 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaniel Cremers
A Perspective on Deep Vision Performance with Standard Image and Video Codecs
Apr 18, 2024
Resource-constrained hardware, such as edge devices or cell phones, often rely on cloud servers to provide the required computational resources for inference in deep vision models. However, transferring image and video data from an edge or mobile device to a cloud server requires coding to deal with network constraints. The use of standardized codecs, such as JPEG or H.264, is prevalent and required to ensure interoperability. This paper aims to examine the implications of employing standardized codecs within deep vision pipelines. We find that using JPEG and H.264 coding significantly deteriorates the accuracy across a broad range of vision tasks and models. For instance, strong compression rates reduce semantic segmentation accuracy by more than 80% in mIoU. In contrast to previous findings, our analysis extends beyond image and action classification to localization and dense prediction tasks, thus providing a more comprehensive perspective.
Partial-to-Partial Shape Matching with Geometric Consistency
Apr 18, 2024Finding correspondences between 3D shapes is an important and long-standing problem in computer vision, graphics and beyond. A prominent challenge are partial-to-partial shape matching settings, which occur when the shapes to match are only observed incompletely (e.g. from 3D scanning). Although partial-to-partial matching is a highly relevant setting in practice, it is rarely explored. Our work bridges the gap between existing (rather artificial) 3D full shape matching and partial-to-partial real-world settings by exploiting geometric consistency as a strong constraint. We demonstrate that it is indeed possible to solve this challenging problem in a variety of settings. For the first time, we achieve geometric consistency for partial-to-partial matching, which is realized by a novel integer non-linear program formalism building on triangle product spaces, along with a new pruning algorithm based on linear integer programming. Further, we generate a new inter-class dataset for partial-to-partial shape-matching. We show that our method outperforms current SOTA methods on both an established intra-class dataset and our novel inter-class dataset.
Uncertainty-Based Abstention in LLMs Improves Safety and Reduces Hallucinations
Apr 16, 2024A major barrier towards the practical deployment of large language models (LLMs) is their lack of reliability. Three situations where this is particularly apparent are correctness, hallucinations when given unanswerable questions, and safety. In all three cases, models should ideally abstain from responding, much like humans, whose ability to understand uncertainty makes us refrain from answering questions we don't know. Inspired by analogous approaches in classification, this study explores the feasibility and efficacy of abstaining while uncertain in the context of LLMs within the domain of question-answering. We investigate two kinds of uncertainties, statistical uncertainty metrics and a distinct verbalized measure, termed as In-Dialogue Uncertainty (InDU). Using these uncertainty measures combined with models with and without Reinforcement Learning with Human Feedback (RLHF), we show that in all three situations, abstention based on the right kind of uncertainty measure can boost the reliability of LLMs. By sacrificing only a few highly uncertain samples we can improve correctness by 2% to 8%, avoid 50% hallucinations via correctly identifying unanswerable questions and increase safety by 70% up to 99% with almost no additional computational overhead.
Flattening the Parent Bias: Hierarchical Semantic Segmentation in the Poincaré Ball
Apr 15, 2024Hierarchy is a natural representation of semantic taxonomies, including the ones routinely used in image segmentation. Indeed, recent work on semantic segmentation reports improved accuracy from supervised training leveraging hierarchical label structures. Encouraged by these results, we revisit the fundamental assumptions behind that work. We postulate and then empirically verify that the reasons for the observed improvement in segmentation accuracy may be entirely unrelated to the use of the semantic hierarchy. To demonstrate this, we design a range of cross-domain experiments with a representative hierarchical approach. We find that on the new testing domains, a flat (non-hierarchical) segmentation network, in which the parents are inferred from the children, has superior segmentation accuracy to the hierarchical approach across the board. Complementing these findings and inspired by the intrinsic properties of hyperbolic spaces, we study a more principled approach to hierarchical segmentation using the Poincar\'e ball model. The hyperbolic representation largely outperforms the previous (Euclidean) hierarchical approach as well and is on par with our flat Euclidean baseline in terms of segmentation accuracy. However, it additionally exhibits surprisingly strong calibration quality of the parent nodes in the semantic hierarchy, especially on the more challenging domains. Our combined analysis suggests that the established practice of hierarchical segmentation may be limited to in-domain settings, whereas flat classifiers generalize substantially better, especially if they are modeled in the hyperbolic space.
Boosting Self-Supervision for Single-View Scene Completion via Knowledge Distillation
Apr 11, 2024Inferring scene geometry from images via Structure from Motion is a long-standing and fundamental problem in computer vision. While classical approaches and, more recently, depth map predictions only focus on the visible parts of a scene, the task of scene completion aims to reason about geometry even in occluded regions. With the popularity of neural radiance fields (NeRFs), implicit representations also became popular for scene completion by predicting so-called density fields. Unlike explicit approaches. e.g. voxel-based methods, density fields also allow for accurate depth prediction and novel-view synthesis via image-based rendering. In this work, we propose to fuse the scene reconstruction from multiple images and distill this knowledge into a more accurate single-view scene reconstruction. To this end, we propose Multi-View Behind the Scenes (MVBTS) to fuse density fields from multiple posed images, trained fully self-supervised only from image data. Using knowledge distillation, we use MVBTS to train a single-view scene completion network via direct supervision called KDBTS. It achieves state-of-the-art performance on occupancy prediction, especially in occluded regions.
Flattening the Parent Bias: Hierarchical Semantic Segmentation in the Poincar{é} Ball
Apr 11, 2024Hierarchy is a natural representation of semantic taxonomies, including the ones routinely used in image segmentation. Indeed, recent work on semantic segmentation reports improved accuracy from supervised training leveraging hierarchical label structures. Encouraged by these results, we revisit the fundamental assumptions behind that work. We postulate and then empirically verify that the reasons for the observed improvement in segmentation accuracy may be entirely unrelated to the use of the semantic hierarchy. To demonstrate this, we design a range of cross-domain experiments with a representative hierarchical approach. We find that on the new testing domains, a flat (non-hierarchical) segmentation network, in which the parents are inferred from the children, has superior segmentation accuracy to the hierarchical approach across the board. Complementing these findings and inspired by the intrinsic properties of hyperbolic spaces, we study a more principled approach to hierarchical segmentation using the Poincar\'e ball model. The hyperbolic representation largely outperforms the previous (Euclidean) hierarchical approach as well and is on par with our flat Euclidean baseline in terms of segmentation accuracy. However, it additionally exhibits surprisingly strong calibration quality of the parent nodes in the semantic hierarchy, especially on the more challenging domains. Our combined analysis suggests that the established practice of hierarchical segmentation may be limited to in-domain settings, whereas flat classifiers generalize substantially better, especially if they are modeled in the hyperbolic space.
Finsler-Laplace-Beltrami Operators with Application to Shape Analysis
Apr 05, 2024The Laplace-Beltrami operator (LBO) emerges from studying manifolds equipped with a Riemannian metric. It is often called the Swiss army knife of geometry processing as it allows to capture intrinsic shape information and gives rise to heat diffusion, geodesic distances, and a multitude of shape descriptors. It also plays a central role in geometric deep learning. In this work, we explore Finsler manifolds as a generalization of Riemannian manifolds. We revisit the Finsler heat equation and derive a Finsler heat kernel and a Finsler-Laplace-Beltrami Operator (FLBO): a novel theoretically justified anisotropic Laplace-Beltrami operator (ALBO). In experimental evaluations we demonstrate that the proposed FLBO is a valuable alternative to the traditional Riemannian-based LBO and ALBOs for spatial filtering and shape correspondence estimation. We hope that the proposed Finsler heat kernel and the FLBO will inspire further exploration of Finsler geometry in the computer vision community.
Sparse Views, Near Light: A Practical Paradigm for Uncalibrated Point-light Photometric Stereo
Mar 29, 2024Neural approaches have shown a significant progress on camera-based reconstruction. But they require either a fairly dense sampling of the viewing sphere, or pre-training on an existing dataset, thereby limiting their generalizability. In contrast, photometric stereo (PS) approaches have shown great potential for achieving high-quality reconstruction under sparse viewpoints. Yet, they are impractical because they typically require tedious laboratory conditions, are restricted to dark rooms, and often multi-staged, making them subject to accumulated errors. To address these shortcomings, we propose an end-to-end uncalibrated multi-view PS framework for reconstructing high-resolution shapes acquired from sparse viewpoints in a real-world environment. We relax the dark room assumption, and allow a combination of static ambient lighting and dynamic near LED lighting, thereby enabling easy data capture outside the lab. Experimental validation confirms that it outperforms existing baseline approaches in the regime of sparse viewpoints by a large margin. This allows to bring high-accuracy 3D reconstruction from the dark room to the real world, while maintaining a reasonable data capture complexity.
SatSynth: Augmenting Image-Mask Pairs through Diffusion Models for Aerial Semantic Segmentation
Mar 25, 2024In recent years, semantic segmentation has become a pivotal tool in processing and interpreting satellite imagery. Yet, a prevalent limitation of supervised learning techniques remains the need for extensive manual annotations by experts. In this work, we explore the potential of generative image diffusion to address the scarcity of annotated data in earth observation tasks. The main idea is to learn the joint data manifold of images and labels, leveraging recent advancements in denoising diffusion probabilistic models. To the best of our knowledge, we are the first to generate both images and corresponding masks for satellite segmentation. We find that the obtained pairs not only display high quality in fine-scale features but also ensure a wide sampling diversity. Both aspects are crucial for earth observation data, where semantic classes can vary severely in scale and occurrence frequency. We employ the novel data instances for downstream segmentation, as a form of data augmentation. In our experiments, we provide comparisons to prior works based on discriminative diffusion models or GANs. We demonstrate that integrating generated samples yields significant quantitative improvements for satellite semantic segmentation -- both compared to baselines and when training only on the original data.
VXP: Voxel-Cross-Pixel Large-scale Image-LiDAR Place Recognition
Mar 21, 2024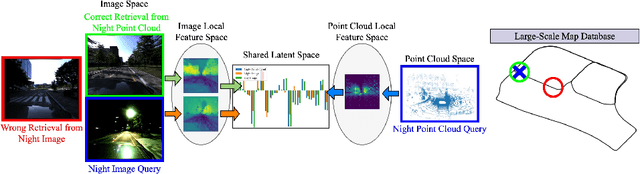

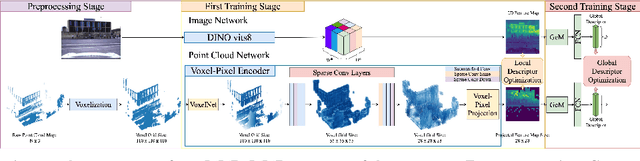
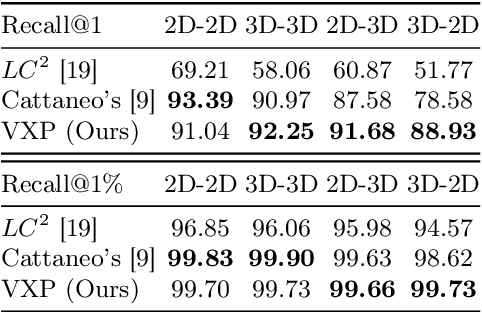
Recent works on the global place recognition treat the task as a retrieval problem, where an off-the-shelf global descriptor is commonly designed in image-based and LiDAR-based modalities. However, it is non-trivial to perform accurate image-LiDAR global place recognition since extracting consistent and robust global descriptors from different domains (2D images and 3D point clouds) is challenging. To address this issue, we propose a novel Voxel-Cross-Pixel (VXP) approach, which establishes voxel and pixel correspondences in a self-supervised manner and brings them into a shared feature space. Specifically, VXP is trained in a two-stage manner that first explicitly exploits local feature correspondences and enforces similarity of global descriptors. Extensive experiments on the three benchmarks (Oxford RobotCar, ViViD++ and KITTI) demonstrate our method surpasses the state-of-the-art cross-modal retrieval by a large margin.