic segmentation, instance segmentation and object detection. Experiments show that Mask3D notably outperforms existing self-supervised 3D pre-training approaches on ScanNet, NYUv2, and Cityscapes image understanding tasks, with an improvement of +6.5% mIoU against the state-of-the-art Pri3D on ScanNet image semantic segmentation.
Pruning Compact ConvNets for Efficient Inference
Jan 11, 2023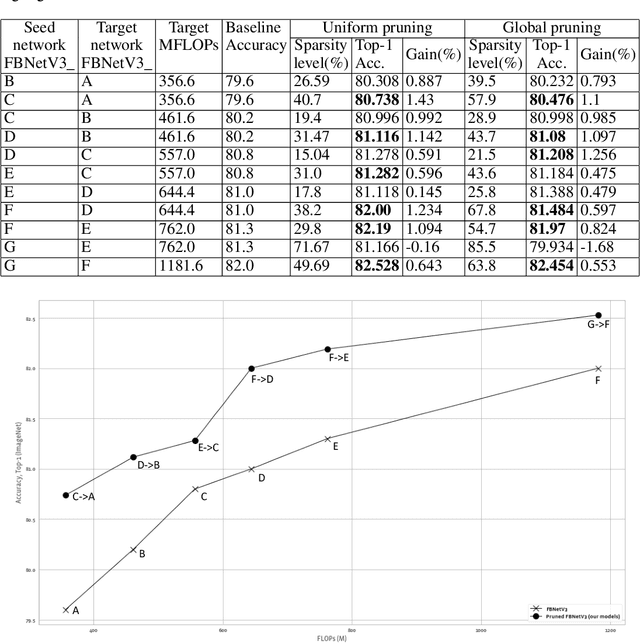
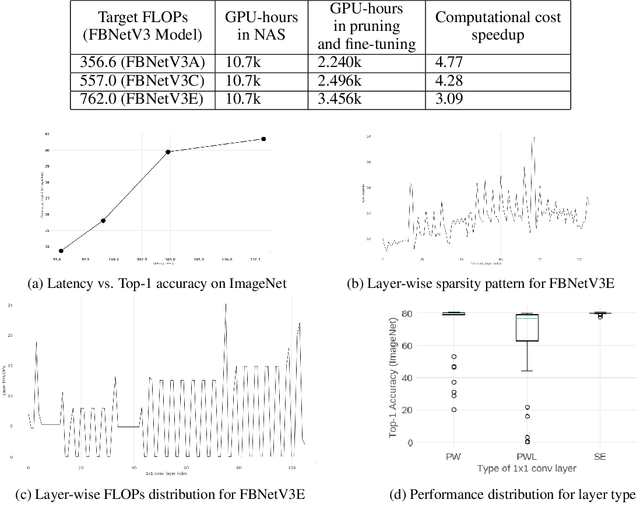
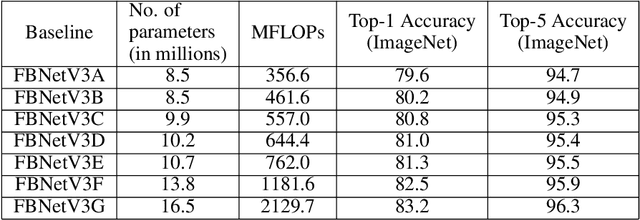
Neural network pruning is frequently used to compress over-parameterized networks by large amounts, while incurring only marginal drops in generalization performance. However, the impact of pruning on networks that have been highly optimized for efficient inference has not received the same level of attention. In this paper, we analyze the effect of pruning for computer vision, and study state-of-the-art ConvNets, such as the FBNetV3 family of models. We show that model pruning approaches can be used to further optimize networks trained through NAS (Neural Architecture Search). The resulting family of pruned models can consistently obtain better performance than existing FBNetV3 models at the same level of computation, and thus provide state-of-the-art results when trading off between computational complexity and generalization performance on the ImageNet benchmark. In addition to better generalization performance, we also demonstrate that when limited computation resources are available, pruning FBNetV3 models incur only a fraction of GPU-hours involved in running a full-scale NAS.